精通Mybatis之结果集处理流程与映射体系(重点mybatis嵌套子查询,循环依赖解决方案)(二)
前言
大家五一快乐啊,上次小编写了映射体系一,具体讲了MetaObject反射工具的使用以及源码解释,接下来讲一下真正的映射体系。
手动 自动映射
手动映射配置
xml
<resultMap id="baseMap" type="entity.Company">
<id property="id" column="id"/>
<result property="companyName" column="company_name" jdbcType="VARCHAR"/>
<association property="legalPerson" column="id">
<id property="id" column="id"/>
<result property="name" column="name"/>
association>
resultMap>
<resultMap id="baseMap1" type="entity.Company">
<id property="id" column="id"/>
<result property="companyName" column="company_name" jdbcType="VARCHAR"/>
<association property="legalPerson" column="id" resultMap="legalPersonMap">
association>
resultMap>
<resultMap id="legalPersonMap" type="entity.LegalPerson">
<id property="id" column="id"/>
<result property="name" column="name"/>
resultMap>
<resultMap id="baseMap2" type="entity.Company">
<id property="id" column="id"/>
<result property="companyName" column="company_name" jdbcType="VARCHAR"/>
<association property="legalPerson" column="id" select="selectByCompanyId"/>
resultMap>
<select id="selectByCompanyId" resultType="entity.LegalPerson"/>
这个比较基础,当然也可以使用java代码,小伙伴自行研究啊。
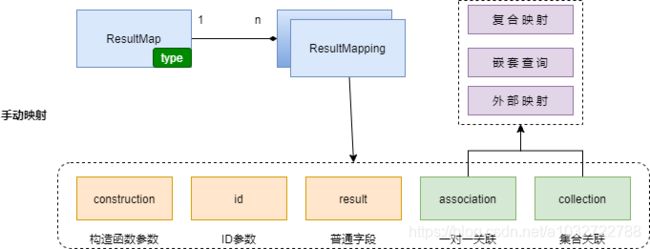
一个ResultMap 中包含多个ResultMapping 表示一个具体的JAVA属性到列的映射,其主要值如下:
| result id属性 |
|---|
| property | 类属性名(必填) |
|---|---|
| column | 数据库列名(必填) |
| jdbcType | jdbc类型(自动推导) |
| javaType | java类型(自动推导) |
| TypeHandler | 类型处理器(自动推导) |
ResultMapping 有多种表现形式如下:
- constructor:构建参数字段
- id:ID字段
- result:普通结构集字段
- association:1对1关联字段
- collection:1对多集合关联字段
上面手动映射图如下:
自动映射配置
<resultMap id="baseMap" type="entity.Company" autoMapping="true">
resultMap>
自动映射条件
- 列名和属性名同时存在(勿略大小写)
- 当前列未手动设置映射
- 属性类别存在TypeHandler
- 开启autoMapping (默认开启)
自动映射图如下:

嵌套子查询
小编用上面的示例写一个简单测试代码这里用了lombok:
类测试类以及接口代码:
public interface CompanyMapper {
Company selectById(@Param("id")Long id);
}
@Data
public class Company {
private Long id;
private String companyName;
private LegalPerson legalPerson;
private List<Department> departmentList;
}
@Data
public class LegalPerson {
private Long id;
private String name;
private Long companyId;
}
@Data
public class Department {
private Long id;
private String departmentName;
private Long companyId;
private List<Employee> employeeList;
}
@Test
public void associationTest() {
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE)) {
CompanyMapper companyMapper = sqlSession.getMapper(CompanyMapper.class);
Company company = companyMapper.selectById(1L);
System.out.println(company.getLegalPerson());
}
}
xml配置:
<resultMap id="CompanyMap" type="entity.Company">
<id property="id" column="id"/>
<result property="companyName" column="company_name" jdbcType="VARCHAR"/>
<association property="legalPerson" column="id" select="selectByCompanyId"/>
<collection property="departmentList" column="id" select="selectDepartByCompanyId"/>
</resultMap>
<resultMap id="LegalPersonMap" type="entity.LegalPerson">
<id property="id" column="id"/>
<result property="companyId" column="company_id" />
<result property="name" column="name"/>
</resultMap>
<resultMap id="DepartmentMap" type="entity.Department">
<id property="id" column="id"/>
<result property="companyId" column="company_id" />
<result property="departmentName" column="department_name"/>
</resultMap>
<select id="selectByCompanyId" resultMap="LegalPersonMap">
select * from legal_person where company_id = #{
companyId}
</select>
<select id="selectDepartByCompanyId" resultMap="DepartmentMap">
select * from department where company_id = #{
companyId}
</select>
<select id="selectById" resultMap="CompanyMap" parameterType="java.lang.Long">
select * from company where id = #{
id}
</select>
提问:当这里需要传递多个参数时该怎么写?
这里小编写伪xml column = “companyId =id,name=companyName” ,然后下面就可以company_id=#{companyId} and name = #{name}
上面小编为什么写这样的示例呢?其实小编想说明一个问题,我们来讨论一个这样的问题:假设我们的法人有一家公司,然后公司下面的法人又是自己,那当我们查询法人的时候要填充公司属性,但公司填充的时候又查询到这个法人,那这样不就死循环了吗?那mybatis到底会不会出现死循环呢
答案:当然不会死循环了(不信大家自己试一下,小编已经试过了),其实mybatis作者也想到了这个问题,spring中是不是也会有循环依赖的问题,那mybatis是如何解决的呢,那下面小编继续讲解其中的原理。
循环依赖
循环依赖流程图:

根据上面的流程图,小编带大家看一下源码,大家也可以自己打断点调试。在上一篇博客中,封装行对象的时候用到DefaultResultSetHandler#getRowValue方法,里面用到了applyPropertyMappings方法,因为是嵌套查询的最终会用到getPropertyMappingValue方法:
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
//是否是嵌套查询 这个方法就开始和上面流程图差不多了
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK?
return DEFERRED;
} else {
//直接获取值
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
return typeHandler.getResult(rs, column);
}
}
开始嵌套查询
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
//准备参数 ,获取mappedStatement,动态sql 准备换成key
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
//是否存在缓存
if (executor.isCached(nestedQuery, key)) {
//命中缓存 延时加载
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
value = DEFERRED;
} else {
//没有命中缓存
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
if (propertyMapping.isLazy()) {
//看是否懒加载
lazyLoader.addLoader(property, metaResultObject, resultLoader);
value = DEFERRED;
} else {
//否则直接查询
value = resultLoader.loadResult();
}
}
}
return value;
}
延迟加载是在主查询结束后再将属性值填充进去。其具体实现在baseExecutor
@Override
public void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
DeferredLoad deferredLoad = new DeferredLoad(resultObject, property, key, localCache, configuration, targetType);
//是否可延迟加载
if (deferredLoad.canLoad()) {
//可以直接延迟加载
deferredLoad.load();
} else {
//需要延迟加载的放入deferredLoads 这里就是法人下面查找的公司
deferredLoads.add(new DeferredLoad(resultObject, property, key, localCache, configuration, targetType));
}
}
public boolean canLoad() {
//本地缓存有且不是EXECUTION_PLACEHOLDER值,在第一次查询的时候会有占位符
return localCache.getObject(key) != null && localCache.getObject(key) != EXECUTION_PLACEHOLDER;
}
public void load() {
@SuppressWarnings("unchecked")
// we suppose we get back a List
//然后直接从key拿值,然后赋值即可
List<Object> list = (List<Object>) localCache.getObject(key);
Object value = resultExtractor.extractObjectFromList(list, targetType);
resultObject.setValue(property, value);
}
上面的流程图和源代码已经对应起来了,但是大家可能还没明白mybatis怎么解决循环依赖的。
首先先说结论,第一使用一级缓存,第二个使用延迟加载(这里也间接说明了一级缓存是不能关闭的),这边还用了一个queryStack参数和缓存占位符,
下面咱们再次捋一下
1、查询公司 queryStack=0
2、公司下的法人 queryStack=1
3、法人下的公司 queryStack=2
其中第一次查询将自己设置缓存和第三次查询时是同一家公司,所以会走一级缓存,不会重复查询数据库,接着将自己放入到延迟加载集合中,回到主查询,加载延迟加载中的属性值即可。
小编完整说明一下循环依赖的解决:
再次贴一下代码BaseExecutor代码:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
//查询一次 加一次查询堆
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
//查询完毕 减一次查询堆
queryStack--;
}
//当查询到0的时候就是返回主查询,进行延迟装载
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
//装载完延迟后清空延迟加载器
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//查询前放入占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//查询并且赋值相应的参数值,会涉及上面的嵌套查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
- 第一次查询公司的时候:BaseExecutor.query方法中 queryStack++,并且设置一级缓存占位符;
- 在嵌套查询,即第二次查询法人的时候,因为不是懒加载则会再次BaseExecutor.query这个方法,queryStack++然后设置查询法人的一级缓存占位符
- 查询法人信息的时候又查询公司,即第三次查询公司有缓存了,因为还不能直接加载,则放入了deferredLoads
- 返回结果,先是法人查询填充属性完毕queryStack – ,删除法人一级缓存的占位符,将法人放入一级缓存中,之后是公司查询填充法人信息完毕queryStack – ,删除公司一级缓存占位符,将公司放入一级缓存中
- queryStack为0,执行延迟加载,里面有刚刚放入的一个,并且可以加载了(公司一级缓存不为空也不是占位符),延迟加载使用metaObject设置对应的值即可。
总结
今天主要讲了映射体系中的手动自动,以及嵌套子查询和循环依赖mybatis是如何解决的,还有懒加载和延迟加载是两回事情,希望小编讲得足够明白了。最近小编在讲解过程中留下来一些问题,主要是希望大家不仅仅是看看,更得实践,否则容易忘记,一起加油啊。接下来小编会讲解懒加载,大家继续关注吧