爬虫项目可视化 centos7+python+echarts+flask
flask框架+echarts+mysql+centos7
根据 hxxjxw 原博客 实现与改进
项目完整代码
项目完整代代码github上面自行下载 完整代码
数据接口
腾讯新闻接口:
https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5
https://view.inews.qq.com/g2/getOnsInfo?name=disease_other
百度热搜:
https://voice.baidu.com/act/virussearch/virussearch?from=osari_map&tab=0&infomore=1
基于centos7上的mysql开发
centos7 mysql环境的搭建自行百度资源很多
centos7 python3安装:
转自 https://blog.csdn.net/hxxjxw/article/details/105336981
在数据库中建表存放数据
建表建库之前建议大家先设置一下数据库的编码,设置为utf-8不然后续插数据会出错,
修改Mysql编码格式:
show variables like ‘character%’;
set character_set_database=utf8;
对于已经存在的数据库和表格,修改:
修改数据库编码格式: Alter database 数据库名称 character set utf8 collate utf8_general_ci;
修改表编码格式: Alter table 表名称 convert to character set utf8;
查看数据库的编码格式: show create database 数据库名称;
转自 https://www.jianshu.com/p/eca83992983a
建表语句
创建6张表来分别存储国内历史数据,全球历史数据,国内当日数据,美国详细数据,百度热搜数据
建表语句如下:
CREATE TABLE `chinahistory` (
`ds` datetime NOT NULL COMMENT '日期',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(11) DEFAULT NULL COMMENT '当日新增确诊',
`suspect` int(11) DEFAULT NULL COMMENT '剩余疑似',
`suspect_add` int(11) DEFAULT NULL COMMENT '当日新增疑似',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`heal_add` int(11) DEFAULT NULL COMMENT '当日新增治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
`dead_add` int(11) DEFAULT NULL COMMENT '当日新增死亡',
PRIMARY KEY (`ds`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `globalhistory` (
`ds` datetime NOT NULL COMMENT '日期',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`newAddConfirm` int(11) DEFAULT NULL COMMENT '当日新增确诊',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
`confirm_add` int(11) DEFAULT NULL COMMENT '当日新增确诊',
`heal_add` int(11) DEFAULT NULL COMMENT '当日新增治愈',
`dead_add` int(11) DEFAULT NULL COMMENT '当日新增死亡',
PRIMARY KEY (`ds`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `details` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`update_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`province` varchar(50) DEFAULT NULL COMMENT '省',
`city` varchar(50) DEFAULT NULL COMMENT '市',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(11) DEFAULT NULL COMMENT '新增治愈',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `globaldata` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`update_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`name` varchar(50) DEFAULT NULL COMMENT '国家',
`continent` varchar(50) DEFAULT NULL COMMENT '州名',
`confirmAdd` int(11) DEFAULT NULL COMMENT '新增治愈',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`suspect` int(11) DEFAULT NULL COMMENT '治愈',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
`nowConfirm` int(11) DEFAULT NULL COMMENT '现存确诊',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `detailsusa` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`update_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`city` varchar(50) DEFAULT NULL COMMENT '城市',
`namemap` varchar(50) DEFAULT NULL COMMENT '英文名',
`confirm` int(11) DEFAULT NULL COMMENT '累计确诊',
`confirm_add` int(11) DEFAULT NULL COMMENT '新增治愈',
`heal` int(11) DEFAULT NULL COMMENT '累计治愈',
`dead` int(11) DEFAULT NULL COMMENT '累计死亡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `hotsearch` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dt` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`content` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
爬取数据
import requests
import json
import time
import pymysql
#from selenium.webdriver import Chrome,ChromeOptions
import traceback
import sys
#from selenium import webdriver
from lxml import etree
#返回历史数据和当日详细数据
def get_data():
#url来自腾讯:https://news.qq.com//zt2020/page/feiyan.htm ,F12找到js中Get方法的数据json的url
#国内当日新增
url1 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
#国内历史数据
url2 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_other"
#国外历史数据
url3 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_foreign"
#国外当日数据
url4 = "https://api.inews.qq.com/newsqa/v1/automation/foreign/country/ranklist"
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
r1 = requests.get(url1, headers)
time.sleep(1)
r2 = requests.get(url2, headers)
time.sleep(1)
r3 = requests.get(url3, headers)
time.sleep(1)
r4 = requests.get(url4, headers)
#json字符串转字典
r1 = json.loads(r1.text)
r2 = json.loads(r2.text)
r3 = json.loads(r3.text)
r4 = json.loads(r4.text)
#print(r1)
data_all1 = json.loads(r1["data"])
data_all2 = json.loads(r2["data"])
data_all3 = json.loads(r3["data"])
#print(data_all3['foreignList'][3])
#print(data_all3)
#print(data_all2["provinceCompare"]['上海'])
#print("-----"*30)
#print(data_all2["chinaDayList"])
#国内历史数据
chinahistory = {}
for i in data_all2["chinaDayList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
chinahistory[ds] = {"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all2["chinaDayAddList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #数据库datatime格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
chinahistory[ds].update({"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
#print(chinahistory)
#全球历史数据
globalhistory = {}
for i in data_all3["globalDailyHistory"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #数据库datatime格式
confirm = i["all"]["confirm"]
newAddConfirm = i["all"]["newAddConfirm"]
heal = i["all"]["heal"]
dead = i["all"]["dead"]
globalhistory[ds] = {"confirm": confirm, "newAddConfirm": newAddConfirm, "heal": heal, "dead": dead}
for i in data_all3["globalDailyHistory"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) #数据库datatime格式
confirm = i["all"]["confirm"]
newAddConfirm = i["all"]["newAddConfirm"]
heal = i["all"]["heal"]
dead = i["all"]["dead"]
globalhistory[ds].update({"confirm_add": confirm, "newAddConfirm": newAddConfirm, "heal_add": heal, "dead_add": dead})
#print(globalhistory)
#国内当日详细数据,这里默认为境外输入,当前编写时间为4月24日,主要来自境外
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"] #list 25个国家
data_province = data_country[0]["children"] #中国各省
for pro_infos in data_province:
province = pro_infos["name"] #省名
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
#print("国内每日数据"*10)
#print(details)
#美国各州当日详细数据
detailsusa = []
#update_time = data_all3["lastUpdateTime"] #此json里没有这个列
data_province = data_all3['foreignList'][0]['children']
for city_infos in data_province:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
update_time = time.strftime("%Y-%m-%d", tup) #数据库datatime格式
city = city_infos["name"]
namemap = city_infos["nameMap"]
confirm = city_infos["confirm"]
confirm_add = city_infos["confirmAdd"]
heal = city_infos["heal"]
dead = city_infos["dead"]
detailsusa.append([update_time,city,namemap, confirm, confirm_add, heal, dead])
#
#全球当日详细数据
globaldata = []
for i in r4["data"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
update_time = time.strftime("%Y-%m-%d", tup) #数据库datatime格式
name = i['name']
continent = i['continent']
confirmAdd = i['confirmAdd']
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
nowConfirm = i['nowConfirm']
globaldata.append([update_time,name,continent,confirmAdd,confirm,suspect,heal,dead,nowConfirm])
#print(globaldata)
return chinahistory,globalhistory,details,globaldata,detailsusa
def get_conn():
#建立连接
conn = pymysql.connect(host="", user="", password="", db="")#数据库的信息根据个人来填写,插入的数据有中文就要设置charset的编码格式
#创建游标
cursor = conn.cursor()
return conn,cursor
def close_conn(conn,cursor):
if cursor:
cursor.close()
if conn:
conn.close()
#插入detailsusa数据
def update_detailsusa():
cursor = None
conn = None
try:
li = get_data()[4] #返回的数据
conn,cursor = get_conn()
sql = "insert into detailsusa(update_time,city,namemap, confirm, confirm_add, heal, dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select %s=(select update_time from details order by id desc limit 1)" #对比当前最大时间戳
#对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新数据")
for item in li:
cursor.execute(sql,item)
conn.commit()
print(f"{time.asctime()}更新到最新数据")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#插入globaldata数据
def update_globaldata():
cursor = None
conn = None
try:
li = get_data()[3] #返回的数据
conn,cursor = get_conn()
sql = "insert into globaldata(update_time,name,continent,confirmAdd,confirm,suspect,heal,dead,nowConfirm) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select %s=(select update_time from details order by id desc limit 1)" #对比当前最大时间戳
#对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新数据")
for item in li:
cursor.execute(sql,item)
conn.commit()
print(f"{time.asctime()}更新到最新数据")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#插入details数据
def update_details():
cursor = None
conn = None
try:
li = get_data()[2] #返回的数据
conn,cursor = get_conn()
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select %s=(select update_time from details order by id desc limit 1)" #对比当前最大时间戳
#对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新数据")
for item in li:
cursor.execute(sql,item)
conn.commit()
print(f"{time.asctime()}更新到最新数据")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#插入chinahistory数据
def insert_chinahistory():
cursor = None
conn = None
try:
dic = get_data()[0] #0代表历史数据字典
print(f"{time.asctime()}开始插入历史数据")
conn,cursor = get_conn()
sql = "insert into chinahistory values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
for k,v in dic.items():
cursor.execute(sql,[k, v.get("confirm"),v.get("confirm_add"),v.get("suspect"),
v.get("suspect_add"),v.get("heal"),v.get("heal_add"),
v.get("dead"),v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#更新国内历史数据
def update_chinahistory():
cursor = None
conn = None
try:
dic = get_data()[0]#0代表历史数据字典
print(f"{time.asctime()}开始更新历史数据")
conn,cursor = get_conn()
sql = "insert into chinahistory values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from chinahistory where ds=%s"
for k,v in dic.items():
if not cursor.execute(sql_query,k):
cursor.execute(sql,[k, v.get("confirm"),v.get("confirm_add"),v.get("suspect"),
v.get("suspect_add"),v.get("heal"),v.get("heal_add"),
v.get("dead"),v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#插入globalhistory数据
def insert_globalhistory():
cursor = None
conn = None
try:
dic = get_data()[1] #0代表历史数据字典
print(f"{time.asctime()}开始插入历史数据")
conn,cursor = get_conn()
sql = "insert into globalhistory values (%s,%s,%s,%s,%s,%s,%s,%s)"
for k,v in dic.items():
cursor.execute(sql,[k, v.get("confirm"),v.get("newAddConfirm"),v.get("heal"),
v.get("dead"),v.get("confirm_add"),v.get("heal_add"),
v.get("dead_add")])
conn.commit()
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#更新全球历史数据
def update_globalhistory():
cursor = None
conn = None
try:
dic = get_data()[1] #代表历史数据字典
print(f"{time.asctime()}开始更新历史数据")
conn,cursor = get_conn()
sql = "insert into globalhistory values (%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from globalhistory where ds=%s"
for k,v in dic.items():
if not cursor.execute(sql_query,k):
cursor.execute(sql,[k, v.get("confirm"),v.get("newAddConfirm"),v.get("heal"),
v.get("dead"),v.get("confirm_add"),v.get("heal_add"),
v.get("dead_add")])
conn.commit()
#{"confirm": confirm, "newAddConfirm": newAddConfirm, "heal": heal, "dead": dead}
#{"confirm_add": confirm, "newAddConfirm": newAddConfirm, "heal_add": heal, "dead_add": dead}
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#返回百度疫情复工复课热搜
def get_baidu_hot():
#option = ChromeOptions() #创建谷歌浏览器实例
#option.add_argument("--headless")#隐藏浏览器
#option.add_argument("--no-sandbox") #禁用沙盘 部署在linux上访问chrome要求这样
#url = 'https://voice.baidu.com/act/virussearch/virussearch?from=osari_map&tab=0&infomore=1'
#brower = Chrome(options = option)
#brower.get(url)
#找到展开按钮
#driver_path = r"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe"
driver_path = r'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://voice.baidu.com/act/virussearch/virussearch?from=osari_map&tab=0&infomore=1')
#but = driver.find_element_by_xpath("//*[@id="ptab-0"]/div/div[1]/section/div") #定位到点击展开按钮
#but.click() #点击展开
time.sleep(2)#
c = driver.find_elements_by_xpath('//*[@id="ptab-0"]/div/div[2]/section/a/div/span[2]')
context = [i.text for i in c] #获取标签内容
# 关闭浏览器窗口
driver.close()
print(context)
return context
#将疫情复工复课热搜插入数据库
def update_hotsearch():
cursor = None
conn = None
try:
context = get_baidu_hot()
print(f"{time.asctime()}开始更新热搜数据")
conn, cursor = get_conn()
sql = "insert into hotsearch(dt,content) values(%s,%s)"
ts = time.strftime("%Y-%m-%d %X")
for i in context:
cursor.execute(sql,(ts,i)) #插入数据
conn.commit() #提交事务保存数据
print(f"{time.asctime()}数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
#清空表数据
def clean_table():
conn = pymysql.connect(host="47.115.148.142", user="root", password="hht*LSL520", db="yq", charset="utf8")
mycursor = conn.cursor()
sql1 = "truncate table chinahistory" ## 清空
sql2 = "truncate table details" ## 清空
sql3 = "truncate table detailsusa" ## 清空
sql4 = "truncate table globaldata" ## 清空
sql5 = "truncate table globalhistory" ## 清空
sql6 = "truncate table hotsearch" ## 清空
mycursor.execute(sql1)
mycursor.execute(sql2)
mycursor.execute(sql3)
mycursor.execute(sql4)
mycursor.execute(sql5)
mycursor.execute(sql6)
conn.commit()
conn.close()
print("清表操作完成......")
if __name__ == "__main__":
#get_data()
clean_table()
update_detailsusa()
update_globaldata()
update_details()
insert_chinahistory()
insert_globalhistory()
update_chinahistory()
update_globalhistory()
#在服务器端暂时不打开百度热搜,需要单独安装插件
update_hotsearch()
这个爬虫代码大家在本地测试好了之后就可以传到服务器上面然后设置自动爬虫了
下载pyecharm并创建一个flask项目
flask框架的具体使用这里我就不细说了,大家可以去b站搜一下
大家可以去github上面下载我的源码研究一下

这个就是最终的效果
将本地怕从以及flask项目部署到阿里云centos7服务器上
大家安装好了python3之后需要把flask里面以及爬虫代码里面需要用到的库给安装一下
pip3 install pymsql
pip3 install flask
pip install jieba
安装好了之后大家通过xshell或者filezilla将本地的爬虫代码和flask项目传到服务器上
设置定时启动爬虫
这里用到的是crontab服务来设置爬虫脚本自己启动
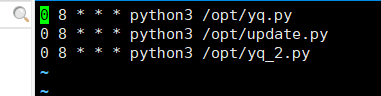
输入 :crontab -e
编辑这个文件:
例如我的: 0 8 * * * python3 /opt/yq.py
表示的就是每天早上8点钟自动执行 python3 /opt/yq.py这个命令
设置好之后保存退出即可,这样定时爬虫就设置好了
那么要想在服务器启动flask项目就需要进入app.py这个文件所在的路径:

在运行之前要在app.py的末尾添加一点东西

0.0.0.0运行所有人访问,8080设置任务的端口号
要进入到这个目录然后运行python3 app.py当然这样运行只是一个开发模式并不是一个生产模式
要想让程序一直挂在后台运行就需要nginx服务大家自行查一下