女朋友哭着问我为什么她写的sql运行那么慢(一)
人世仙家本自殊,何须相见向中途。惊鸿瞥过游龙去,漫恼陈王一事无。
嗨,大家好,我是洛神,性别男。一个来自快乐星球的程序员。
欢迎大家专注我的公众号【程序员洛神】,我会不定期发放福利哟~
前言
这篇文章其实已经构思了蛮久的了,作为回归后的第一篇技术文,一直想找一个最合适的切入点。想来想去,这不正好赶上金三银四面试季嘛,温馨体贴的洛帅帅就决定写一篇关于Mysql优化的文章,而且数据库也可以说是当下企业最重视的方面了,相信正在面试的小伙伴们,也一定发现了,数据库在面试中提及的频率是相当高的,我也结合了很多我面试的总结和思考,希望能对各位小伙伴有一定的帮助。
背景
某个风和日丽的周末下午,洛帅帅正忧郁的坐在沙发上思考着下一周的划水摸鱼计划,和煦的阳光洒在他棱角分明的脸庞上,令人陶醉…突然,女朋友的房间里传来了哭声,作为一名暖男,当然第一时间冲了过去,女朋友看到洛帅帅后,一下子抱住了他,哽咽的说到:亲爱的,为什么我写的sql运行这么慢啊,你快帮我看看有什么问题呜呜呜~~

傻瓜,数据库的学问可多着呢,可不是简单的写个sql就行,一个好的数据库设计可以提升N+1倍的执行效率。有句老话说得好,学好数据库,走遍天下都不怕!来,今天让洛帅帅好好给你讲一讲。

正文
众所周知,数据库调优是一个复杂且漫长的过程,一个产品的研发过程中,数据库的优化是一直伴随的,随着业务量增加,数据库的优化方向也要不断调整。洛帅帅将从以下四个角度来唠一下女朋友写的sql到底该怎么优化!
- 数据库表结构优化
- SQL和索引优化
- 系统和MySQL配置优化
- 硬件设备优化
数据库表结构优化
首先说一下关于建表时要遵循的规范—三范式,它是所有开发人员都必须要遵循的规范。
第一范式(1NF)
每个表的每一列都要保持它的原子性,通俗的说就是每列只存储一项信息,不可细分。

该设计就违反了第一范式,因为"people"可以被细分为三个字段:名称、性别、年龄。
第二范式(2NF)
在满足第一范式的基础上,每个表都要保持唯一性,也就是说表的非主键字段要完全依赖主键字段

该设计就违反了第二范式,因为name和class都属于主键字段。应该将class和score拆出来,形成一个class表和score表,这样就保证了每个表的主键唯一性了。
第三范式(3NF)
表中不能产生传递依赖,要消除表中的冗余性(可以适当违反)
说到三范式,就不得不提一下反范式的概念:有时候为了提升运行效率,会适当的降低三范式要求,在表中冗余一些业务数据,比如订单表,关联物流表中的某个字段,这样我们就可以把这个字段冗余到订单表中,避免每次都要联表查询,提升查询效率。
数据库表结构的设计,仅仅遵循三范式是远远不够的,这只是设计的基础。还要结合实际的业务需求,一定要花大量的时间来设计表结构,避免开发过程中对表结构进行频繁修改。

表结构设计好了,接下来该考虑合适的表引擎了,来,洛帅帅手把手的教你
目前MySQL支持8种引擎,不过别担心,不需要你全记住,目前使用最广泛以及频率最高的,无非就是两种:InnoDB和MyISAM
简单说一下这两种引擎的区别:
1.InnoDB支持事务,支持崩溃后的安全恢复,MyISAM不支持(因为这个超牛的特性,MySQL的默认引擎从MyISAM变成了InnoDB)
2.InnoDB最小的锁粒度是行锁,MyISAM最小的锁粒度是表锁。也就是说MyISAM的一个update语句,就会锁住整张表,造成其他查询或更新的阻塞(注意一点:InnoDB的行锁是基于索引的,也就是说,如果访问的时候没有命中索引,那么就会退化为表锁了)
3.InnoDB支持外键,MyISAM不支持(如果一个InnoDB的表中有外键,那么将无法转换为MyISAM表)
4.InnoDB是聚集索引,MyISAM是非聚集索引。
5.InnoDB 表有自己的数据页管理,默认 16KB。MYISAM 表数据的管理依赖文件系统,比如文件系统一般默认 4KB,MYISAM 的块大小也是 4KB,MYISAM 表的没有自己的一套崩溃恢复机制,全部依赖于文件系统。
什么?看文字不够直接?洛帅帅作为一名暖男,怎么能不为你们考虑呢,来,上图
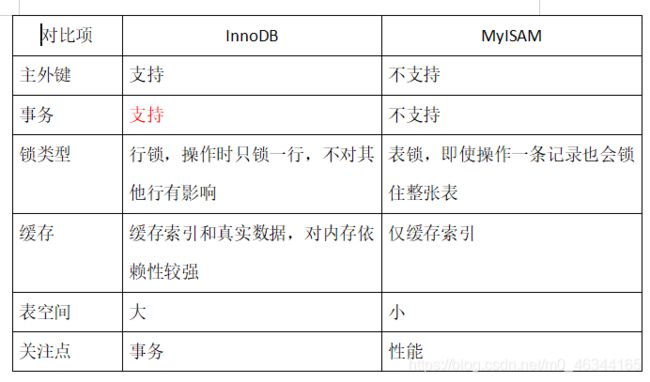
看完两种引擎的对比,我想大家心里对于什么时候用什么引擎,心里大概应该有数了。没错,当我们需要做业务处理(也就是牵扯到事务)的时候,肯定是要选择使用InnoDB的。如果有些数据是冷数据,或者说有些表只用来查询,我们就可以用MyISAM引擎存储。

例如博客系统中的文章、作者、标题等,查询次数多但是几乎不会修改,就可以将他们从业务表中拆出来,用MyISAM引擎的表存储,提升搜索效率。
而对于博客浏览量,回复数等更新较频繁的数据,可以使用InnoDB引擎,提升更新效率。
接下来我再给你讲一下这个分…
“等等!”,女朋友毫不留情的打断了洛帅帅水银泻地般流畅的思路:“亲爱的,刚才你讲得两个的引擎的区别,其中的聚集索引和非聚集索引是什么啊,我没记得用过这种索引呀~”

洛帅帅宠溺的摸了摸她的头:傻瓜,那我问你,每张业务表里你是不是都会设置个主键索引呀,这个主键索引,就是聚集索引啦(注意!主键索引≠聚集索引,只不过基于innoDB特性,每张表都会默认设置聚集索引,通常来说是主键,如果该表没有主键,会将该表的一个唯一非空索引设置为聚集索引。如果上面两个都不成立,那么innoDB内部会生成一个隐藏的主键作为聚集索引)。
所以说,聚集索引在一张表中只能有一个(但是可以包含多列),而且它的键值顺序决定了表数据行的物理存储顺序。聚簇索引对主键查询有很高的性能吗,不过它的二级索引(非主键索引)必须包含主键列。所以说如果主键列很大的话,索引也会变得很大。
再说非聚集索引,它就是普通的索引,一张表中可以有多个,它只是对表中列创建相应的索引,并不会像聚集索引那样影响整个表的物理存储顺序,这么说你明白了吧。
哦哦,原来是酱紫啊~亲爱的你真厉害! 对了,你刚才要跟我讲什么? 分? 分手??
呜呜呜~我就知道,长得帅的男人没有一个是好东西,何况还是你这么帅的!

咳咳,不能再往下说了,再夸洛帅帅该脸红了。回归正题,下面给大家讲一下优化杀手锏----分库分表
这其实是一个老生常谈的话题了,分库分表固然是一种优化数据库的很直接暴力的一种方式,但凡事都是有利有弊,分库分表后会带来许多的新问题,这都是需要在设计方案时考虑到的。
女朋友:可是人家就是想分库分表嘛!赶紧教教我啦!~~~
害,真是拿你没办法,谁让洛帅帅这么暖呢,乖,教你。
首先我们要知道为什么需要分库分表?
- 用户请求量太大
普通的主从模式已经无法支撑 - 单表数据量太大
MySQL官方建议每张表的最大数据量不超过600w。过大的数据量会造成索引膨胀,查询超时,最终形成性能瓶颈。 - 单库太大
单个数据库的处理并发数有限,一旦请求量提升,单库很难支撑。
好了,现在知道了为什么要分库分表,那么,如何进行分库分表呢,别急,且听洛帅帅慢慢道来…
垂直切分
垂直切分又分为垂直分库以及垂直分表。
垂直分表是指将一张表中的部分字段拆分出来形成另外一张表,这种做法通常发生在单表列数过多时,例如将订单表中的收货地址以及备注等大字段信息拆出来。这样做在某种意义上也能避免"跨页"的问题(MySQL底层的存储用的"数据页",跨页可能会带来额外的性能开销)。
垂直分库是指将数据库按照业务需求进行拆分,例如将原本的电商库拆分为了订单库和物流库,将不同的业务请求打到不同的库上。这样我们就可以对不同业务类型的数据进行分级管理、维护、监控、扩展。
这也是大型分布式系统中优化数据库架构的重要手段。
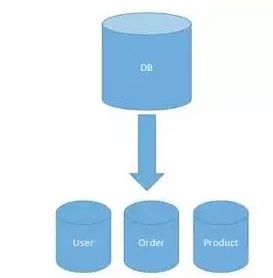
垂直切分缺点:
单表大数据量依然存在性能瓶颈。
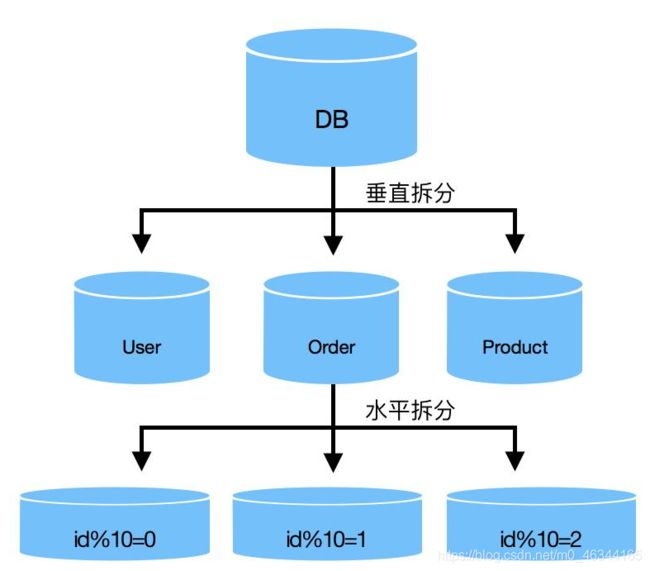
水平切分
同理,水平切分也分为水平分库和水平分表。
水平分表是指将一张数据量较大的表通过某种规则(hash、按照订单时间拆、按照用户id拆等等)拆分成多张表,这样查询数据的时候,只需要根据数据去查询特定的小表就可以了。
水分分库是在数据到一定的体量之后,单库无法承受如此高的数据,会按照规则将数据分到不同的库中,缓解单库处理数据压力。
PS:对于冷数据,我们也可以利用数据切分做冷热分离,冷数据用作数据分析,热数据用做业务处理。
缺点:
水平切分无法解决表与表之间的IO争夺。
从上面的叙述中可以知道,水平/垂直切分是各有利弊的,所以,现在企业中的做法一般都是采用水平+垂直切分的数据架构:垂直切分业务解耦,水平切分缓解单表压力。
“哇,原来分库分表的作用这么大啊,我现在就去把我们公司的数据库重新设计一下!”
傻瓜,先别着急,凡事都有利有弊,洛帅帅再给你讲一下分库分表后带来的问题:
- 分布式事务问题
只要是做了分库以后,无法避免的就是业界最头疼的分布式事务问题,同一个接口操作结果放在不同的库中,如何保证数据的一致性?这就要知道2PC 3PC TCC XA等相关的分布式事务概念(这个地方牵扯的东西比较多,
洛帅帅打算单独出一期来将这一块,在此不做详细说明) 分布式事务解决可以使用分布式事务框架例如TCC-Transcation等来解决。
- 跨库join的问题
分库后,就无法用join来连接不同库的表啦,原本一次就能查询出来的结果,可能要多次才能查询出来。如何解决?可以考虑将需要join的字段冗余在各个表中,尽量减少join的需求。也可以考虑在代码层做数据组装,先分别查出需要的各种业务数据,然后进行组装(比较麻烦)。
- 横向扩展问题
例如当我们使用hash取模来做分库分表的数据分配时,本来8个表,那我们就hash%8来分配数据,但是如果后期业务量加大,表需要扩展到16个,这个时候对16进行hash取模,原来的数据可能就无法通过hash%16定位到了,因为旧数据是用8做的分配。
如何解决?出现这种问题通常是因为切分前没有做好合理的规划,所以应当在分库分表前,根据业务当前以及预期数据量做好合理的容量规划,避免出现后期扩容以及迁移。
针对这个问题其实也可以考虑使用一致性hash做数据分配,它是利用hash环做的,扩容后也只会影响临近的数据点。感兴趣的话可以在下面评论,我后面专门出一期讲。
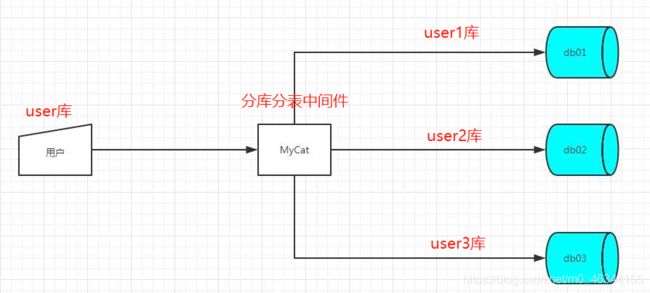
分库分表可以借助中间件来做,例如Sharding-JDBC或MyCat,网上的学习资源也很全,大家可以去边学边练,自己搭一个架子,切记,好记性不如烂笔头!
总结:
1.三范式 必须遵循的规范,但是在实际业务数据设计时,可以适当违反第三范式,做一些合适的字段冗余。例如订单表和物流表关联,除了在订单表中有物流表的ID之外,还可以冗余物流的状态列,这样就不用为了查一列去join整张表了。
2.表引擎选择 处理业务频繁当时是用InnoDB,但是对于冷数据,可以考虑使用MyISAM,查询快。
3.分库分表 分库分表方案是要谨慎选择的,要根据实际业务需求来设计,不要为了切分而切分,切忌过度优化和过度设计。
所以,个人推荐的数据库优化顺序:索引优化->SQL优化->表结构优化->读写分离->分库分表
好啦,说到这里,数据库的结构设计你大概明白了吧?
女朋友:嗯嗯!我大彻大悟了!亲爱的你真的太厉害了!剩下的明天再讲吧,你都这么辛苦了,快去去刷刷碗休息一下~
洛帅帅:???

结尾
首先声明这是一篇扫盲文,没有太过深入讲解,众所周知,这上面随便一个点拿出来,都是可以扯一篇文章的。
本来是想一口气把数据库优化怼完的,但是发现内容太多了,一篇文章太长了。所以我就把它按照模块拆分了一下,后面几天会把其他三部分内容怼出来(其实是为了多水几篇文章)。
人世仙家本自殊,何须相见向中途。惊鸿瞥过游龙去,漫恼陈王一事无。我是洛神,我们下期见。