机器学习入门笔记1--使用KNN近邻算法手把手完成你的第一个机器学习模型
在Python使用KNN近邻算法入门第一个机器学习模型
前言
这篇博客亦在为各位想入门机器学习的小白(包括我)使用KNN(k-Nearest Neighbor)分类算法实现自己的第一个模型。本文内容主要包括以下4部分:
- 对KNN算法的简介
- 对数据集的整理以及转变
- 简单的数据可视化
- 预测你的测试集并评估准确率
文中部分内容来自Cousera MU大学网课,我进行了记录以及整理。下面开始。
对KNN模型的简介
K最近邻(k-Nearest Neighbor,KNN)是一种常用的分类算法,导入数据以后可以用于做分类问题,比如输入重量,高度,色泽数据来分辨水果类型。下文中用KNN 算法实现对癌症病人数据的分类然后评估该病人的癌症是恶性还是良性(0代表恶行,1代表良性)。
本文只涉及sklearn.neighbors中的 n_neighbors 参数。建议大家再去百度学习这个模型的细节。
下图为算法的大体步骤:

总结一下,在你给这个模型喂了X_train(训练集数据)和y_train(label标签,也就是target)以后,当你再给它喂一个新的X_test(测试集)以后,这个Classifier会记住整个训练集然后做以下的事情:
- Classifier找到在X_test训练集数据中 与X_train训练集中 最接近的k个数据,我们把这个有点类似交集的数据叫做X_NN
- 然后Classifier会获得这些X_NN数据的label(target),这些标签叫做y_NN
- 组合y_NN的标签值来预测X_test的label
开始
首先引入需要的包以及数据。这个cancer的数据集未处理前比较杂乱。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
#cancer 这是什么鬼?里面比较杂乱,在此不展示output
cancer.keys() #查看主要的标签
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
为了确保尽可能易于理解和实现knn算法,只简单的引入以上三个包,然后导入数据。
用keys看看里面有啥重点?
在cancer数据集中,data是数据集中的数据部分(可以想象成excel表格中除了行和列的部分),target和target_names代表病人是否有癌症(0代表得了恶性癌症,1代表良性癌症),target就是我们使用data数据集预测的目标,feature_names代表数据集的列名称,也就是data每一列数据的列名称(总不能光有个数字不知道是啥吧)。
数据整理
为了方便操作,我们准备把cancer里面一坨东西转换为Pandas中的数据框。也方便一会对数据的操作。
In:
data = np.c_[cancer.data,cancer.target] #左右方向合并矩阵
columns = np.append(cancer.feature_names,'target')
df = pd.DataFrame(data,columns = columns)
df.head()
对于看不懂上面 np.c_[array1,array2] 的小伙伴我这里再做一个栗子,知道的可以跳过
In:
# np.c_[array1,array2]举例,看懂请跳过
a = np.array([[1,1,1],[1,1,1]])
print(' a\n',a)
b = np.array([[2,4,5],[6,7,8]])
print(' b\n',b)
print(' a和b合并\n',np.c_[a,b])
Out:
a
[[1 1 1]
[1 1 1]]
b
[[2 4 5]
[6 7 8]]
a和b合并
[[1 1 1 2 4 5]
[1 1 1 6 7 8]]
下图为df.head()的前五行
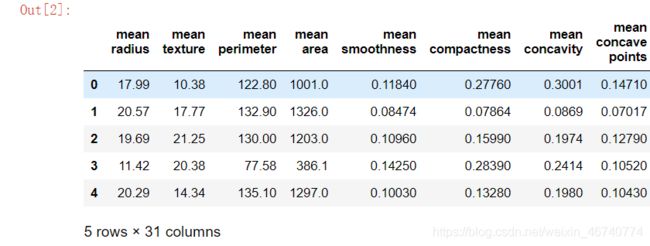
查看前五行看起来非常多,不过没关系,本文主要涉及KNN算法的实现,对数据的分布细节不深究。现在先来看看target中恶行和良性的数据分布(满足一下好奇心)。
In:
plt.figure(figsize = (3,3))
count = df.target.value_counts()
count.index = ('benign','malignant')
print(count)
plt.bar(count.index,count.values)
Out:
benign 357
malignant 212
Name: target, dtype: int64
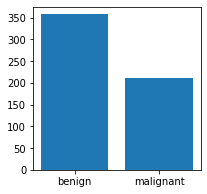
可以看到Target列中0(代表恶性malignant)的人数为212,1(代表良性benign)的人数为357。
划分数据集
现在要把数据中data 和target 拆分开来(虽然刚才把数据都拼在了一起),因为target这一列都是0和1的数字是我们其他30列数据data的预测目标。
X = df.iloc[:,0:30] #把前30列数据放入X
y = df.target # 这就是我们的target预测目标,现在把他孤立出来
现在准备进行伟大的机器学习。不过我们先得把数据划分为训练集和测试集,也就是把数据划分为train_set和test_set。使用训练集来训练和测试我们的KNN模型,然后用测试集代入模型来看看准确不准确。
from sklearn.datasets import load_breast_cancer
X_train, X_test, y_train,y_test = train_test_split(X,y,random_state=0)
#random_state = 0帮我们设置随机数种子,这样以后对于这个本是随机的步骤,
#你后来都可以得到同样的数据划分。
建立模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 1) #模型启动!
model = knn.fit(X_train,y_train) #拟合我们的训练集
现在模型建立完毕。为了满足再满足一下好奇心,我们可以康康若用全部数据的均值代入模型,我们的模型会给出什么结果(恶性或者良性)?
In:
#求数据均值
mean = X.mean().values
mean
Out:
array([1.41272917e+01, 1.92896485e+01, 9.19690334e+01, 6.54889104e+02,
9.63602812e-02, 1.04340984e-01, 8.87993158e-02, 4.89191459e-02,
1.81161863e-01, 6.27976098e-02, 4.05172056e-01, 1.21685343e+00,
2.86605923e+00, 4.03370791e+01, 7.04097891e-03, 2.54781388e-02,
3.18937163e-02, 1.17961371e-02, 2.05422988e-02, 3.79490387e-03,
1.62691898e+01, 2.56772232e+01, 1.07261213e+02, 8.80583128e+02,
1.32368594e-01, 2.54265044e-01, 2.72188483e-01, 1.14606223e-01,
2.90075571e-01, 8.39458172e-02])
现在代入数据:
In:
#来看看这位‘均值’病的重不重
model.predict(mean)
Out:
ValueError
in the future np.flexible dtypes will be handled like object dtypes
ValueError: Expected 2D array, got 1D array instead:
这里怎么出现了问题?可能是模型长度不匹配导致无法带入模型。机器学习过程中常常要注意模型的长度与你代入得数据长度是否匹配。刚在在创建模型的时候,我们代入模型的应该是一个个shape为(1,30)的数据。现在来看看我们均值矩阵的shape。
In:
mean.shape
Out:
(30,)
虽然不懂这个(30,)是个啥,但是和(1,30)长得不一样,这应该是出现问题的原因。现在再把这个矩阵reshape一下,让他变成(1,30)。
In:
mean = mean.reshape(1,-1)
mean.shape
Out:
(1, 30)
这里的reshape(1,-1)中,1代表把把一个矩阵变成一行,-1在列的位置上,这表示你是个懒鬼,不想亲自计算他有多少个列,把他交给计算机来算。
可以看到,矩阵的shape变成了期望中的(1,30),因此我们把这位‘均值哥’代入模型看看他病的重不重。
In:
model.predict(mean)
Out:
array([1.])
恭喜这位老哥,返回的矩阵1代表了这是良性肿瘤。
将测试集代入模型
代入完单个数据,现在准备代入我们之前划分出的测试集(X_test),预测结果,再使用(y_test)来看看我们的模型预测的结果是否准确。
score函数能帮我们看看预测的结果准确与否。
In:
model.predict(X_test)
Out:
array([1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 0., 0., 1.,
0., 0., 0., 0., 1., 1., 1., 0., 1., 1., 1., 1., 0., 1., 0., 1., 0.,
1., 0., 1., 0., 1., 0., 0., 1., 0., 1., 0., 0., 1., 1., 1., 0., 0.,
1., 0., 1., 1., 1., 1., 1., 1., 0., 0., 0., 1., 1., 0., 1., 0., 0.,
0., 1., 1., 0., 1., 1., 0., 1., 1., 1., 1., 1., 0., 0., 0., 1., 0.,
1., 1., 1., 0., 0., 1., 0., 1., 0., 1., 1., 0., 1., 1., 1., 1., 1.,
1., 1., 0., 1., 0., 1., 0., 1., 1., 0., 0., 1., 1., 1., 0., 1., 1.,
1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 1.,
1., 0., 0., 1., 1., 1., 0.])
In:
model.score(X_test,y_test)
Out:
0.916083916083916
我们得到了90+的准确率,准确率可谓是十分生猛。
补充
- 对于模型若使用不同的k值,会使得准确率发生什么变化?
- 在使用train_test_split()函数划分数据集时,若使用不同的比例划分训练集和测试集,结果会发生什么变化?
下面我们来试一下:
#对于不同的k值
k_range = range(1,20)
scores = []
k_value = []
for k in k_range:
model = KNeighborsClassifier(n_neighbors = k)
model.fit(X_train,y_train)
scores.append(model.score(X_test,y_test))
k_value.append(k) #准确率一一对应的K值
scores
数据可视化
plt.figure()
plt.scatter(k_range,scores)
plt.xlabel('k value')
plt.ylabel('Accuracy')
plt.title('Accuracy for different k_value')
plt.xticks([0,5,10,15,20]);
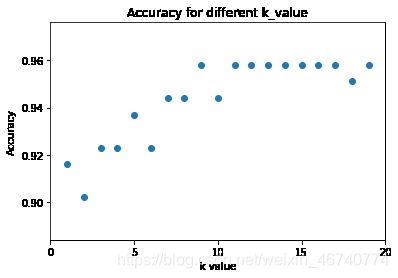
可以看出不同k值会导致的准确率对应的不一样。
- 划分训练集对结果的影响
#使用不同比例的划分训练集对结果的影响
proportion = [0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
model = KNeighborsClassifier(n_neighbors = 12)
socres = []
plt.figure()
for p in proportion:
scores = []
for i in range(1,100):
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 1-p)
model.fit(X_train,y_train)
scores.append(model.score(X_test,y_test))
plt.plot(p,np.mean(scores),'bo')
plt.xlabel('Train_set Proportion')
plt.ylabel('Accuuracy')
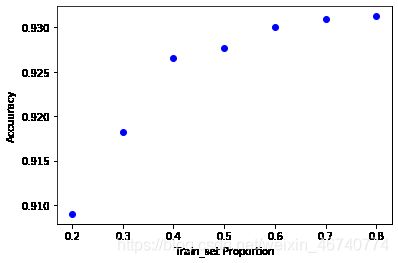
也可以看出,对训练集不同的划分也会导致准确率的不同的。
完
喜欢的小伙伴记得点赞收藏加关注~