八大经典排序算法的理解、动图演示和C++方法实现
0. 排序算法概述
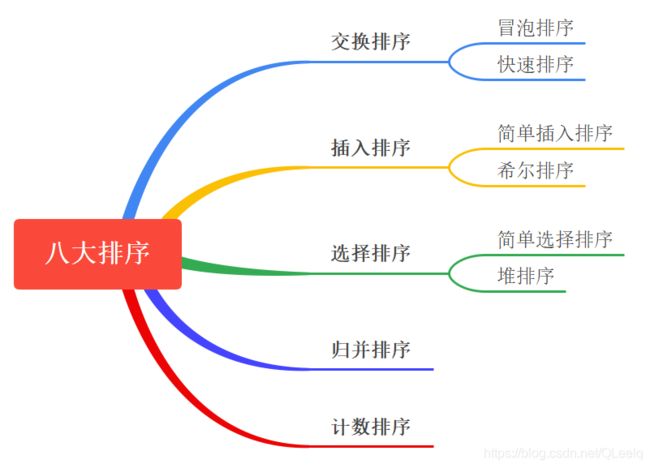
所谓排序,就是使一串序列,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。掌握基本排序方法是算法入门的必备基础知识。八种排序如下所示:
看到有文章说计数排序是稳定排序,实际上计数排序是重新赋值的,所以我的理解它应该属于不稳定排序。这里介绍的8种排序算法的基本情况,如下思维导图和表格所示:
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 选择排序 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O(1)$ | 不稳定 |
| 插入排序 | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | 稳定 |
| 快速排序 | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n 2 ) O(n^2) O(n2) | O ( n l o g n ) O(n\ log\ n) O(n log n) | 不稳定 |
| 归并排序 | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n ) O(n) O(n) | 稳定 |
| 计数排序 | O ( n + k ) O(n + k) O(n+k) | O ( n + k ) O(n + k) O(n+k) | O ( n + k ) O(n + k) O(n+k) | O ( k ) O(k) O(k) | 不稳定 |
| 希尔排序 | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g 2 n ) O(n\ log^2\ n) O(n log2 n) | O ( n l o g 2 n ) O(n\ log^2\ n) O(n log2 n) | O ( 1 ) O(1) O(1) | 不稳定 |
| 堆排序 | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( n l o g n ) O(n\ log\ n) O(n log n) | O ( 1 ) O(1) O(1) | 不稳定 |
说明:排序算法的稳定性,指的是排序前后相同元素的相对位置不变,则称排序算法是稳定的;否则排序算法是不稳定的。
下面开始介绍各类算法的实现,例程全部是从小到大排序。
1. 冒泡排序
原理:它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。把最小的数浮上来,或者把最大的数据沉下去。
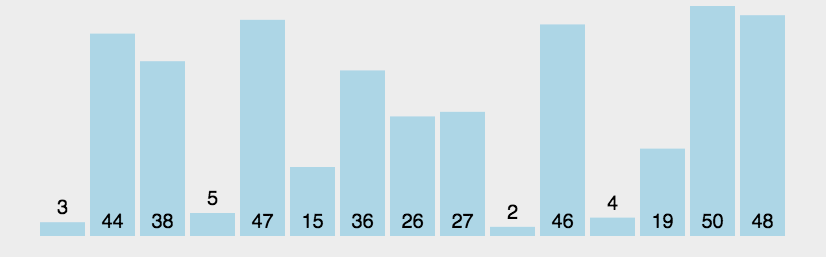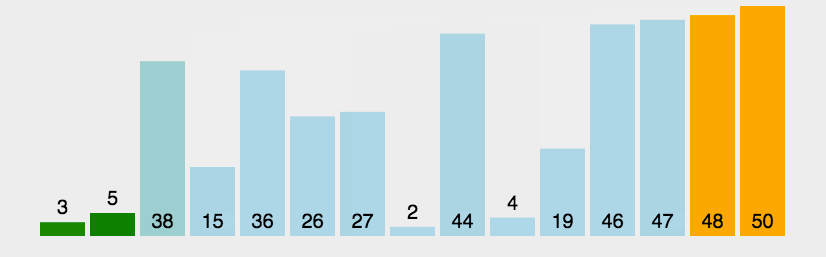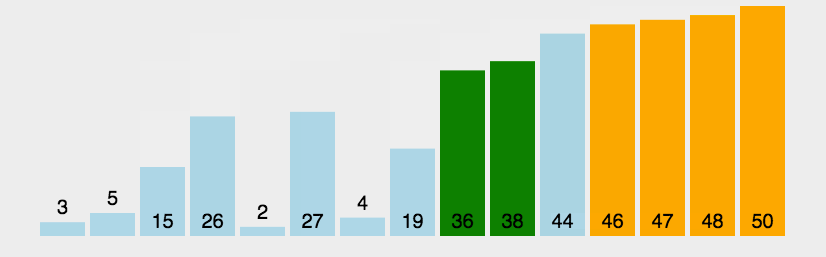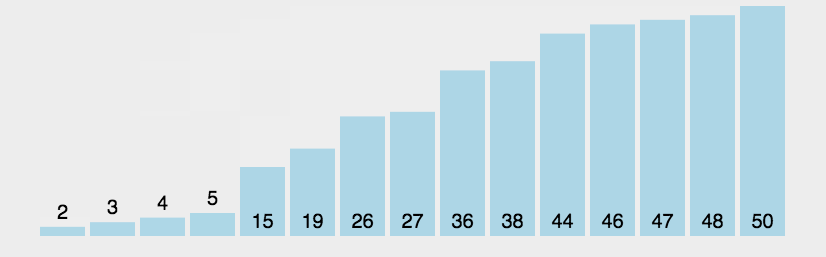
代码实现:
#include2. 选择排序
原理:选择排序和冒泡很像,它也是比较两个元素,不过它先不交换,等到选取最大或者最小的数据之后再进行交换。

代码实现:
#include3. 插入排序
原理:从第二位数据开始, 当前数(第一趟是第二位数)与前面的数依次比较,如果前面的数大于当前数,则将这个数放在当前数的位置上,当前数的下标-1,直到当前数不大于前面的某一个数为止。直到遍历至最后一位元素。
通俗的讲,就是从第二位开始,更小的值往前插入。前面的数据肯定是插入排序已经排列好的,前面的值小于或等于当前值基准值的位置。
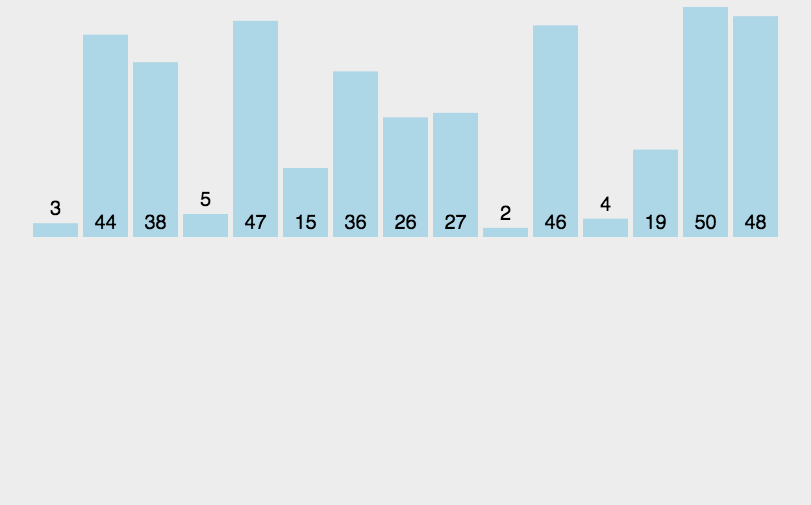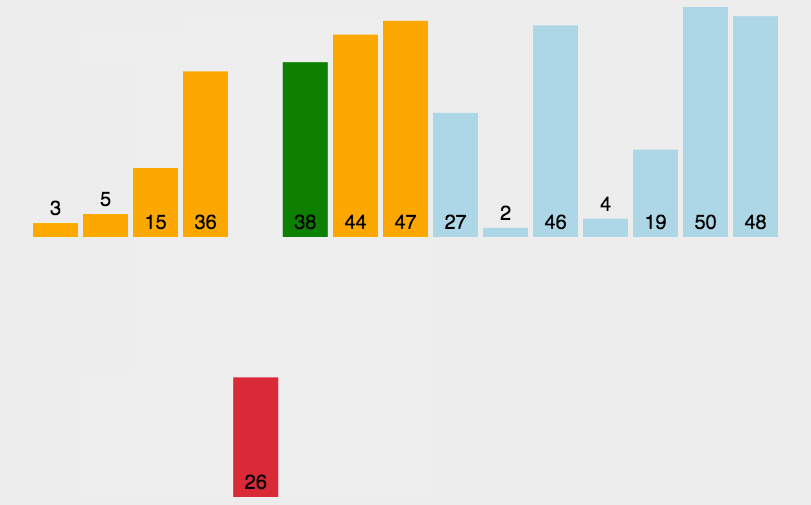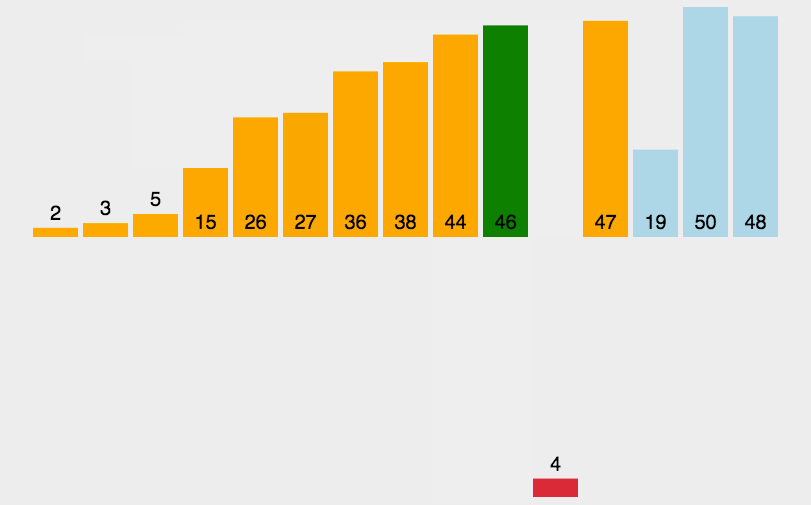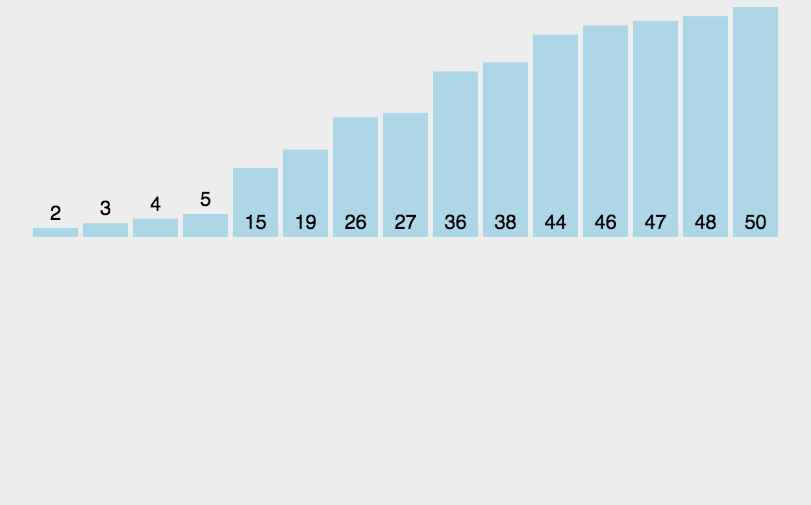
代码实现:
#include4. 快速排序
原理:通过一趟排序将序列分成左右两部分,其中左半部分的的值均比右半部分的值小,然后再分别对左右部分的记录进行排序,直到整个序列有序。

代码实现:
#include5. 归并排序
归并排序是把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
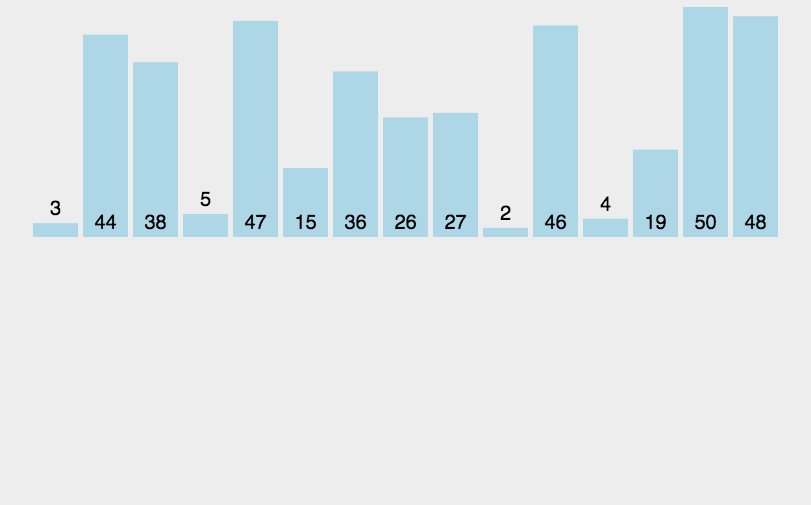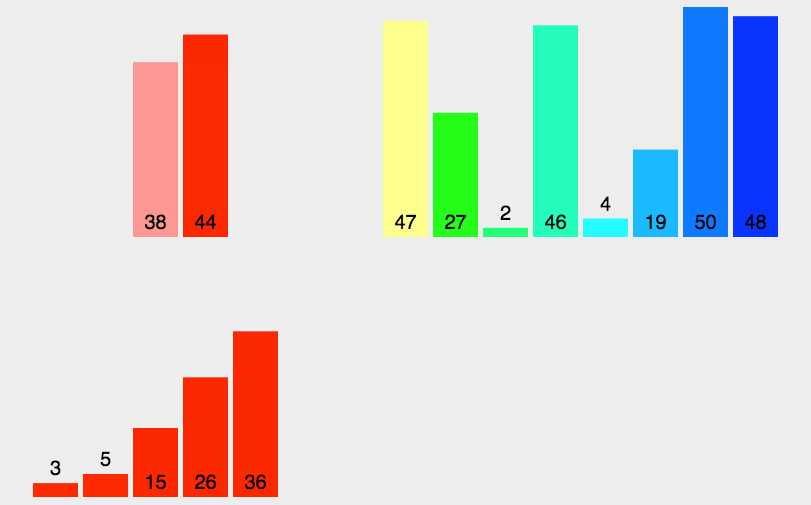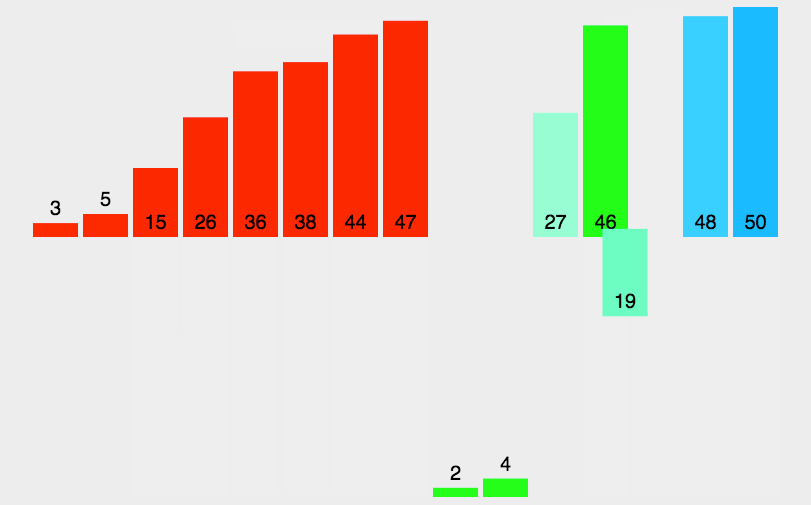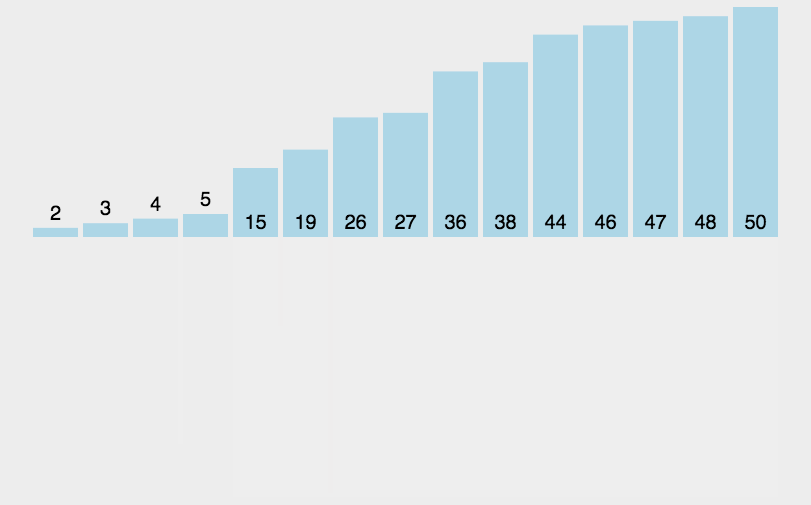
实现代码:
#include6. 计数排序
原理:当待排序的数的值都是在一定的范围内的整数时,可以用待排序的数作为计数数组的下标,统计每个数的个数,然后依次输出即可。
算法步骤:
- 花O(n)的时间扫描一下整个序列 A,max
- 开辟一块新的空间创建新的数组 B,长度为 ( max + 1)
- 数组 B 中 index 的元素记录的值是 A 中某元素出现的次数
- 最后输出目标整数序列,具体的逻辑是遍历数组 B,输出相应元素以及对应的个数
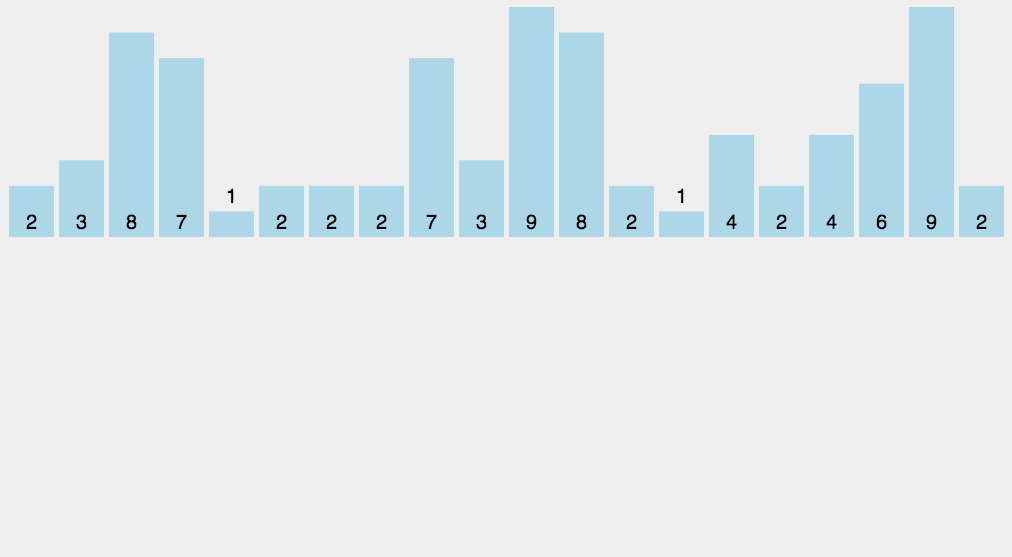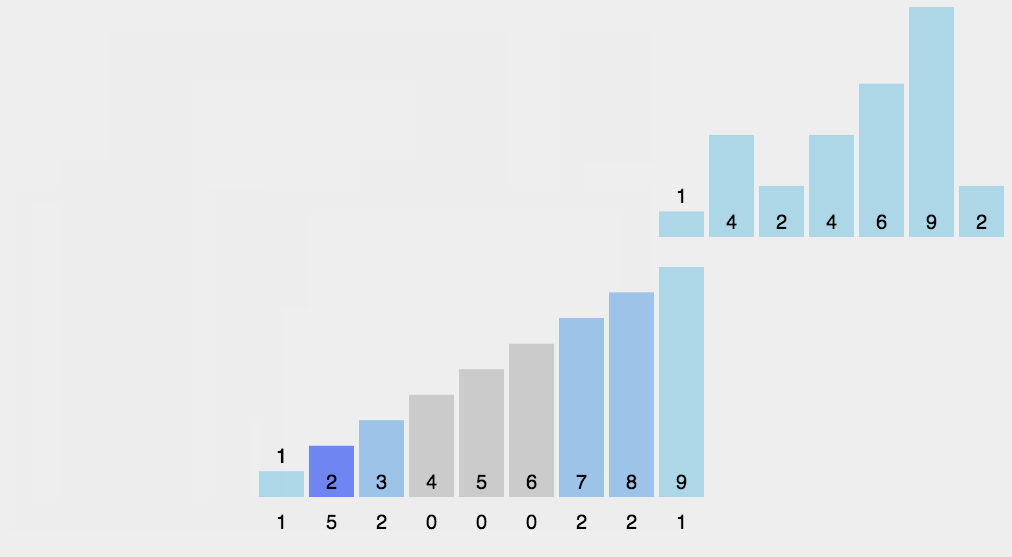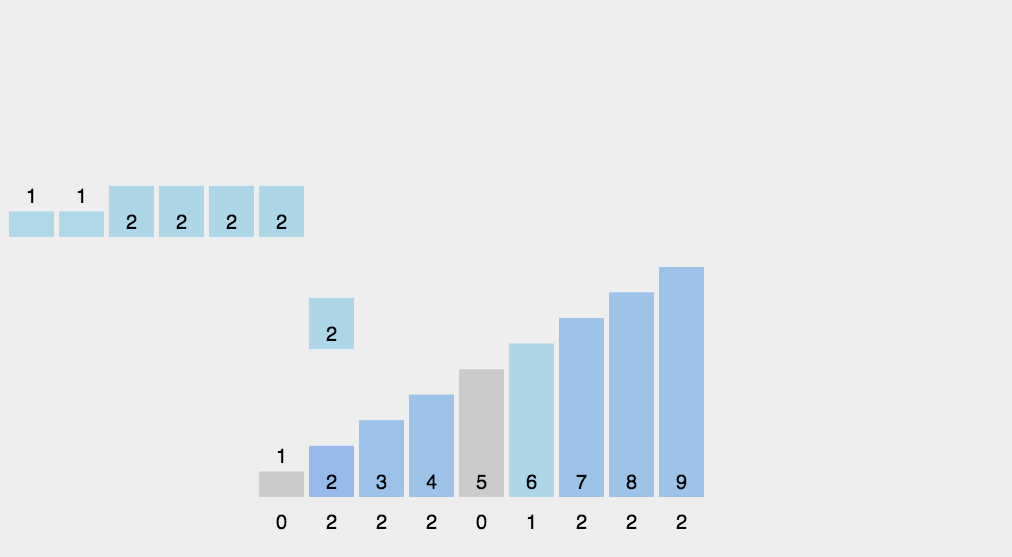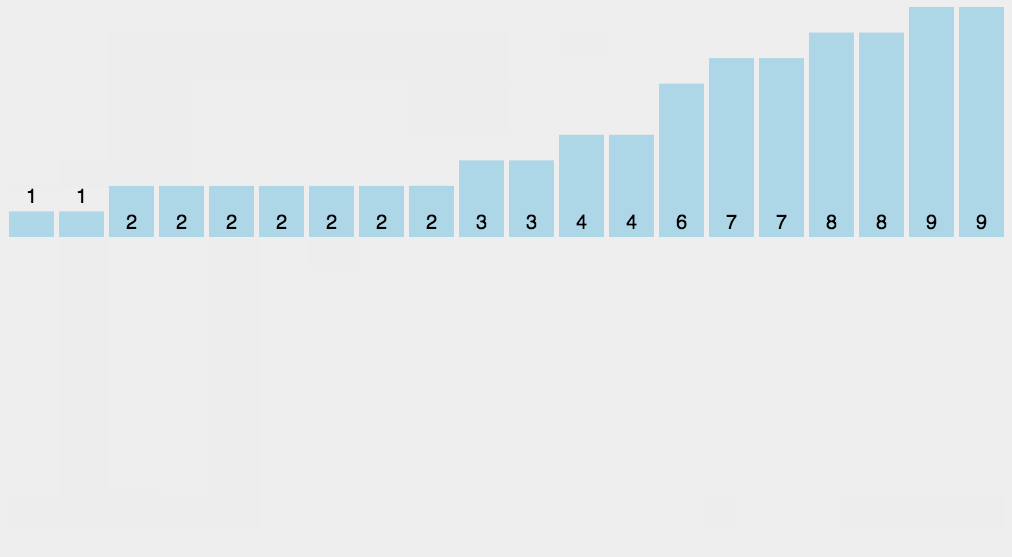
实现代码:
#include7. 希尔排序
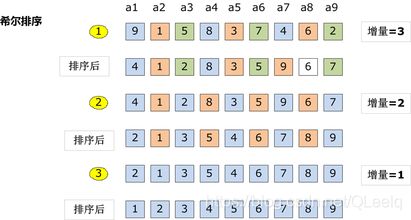
原理:希尔排序是插入排序改良的算法,是插入排序的一种高效率的实现,也叫缩小增量排序。希尔排序步长从大到小调整,所以步长是关键,最终步长为1,做最后的排序。
步长为1的时候肯定能排出符合的序列。
实现代码:
#include8. 堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法。利用了堆的一个总要性质,即子结点的键值或索引总是小于(或者大于)它的父节点。
堆的性质:
- 堆是一个完全二叉树
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
- 一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
原理:从小到大排序,则使用大顶堆,每次取堆顶元素和后面的元素交换,然后对剩下的元素进行大顶堆排序。
大顶堆的构建:
代码实现:
#include参考(Java实现):https://www.cnblogs.com/fivestudy/p/10212306.html