需求:
遍历58同城上海站,平板电脑信息。
数据内容:
{'img', 'visit_time', 'category', 'area', 'price','title'}
代码:
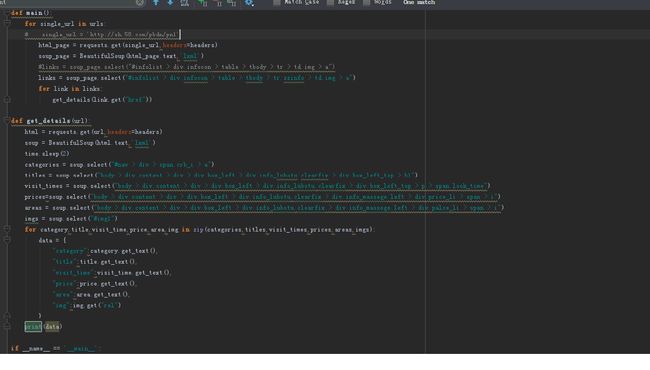
结果

难点:
1. 这个脚本只能爬“转转”的数据,但是
现在存在“转转”和“58同城信息”,一开始没有对于href进行加工筛选,造成无法爬取。
#links = soup_page.select("#infolist > div.infocon > table > tbody > tr > td.img > a") ==》爬取所有页面
links = soup_page.select("#infolist > div.infocon > table > tbody > tr.zzinfo> td.img > a") ==》值爬取“转转”信息。
下面是页面解析后的样式:

如果要爬取58原来的信息要写个判断语句,然后重写一个get_detail2来爬取58原来的结构信息。
本来是想通过判断每条记录上的“精准推广”来判断是否是“转转”的记录,但是发觉很难去一条一条去选择分类,因为python一下子就拿到了所有的链接。以后要多多观察class对不同类型链接的进行选择,这样会方便很多。
2. main主函数的调用
if__name__ =='__main__':
main()
Python会用__name__是否等于‘__main__’来判断是否是主程序,当等于的时候就是主程序,否则就是被别的程序来调用。
所有,这个程序是主程序,所以要加这段让它进入main()函数。