用虚拟机搭建k8s集群节点二 —— kubeadm方式
环境说明:
| 主机名 | 操作系统版本 | ip | docker version | kubelet version | kubeadm version | kubectl version | flannel version | 备注 |
|---|---|---|---|---|---|---|---|---|
| master | Centos 7.6.1810 | 172.27.9.131 | Docker 18.09.6 | V1.14.2 | V1.14.2 | V1.14.2 | V0.11.0 | master主机 |
| node01 | Centos 7.6.1810 | 172.27.9.135 | Docker 18.09.6 | V1.14.2 | V1.14.2 | V1.14.2 | V0.11.0 | node节点 |
| node02 | Centos 7.6.1810 | 172.27.9.136 | Docker 18.09.6 | V1.14.2 | V1.14.2 | V1.14.2 | V0.11.0 | node节点 |
前言:本文通过kudeadm方式在centos7.6上安装kubernetes v1.14.2集群(目前centos和kubernetes都为最新版),共分为六个部分:
一、Docker安装;
二、k8s安装准备工作;
三、Master节点安装;
四、Node节点安装;
五、Dashboard安装;
六、集群测试。
目录
一、Docker安装
1. 安装依赖包
2. 设置Docker源
3. 安装Docker CE
3.1 docker安装版本查看
3.2 安装docker
4. 启动Docker
5. 命令补全
5.1 安装bash-completion
5.2 加载bash-completion
6. 镜像加速
6.1 登陆阿里云容器模块
6.2 配置镜像加速器
7. 验证
二、k8s安装准备工作
1. 配置主机名
1.1 修改主机名
1.2 修改hosts文件
2. 验证mac地址uuid
3. 禁用swap
3.1 临时禁用
3.2 永久禁用
4. 内核参数修改
4.1 临时修改
4.2 永久修改
5. 修改Cgroup Driver
5.1 修改daemon.json
5.2 重新加载docker
6. 设置kubernetes源
6.1 新增kubernetes源
6.2 更新缓存
三、Master节点安装
1. 版本查看
2. 安装kubelet、kubeadm和kubectl
2.1 安装三个包
2.2 安装包说明
2.3 启动kubelet
2.4 kubelet命令补全
3. 下载镜像
3.1 镜像下载的脚本
3.2 下载镜像
4. 初始化Master
4.1 初始化
4.2 加载环境变量
5. 安装pod cni网络插件flannel
6. master节点配置
6.1 删除master节点默认污点
6.2 污点机制
四、Node节点安装
1. 安装kubelet、kubeadm和kubectl
2. 下载镜像
3. 将master的kubectl命令权限开放给node节点
4. 安装pod cni 网络插件flannel
5. node加入集群
5.1 查看令牌是否过期
5.2 node节点加入集群
五、Dashboard安装
1. 下载yaml
2. 配置yaml
2.1 修改镜像地址
2.2 外网访问
2.3 新增管理员帐号
3. 部署访问
3.1 部署Dashboard
3.2 状态查看
3.3 令牌查看
3.4 访问
六、集群测试
1. 部署应用
1.1 命令方式
1.2 配置文件方式
2. 状态查看
2.1 查看节点状态
2.2 查看pod状态
2.3 查看副本数
2.4 查看deployment详细信息
2.5 查看集群基本组件状态
一、Docker安装
所有节点都需要安装docker
1. 安装依赖包
[root@centos7 ~]# yum install -y yum-utils device-mapper-persistent-data lvm22. 设置Docker源
[root@centos7 ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo3. 安装Docker CE
3.1 docker安装版本查看
[root@centos7 ~]# yum list docker-ce --showduplicates | sort -r3.2 安装docker
[root@centos7 ~]# yum install docker-ce-18.09.6 docker-ce-cli-18.09.6 containerd.io指定安装的docker版本为18.09.6,也可以直接安装最新版本,则不用指定版本(出于各种组件的版本兼容性考虑,不建议安装最新版本):
yum install -y docker-ce docker-ce-cli containerd.io4. 启动Docker
[root@centos7 ~]# systemctl start docker
[root@centos7 ~]# systemctl enable docker5. 命令补全
5.1 安装bash-completion
[root@centos7 ~]# yum -y install bash-completion5.2 加载bash-completion
[root@centos7 /]# source /etc/profile.d/bash_completion.sh6. 镜像加速
由于Docker Hub的服务器在国外,下载镜像会比较慢,可以配置镜像加速器。主要的加速器有:Docker官方提供的中国registry mirror、阿里云加速器、DaoCloud 加速器,本文以阿里加速器配置为例。
6.1 登陆阿里云容器模块
登陆地址为:https://cr.console.aliyun.com ,未注册的可以先注册阿里云账户
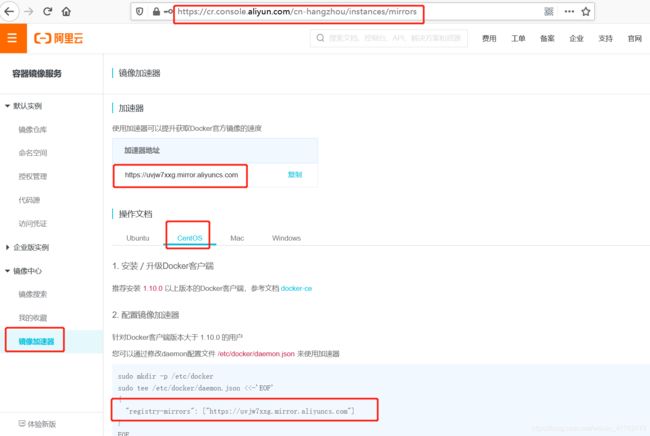
6.2 配置镜像加速器
配置daemon.json文件
[root@centos7 ~]# mkdir -p /etc/docker
[root@centos7 ~]# tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://uvjw7xxg.mirror.aliyuncs.com"]
}
EOF加速器配置完成。
7. 验证
[root@centos7 ~]# docker --version
[root@centos7 ~]# docker run hello-world
通过查询docker版本和运行容器hello-world来验证docker是否安装成功。
二、k8s安装准备工作
安装Centos是已经禁用了防火墙和selinux并设置了阿里源。master和node节点都执行本部分操作。
1. 配置主机名
1.1 修改主机名
[root@centos7 ~]# hostnamectl set-hostname master
[root@centos7 ~]# more /etc/hostname
master退出重新登陆即可显示新设置的主机名master
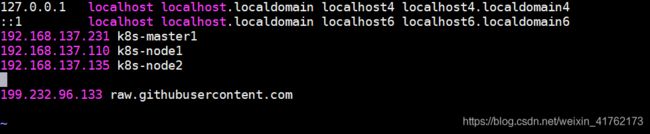
1.2 修改hosts文件
[root@master ~]# cat >> /etc/hosts << EOF
172.27.9.131 master
172.27.9.135 node01
172.27.9.136 node02
EOF2. 验证mac地址uuid
[root@master ~]# cat /sys/class/net/ens33/address
[root@master ~]# cat /sys/class/dmi/id/product_uuid保证各节点mac和uuid唯一
3. 禁用swap
3.1 临时禁用
[root@master ~]# swapoff -a3.2 永久禁用
若需要重启后也生效,在禁用swap后还需修改配置文件/etc/fstab,注释swap
[root@master ~]# sed -i.bak '/swap/s/^/#/' /etc/fstab4. 内核参数修改
4.1 临时修改
[root@master ~]# sysctl net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-iptables = 1
[root@master ~]# sysctl net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-ip6tables = 14.2 永久修改
[root@master ~]# cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@master ~]# sysctl -p /etc/sysctl.d/k8s.conf 
5. 修改Cgroup Driver
5.1 修改daemon.json
修改daemon.json,新增‘"exec-opts": ["native.cgroupdriver=systemd"]
[root@master ~]# more /etc/docker/daemon.json
{
"registry-mirrors": ["https://v16stybc.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}5.2 重新加载docker
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart docker修改cgroupdriver是为了消除告警:
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
6. 设置kubernetes源
6.1 新增kubernetes源
[root@master ~]# cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- [] 中括号中的是repository id,唯一,用来标识不同仓库
- name 仓库名称,自定义
- baseurl 仓库地址
- enable 是否启用该仓库,默认为1表示启用
- gpgcheck 是否验证从该仓库获得程序包的合法性,1为验证
- repo_gpgcheck 是否验证元数据的合法性 元数据就是程序包列表,1为验证
- gpgkey=URL 数字签名的公钥文件所在位置,如果gpgcheck值为1,此处就需要指定gpgkey文件的位置,如果gpgcheck值为0就不需要此项了
6.2 更新缓存
[root@master ~]# yum clean all
[root@master ~]# yum -y makecache
三、Master节点安装
1. 版本查看
[root@master ~]# yum list kubelet --showduplicates | sort -r 目前最新版是1.14.2,该版本支持的docker版本为1.13.1, 17.03, 17.06, 17.09, 18.06, 18.09。
2. 安装kubelet、kubeadm和kubectl
2.1 安装三个包
[root@master ~]# yum install -y kubelet-1.14.2 kubeadm-1.14.2 kubectl-1.14.2若不指定版本直接运行‘yum install -y kubelet kubeadm kubectl’则默认安装最新版。(注:不要安装 kubernets-cni插件,否则会导致依赖的kubelet的版本号发生变化)
2.2 安装包说明
- kubelet 运行在集群所有节点上,用于启动Pod和容器等对象的工具
- kubeadm 用于初始化集群,启动集群的命令工具
- kubectl 用于和集群通信的命令行,通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2.3 启动kubelet
启动kubelet并设置开机启动
[root@master ~]# systemctl enable kubelet && systemctl start kubelet2.4 kubelet命令补全
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@master ~]# source .bash_profile 3. 下载镜像
3.1 镜像下载的脚本
Kubernetes几乎所有的安装组件和Docker镜像都放在goolge自己的网站上,直接访问可能会有网络问题,这里的解决办法是从阿里云镜像仓库下载镜像,拉取到本地以后改回默认的镜像tag。
[root@master ~]# more image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.14.2
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
doneurl为阿里云镜像仓库地址,version为安装的kubernetes版本。
3.2 下载镜像
运行脚本image.sh,下载指定版本的镜像,运行脚本前先赋权。
[root@master ~]# chmod u+x image.sh
[root@master ~]# ./image.sh
[root@master ~]# docker images
4. 初始化Master
4.1 初始化
[root@master ~]# kubeadm init --apiserver-advertise-address 172.27.9.131 --pod-network-cidr=10.244.0.0/16apiserver-advertise-address指定master的interface,pod-network-cidr指定Pod网络的范围,这里使用flannel网络方案。

记录kubeadm join的输出,后面需要这个命令将各个节点加入集群中。
4.2 加载环境变量
[root@master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master ~]# source .bash_profile 本文所有操作都在root用户下执行,若为非root用户,则执行如下操作:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config5. 安装pod cni网络插件flannel
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml注:若出现报错:The connection to the server raw.githubusercontent.com was refused,则在hosts文件中添加一行解析:vi /etc/hosts
6. master节点配置
taint:污点的意思。如果一个节点被打上了污点,那么pod是不允许运行在这个节点上面的
6.1 删除master节点默认污点
默认情况下集群不会在master上调度pod,如果偏想在master上调度Pod,可以执行如下操作:
查看污点:
[root@master ~]# kubectl describe node master|grep -i taints
Taints: node-role.kubernetes.io/master:NoSchedule删除默认污点:
[root@master ~]# kubectl taint nodes master node-role.kubernetes.io/master-
node/master untainted6.2 污点机制
语法:
kubectl taint node [node] key=value[effect]
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
NoSchedule: 一定不能被调度
PreferNoSchedule: 尽量不要调度
NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod打污点
[root@master ~]# kubectl taint node master key1=value1:NoSchedule
node/master tainted
[root@master ~]# kubectl describe node master|grep -i taints
Taints: key1=value1:NoSchedulekey为key1,value为value1(value可以为空),effect为NoSchedule表示一定不能被调度
删除污点:
[root@master ~]# kubectl taint nodes master key1-
node/master untainted
[root@master ~]# kubectl describe node master|grep -i taints
Taints: 删除指定key所有的effect,‘-’表示移除所有以key1为键的污点。
四、Node节点安装
1. 安装kubelet、kubeadm和kubectl
同: master节点安装;
2. 下载镜像
同:master节点下载镜像;
3. 将master的kubectl命令权限开放给node节点
该步在master节点操作:将admin.conf文件拷贝到其它从节点
[root@k8s-master ~]# scp -r /etc/kubernetes/admin.conf root@k8s-node01:/etc/kubernetes/
然后回到node节点,在node节点上创建一个./kube的目录用来保存的我们的连接配置:
mkdir -p $HOME/.kube
接着复制admin.conf到该目录下:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
最后授予权限:
sudo chown $(id -u):$(id -g) $HOME/.kube/config
4. 安装pod cni 网络插件flannel
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml5. node加入集群
以下操作master上执行
5.1 查看令牌是否过期
[root@master ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
j5eoyz.zu0x6su7wzh752b3 2019-06-04T17:40:41+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token 若初始化时的令牌过期则执行如下两步:
生成新的令牌:
[root@master ~]# kubeadm token create
1zl3he.fxgz2pvxa3qkwxln生成新的加密串:
[root@master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'5.2 node节点加入集群
在node节点上分别执行如下操作:
[root@node01 ~]# kubeadm join 172.27.9.131:6443 --token 1zl3he.fxgz2pvxa3qkwxln --discovery-token-ca-cert-hash sha256:5f656ae26b5e7d4641a979cbfdffeb7845cc5962bbfcd1d5435f00a25c02ea50
五、Dashboard安装
1. 下载yaml
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml如果连接超时,可以多试几次
2. 配置yaml
2.1 修改镜像地址
sed -i 's/k8s.gcr.io/registry.cn-hangzhou.aliyuncs.com\/kuberneters/g' kubernetes-dashboard.yaml由于默认的镜像仓库网络访问不通,故改成阿里镜像
2.2 外网访问
sed -i '/targetPort:/a\ \ \ \ \ \ nodePort: 30001\n\ \ type: NodePort' kubernetes-dashboard.yaml配置NodePort,外部通过https://NodeIp:NodePort 访问Dashboard,此时端口为30001
2.3 新增管理员帐号
cat >> kubernetes-dashboard.yaml << EOF
---
# ------------------- dashboard-admin ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
EOF 创建超级管理员的账号用于登录Dashboard
3. 部署访问
3.1 部署Dashboard
[root@master ~]# kubectl apply -f kubernetes-dashboard.yaml 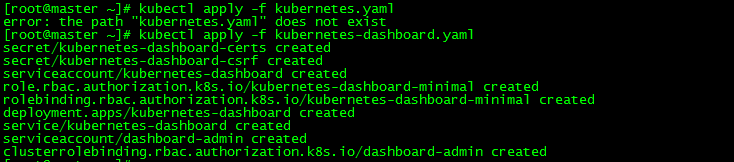
3.2 状态查看
[root@master ~]# kubectl get deployment kubernetes-dashboard -n kube-system
[root@master ~]# kubectl get pods -n kube-system -o wide
[root@master ~]# kubectl get services -n kube-system3.3 令牌查看
kubectl describe secrets -n kube-system dashboard-admin
令牌为:
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4ta3Q5eDciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYzI2MjZiYTUtOTE5Ny0xMWU5LTk2OTQtMDAwYzI5ZDk5YmEzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.XnBTkkMNQx_hKlTml7B-D1Ip-hp-WFi1mgjgx2E_SHbaRJluLN5qXWLsBAPl1Cgp-IY5ujg9pYePAZL2GDYyjnCaMiFmQsRW-zbNfkyYfPWje8MtCxJqoILTlCxsa5apwWsKdbsW_X8moMC4cM92hApQshn_-x-V7cxydEKuQPrB3PfQ7ReNMM5VCj4rexAh9Qr7I1wEHFa0KX1XaDRiedjWgXFKU7kWX2VQ3vwnfRdpKq_r0vlDSQRVdrMDPT1BHuBaUn8Gz-EdLR3qUy5vlZbzo1UFvxuL2enoZxntHZmnP1vg4552HROeEJhigdtRSbDvxHTEGWT3A67faha-Kg3.4 访问
https://NodeIp:30001
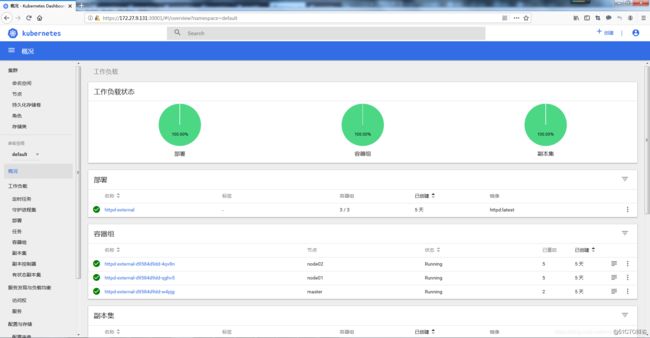
Dashboard提供了可以实现集群管理、工作负载、服务发现和负载均衡、存储、字典配置、日志视图等功能。
六、集群测试
1. 部署应用
1.1 命令方式
[root@master ~]# kubectl run httpd-app --image=httpd --replicas=3
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/httpd-app created通过命令行方式部署apache服务
1.2 配置文件方式
cat >> nginx.yml << EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
restartPolicy: Always
containers:
- name: nginx
image: nginx:latest
EOF
[root@master ~]# kubectl apply -f nginx.yml
deployment.extensions/nginx created通过配置文件方式部署nginx服务
2. 状态查看
2.1 查看节点状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 47h v1.14.2
node01 Ready 22h v1.14.2
node02 Ready 6h55m v1.14.2 2.2 查看pod状态
[root@master ~]# kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default httpd-app-6df58645c6-42zmc 1/1 Running 0 176m
default httpd-app-6df58645c6-g6bkc 1/1 Running 0 176m
default httpd-app-6df58645c6-kp8tl 1/1 Running 0 176m
default nginx-9d4cf4f77-dft2f 1/1 Running 0 18m
default nginx-9d4cf4f77-dztxq 1/1 Running 0 18m
default nginx-9d4cf4f77-l9gdh 1/1 Running 0 18m
kube-system coredns-fb8b8dccf-bxvrz 1/1 Running 1 47h
kube-system coredns-fb8b8dccf-mqvd8 1/1 Running 1 47h
kube-system etcd-master 1/1 Running 3 47h
kube-system kube-apiserver-master 1/1 Running 3 47h
kube-system kube-controller-manager-master 1/1 Running 4 47h
kube-system kube-flannel-ds-amd64-lkh5n 1/1 Running 0 6h55m
kube-system kube-flannel-ds-amd64-pv5ll 1/1 Running 1 24h
kube-system kube-flannel-ds-amd64-wnn5g 1/1 Running 1 22h
kube-system kube-proxy-42vb5 1/1 Running 3 47h
kube-system kube-proxy-7nrfk 1/1 Running 0 6h55m
kube-system kube-proxy-x7dmk 1/1 Running 1 22h
kube-system kube-scheduler-master 1/1 Running 4 47h2.3 查看副本数
[root@master ~]# kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
httpd-app 3/3 3 3 178m
nginx 3/3 3 3 19m
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
httpd-app-6df58645c6-42zmc 1/1 Running 0 179m 10.244.0.6 master
httpd-app-6df58645c6-g6bkc 1/1 Running 0 179m 10.244.1.2 node01
httpd-app-6df58645c6-kp8tl 1/1 Running 0 179m 10.244.2.2 node02
nginx-9d4cf4f77-dft2f 1/1 Running 0 20m 10.244.0.7 master
nginx-9d4cf4f77-dztxq 1/1 Running 0 20m 10.244.2.3 node02
nginx-9d4cf4f77-l9gdh 1/1 Running 0 20m 10.244.1.3 node01
[root@master ~]# 可以看到nginx和httpd的3个副本pod均匀分布在3个节点上
2.4 查看deployment详细信息
[root@master ~]# kubectl describe deployments
2.5 查看集群基本组件状态
[root@master ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
至此完成Centos7.6下k8s(v1.14.2)集群部署。
附:若有node节点NotReady, 可用命令查看node的kubelet日志:
journalctl -f -u kubelet
另外,在node节点的配置daemon.json中的项目,‘"exec-opts": ["native.cgroupdriver=systemd"]可能会引起kubelet的报错:
kubelet cgroup driver: “cgroupfs“ is different from docker cgroup driver: “systemd“
这里要修改3个配置文件为cgroupfs(或者systemd,视具体情况而定)
1.vim /etc/docker/daemon.json
"exec-opts": ["native.cgroupdriver=cgroupfs"]2.vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
在KUBELET_KUBECONFIG_ARGS 后面追加 --cgroup-driver=cgroupfs
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --cgroup-driver=cgroupfs"
3.vim /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--cgroup-driver=cgroupfs --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2"
然后重启kubelet和docker,k8s集群就恢复了:
systemctl daemon-reload
systemctl restart docker
systemctl restart kubelet
k8s主备高可用部署详见:Centos7.6部署k8s v1.16.4高可用集群(主备模式)
k8s集群高可用部署详见:lvs+keepalived部署k8s v1.16.4高可用集群
参考: https://blog.51cto.com/3241766/2405624#h51