Python 机器学习 随机森林 天气最高温度预测任务(二)
更多的数据效果会不会更好呢?
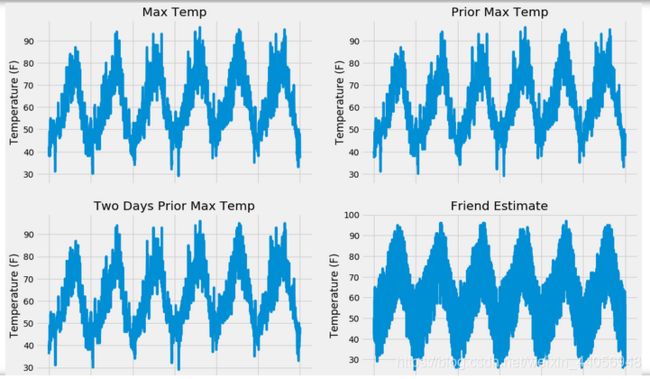
# 导入工具包 import pandas as pd # 读取数据 features = pd.read_csv('data/temps_extended.csv') features.head(5) # 转换成标准格式 import datetime # 得到各种日期数据 years = features['year'] months = features['month'] days = features['day'] # 格式转换 dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)] dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates] # 绘图 import matplotlib.pyplot as plt %matplotlib inline # 风格设置 plt.style.use('fivethirtyeight') # Set up the plotting layout fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (15,10)) fig.autofmt_xdate(rotation = 45) # Actual max temperature measurement ax1.plot(dates, features['actual']) ax1.set_xlabel(''); ax1.set_ylabel('Temperature (F)'); ax1.set_title('Max Temp') # Temperature from 1 day ago ax2.plot(dates, features['temp_1']) ax2.set_xlabel(''); ax2.set_ylabel('Temperature (F)'); ax2.set_title('Prior Max Temp') # Temperature from 2 days ago ax3.plot(dates, features['temp_2']) ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature (F)'); ax3.set_title('Two Days Prior Max Temp') # Friend Estimate ax4.plot(dates, features['friend']) ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature (F)'); ax4.set_title('Friend Estimate') plt.tight_layout(pad=2)
在数据分析和特征提取的过程中,我们的出发点都是尽可能多的选择有价值的特征,因为其实阶段我们能得到的信息越多,之后建模可以利用的信息也是越多的,比如在这份数据中,我们有完整日期数据,但是显示天气的变换肯定是跟季节因素有关的,但是在原始数据集中并没有体现出季节的指标,我们可以自己创建一个季节变量当做新的特征,无论是对之后建模还是分析都会起到帮助的:# 设置整体布局 fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (15,10)) fig.autofmt_xdate(rotation = 45) # 平均最高气温 ax1.plot(dates, features['average']) ax1.set_xlabel(''); ax1.set_ylabel('Temperature (F)'); ax1.set_title('Historical Avg Max Temp') # 风速 ax2.plot(dates, features['ws_1'], 'r-') ax2.set_xlabel(''); ax2.set_ylabel('Wind Speed (mph)'); ax2.set_title('Prior Wind Speed') # 降水 ax3.plot(dates, features['prcp_1'], 'r-') ax3.set_xlabel('Date'); ax3.set_ylabel('Precipitation (in)'); ax3.set_title('Prior Precipitation') # 积雪 ax4.plot(dates, features['snwd_1'], 'ro') ax4.set_xlabel('Date'); ax4.set_ylabel('Snow Depth (in)'); ax4.set_title('Prior Snow Depth') plt.tight_layout(pad=2)
有了季节特征之后,假如我想观察一下不同季节的时候上述各项指标的变换情况该怎么做呢?这里给大家推荐一个非常实用的绘图函数pairplot,需要我们先安装seaborn这个工具包,它相当于是在Matplotlib的基础上进行封装,说白了就是用起来更简单规范了:

Pairplots
最简单实用的!用它来看看这些特征有没有啥用呢!
# 创建一个季节变量 seasons = [] for month in features['month']: if month in [1, 2, 12]: seasons.append('winter') elif month in [3, 4, 5]: seasons.append('spring') elif month in [6, 7, 8]: seasons.append('summer') elif month in [9, 10, 11]: seasons.append('fall') # 有了季节我们就可以分析更多东西了 reduced_features = features[['temp_1', 'prcp_1', 'average', 'actual']] reduced_features['season'] = seasons # 导入seaborn工具包 import seaborn as sns sns.set(style="ticks", color_codes=True); # 选择你喜欢的颜色模板 palette = sns.xkcd_palette(['dark blue', 'dark green', 'gold', 'orange']) # 绘制pairplot sns.pairplot(reduced_features, hue = 'season', diag_kind = 'kde', palette= palette, plot_kws=dict(alpha = 0.7), diag_kws=dict(shade=True));
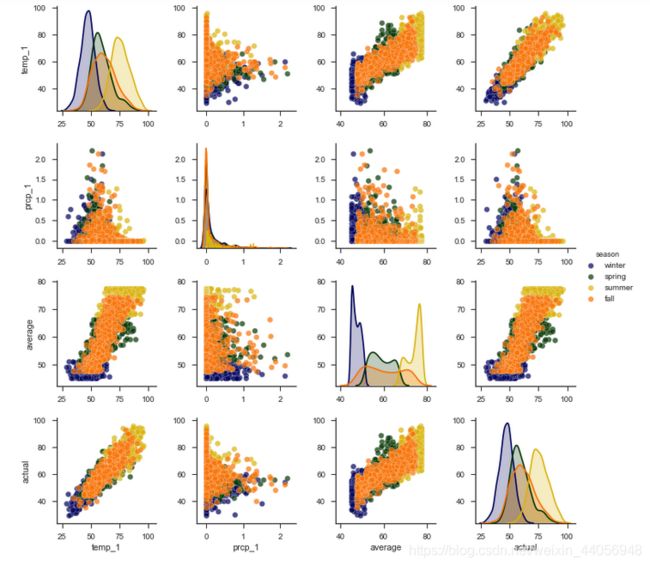
可以看到,x轴和y轴都是我们这4项指标,不同颜色的点表示不同的季节,在主对角线上x轴和y轴都是相同特征表示其在不同季节时的数值分布情况,其他位置用散点图来表示两个特征之间的关系,例如在左下角temp_1和actual就呈现出了很强的相关性。
数据预处理
# 独热编码 features = pd.get_dummies(features) # 提取特征和标签 labels = features['actual'] features = features.drop('actual', axis = 1) # 特征名字留着备用 feature_list = list(features.columns) # 转换成所需格式 import numpy as np features = np.array(features) labels = np.array(labels) # 数据集切分 from sklearn.model_selection import train_test_split train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size = 0.25, random_state = 0) print('Training Features Shape:', train_features.shape) print('Training Labels Shape:', train_labels.shape) print('Testing Features Shape:', test_features.shape) print('Testing Labels Shape:', test_labels.shape)

先来看看老数据的结果
# 工具包导入 import pandas as pd # 为了剔除特征个数对结果的影响,这里特征统一只有老数据集中特征 original_feature_indices = [feature_list.index(feature) for feature in feature_list if feature not in ['ws_1', 'prcp_1', 'snwd_1']] # 读取老数据集 original_features = pd.read_csv('data/temps.csv') original_features = pd.get_dummies(original_features) import numpy as np # 数据和标签转换 original_labels = np.array(original_features['actual']) original_features= original_features.drop('actual', axis = 1) original_feature_list = list(original_features.columns) original_features = np.array(original_features) # 数据集切分 from sklearn.model_selection import train_test_split original_train_features, original_test_features, original_train_labels, original_test_labels = train_test_split(original_features, original_labels, test_size = 0.25, random_state = 42) # 同样的树模型进行建模 from sklearn.ensemble import RandomForestRegressor # 同样的参数与随机种子 rf = RandomForestRegressor(n_estimators= 100, random_state=0) # 这里的训练集使用的是老数据集的 rf.fit(original_train_features, original_train_labels); # 为了测试效果能够公平,统一使用一致的测试集,这里选择了刚刚我切分过的新数据集的测试集 predictions = rf.predict(test_features[:,original_feature_indices]) # 先计算温度平均误差 errors = abs(predictions - test_labels) print('平均温度误差:', round(np.mean(errors), 2), 'degrees.') # MAPE mape = 100 * (errors / test_labels) # 这里的Accuracy为了方便观察,我们就用100减去误差了,希望这个值能够越大越好 accuracy = 100 - np.mean(mape) print('Accuracy:', round(accuracy, 2), '%.')

新数据来了,只增大数据量的话,结果会提升吗
from sklearn.ensemble import RandomForestRegressor # 剔除掉新的特征,保证数据特征是一致的 original_train_features = train_features[:,original_feature_indices] original_test_features = test_features[:, original_feature_indices] rf = RandomForestRegressor(n_estimators= 100 ,random_state=0) rf.fit(original_train_features, train_labels); # 预测 baseline_predictions = rf.predict(original_test_features) # 结果 baseline_errors = abs(baseline_predictions - test_labels) print('平均温度误差:', round(np.mean(baseline_errors), 2), 'degrees.') # (MAPE) baseline_mape = 100 * np.mean((baseline_errors / test_labels)) # accuracy baseline_accuracy = 100 - baseline_mape print('Accuracy:', round(baseline_accuracy, 2), '%.')

加入新特征再来看一看
# 准备加入新的特征 from sklearn.ensemble import RandomForestRegressor rf_exp = RandomForestRegressor(n_estimators= 100, random_state=0) rf_exp.fit(train_features, train_labels) # 同样的测试集 predictions = rf_exp.predict(test_features) # 评估 errors = abs(predictions - test_labels) print('平均温度误差:', round(np.mean(errors), 2), 'degrees.') # (MAPE) mape = np.mean(100 * (errors / test_labels)) # 看一下提升了多少 improvement_baseline = 100 * abs(mape - baseline_mape) / baseline_mape print('特征增多后模型效果提升:', round(improvement_baseline, 2), '%.') # accuracy accuracy = 100 - mape print('Accuracy:', round(accuracy, 2), '%.')

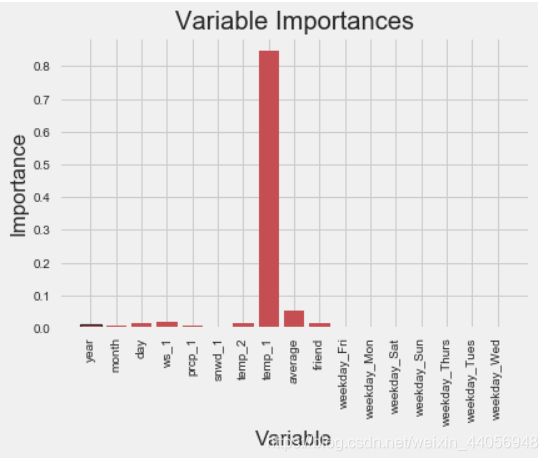
模型整体效果有了略微提升,这里我们还加入一项额外的评估就是模型跟基础模型相比提升的大小,方便来进行对比观察。这回特征也多了,我们可以好好研究下特征重要性这个指标了,虽说其只供参考,但是业界也有一些不成文的行规我们来看一下:
特征重要性
# 特征名字 importances = list(rf_exp.feature_importances_) # 名字,数值组合在一起 feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)] # 排序 feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True) # 打印出来 [print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances]; # 指定风格 plt.style.use('fivethirtyeight') # 指定位置 x_values = list(range(len(importances))) # 绘图 plt.bar(x_values, importances, orientation = 'vertical', color = 'r', edgecolor = 'k', linewidth = 1.2) # x轴名字得竖着写 plt.xticks(x_values, feature_list, rotation='vertical') # 图名 plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
之前我们只是简单看了下载特征中哪些更重要,这回我们需要考虑的是特征的累加重要性,先把特征按照其重要性进行排序,再算起累计值,这里用到了cumsum()函数,比如cusm([1,2,3,4])得到的结果就是其累加值(1,3,6,10),通常我们都以95%为阈值,看看有多少个特征累加在一起之后,其特征重要性的累加值超过该阈值,就取它们当做筛选后的特征:
特征重要性累加,看看95%之前有多少个
# 对特征进行排序 sorted_importances = [importance[1] for importance in feature_importances] sorted_features = [importance[0] for importance in feature_importances] # 累计重要性 cumulative_importances = np.cumsum(sorted_importances) # 绘制折线图 plt.plot(x_values, cumulative_importances, 'g-') # 画一条红色虚线,0.95那 plt.hlines(y = 0.95, xmin=0, xmax=len(sorted_importances), color = 'r', linestyles = 'dashed') # X轴 plt.xticks(x_values, sorted_features, rotation = 'vertical') # Y轴和名字 plt.xlabel('Variable'); plt.ylabel('Cumulative Importance'); plt.title('Cumulative Importances');

这里当第5个特征出现的时候,其总体的累加值超过了95%,那么接下来我们的对比实验又来了,如果只用这5个特征效果会怎么样呢?时间效率又会怎样呢?
训练集和测试集要使用一样的
# 选择这些特征 important_feature_names = [feature[0] for feature in feature_importances[0:5]] # 找到它们的名字 important_indices = [feature_list.index(feature) for feature in important_feature_names] # 重新创建训练集 important_train_features = train_features[:, important_indices] important_test_features = test_features[:, important_indices] # 数据维度 print('Important train features shape:', important_train_features.shape) print('Important test features shape:', important_test_features.shape) # 再训练模型 rf_exp.fit(important_train_features, train_labels); # 同样的测试集 predictions = rf_exp.predict(important_test_features) # 评估结果 errors = abs(predictions - test_labels) print('平均温度误差:', round(np.mean(errors), 2), 'degrees.') mape = 100 * (errors / test_labels) # accuracy accuracy = 100 - np.mean(mape) print('Accuracy:', round(accuracy, 2), '%.')
