MYSQL数据库原理与应用-个人总结(上)
序言
此复习为个人整理的有关MySql的复习,大量知识点来自老师上课复习、个人总结、以及部分网上资料,以便能够提供给自己复习时的内容。此资料含有大量的执行语句,并且每一条都是自己亲自试验,只得没问题之后才敢放上来,但不免有疏忽的地方,欢迎指出。
第一章 数据库概述
(一) 数据库概述
数据库(DataBase,DB): 数据库是指可永久存储在计算机内、有组织、可共享的大量数据的集合
**关键词:可永久存储、有组织、可共享
数据库管理系统(DBMS):安装在操作系统之上,是一个管理、控制数据库中各种数据库对象的系统软件。
DBMS常用的数学模型有: 层次模型、网状模型、关系模型、面向对象模型,其中关系数据库管理系统已占据主导地位。
数据库系统(DBS): 是指计算机引入数据库后的系统,它能够有组织、动态地存储大量的数据、提供数据处理和数据共享机制。
组成: 一般由硬件系统、软件系统、数据库和人员组成。
DBMS主要功能:
- 提供了数据定义语言(Data Definition Language ,DDL),用户可以通过这种语言来定义数据库中的表结构。
- 提供了数据操作语言(Data manipulation Language , DML),用户可以对数据库 进行基本的操作,如增删改查。
(二) 数据库系统之间的关系
这里简单使用一张图表示。
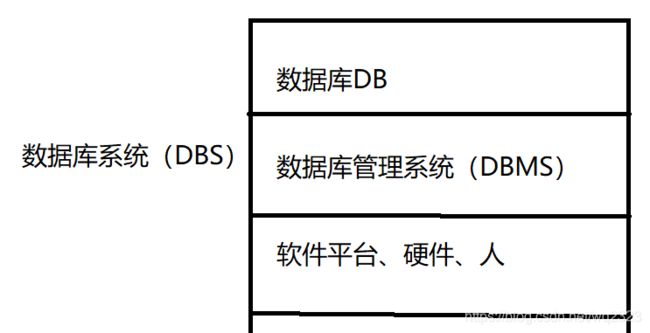
通俗的说,数据库系统包含了DBMS、数据库、软件平台与硬件支持环境以及各类人员。
而DBMS与数据库的关系:DBMS是管理数据库的
(三) 数据库管理系统的发展
三个阶段:
- 人工管理阶段
- 文件系统管理
- 数据库系统管理
(四) 数据库系统结构
数据库通常的体系结构都具有相同的特征,即采用三级模式结构、并提供两级映射。
三级模式:外模式、模式、内模式。
外模式:是数据库用户所见和使用的局部数据的逻辑结构和特征的描述,是用户所用的数据库结构。一个数据库可以有多个外模式
模式:是数据库中全体数据的逻辑结构的特征的描述。一个数据库只有一个模式
内模式:是数据物理结构和存储方法的描述。一个数据库只有一个内模式
数据库系统提醒结构:
1.客户/服务器的结构(C/S)结构,特点就是需要安装,如电脑中的qq、微信就是使用这种结构。
2.浏览器/服务器结构(B/S)结构,只要电脑联网,安装了浏览器就能访问各种web网站。
C为客户端,指的是Client、S为服务器,Server,B为浏览器,Browser
第二章 信息与数据模型
(一) 数据模型与三层抽象描述
数据模型:它是对现实世界中数据特征及数据之间联系的抽象。
数据处理三层抽象:
1.概念层:是数据抽象的最高级别,按照用户的观点来对现实世界进行建模。
概念层的数据模型称为概念数据模型,简称概念模型。常用的概念模型有:实体-联系模型(Entity-Relationship model,E-R模型)
2.逻辑层:中间层,是描述数据库数据整体的逻辑结构。
此层数据抽象称为逻辑数据模型,简称数据模型,常见的数据模型有:层次模型、网状模型、关系模型、面向对象模型
3.物理层: 是数据抽象的最底层,用来描述数据物理存储结构和存储方法。
考: 将E-R概念模型转换为关系数据模型
(二) 概念模型
基本概念:
- 实体(Entity): 客观存在并能互相区别的事物称为实体
- 属性(Attribute): 实体所具有的某一特效称为属性,如学生具有学号、姓名等属性。
- 实体型(Entity Type): 用实体类型名和所有属性来共同表示同一类实体,比如学生(学号、姓名)
- 实体集(Entity Set): 同一类型的实体集合,如全体学生
- 码(Key): 用来唯一标识一个实体的属性集,如学号
- 域(Domain): 实体中属性的取值范围
- 联系(Relationship): 实体之间的联系
E—R模型
实体的三要素:实体、属性、联系
实体间的联系:一对一(1:1)、一对多(1:n)、多对多(n:m)
补充:
在1:n的关系中,1的一方称为主表,n的一方称为从表,所以在设计表结构的时候,需要在n的一方加上1的一方的主键 作为外键。
(三) 关系模型
1.关系中的基本术语:
元组:即记录,在关系表中对应某一行,组成元组的元素称为分量;也就是说,二维表中的某一行,就是一个元组,而某一行中的所有属性称为分量。
属性:在二维表中,给每一列命名,这个命名就称为属性。
候选码 : 若关系中的某一属性和属性组能够唯一地标识一个元组,就称为该属性为候选码。
**主码:**在众多候选码中,选定其中一个为主码(也称为主键)
(四) 关系的完整性
关系模型允许定义3类完整性约束: 实体完整性、参照完整性、用户自定义完整性
实体完整性:
若属性A是基本关系R中的主属性,则属性A不能取空值。简单理解就是,主键不能为空,因为为空了就无法唯一标识这一行记录了。
参照完整性:
两张表,一个学生表(学号、姓名、系编号),一个系别表(系编号、系部名称)。
简单看,学生的系别信息是从系别表中查询的,所以就需要有外键联系——系编号。那么就有一个限制了,就是我学生表中的系编号,只能取自系别表,不能取什么部门表、用户表等等,只能是来自系别表中的字段。
也就是说,需要参照的系编号有两种选择:一是取空,二是取来自系编号表中的数据。
第三章 关系代数和关系数据理论
暂略
第四章 数据库的设计方法
(一) 数据库设计的阶段
按照规范设计的方法,同时考虑数据库及其应用系统开发的全过程,可以将数据库设计分为6个阶段:需求分析、概念结构设计、逻辑结构设计、物理结构设计、数据库实施以及数据库运行与维护
- 需求分析
- 概念结构设计:通常使用E-R图进行刻画
- 逻辑结构设计:将E-R模型转换为关系数据模型
- 物理结构设计:是存储设备上的存储结构、存储方法。
- 数据库实施阶段
- 数据库运行与维护
(二) 概念结构设计的方法和步骤
概念结构的设计方法有4种:
- 自定向下方法:根据用户要求,先定义全局概念结构的框架,然后分层开展,逐步细化。
- 自定向上方法:先定义各局部应用的概念结构,然后将它们集合起来,得到全局的概念结构。
- 逐步扩张方法:核心是先定义核心概念结构,然后向外扩张。
- 混合策略方法
概念结构设计的步骤:
- 进行局部数据抽象,设计局部概念模式
- 将局部概念模式综合称为全局概念模式
- 评审
采用E-R模型设计概念结构的方法:
- 分类
- 概况
- 聚集
第五章 MySQL的安装和使用
本章开始会涉及到大量的操作,这里主要记录的是相关的cmd命令,所以操作方面会记录的非常少,如果你对MySQL的安装有问题,可以参考PDF文档,里面有非常详细的介绍。
链接:https://pan.baidu.com/s/1ZH25aLuEnhTde_dzaqh5fA 提取码:ljz5
(一) MySQL安装
MySQl目前流行的版本为5.7,你可以通过以下地址下载:
链接:https://pan.baidu.com/s/1vLIJyjrVjyv05NtdneCeeQ 提取码:7n5x
如果需要借助MySql的图形化管理工具Navicat,你可以按照以下地址下载:
链接:https://pan.baidu.com/s/1utCjmIVyPc3iavQtI_UKVQ 提取码:sur7
因为目前许多后端的开发基本都是基于MYSQL5.5-5.7之间的版本,建议不要盲目升级mysql8,以免在日后学习当中产生许多难以避免的BUG。
(二) 常用命令DOS
启动MySQL服务
net start mysql57 # 此处mysql57特指你自己机器上mysql服务的名称
关闭MySQL服务
net stop mysql57 # 此处mysql57特指你自己机器上mysql服务的名称
注:如果登录时提示mysql不是内部或外部命令,则说明你的mysql环境变量没有配置好,需要配置一下环境
连接MySQL服务器
mysql -u登录名 -h服务器地址 -p密码
#如为本机,可以不写 -h服务器地址
#例
mysql -uroot -proot
断开MySQL服务器
quit
#或
exit
第六章 MySQL的存储引擎和数据库操作管理
(一) 数据库存储引擎
概念:数据库存储引起是数据库底层软件组件,DBMS使用数据引擎进行创建、查询、更新删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平。
即:存储引擎实际上就是数据库如何存储数据、如何为存储的数据建立索引和如何更新、查询数据的机制。
MySQL数据库常用的存储引擎有InnoDB和MyISAM
(二) InnoDB存储引擎
在MySQL5.5.5之后,默认选择InnoDB作为存储引擎:
- InnoDB提供了事务能力,即完整的提交、回滚、崩溃回复能力的事物安全。
- InnoDB为处理巨大数据量提供最大性能而设计的。(性能不及MyISAM)
- InnoDB支持外键完整性约束(Foreign key)
(三) MyISAM存储引擎
- 不支持事务能力,所以安全性不足。
- 与InnoDB相比,速度非常快,适用于小型网站使用。
(四) MEMORY存储引擎
这种存储引擎是将表中的数据存储在内存当中的,存储的速度非常快,但是当断电或宕机时表中的数据就会消失。它适用于存储临时数据的临时表。
- 默认使用Hash(哈希)索引
- 速度比B+树索引更快。
(五) MERGE存储引擎
MERGE是一组MyISAM表的集合,这些MyISAM表结构必须完全相同,MERGE本身没有任何数据,对MERGE的增删改查操作实际上就是对内部的MyISAM进行操作的。
(六) 不同存储引擎的选择
InnoDB:适用于需要事务支持、行级锁定,对高并发有很好的适用能力,但是需要确保查询是通过索引完成的,数据更新较为频繁。抓住关键词:事务支持
MyISAM:适用于不需要事务支持、并发相对低、数据修改少、以读为主,对数据要求一致不是非常高。
MEMORY:适用于追求很快的读写 能力,对数据安全性要求很低的场景。
第七-八章 MySQL的操作
本章开始主要是相关的语法操作,方便自己的复习。其中,SQL语句是非常重要的部分,整个章节都是围绕SQL语句比编写。
此处的知识是结合网上资料、课本上的知识,外加自己的理解而整理的,主要内容是SQL的概念、有条理的复习如何操作数据库、个人总结等内容,希望这样能够帮助大家复习吧。
(一) 结构化语句
Structured Query Language 结构化查询语言,简称SQL。我们平时使用的各种语句对数据库的操作,其实就是SQL语句,因为MYSQL是支持SQL语句的。
作用:
- 是一种所有关系型数据库的查询规范,不同的数据库都支持。
- 通用的数据库操作语言,可以用在不同的数据库中。
- 不同的数据库 SQL 语句有一些区别
SQL 语句分类
- Data Definition Language (DDL 数据定义语言) 如:建库,建表
- Data Manipulation Language(DML 数据操纵语言),如:对表中的记录操作增删改
- Data Query Language(DQL 数据查询语言),如:对表中的查询操作
- Data Control Language(DCL 数据控制语言),如:对用户权限的设置
MySQL 的语法
- 每条语句以分号结尾,如果在 SQLyog 或者Navicat当中不是必须加的。
- SQL 中不区分大小写,关键字中认为大写和小写是一样的
- 3 种注释:
# 我是MYSQL中独特的注释方法
/*我是多行注释 */
-- 空格
(二) DDL语句操作数据库
主要围绕增删改查,相关的数据库的名称为palewl
创建数据库
create database 数据库名称"=; -- 注意是database 不是databases
-- 例
CREATE DATABASE palewl;
创建数据库之前判断数据库是否存在,不存在就执行创建
create database if not exists 数据库名称 ;
-- 例
CREATE DATABASE IF NOT EXISTS palewl;
创建数据库,并指定字符集,如为utf8
create database 数据库名称 character set utf8
-- 例
CREATE DATABASE palewl CHARACTER SET utf8;;
查询数据库
SHOW DATABASES; -- 注意是DATABASES,后面有s
技巧补充: 在输入相关的关键字时,可以按Tab键自动补充
修改数据库
-- 修改palewl中字符集为gbk
ALTER DATABASE palewl DEFAULT CHARACTER SET gbk;
删除数据库
DROP DATABAS 数据库名称;
-- 例
DROP DATABASE palewl;
使用某个数据库
use 数据库名称;
-- 例
use palewl;
总结:
其实可以发现规律很统一,创建就用CREATE,修改用ALTER,删除就用DROP
(三) DDL语句操作数据表
创建表
create table 表名(
字段名1 字段类型1,
字段名2 字段类型2,
)
-- 注意是(),不是大括号{}
MYSQL中的字段类型有挺多,这里截个图:
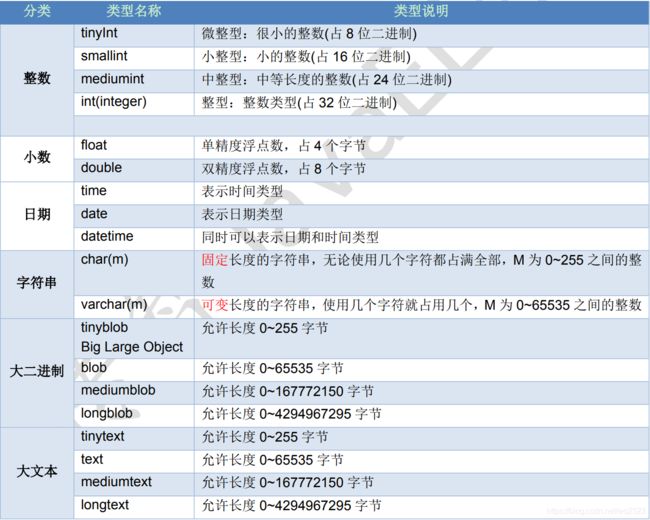
其中,常用的就是int/varchar/double/date
具体操作:在创建了一个叫palewl的数据库,创建一个表user,有id,NAME,birthday这些字段
CREATE TABLE USER(
id INT,
NAME VARCHAR(20),
birthday DATE
)
查看数据库里面的表
show tables
查看表结构
DESC 表名
查看创建某个表所用的DDL语句
show create table 表名;
创建一个表结构相似的表
create table 新表名 like 旧表名;
-- 例
CREATE TABLE l_user LIKE USER;
修改表名称
RENAME TABLE 表名 TO 新表名;
-- 例 将user表名改为tb_user
RENAME TABLE user TO tb_user;
删除表
drop table 表名;
-- 例
DROP TABLE USER;
创建表之前判断表是否存在,存在就删除
DROP TABLE IF EXISTS "表名";
-- 例
DROP TABLE IF EXISTS USER;
新增表中字段
ALTER TABLE 表名 ADD 字段名 字段类型;
-- 如在user表中新增一个字段remark,类型为VARCHAR(50);
ALTER TABLE USER ADD remark VARCHAR(50);
修改表中某个字段类型
ALTER TABLE 表名 MODIFY 列名 新的类型;
-- 如在user表中将字段remark类型改为VARCHAR(100);
ALTER TABLE USER MODIFY remark VARCHAR(100);
修改表中字段名称
ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
-- 如在user表中将字段remark字段改为nickName;
alter table user change remark nickName varchar(50);
删除表中的某列
ALTER TABLE 表名 DROP 列名
-- 如在user表中将字段nickName删除
ALTER TABLE USER DROP nickName;
字段约束:
MySQL支持7种外键约束:主键约束(PRIMARY KEY)、外键约束(FOREIGN KEY),非空约束(NOT NULL)、唯一性约束(UNIQUE)、默认值约束(DEFAULT)、自增约束(AUTO_INCREMENT)、检查约束
--创建一个t_user表
CREATE TABLE t_user (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(25),
score INT NOT NULL,
TYPE VARCHAR(25) UNIQUE,
flag VARCHAR(20) DEFAULT 60
)
- PRIMARY KEY 指的是主键约束
- AUTO_INCREMENT 主键id自增
- NOT NULL 非空约束
- UNIQUE 唯一性约束
- DEFAULT 60 默认值约束,令flag的默认值为60
给已经创建好的表增加主键约束
ALTER TABLE USER ADD PRIMARY KEY(id);
-- USER 为表名 id为需要设为主键的字段
修改user表的主键,删除原来的主键,增加id为主键
ALTER TABLE USER DROP PRIMARY KEY, ADD PRIMARY KEY(id);
在user表中给name增加非空验证、唯一性验证
ALTER TABLE USER MODIFY NAME VARCHAR(20) NOT NULL UNIQUE;
--注意此处的关键字为
(四) DML 操作表中的数据
操作表的数据,其实就是对某个表中的数据进行增删改,注意没有查
插入一条记录
--所有的字段名都写出来
insert into 表名(字段1,字段2,字段3) values(字段1,字段2,字段3)
--不写字段名
insert into 表名 values(字段1,字段2,字段3)
--例 向user表插入一条记录
INSERT INTO USER(id,NAME,birthday) VALUES("1","小红","2000-12-20");
INSERT INTO USER VALUES("1","小红","2000-12-20");
更新一条记录
update 表名 set 字段1= ?,字段2= ?, where id = ?
--此处?表示占位符,无实际意义。
--例 在用户表中,将id为1的用户名修改为小蓝
UPDATE USER SET NAME="小蓝" WHERE id=1;
删除一条记录
delete from 表名 where id = ?
--此处?表示占位符,无实际意义。
--例 在用户表中,将id为1的记录删除
DELETE FROM USER WHERE id=1;
当然,以上的例子是最为常用的,实际上使用还有别的方式,因为使用的相对少,所以没有举例出来。
为什么需要where ?
where在此处的意思是条件的意思,比如:
//我要更新或删除某一条记录,我就得知道这条记录的唯一标识(一般为id),这样才能准确定位。
(五) DQL 查询表中的数据
在众多语句当中,其实查询是相对复杂的,也是能玩出花样特别多的,所以这里尽量总结的完善,使用相关的例子来举例。
查询不会对原有的数据造成影响,只是一种数据的展现形式。
基本格式:
SELECT * FROM 表名 where [条件]
- SELECT表示查询语句
- *标识为通配符,SELECT 语句会返回表的所有字段数据
- where 表示查询的条件
为了讲解,导入user表,有三个字段。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`birthday` date DEFAULT NULL,
`score` int(10) DEFAULT NULL,
`type` varchar(225) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
/*Data for the table `user` */
insert into `user`(`id`,`name`,`birthday`,`score`,`type`) values (1,'李东来','2020-12-23',50,'数科院'),(2,'张无忌','2020-12-23',30,'天龙院'),(3,'冯森','2020-12-21',60,'数科院'),(4,'机械','2020-12-23',80,'数科院'),(5,'萧峰','2020-12-19',90,'天龙院');
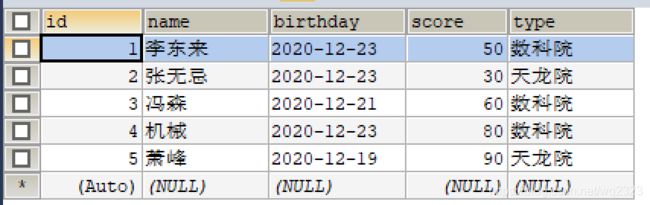
查询所有
SELECT *FROM USER;
根据ID查询,如查询id为1的信息
SELECT *FROM USER WHERE id = '1';
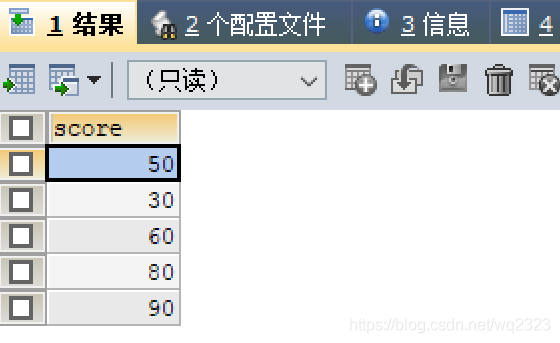
查询单个字段,如查询user表中的score成绩。
SELECT score FROM USER;
起别名,在查询单个字段的同时起个别名.如查询score,并给它取别名为 “成绩”
SELECT score AS "成绩" FROM USER;
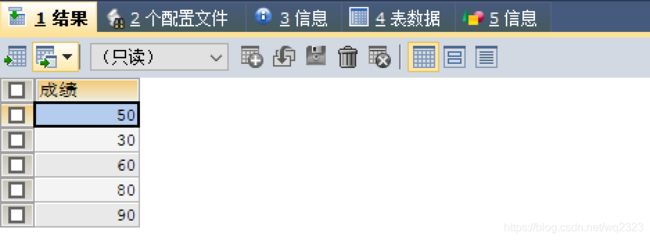
使用别名的好处: 显示的时候使用新的名字,并不修改表的结构。
-- 格式: SELECT 字段名 1 AS 别名, 字段名 2 AS 别名... FROM 表名;
-- 例 给表中的字段加上别名
SELECT NAME AS “姓名”,birthday AS “出生日”,score AS “成绩”,TYPE AS "类型" FROM USER;
查询结果参与运算 给查询的成绩+5分
SELECT score+5 AS '成绩' FROM USER;
避免重复数据查询user表的score字段–使用DISTINCT关键字
SELECT DISTINCT score FROM USER;
(六) DQL 条件查询
条件查询的意思是对查询的内容进行筛选,从而获得自己需要的信息.
格式:
SELECT 字段名 FROM 表名 WHERE 条件;
MYSQL中常用的运算符:
| >、<、<=、>=、=、<> | <>在 SQL 中表示不等于,在 mysql 中也可以使用!= , 没有== |
|---|---|
| BETWEEN…AND | 在一个范围之内,如:between 100 and 200相当于条件在 100 到 200 之间,包头又包尾 |
| IN(集合) | 集合表示多个值,使用逗号分隔 |
| LIKE ‘%连%’ | 模糊查询 |
| IS NULL | 查询某一列为 NULL 的值,注:不能写=NULL |
具体实例:
SELECT *FROM USER WHERE score>80; -- 查询成绩大于80的记录
SELECT *FROM USER WHERE score<=80 AND score>=60; -- 查询成绩大于等于60小于等于80的数据
SELECT *FROM USER WHERE score BETWEEN 60 AND 80; --查询成绩在于60到80的记录(包括60/80)
使用IN关键字查询
IN关键字可以判断某个字段的值是否在某个指定的集合当中,如果字段的值在集合中,就满足查询条件
-- 查询成绩为50/60/80的数据。注意,不是50-80这个范围,而是成绩等于50/60/80的数据
SELECT *FROM USER WHERE score IN(50,60,80);
使用LIKE关键字查询
“%” 可以代表任意长度的字符串,长度可以是0.
“_” 只能表示单个字符
-- 使用LIKE关键字查询姓名当中含有“张”的数据(模糊查询)
SELECT *FROM USER WHERE NAME LIKE "%张%";
-- 使用LIKE关键字查询姓名中以冯开头二字姓名。如 冯森,冯后仅接一个字
SELECT *FROM USER WHERE NAME LIKE "冯_";
分组查询:使用关键字 GROUP BY
-- 查询user表,对学生内的type进行分组
SELECT * FROM USER GROUP BY TYPE;
对查询结果排序:使用关键字ORDER BY
DESC为倒序,ASC为升序
-- 对查询的结果按成绩进行倒序
SELECT *FROM USER ORDER BY score DESC;
限制查询结果数量:使用关键字LIMIT
可做分页
-- 查询从第2名用户开始的3名学生信息
SELECT *FROM USER LIMIT 2,3;
聚合函数
--使用count函数统计user表中的记录
SELECT COUNT(*) AS "总记录" FROM USER;
-- 使用COUNT函数统计user表中不同的name值,并与GROUP BY关键字一起使用
SELECT TYPE,COUNT(*) AS "总记录" FROM USER GROUP BY TYPE;
-- 使用SUM函数统计不同院系的总成绩
SELECT SUM(score) '总成绩' ,TYPE FROM USER GROUP BY TYPE;
-- 使用AVG函数计算不同院系的平均分
SELECT AVG(score) AS "平均分" ,TYPE FROM USER GROUP BY TYPE;
-- 使用MAX函数计算user表最分数最高的
SELECT MAX(score) AS "最大值" FROM USER;
-- 使用MIN函数计算user表最分数最低的
SELECT MIN(score) AS "最小值" FROM USER;
(七) 多表查询
表之间的关系:
| 关系 | 说明 |
|---|---|
| 一对一 | 通过主外键连接 |
| 多对多 | 需要中间表,中间表对其余两表的关系为多对一 |
| 一对多 | 通过主外键连接,需要在多的一方增加一的一方的外键。 |
三范式
- 第一范式:原子不可再分
- 第二范式:不产生局部依赖,表中的记录完全依赖唯一标识的主键
- 第三范式:不产生传递关系,表中的每一列都直接依赖于主键。
准备一张部门表dept 和员工表emp
CREATE TABLE `dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
insert into `dept`(`id`,`name`) values (1,'开发部'),(2,'市场部'),(3,'财务部'),(4,'销售部');
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`salary` double DEFAULT NULL,
`join_date` date DEFAULT NULL,
`dept_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `dept_id` (`dept_id`),
CONSTRAINT `emp_ibfk_1` FOREIGN KEY (`dept_id`) REFERENCES `dept` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
insert into `emp`(`id`,`name`,`gender`,`salary`,`join_date`,`dept_id`) values (1,'孙悟空','男',7200,'2013-02-24',1),(2,'猪八戒','男',3600,'2010-12-02',2),(3,'白骨精','女',5000,'2015-10-07',3),(4,'蜘蛛精','女',4500,'2011-03-14',1);
内连接查询与外连接查询的区别:内连接查询仅仅查出表之间互相匹配的记录,而外连接则会选出其他不匹配的记录。
内连接:使用关键字INNER JOIN
隐式内连接:隐藏INNER JOIN转而使用where
-- 查询员工表的同时查询员工所属部门的相关信息
SELECT *FROM emp,dept WHERE emp.dept_id = dept.id;
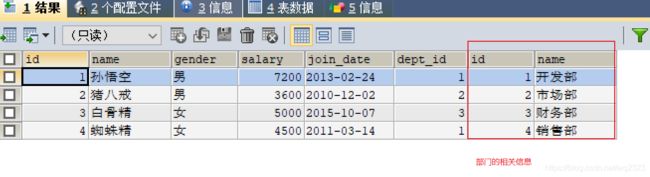
显示内连接:使用 INNER JOIN … ON 语句,**
-- 查询员工表的同时查询员工所属部门的相关信息
SELECT *FROM emp INNER JOIN dept ON emp.dept_id = dept.id;
左外连接:使用关键字LEFT JOIN
用左边表的记录去匹配右边表的记录,如果符合条件的则显示;否则,显示 NULL 可以理解为:在内连接的基础上保证左表的数据全部显示(左表是部门,右表员工)
-- 查询员工表的同时查询员工所属部门的相关信息
SELECT *FROM emp LEFT JOIN dept ON emp.dept_id = dept.id;
右外连接:使用关键字RIGHT JOIN
用右边表的记录去匹配左边表的记录,如果符合条件的则显示;
-- 查询员工表的同时查询员工所属部门的相关信息
SELECT *FROM emp LEFT JOIN dept ON emp.dept_id = dept.id;
子连接:
一个查询语句的条件可以是在另一条查询语句的查询结果当中,这时候可以使用IN的关键字查询
-- 查询员工表的同时查询员工所属部门的相关信息
SELECT *FROM emp WHERE emp.dept_id IN (SELECT id FROM dept) ;
第九章 MySQL索引
(一) 索引概述和分类
概念:索引是一种特殊的数据库结构,其作用相当于一本书的目录,可以用来快速查询数据库表中的特点记录。索引是提高数据库性能的重要方式
索引的优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大的加快数据的检索速度。
- 可以加速表和表之间的连接,特别是实现数据的参考完整性方面。
索引的缺点:
- 创建索引和维护索引需要消耗时间
- 索引需要占用物理空间。
- 对表的数据进行增删改时,索引也需要动态维护。
索引的特征:索引的两大特征为唯一性索引和复合索引
索引的分类:
- 普通索引:在创建普通索引时,不附加任何限制条件
- 唯一性索引:使用UNIQUE参数设置索引为唯一性索引
- 全文索引:使用FULLTEXT参数设置索引为全文索引
- 单列索引:在表中的单个字段上创建索引
- 多列索引:多列索引是在表中的多个字段上创建索引。
- 空间索引:使用SPATIAL参数可以设置索引为空间索引。
(二) 索引的操作
创建索引:关键字index [索引名] (属性名[长度])
1.在创建表的时候创建索引
CREATE TABLE test1 (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
INDEX t_name(NAME(5))
);
2.在已经存在的表中创建索引
CREATE INDEX t_name ON test2 (NAME(10));
3.使用ALTER TABLE语句创建索引
ALTER TABLE test3 ADD INDEX t_name (NAME(10));
4.创建唯一性索引或全文索引
CREATE TABLE `test2` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX t_name (NAME(10))
);
--或 在已经存在的表中创建全文索引
CREATE FULLTEXT INDEX t_name ON test2 (NAME(10));
5.多列索引
CREATE TABLE `test3` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
`age` VARCHAR(255) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX t_name_age (NAME,age)
);
6.查看索引
-- 格式 SHOW INDEX FROM 数据库名.表名
SHOW INDEX FROM palewl.`test3`;
-- SHOW INDEX FROM 表名 FROM 数据库名
SHOW INDEX FROM test3 FROM palewl;
7.删除索引
-- DROP INDEX 索引名 ON 表名
DROP INDEX idx_name ON test1;
-- ALTER TABLE 表名 DROP INDEX 索引名
ALTER TABLE test2 DROP INDEX t_name;
(三) 设计原则和注意事项
合理使用索引:
- 在经常需要搜索的列上创建索引,可以加快搜索的速度
- 在作为主键上的列,强制该列的唯一性和组织表中的数据排列结构
- 在经常用在连接的列上,这些列主要作为外键,加快连接的速度
- 在经常使用WHERE子句中的列上创建索引,加快条件的判断速度
不合理使用索引:
- 对于在查询中很少使用或者参考的列不应该创建索引。
- 对于只有很少数据值的列也不应该创建索引。
- 对于定义text、image和bit的数据类型不应该创建索引
- 当修改性能远远大于检索性能时,不应该创建索引。
第十章 MYSQL视图
(一) 视图概述
概念:
视图是从一个或多个表中导出的表,是一种虚拟存在的表。视图就像一个窗口,通过这个窗口可以看到系统专门提供的数据。
视图与索引视图不需要占据存储空间,索引需要占据物理空间视图的优势:增强数据安全性、提高灵活性,操作变简单、提高数据的逻辑独立性
(二) 视图的操作
视图的创建使用关键字:CREATE VIEW
--格式 CREATE VIEW 视图名 AS SELECT *FROM 表名
--AS后面的语句是正常的查询语句,指将查询的结果导入视图
CREATE VIEW user_view AS SELECT *FROM t_user;
-- 可指定视图里的具体参数
CREATE VIEW my_user(id,NAME) AS SELECT id,NAME FROM t_user;
--可借助视图查询 SELECT *FROM 视图名;
SELECT *FROM user_view;
删除视图
-- 格式 DROP VIEW 视图名;
DROP VIEW user_view;
查看视图定义
--格式 SHOW CREATE VIEW 视图名
SHOW CREATE VIEW my_user;
还有别的方式可以查看视图定义
SHOW TABLE STATUS LIKE 视图名
DESC 视图名
修改视图定义
修改视图是指修改数据库中已经存在表的定义。当基本表的某些字段发送改变时,可以通过修改视图来保持视图与基本表之间的一致。
-- 格式CREATE OR REPLACE VIEW 视图名 AS 语句
CREATE OR REPLACE VIEW my_user AS SELECT *FROM tb_user;
更新视图数据
对视图的更新其实就是对表的更新,更新视图是指通过视图来插入、更新、删除表中的数据。视图的更新会对表的数据进行修改,但是修改视图定义并不会修改原表中的数据
(三) 对视图的进一步说明
视图是在原有的表或者视图的基础上重新定义的虚拟表,这样可以从原有的表选取对用户有用的信息
主要有:
- 使操作变的更简单。视图的目的就是要所见即所需
- 增加数据的安全性
- 提高表的逻辑独立性
第十二章 MySQL触发器与事件
(一) 存储过程与函数介绍
概念:存储过程是一组为了完成特定功能的SQL语句集,经过编译后存储在数据库中,用户可以通过指定存储过程的名字来调用执行。
存储过程是一个可编程的函数,它在数据库中创建并保存,由SQL语句和一些特殊的控制结构组成。
优点:
- 存储过程增强了SQL语言的功能和灵活性
- 存储过程运行标准组件的编程。
- 存储过程能够实现较快的执行速度
- 存储过程能够减少网络流量。
存储过程与函数的区别:
- 一般存储过程实现的功能要复杂一些,而函数实现的功能针对性比较强
- 存储过程可以返回参数,如记录集,而函数只能返回值或表对象。
(二) 存储过程和函数的操作
创建一个存储过程的基本格式
create procedure 名称()
begin
.........
end
创建一个简单的存储过程test
create procedure test1()
begin
select * from users;
select * from orders;
end;
调用存储过程
CALL test1();
但是:
在 MySQL 中,服务器处理 SQL 语句默认是以分号作为语句结束标志的。然而,在创建存储过程时,存储过程体可能包含有多条 SQL 语句,这些 SQL 语句如果仍以分号作为语句结束符,那么 MySQL 服务器在处理时会以遇到的第一条 SQL 语句结尾处的分号作为整个程序的结束符,而不再去处理存储过程体中后面的 SQL 语句,这样显然不行.
为解决以上问题,通常使用 DELIMITER 命令将结束命令修改为其他字符。语法格式如下:
-- DELIMITER $$
--其中$$ 是用户自定义的介绍符号
所以,创建存储过程的语句就成为了:
DELIMITER $$
CREATE PROCEDURE test2()
BEGIN
SELECT * FROM t_user;
SELECT * FROM t_order;
END $$
-- 如果需要在结束时将结束语句换回; 则:
DELIMITER $$
CREATE PROCEDURE mypro4()
BEGIN
SELECT * FROM t_user;
SELECT * FROM t_order;
END $$
DELIMITER ;
-- 注意:DELIMITER 和分号“;”之间一定要有一个空格
此时就可以正常使用了
CALL test();
删除存储过程
-- 格式 drop procedure 名称
DROP PROCEDURE MYPRO4
第十三章 MYSQL事务
事务通常包含一系列更新操作(增删改),这些更新操作都是作为一个不可分割的逻辑单元
如果事务中的某个更新操作执行失败,那么事务中所有更新的操作均被撤销,所有影响到的数据将返回事务开始以前的状态。
事务的更新操作要么全部更新,要么都不更新,这个特征叫事务的原子性。
存储引擎: InnoDB支持事务,MyISAM是不支持事务的。
事务的特性:
- 原子性:原子性意味着每一个事务都必须被认为不可分割的单元,事务的更新操作要么全部更新,要么都不更新。
- 一致性: 事务在执行前数据库的状态与执行后数据库的状态保持一致。如:在转账操作中,转账前2个人的 总金额是 2000,转账后 2 个人总金额也是 2000 。事务的一致性保证了数据库从不返回一个未处理完的事务
- 隔离性: 事务与事务之间不应该相互影响,执行时保持隔离的状态。 事务的隔离性原则保证了某个特点事务在未完成之前,其结果是看不见的。
- 持久性: 一旦事务执行成功,对数据库的修改是持久的。就算关机,也是保存下来的。
事务的隔离性级别:
事务在操作时的理想状态: 所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个 数据。
**MYSQL并发的问题: **
脏读 一个事务读取到了另一个事务中尚未提交的数据
| 问题 | 解释 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务中尚未提交的数据 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这 是事务 update 时引发的问题 |
| 幻读 | 一个事务中两次读取的数据的数量不一致,要求在一个事务多次读取的数据的数量是一致 的,这是 insert 或 delete 时引发的问题 |
| 丢失更新 | 一个事务不知道其他事务的存在,就会发烧丢失更新问题-最后的更新覆盖了由其他事务所做的更新。 |