尚硅谷Flink入门到实战-学习笔记1
尚硅谷Flink入门到实战-学习笔记1
- 尚硅谷2021最新Java版Flink
1. Flink的特点
- 事件驱动(Event-driven)
- 基于流处理
一切皆由流组成,离线数据是有界的流;实时数据是一个没有界限的流。(有界流、无界流) - 分层API
越顶层越抽象,表达含义越简明,使用越方便
越底层越具体,表达能力越丰富,使用越灵活
1.1 Flink vs Spark Streaming
-
数据模型
-
Spark采用RDD模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合
-
flink基本数据模型是数据流,以及事件(Event)序列
-
运行时架构
-
spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
-
flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点处理
2. 快速上手
2.1 批处理实现WordCount
注意代码引用:
flink-streaming-scala_2.12 => org.apache.flink:flink-runtime_2.12:1.12.1 => com.typesafe.akka:akka-actor_2.12:2.5.21,akka就是用scala实现的。即使这里我们用java语言,还是用到了scala实现的包
目录结构:
pom依赖
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.4.3
com.atguigu
flink
0.0.1-SNAPSHOT
flink
Demo project for Spring Boot
8
8
1.12.1
2.12
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-scala_${scala.binary.version}
${flink.version}
org.apache.flink
flink-clients_${scala.binary.version}
${flink.version}
Java代码:
package com.atguigu.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class FlinkApplication {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
String inputPath = "F:\\视频学习\\ElasticSearch\\02-课程配套代码\\代码\\flink01\\src\\main\\resources\\hello.txt";
DataSet inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
// 按照第一个位置的word分组
// 按照第二个位置上的数据求和
DataSet> resultSet = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0)
.sum(1);
resultSet.print();
}
// 自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction> {
@Override
public void flatMap(String s, Collector> out) throws Exception {
// 按空格分词
String[] words = s.split(" ");
// 遍历所有word,包成二元组输出
for (String str : words) {
out.collect(new Tuple2<>(str, 1));
}
}
}
}
hello.txt 文件
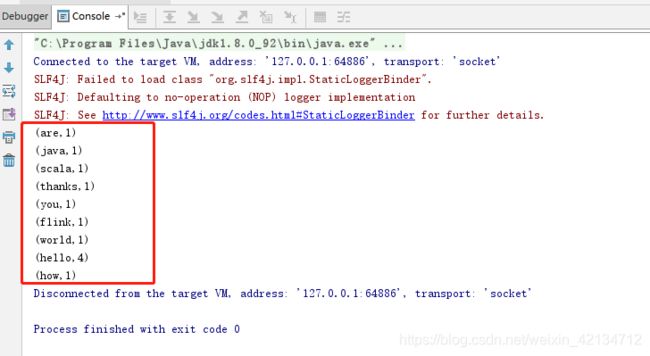
hello java
hello world
hello flink
hello scala
how are
thanks you
执行效果
注意代码引用jar问题
本人遇到的问题:
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
String inputPath = "F:\\视频学习\\ElasticSearch\\02-课程配套代码\\代码\\flink01\\src\\main\\resources\\hello.txt";
// 从文件中读取数据
DataSet inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
// 按照第一个位置的word分组
// 按照第二个位置上的数据求和
inputDataSet.flatMap(new MyFlatMapper()).groupBy(0).sum(1);
inputDataSet.print();
}
在代码编写过程中:
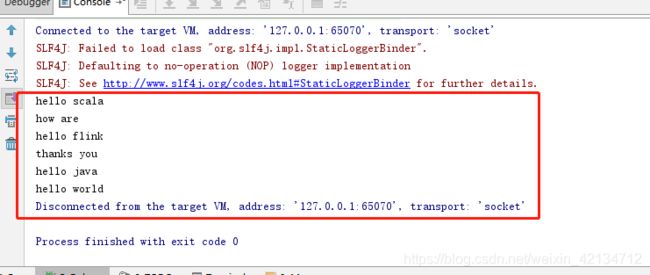
inputDataSet.flatMap(new MyFlatMapper()).groupBy(0).sum(1);
inputDataSet.print();
未对返回值进行指定数据接受集合就开始打印,出现效果如下:
第一讲结束 。
2.2 流处理实现WordCount
在2.1批处理的基础上,新建一个类进行改动。
-
批处理=>几组或所有数据到达后才处理;流处理=>有数据来就直接处理,不等数据堆叠到一定数量级
-
这里不像批处理有groupBy => 所有数据统一处理,而是用流处理的keyBy =>
每一个数据都对key进行hash计算,进行类似分区的操作,来一个数据就处理一次,所有中间过程都有输出! -
并行度:开发环境的并行度默认就是计算机的CPU逻辑核数
在代码中FlinkApplicationTwo 对代码进行修改:
package com.atguigu.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.client.program.StreamContextEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkApplicationTwo {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamContextEnvironment.getExecutionEnvironment();
// 设置并行度,默认值 = 当前计算机的CPU逻辑核数(设置成1即单线程处理)
// env.setMaxParallelism(32);
// 从文件中读取数据
String inputPath = "F:\\视频学习\\ElasticSearch\\02-课程配套代码\\代码\\flink01\\src\\main\\resources\\hello.txt";
DataStream inputDataStream = env.readTextFile(inputPath);
// 基于数据流进行转换计算
DataStream> resultStream = inputDataStream.flatMap(new FlinkApplication.MyFlatMapper())
.keyBy(item->item.f0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
}
这里env.execute();之前的代码,可以理解为是在定义任务,只有执行env.execute()后,Flink才把前面的代码片段当作一个任务整体(每个线程根据这个任务操作,并行处理流数据)。
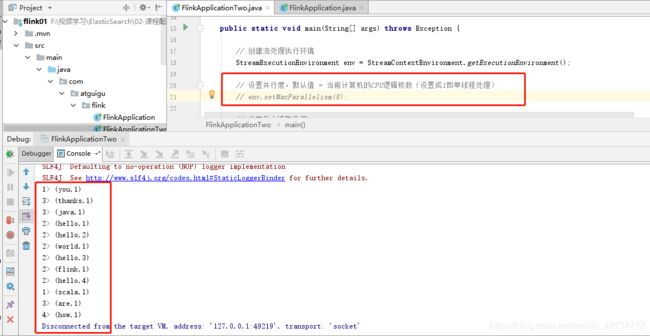
输出: 执行效果如下
竖着的前缀–>对应本人电脑为几核的处理器 (1、2、3、4)
遗留疑问:
1、视频上说 设置以下代码 可以变更系统环境,本人执行发现没有效果;
// 设置并行度,默认值 = 当前计算机的CPU逻辑核数(设置成1即单线程处理)
// env.setMaxParallelism(8);
2、变更条件为2时,出现一下错误;
// 设置并行度,默认值 = 当前计算机的CPU逻辑核数(设置成1即单线程处理)
// env.setMaxParallelism(2);
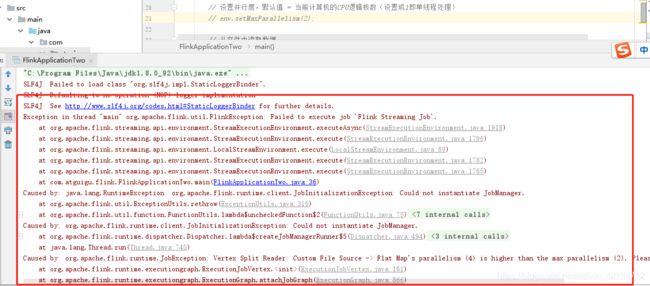
上述代码 对应视频路径:
https://www.bilibili.com/video/BV1qy4y1q728?p=8&spm_id_from=pageDriver
2.3 流式数据源测试
1.通过nc -lk 打开一个socket服务,用于模拟实时的流数据
nc -lk 7777
2.代码修改inputStream的部分
学习视频中 讲解老师自己配置的服务器用于接受输入数据,我没有进行测试;只保留了视频截图用作参考。
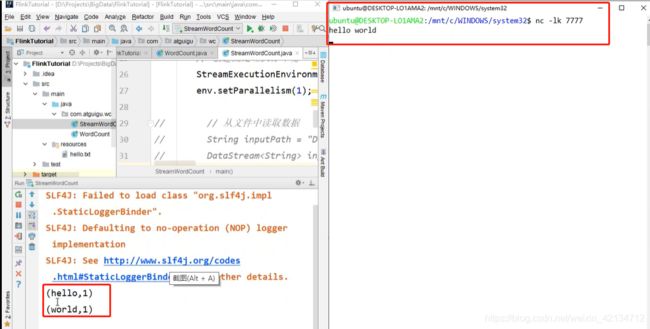
对应代码:
package com.atguigu.flink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.client.program.StreamContextEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamContextEnvironment.getExecutionEnvironment();
// 设置并行度,默认值 = 当前计算机的CPU逻辑核数(设置成1即单线程处理)
// env.setMaxParallelism(32);
// 从文件中读取数据
// String inputPath = "/tmp/Flink_Tutorial/src/main/resources/hello.txt";
// DataStream inputDataStream = env.readTextFile(inputPath);
// 从socket文本流读取数据
DataStream inputDataStream = env.socketTextStream("localhost", 7777);
// 基于数据流进行转换计算
DataStream> resultStream = inputDataStream.flatMap(new FlinkApplication.MyFlatMapper())
.keyBy(item->item.f0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
}
代码对应转换
方式一:
// 从socket文本流读取数据
DataStream inputDataStream = env.socketTextStream("localhost", 7777);
方式二:
// 用parameter tool 工具从程序启动参数中提取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
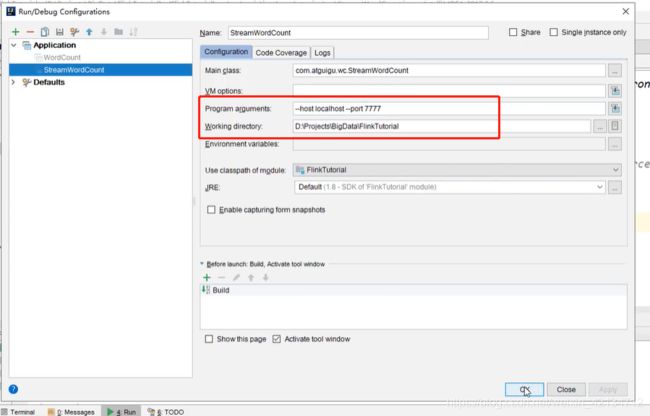
https://www.bilibili.com/video/BV1qy4y1q728?p=9&spm_id_from=pageDriver
本文参考网址:
https://ashiamd.github.io/docsify-notes/#/study/BigData/Flink/%E5%B0%9A%E7%A1%85%E8%B0%B7Flink%E5%85%A5%E9%97%A8%E5%88%B0%E5%AE%9E%E6%88%98-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0
如有侵权请联系删除!!!