新手入门Python核心笔记五:多线程、图形用户界面、web、数据库、扩展Python

目录
第十八章多线程编程
第十九章图形用户界面编程
第二十章Web 编程
urllib.open()
urllib.urlretrieve()
第二十一章数据库编程
第二十二章扩展 Python
第二十三章其他话题
第十八章多线程编程
Python 代码的执行由 Python 虚拟机(也叫解释器主循环)来控制。
虽然 Python 解释器中可以“运行”多个程序,但在任意时刻,只有一个线程在解释器中运行。与单个 CPU 的多线程原理是一样的。
对 Python 虚拟机的访问由全局解释器锁(GIL)来控制的,也正是这个锁保证了同一时刻只有一个线程在运行。
不建议使用 thread 模块,而推荐使用 threading 模块,原因:
- Thread 模块不支持守护进程。在主线程退出的时候,所有他其他线程没有被清除就退出了
- Threading 模块支持守护进程。能保证所有“重要的”子线程都退出后,进程才会结束
- Threading 模块更为先进,对线程的支持更为完善
- Thread 模块中的属性可能与 threading 出现冲突
- 低级别的 Thread 模块的同步原语只有一个,而Threading 则有很多
time.sleep(secs):睡眠多长时间,secs 单位秒(不是毫秒)
start_new_thread(function, args keargs=None) 产生一个新的线程,在新线程中用指定的参数和可选的 kwargs 来调用这个函数
Threading 的 Thread 类是我们主要的运行对象。它有很多 Thread 模块中没有的函数。
| 函数 |
描述 |
| start() |
开始线程的执行 |
| run() |
定义线程的功能的函数(一般会被子类重写) |
| join(timeout=None) |
程序挂起直到线程结束;给了 timeout,则最多阻塞 timeout 秒 |
| getName() |
返回线程的名字 |
| setName(name) |
设置线程的名字 |
| isAlive() |
布尔标志,标示这个线程是否还在运行中 |
| isDaemon() |
返回线程的 daemon 标志 |
| setDaemon(daemonic) |
把线程的 daemon 标志设为 daemonic(一定要在 start()前调用) |
注:thread.start()前调用 thread.setDaemon(True)表示这个线程“不重要”
Python核心笔记一:欢迎来到Python世界【我从没见过你 但我懂你】
Python核心笔记二:学习基础、对象、字符串、列表和元组【我从没见过你 但我懂你】
新手入门Python核心笔记三:字典、循环、输入输出、错误和异常、函数【我从没见过你 但我懂你】
新手入门Python核心笔记四:面向对象、执行环境、正则表达式、网络编程
更多精彩内容可以关注本人的公众号:

第十九章图形用户界面编程
GUI:graphical user interface
Python 的默认 GUI 工具集是 TK,我们可以通过Python 接口 Tkinter 来使用 Tk
import Tkinter 先测试一下系统有没有开启 Tkinter。
创建 GUI 程序的五个基本步骤:
- Import Tkinter
- 创建顶层窗口对象容纳你的 GUI: top = Tkinter.Tk()
- 在 top 中创建所有的 GUI 模块
- 将 3 中的 GUI 模块与底层代码相连接
- 进入主事件循环
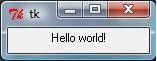
A Tkinter example: “Hello world!” :
from Tkinter import * #导入 Tkinter top = Tk() #顶层窗口
label = Label(top, text=’Hello world!’) #创建模块
label.pack() #装载连接
mainloop() #主事件循环
运行截图:
Python 拥有大量的图形工具集,其中 4 种比较流行的工具集:
- Tix(Tk Interface eXtensions)
- Pmw(Python MegaWidgets 的 Tkinter 扩展)
- wxPython(wxWidgets 的Python 绑定)
- PyGTK(GTK+的 Python 绑定)
其中 Tix 模块包含在Python 标准库中,其它工具集是第三方的,必须自己下载。
Learn more about Python GUI:
http://wiki.python.org/moin/GuiProgramming
第二十章Web 编程
urlparse 模块:
| Urlparse 功能 |
描述 |
| Urlparse(urlstr,defProtSch=None,allowF rag=None |
将 urlstr 解析成各个部件defProtSch 为 URL 协议, allowFrag 为决定是否允许 URL 零部件 |
| Urlunparse(urltup) |
将 URL 数据的一个元组反解析成一个 URL 字符串 |
| Urljoin(baseurl,newurl,allowFrag=None ) |
将 URL 基部件 baseurl 和newurl 拼合成一个完整的 URL |
Urllib 模块:
Urllib 模块提供了所有你需要的功能,它提供了一个高级的Web 交流库。其特殊功能在于利用各种协议(HTTP、FTP 等)从网络上下载数据。
urllib.open()
语法:urlopen(urlstr, postQueryData=None)
作用:打开 urlstr 所指向的 URL
结果:成功则返回一个文件类型对象
urllib.urlretrieve()
语法:urlretrieve(urlstr, localfile=None, downloadSta-tusHook=None)
作用:将 urlstr 定位到的整个 HTML 文件下载到本地硬盘
结果:返回一个二元组(filename,mine_hdrs)本地文件名、MIME 文件头
(以上是两个 urllib 模块核心函数中特别常用的两个函数,故为大家列了出来,望学习时多加关注,另外对于更为复杂的 URL 打开问题可用 urllib2 模块进行处理)
Python 的基本 Web 客户端一般用于在 Web 上查询或下载文件。而其高级 Web 客户端可
以在 internet 上完成基于不同目的的所有和下载页面,包括:
- 为 Google 和 Yahoo 的搜索引擎建索引
- 脱机浏览—将文档下载到本地,重新设定超链接,为本地浏览器创建镜像
- 下载并保持历史记录或框架
- Web 页的缓存,节省再次访问 Web 站点的下载时间
高级 Web 客户端的一个例子就是“网络爬虫”(也称蜘蛛或机器人),与正则表达式的完美结合使用,使你在 internet 上想“爬”什么就“爬”什么。
CGI:帮助 Web 服务器处理客户端数据
Web 服务器接收到表单反馈,与外部应用程序交互,收到并返回新的生成的 HTML
页面都发生在 Web 服务器的 CGI(标准网关接口,Common Gateway Interface)接口上。CGI 其实只是一个适用于小型 Web 网站开发的工具。
FieldStorge 类:Python CGI 脚本开始时被实例化,包含一个类似字典的对象,键—表单栏目的名字,值—栏目相应的数据。
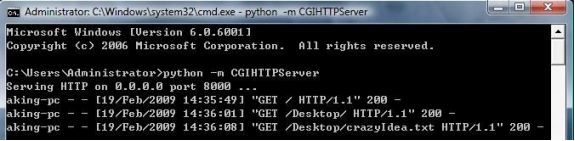
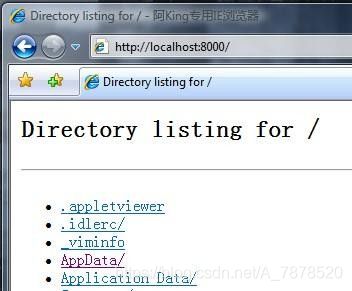
建立 Python 自带的Web 服务器:
命令:$ Python –m CGIHTTPServer
端口:8000
目录:在目录下手工建立 Cgi-bin 存放.py CGI 脚本访问:http://localhost:8000/ex.html
http://localhost:8000/cgi-bin/ex.py
用 Python 建立 Web 服务器:
要建立一个 Web 服务,一个基本的服务器和一个“处理器”是必备的。
基本的服务器:在客户端和服务器端完成必要的 HTTP 交互。
处理器:处理 Web 服务的简单软件。处理客户端请求,并返回适当的文件。
Web 服务器模块和类
| 模块 |
描述 |
| BaseHTTPServer |
提供基本的 Web 服务和处理器类,分别是 HTTPServer 和BaseHTTPRequestHandler |
| SimpleHTTPServer |
包含执行 GET 和 HEAD 请求的 SimpleHTTPRequestHandle 类 |
| CGIHTTPServer |
包含处理 POST 请求和执行 CGIHTTPRequestHandle 类 |
第二十一章数据库编程
本章的主题是如何通过Python 访问关系型数据库(RDBMS)
阅读本章读者须掌握基本的数据库操作和 SQL 语言,这部分相关内容请查阅相关的数据库方面的书籍
Python 数据库 API:Python 能够直接通过数据库接口,也可以通过 ORM(需要自己书写 SQL) 来访问关系数据库
Python 应用程序(嵌入 SQL)-- Python DB 接口程序— RDBMS 客户端库— 关系数据库
DB-API:这是一个规范。它定义了一系列必需的对象和数据库存取方式,以便在各种各样的底层数据库系统和多种多样的数据库接口程序提供一致的访问接口。
DB-API 模块属性
| 属性名 |
描述 |
| apilevel |
模块兼容的 DB-API 版本号 |
| threadsafety |
线程安全级别 |
| paramstyle |
该模块支持的 SQL 语句参考风格 |
| connect() |
连接函数 |
连接对象: 要与数据库通信,必须先和数据库建立连接。连接对象用于处理将命令送往服务器,以及从服务器接受数据等基本功能。
游标对象: 允许用于执行数据库命令和得到查询结果。
对于不支持游标的数据库来说,connect 对象的 cursor()方法仍然会返回一个尽量模仿游标对象的对象。
游标对象最重要的属性是 execute*()和 fetch*(),所有对数据库服务器的请求均由它们来完成。
Python 到底支持哪些平台下的数据库?答案是几乎所有!
以 MySQL 举例:
>>> import MySQLdb
>>> cxn = MySQLdb.connect(user=’rooot’)
>>> cxn.query(‘CREATE DATABASE test’)
>>> cxn.commit()
>>> cxn.close()
>>> cur = cxn.cursor()>>> cxn = MySQLdb.connect(db=’test’)
>>> cur.execute(‘CREATE TABLE users(login VARCHAR(8), uid INT)’)
0L
>>> cur.execute(‘INSERT INTO users VALUES(‘john’, 7000)’)
1L
>>> for data in cur.fetcharall(): print ‘%s\t%s’ % data
john 7000
>>> cur.close()
>>> cxn.commit()
>>> cxn.close()
ORM:对象-关系管理器
考虑对象,而不是 SQL
Python 和 ORM:最著名的 Python ORM 模块是 SQLAlchemy 和 SQLObject
第二十二章扩展 Python
一般来说,所有能被整合或者导入到其他 Python 脚本的代码,都可以称为扩展。扩展的理由:
- 添加额外的(非 Python)功能
- 性能瓶颈的效率提升
- 保持专有源代码私密
为 Python 创建扩展需要 3 个主要的步骤:
- 创建应用程序代码:
- 在 C 代码中放一个 main()用于测试代码的正确性
- 我们要建立的是一个“库”,一个将要在 Python 内运行的模块
2.利用样板来包装代码
- 包含 Python 头文件 #include “Python.h”
- 为每个模块的每一个函数增加一个形如 PyObject* Module_func()的包装函数
- 为每个模块增加一个形如 PyMethodDef ModuleMethods[]的数组
- 增加模块初始化函数 void initModule()
3.编译与测试:distutils 包被用来编译、安装和分发这些模块、扩展和包
- 创建 setup.py
- 通过运行 setup.py 来编译和连接你的代码
- 从 Python 中导入你的模块 : $ python setup.py install
- 测试功能
在编译的时候,我们需要将代码跟 Python 库放在一起进行编译。
Other topics for more learning:
SWIG
Pyrex
Psyco
嵌入
第二十三章其他话题
Web 服务
用 Win32 的 COM 来操作Microsoft Office
用 Jpython 写Python 和 Java 的程序