【skLearn 聚类算法】KMeans
文章目录
- KMeans聚类算法前言
-
- ※ 聚类与分类的区别
- ※ sklearn.cluster: Clustering --- 聚类模块
- 一、KMeans工作原理
-
- 1.定义
- 2.算法过程
- 3.聚类结果分析
- 4.簇内平方和
- 5.KMeans算法的时间复杂度(了解)
- 二、KMeans类的使用
-
- ◐ 重要参数 ---- n_clusters
- ◐ 聚类案例
-
- ① 创建数据集
- ② KMeans聚类
-
- ★ 重要属性labels_,查看聚好的类别,每个样本所对应的簇数
- ☠ 注意 predict 和 fit_ predict
- ★ 重要属性cluster_centers_,查看质心
- ★ 重要属性inertia_,查看总距离平方和
- ③ 结果可视化
- ④ 检验质心数
- 三、聚类的模型评估指标
-
- ◑ 真实标签已知 ---- 几乎不可能
-
- ① 互信息分
- ② V-measure
- ③ 调整兰德系数
- ◑ 真实标签未知
-
- ① 轮廓系数
-
- ◐ 公式
- ◐ 轮廓系数应用
- ② 其他评估方法
-
- 卡林斯基-哈拉巴斯指数
- 四、案例:基于轮廓系数来选择 n_clusters
-
- ◑ 准备工作(数据集、画布)
- ◑ KMeans聚类、评估
- ◑ 可视化:绘制各个簇之间的轮廓系数的对比图
- ◑ 可视化:绘制聚类散点图
- 五、遍历n_cluster查找最优
-
- ◑ 代码可视化
- ◑ 结果展示
- ◑ 分析
- 六、重要参数 init、random_state、n_init
- 七、重要参数 max_iter、tol
- 八、总结回顾重要属性与接口
- 十、cluster.k_means()函数的使用
KMeans聚类算法前言
-
决策树、随机森林、逻辑回归,功能不同,但是都属于
有监督学习(在进行模型训练的时候,既需要特征矩阵 X,也需要真实标签 Y) -
KMeans聚类算法属于无监督学习(在进行模型训练的时候,只需要特征矩阵 X,不需要真实标签 Y)- 降维算法PCA就是无监督学习的一种,降维的目的并非输出某一个具体的标签,而是降低特征的数量 -
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。# 比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客 户价值判断模型RFM,就常常和聚类分析共同使用。 # 再比如,聚类可以用于降维和矢量量化(vector quantization)<将高维特征压缩到一列当中或者在不改变特征的数量和样本的数量情况下压缩数据上的信息量>, 可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
※ 聚类与分类的区别
- 聚类与分类的主要区别在于:
聚类的不确定性- 分类是将新数据按照原有的分组去进行识别划分,已经有了基准;聚类是按照给定的整个数据集,探索划分组别,所划分的类别与真实是否一致很难确定
- 这主要是基于两者的类型不同导致的,分类属于有监督,需要真实的标签(基准)进行训练;而聚类属于无监督,无需标签(没有基准)进行训练



返回顶部
※ sklearn.cluster: Clustering — 聚类模块

[ ] 内表示可选参数,[ ]外表示必填参数
- 输入数据
需要注意的一件重要事情是,该模块中实现的算法可以采用不同类型的矩阵作为输入。所有方法都接受形状[n_samples,n_features]的标准特征矩阵,
这些可以从 sklearn. feature_extraction模块中的类中获得。对于亲和力传播,光谱聚类和 DBSCAN,还可以输入形状[n_ samples,n_samples]
的相似性矩阵,我们可以使用sklearn.metrics.pairwise模块中的函数来获取相似性矩阵。
返回顶部
一、KMeans工作原理
1.定义
KMeans算法将一组N个样本的特征矩阵X分为K个无交集的簇,直观上来看是簇,是一组一组聚集在一起的数据。在一个簇中的数据就认为是同一类,簇就是聚类的结果表现。
簇中所有数据的均值μ(j),通常被称为这个簇的“质心(centroids)”,j表示第j个簇。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值,同理可推广至高维空间。
返回顶部
2.算法过程
KMeans算法中,簇的个数K是一个超参数,需要我们人为输入来确定。
KMeans的核心任务就是根据我们设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。 具体过程可以总结如下:
1.随机抽取K个样本作为最初的质心
2.开始循环:
2.1 将每个样本点分配到离他们最近的质心,生成K个簇
2.2 对于每个簇,计算所有被分到该簇的样本点的平均值作为新的质心
3.当质心的位置不再发生变化,迭代停止,聚类完成
当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,
所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了。
KMeans聚类_B站菜菜老师讲解
返回顶部
3.聚类结果分析
-
被分在同一个簇内的数据是拥有着某些相同性质的;不同的簇中的样本性质可能不同,根据不同的业务需求结合聚类结果指定不同的商业或科技策略。
-
聚类结果追求的是“簇内差异小,簇间差异大”,这样分出来的簇才会具有代表性。
-
所谓的差异,其实是由样本点到其所在簇的质心的距离来衡量的。
对于一个簇来说,所有的样本点到质心的距离之和越小,那么簇中的样本越相似,簇内的差异就越小
返回顶部
4.簇内平方和
-
公式


-
解释
其中,
m为一个簇中样本的个数,j是每个样本的编号。这个公式被称为簇内平方和(cluster Sum of Square),又叫做Inertia。
而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum of Square),又叫做 total inertia.Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。
因此KMeans追求的是,求解能够让 inertia最小化的质心。实际上,在质心不断变化不断迭代的过程中,总体平方和是越来越小的。我们可以使用数学来证明,当整体平方和最小的时候,质心就不再发生变化了。如此,k- Means的求解过程,就变成了一个最优化问题。 -
损失函数
在逻辑回归中曾有这样的结论:损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。
Kmeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一种探索。所以,可以说KMeans不存在什么损失函数, Inertia更像是Kmeans的模型评估指标,而非损失函数。
返回顶部
5.KMeans算法的时间复杂度(了解)
除了模型本身的效果之外,我们还使用另一种角度来度量算法:算法复杂度。算法的复杂度分为时间复杂的和空间复杂度,时间复杂度是指执行算法所需要的计算工作量,常用大O符号表述;而空间复杂度是指执行这个算法所需要的内存空间。如果一个算法的效果很好,但需要的时间复杂度和空间复杂度都很大那我们将会权衡算法的效果和所需的计算成本之间。比如在降维算法和特征工程两章中,我们尝试了一个很大的数据集下KNN和随机森林所需的运行时间,以此来表明我们降维的目的和决心。
和KNN一样, KMeans算法是一个计算成本很大的算法。KMeans算法的平均复杂度是O(knT),其中k是我们的超参数,所需要输入的簇数,n是整个数据集中的样本量,T是所需要的迭代次数(相对的,KNN的平均复杂度是O(n)。在最坏的情况下, KMeans的复杂度可以写作O(n**[(k+2)/p]),其中n是整个数据集中的样本量,p是特征总数。这个最高复杂度是由D. Arthur和s. Vassilvitskii在2006年发表的论文k-means方法有多慢?“中提出的。
尽管如此,相比其他聚类算法,k-means算法已经是很快的了。
返回顶部
二、KMeans类的使用
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10, max_iter=300, tol=0.0001,
precompute_distances='deprecated', verbose=0, random_state=None, copy_x=True, n_jobs='deprecated', algorithm='auto')
◐ 重要参数 ---- n_clusters
- n_clusters就是指要形成的团簇数目以及要生成的质心数,也就是上面提到的k,默认是8.但是通常求出都要比8小
◐ 聚类案例
① 创建数据集
from sklearn.datasets import make_blobs # 用于自定义创建数据集
import matplotlib.pyplot as plt # 用于可视化绘图
# 创建数据集
x , y = make_blobs(n_samples=500, # 500个数据
n_features=2, # 两个特征 --- 绘制平面图
centers=4,
random_state=1 # 保证每次创建的数据集一样
)
# 由生成子图的形式绘图,1表示生成1个子图,每个子图由两部分组成:fig画布、ax1图
fig , axl = plt.subplots(1)
# 绘制ax1图形
axl.scatter(x[:,0], # 横坐标
x[:,1], # 纵坐标
marker='o', # 点的形状
s=8 # 点的大小
)
plt.show()

如上图所示,通过创建的数据集,并将其可视化之后生成的图。接下来我们对其进行KMeans聚类操作。
返回顶部
② KMeans聚类
# 导包
from sklearn.cluster import KMeans
# 1.设定初始簇的数量
n_clusters = 3
# 2.实例化KMeans类
# 在fit训练了x之后,实际上已经完成循环,聚类结束
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(x)
# 3.重要属性labels_,查看聚好的类别,每个样本所对应的簇数
y_pred = cluster.labels_
print(y_pred)
★ 重要属性labels_,查看聚好的类别,每个样本所对应的簇数

返回顶部
☠ 注意 predict 和 fit_ predict
- KMeans因为并不需要建立模型或者预测结果,因此我们只需要fit就能够得到聚类结果了
KMeans也有接口 predict和fit_ predict,表示学习数据x并对的类进行预测。但所得到的结果和我们不调用predict,直接fit之后调 labels 用属性一模一样。- predict常用于大数据集的形式,假设1000万条数据,全部用KMeans().fit()去一轮一轮的查找,效率极低此时可以对数据集进行切片,切取小部分数据进行fit得到准确的质心,再将整个数据集放到predict中进行预测.
- 注意:仅适用于超大数据集,对结果不需要十分精确的情况下,因为毕竟不是将所有的数据集进行KMeans计算的,结果集只会无限逼近。
pre = cluster.fit_predict(x)
print(pre)
print(pre==y_pred)
- 这里全部一致是因为cluster全是用KMeans计算的~

当我们区部分数据集进行KMeans计算后,再将全部数据集通过已经计算好的质心进行推算,最后比较,就会发现有不同的,所以使用predict()是有缺陷的。
cluster_small = KMeans(n_clusters=n_clusters,random_state=0).fit(x[:200])
y_pred_ = cluster_small.predict(x)
print(y_pred_==y_pred)

返回顶部
★ 重要属性cluster_centers_,查看质心
# 4.重要属性cluster_centers_,查看质心
centroid = cluster.cluster_centers_
print(centroid)
print(centroid.shape) # (3,2)
[[-7.09306648 -8.10994454]
[-1.54234022 4.43517599]
[-8.0862351 -3.5179868 ]]
通过cluster_centers_查看计算得到的质心,最终得到3个质心,并且含有2个特征。
返回顶部
★ 重要属性inertia_,查看总距离平方和
# 4.重要属性inertia_,查看总距离平方和
inertia = cluster.inertia_
print(inertia)
# 1903.4503741659223
通过inertia_查看总距离平方和(total inertia)。对于一个簇来说,所有的样本点到质心的距离之和越小,那么簇中的样本越相似,簇内的差异就越小。我们无法根据现有的条件判断得出的结果是好还是差,只能说得出这样一个值,具体要看更加细致的业务状况。
返回顶部
③ 结果可视化
# 绘制点的分布
color = ["red","pink","orange","gray"]
fig , axl = plt.subplots(1)
# 绘制ax1图形
# 画出不同簇的图
for i in range(3):
# 对聚类的y_pred进行分簇展示
axl.scatter(x[y_pred==i,0], # 横坐标
x[y_pred==i,1], # 纵坐标
marker='o', # 点的形状
s=8, # 点的大小,
color=color[i]
)
# 绘制每个簇的质心
axl.scatter(centroid[:,0],centroid[:,1],
marker='x',
s=15,
c="black"
)
plt.show()
可以清晰的看出,通过KMeans聚类计算出了3簇数据,但是3是否是最佳的质心数呢?接下来我们遍历计算一下。

返回顶部
④ 检验质心数
# 7.检验质心数
inertia_list = []
for i in range(1,20):
cluster = KMeans(n_clusters=i,random_state=0).fit(x)
inertia = cluster.inertia_
inertia_list.append(inertia)
print(inertia_list)
[15767.554546172281, 3735.4056749295637, 1903.4503741659223, 908.3855684760613, 811.0952123653019, 728.2271936260031,
647.872583726755, 582.001129497752, 529.8114835823906, 474.9561954014432, 429.9216838743275, 393.73361586234404,
363.1038302591066, 339.9252187572733, 314.32149254897047, 297.9488816311707, 282.30990282094433, 270.3791269138576,
256.3660534768043]
我们可以发现,当更改n_clusters的时候,inertia会越来越小,如此下去最终甚至等于0。之前说过KMeans追求的是,求解能够让 inertia 最小化的质心,而这样一来,改变了n_clusters,同时会对聚类结果有影响。创建数据集的时候,是按照4个类来设定的,按照常理,聚类为4的时候应当是最小的,可现在以inertia为判定显然不合适。所以综上,inertia不是对聚类结果很好的一个评判依据。
返回顶部
三、聚类的模型评估指标
面试高危问题:如何衡量聚类算法的效果?
- 聚类模型的结果不是某种标签输出,并且聚类的结果是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。那我们如何衡量聚类的效果呢?
- 记得上面说过, KMeans的目标是确保"簇内差异小,簇外差异大”,我们就可以通过衡量簇内差异来衡量聚类的效果。并且 Inertia是用距离来衡量簇内差异的指标,因此,我们是否可以使用 Inertia来作为聚类的衡量指标呢?
- 可以,但是这个指标的缺点和极限太大。
- 首先,它不是有界的。我们只知道, InaInertia越小越好,是0最好,但我们不知道,一个较小的究竟有没有达到模型的极限,能否继续提高(正如上面所述)。
- 第二,它的计算太容易受到特征数目的影响,数据维度很大的时候, Inertia的计算量会陷入维度诅咒之中,计算量会爆炸,不适合用来一次次评估模型。
- 第三,它会受到超参数K的影响,在上面的尝试中其实我们已经发现,随着K越大, Inertia注定会越来越小,但这并不代表模型的效果越来越好了。
- 第四, Inertia对数据的分布有假设,它假设数据满足凸分布(即数据在二维平面图像上看起来是一个凸函数的样子),并且它假设数据是各向同性的(isotropic),即是说数据的属性在不同方向上代表着相同的含义。但是现实中的数据往往不是这样。所以使用 Inertia作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳。

◑ 真实标签已知 ---- 几乎不可能
① 互信息分

返回顶部
② V-measure

返回顶部
③ 调整兰德系数

返回顶部
◑ 真实标签未知
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚类,是完全依赖于评价
簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。
① 轮廓系数
- 轮廓系数是最常用的聚类算法的评价指标它是对每个样本来定义的,它能够同时衡量:
- 1.样本与其自身所在的簇中的其他样本的相似度 a,a等于样本与同一簇中所有其他点之间的平均距离
- 2.样本与其他簇中的样本的相似度b,b等于样本与下一个最近的簇中得所有点之间的平均距离
根据聚类的要求簇内差异小,簇外差异大,我们希望b永远大于a,并且大得越多越好.

返回顶部
◐ 公式

很容易理解轮廓系数范围是(-1,1):
- 其中值越接近1,表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似。
- 当轮廓系数为0时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。
- 如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的聚类的超参数K可能设定得太大或者太小。
- 如果一个簇中的大多数样本具有比较高的轮廓系数,则簇会有较高的总轮廓系数,则整个数据集的平均轮廓系数越高,则聚类是合适的。
注意:轮廓系数针对的是每一个样本,并不是一个簇或是整个数据集!!!
返回顶部
◐ 轮廓系数应用
在sklearn中,我们使
用metrics模块中的类silhouette_score来计算轮廓系数,它返回的是一个数据集中所有样本的轮廓系数的均值。
但我们还有同在metrics 模块中的 silhouette_sample,它的参数与轮廓系数一致,但返回的是数据集中每个样本自己的轮廓系数。
# 8.轮廓系数应用
# 导包
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
# silhouette_score(特征矩阵,聚类结果)
result_score = silhouette_score(x,y_pred)
print(result_score) # 0.5882004012129721
# silhouette_samples(特征矩阵,聚类结果)
result_samples = silhouette_samples(x,y_pred)
print(result_samples)
# [ 0.62982017 0.5034877 0.56148795 0.84881844 0.56034142 0.78740319
# 0.39254042 0.4424015 0.48582704 0.41586457 0.62497924 0.75540751
# 0.50080674 0.8452256 0.54730432 0.60232423 0.54574988 0.68789747
# 0.86605921 0.25389678 0.49316173 0.47993065 0.2222642 0.8096265
# 0.54091189 0.30638567 0.88557311 0.84050532 0.52855895 0.49260117
# 0.65291019 0.85602282 0.47734375 0.60418857 0.44210292 0.6835351
# 0.44776257 0.423086 0.6350923 0.4060121 0.54540657 0.5628461
# .....]
接下来运用轮廓系数来检验KMeans计算的结果:
silhouette_score
# 9.利用轮廓系数检验质心数
inertia_list = []
for i in range(3,10):
cluster = KMeans(n_clusters=i,random_state=0).fit(x)
y_pred = cluster.labels_
result_score = silhouette_score(x, y_pred)
inertia_list.append(result_score)
print(inertia_list)
# [0.5882004012129721, 0.6505186632729437, 0.5737098048695828, 0.45415548963886687, 0.3736670158493806,
# 0.34430153505097266, 0.3229799422780043]
silhouette_samples
for i in range(3,6):
cluster = KMeans(n_clusters=i,random_state=0).fit(x)
y_pred = cluster.labels_
result_samples = silhouette_samples(x, y_pred)
print(result_samples)
# k=3
# [ 0.62982017 0.5034877 0.56148795 0.84881844 0.56034142 0.78740319
# 0.39254042 0.4424015 0.48582704 0.41586457 0.62497924 0.75540751
# 0.50080674 0.8452256 0.54730432 0.60232423 0.54574988 0.68789747
# k=4
# [ 0.62903385 0.43289576 0.55834047 0.82660742 0.35213124 0.74123252
# 0.68902347 0.58705868 0.04062548 0.73241492 0.59363669 0.75135825
# 0.66326503 0.81480193 0.45066007 0.59477448 0.10348453 0.66633309
# k=5
# [ 0.33602816 0.49563961 0.56874701 0.82588594 0.35586634 0.74003963
# 0.69497001 0.59361364 0.04170062 0.73774366 0.47620047 -0.01021173
# 0.67057392 0.81392458 0.45520941 0.43815157 0.10407067 0.25539995
可以发现当聚类的k从3-9的时候,果然不论是整体平均轮廓系数还是每个样本的轮廓系数都会逐渐降低。这就说明,使用轮廓系数可以基本有效的对KMeans结果进行评估。
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过 DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
返回顶部
② 其他评估方法
卡林斯基-哈拉巴斯指数

# 10.卡林斯基-哈拉巴斯指数
from sklearn.metrics import calinski_harabasz_score
result_calinski = calinski_harabasz_score(x,y_pred)
print(result_calinski) # 2281.9291919639886
虽然calinski_harabasz指数没有界,在凸型的数据上的聚类也会表现虚高。但是比起轮廓系数,它的计算速度非常快。下面使用时间戳计算运行时间:
# 11.计算calinski_harabasz运行时间
from time import time
# time():记下每一次time()命令运行的时间戳
t0 = time()
calinski_harabasz_score(x,y_pred)
t1 = time()
print(t1-t0) # 0.0009970664978027344
t0 = time()
silhouette_score(x,y_pred)
t1 = time()
print(t1-t0) # 0.0069806575775146484
通过对比轮廓系数与卡林斯基-哈拉巴斯指数的运行时间,可以很明显的看出卡林斯基-哈拉巴斯指数的运行时间远远短于轮廓系数的运行时间。
补充:时间戳具体化
# time() --- 返回的是一串数字,代表了时间
# 时间戳可以通过datetime中的函数fromtimestamp转换成真正的时间格式
import datetime
t0 = time()
print(t0) # 1609945169.027957
date = datetime.datetime.fromtimestamp(t0).strftime("%Y-%m-%d %H:%M:%S")
print(date) # 2021-01-06 22:59:29
返回顶部
四、案例:基于轮廓系数来选择 n_clusters
通过绘制轮廓系数分布图和聚类后的数据分布图来选择最佳n_clusters
◑ 准备工作(数据集、画布)
# -*- coding: utf-8
# @Time : 2021/1/6 23:07
# @Author : ZYX
# @File : Example2.py
# @software: PyCharm
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm # colormap
import pandas as pd
import numpy as np
# 基于轮廓系数来选择最佳的n_clusters
# 知道每个聚出来的类的轮廓系数是多少,还有一个各个类之间的轮廓系数的对比
# 知道聚类完毕之后图像的分布是什么模样
# 创建数据集
x , y = make_blobs(n_samples=500, # 500个数据
n_features=2, # 两个特征 --- 绘制平面图
centers=4,
random_state=1) # 保证每次创建的数据集一样
# 1.设置分成的簇数
n_clusters = 4
# 2.创建一个画布,画布上共有一行两列两个图
fig,(ax1,ax2) = plt.subplots(1,2)
# 2.1 设置画布尺寸 --- 两个图,每个长度9,宽度7
fig.set_size_inches(18,7)
# 2.2 设置坐标刻度
# 第一个图是我们的轮廓系数图,是由各个簇的轮廓系数组成的横向条形图
# 横向条形图的横坐标是轮廓系数取值,纵坐标是每个样本
# 轮廓系数取值范围在[-1,1],但至少希望罗扩系数要大于0,并且便于可视化,设定x在[-0.1,1]
ax1.set_xlim([-0.1,1])
# 纵坐标[0,x.shape[0]] --- 这里进行优化,对不同簇之间进行分隔,加上一个距离(n_clusters+1)*10
ax1.set_ylim([0,x.shape[0]+(n_clusters+1)*10])
返回顶部
◑ KMeans聚类、评估
# 3.开始建模,调用聚类好的标签
clusterer = KMeans(n_clusters=n_clusters,random_state=10).fit(x)
cluster_labels = clusterer.labels_
# 4.使用轮廓系数进行评测
# 计算整体的平均轮廓系数
silhouette_avg = silhouette_score(x,cluster_labels)
# 打印输出
print("For n_clusters=",n_clusters,";The average silhouette_score is:",silhouette_avg)
# For n_clusters= 4 ;The average silhouette_score is: 0.6505186632729437
# 计算每个样本点的轮廓系数 --- 横坐标
sample_silhouette_values = silhouette_samples(x,cluster_labels)
返回顶部
◑ 可视化:绘制各个簇之间的轮廓系数的对比图
# 设置y轴上的初始取值
y_lower = 10
# 5.绘制第一张图
# 对每一个簇进行循环
for i in range(n_clusters):
# 从每个样本的轮廓系数结果中抽取第i个簇的每个样本的轮廓系数,并对他进行排序
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
# 排序
ith_cluster_silhouette_values.sort()
# 查看这一个簇中的样本数量
size_cluster_i = ith_cluster_silhouette_values.shape[0]
# 这一个簇在y轴上的取值,应当是由初始值y_lower开始,到该簇中的样本数量计数(y_upper)
y_upper = y_lower + size_cluster_i
# colormap库中的,使用小数来调用颜色的函数
# 在nipy_spectral([输入意小数来代表一个颜色])
# 在这里我们希望每个簇的颜色是不同的,我们需要的颜色种类刚好是循环的个数的种类
# 在这里,只要能够确保,每次循环生成的小数是不同的,可以使用任意方式来获取小数
# 在这里,我用的浮点数除以n_clusters,在不同的i下,自然生成不同的小数
# 以确保所有的簇会有不同的颜色
color = cm.nipy_spectral(float(i) / n_clusters)
# 开始填充子图中的内容
# fill_between是一个范围中的柱状图都统一颜色的函数
# fill_betweenx的直角是在纵坐标上
# fill_betweeny的直角是在横坐标上
# fill_betweenx的参数应该输入(定义曲线的点的横坐标,定义曲线的点的纵坐标,x轴的取值,柱状图的颜色)
ax1.fill_betweenx(np.arange(y_lower,y_upper),
ith_cluster_silhouette_values,
facecolor=color,
alpha=0.7
)
# 为每个簇的轮廓系数写上簇的编号,并且让簇的编号显示坐标轴上每个条形图的中间位置
# text的参数为(要显示编号的位置的横坐标,要显示编号的位置的纵坐标,要显示的编号内容)
ax1.text(-0.05,y_lower+0.5*size_cluster_i,str(i))
# 为下一个簇计算新的轴上的初始值, 是每一次迭代之后, y的上线再加上10
# 以此来保证,不同的的图像之间显示有空隙
y_lower = y_upper +10
#给图1加上标题,横坐标轴,纵座标轴的标签
ax1.set_title("The silhouette plot for the various clusters. ")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#把整个数据集上的轮廓系数的均值以虚线的形式放入我们的图中
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
#让y轴不显示任何刻度
ax1.set_yticks([])
#让x轴上的刻度显示为我们规定的列表
ax1.set_xticks([-0.1,0,0.2,0.4,0.6,0.8,1])
返回顶部
◑ 可视化:绘制聚类散点图
#开始对第二个图进行处理,首先获取新颜色,由于这里没有循环,因此我们需要一次性生成多个小数来获取多个颜色
colors = cm.nipy_spectral(cluster_labels.astype(float)/n_clusters)
ax2.scatter(x[:,0], x[:,1],
marker='o',#点的形状
s=8,#点的大小
c=colors
)
# 把生成的质心放到图像中去
centers = clusterer.cluster_centers_
# Draw white circles at cLuster centers
ax2.scatter(centers[:,0], centers[:,1], marker='x',c="red", alpha=1,s=200)
# 为图二设置标题,横坐标标题,纵坐标标题
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
# 为整个图设置标题
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data with n_clusters =%d" % n_clusters),
fontsize=14, fontweight='bold')
plt. show()

通过图一绘制整体数据集平均轮廓系数,可以清晰的看出每个簇的聚类效果好差。轮廓系数越接近1越好,从整体上来看,1号簇的聚类效果较好。
#把整个数据集上的轮廓系数的均值以虚线的形式放入我们的图中
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
返回顶部
五、遍历n_cluster查找最优
这里采用了循环,将上述代码包装进去,依次绘制出n_cluster=2,、3、4、5、6、7时的图像。
◑ 代码可视化
# -*- coding: utf-8
# @Time : 2021/1/7 8:59
# @Author : ZYX
# @File : Example3_包装循环对比.py
# @software: PyCharm
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm # colormap
import pandas as pd
import numpy as np
# 基于轮廓系数来选择最佳的n_clusters
# 知道每个聚出来的类的轮廓系数是多少,还有一个各个类之间的轮廓系数的对比
# 知道聚类完毕之后图像的分布是什么模样
# 创建数据集
x , y = make_blobs(n_samples=500, # 500个数据
n_features=2, # 两个特征 --- 绘制平面图
centers=4,
random_state=1) # 保证每次创建的数据集一样
# 遍历n_clusters,对比查找最优n_clusters
for n_clusters in range(2,8):
# 2.创建一个画布,画布上共有一行两列两个图
fig,(ax1,ax2) = plt.subplots(1,2)
# 2.1 设置画布尺寸 --- 两个图,每个长度9,宽度7
fig.set_size_inches(18,7)
# 2.2 设置坐标刻度
# 第一个图是我们的轮廓系数图,是由各个簇的轮廓系数组成的横向条形图
# 横向条形图的横坐标是轮廓系数取值,纵坐标是每个样本
# 轮廓系数取值范围在[-1,1],但至少希望罗扩系数要大于0,并且便于可视化,设定x在[-0.1,1]
ax1.set_xlim([-0.1,1])
# 纵坐标[0,x.shape[0]] --- 这里进行优化,对不同簇之间进行分隔,加上一个距离(n_clusters+1)*10
ax1.set_ylim([0,x.shape[0]+(n_clusters+1)*10])
# 3.开始建模,调用聚类好的标签
clusterer = KMeans(n_clusters=n_clusters,random_state=10).fit(x)
cluster_labels = clusterer.labels_
# 4.使用轮廓系数进行评测
# 计算整体的平均轮廓系数
silhouette_avg = silhouette_score(x,cluster_labels)
# 打印输出
print("For n_clusters=",n_clusters,";The average silhouette_score is:",silhouette_avg)
# For n_clusters= 4 ;The average silhouette_score is: 0.6505186632729437
# 计算每个样本点的轮廓系数 --- 横坐标
sample_silhouette_values = silhouette_samples(x,cluster_labels)
# 设置y轴上的初始取值
y_lower = 10
# 5.绘制第一张图
# 对每一个簇进行循环
for i in range(n_clusters):
# 从每个样本的轮廓系数结果中抽取第i个簇的轮廓系数,并对他进行排序
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
# 排序
ith_cluster_silhouette_values.sort()
# 查看这一个簇中的样本数量
size_cluster_i = ith_cluster_silhouette_values.shape[0]
# 这一个簇在y轴上的取值,应当是由初始值y_lower开始,到该簇中的样本数量计数(y_upper)
y_upper = y_lower + size_cluster_i
# colormap库中的,使用小数来调用颜色的函数
# 在nipy_spectral([输入意小数来代表一个颜色])
# 在这里我们希望每个簇的颜色是不同的,我们需要的颜色种类刚好是循环的个数的种类
# 在这里,只要能够确保,每次循环生成的小数是不同的,可以使用任意方式来获取小数
# 在这里,我用的浮点数除以n_clusters,在不同的i下,自然生成不同的小数
# 以确保所有的簇会有不同的颜色
color = cm.nipy_spectral(float(i) / n_clusters)
# 开始填充子图中的内容
# fill_between是一个范围中的柱状图都统一颜色的函数
# fill_betweenx的直角是在纵坐标上
# fill_betweeny的直角是在横坐标上
# fill_betweenx的参数应该输入(定义曲线的点的横坐标,定义曲线的点的纵坐标,x轴的取值,柱状图的颜色)
ax1.fill_betweenx(np.arange(y_lower,y_upper),
ith_cluster_silhouette_values,
facecolor=color,
alpha=0.7
)
# 为每个簇的轮廓系数写上簇的编号,并且让簇的编号显示坐标轴上每个条形图的中间位置
# text的参数为(要显示编号的位置的横坐标,要显示编号的位置的纵坐标,要显示的编号内容)
ax1.text(-0.05,y_lower+0.5*size_cluster_i,str(i))
# 为下一个簇计算新的轴上的初始值, 是每一次迭代之后, y的上线再加上10
# 以此来保证,不同的的图像之间显示有空隙
y_lower = y_upper +10
#给图1加上标题,横坐标轴,纵座标轴的标签
ax1.set_title("The silhouette plot for the various clusters. ")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#把整个数据集上的轮廓系数的均值以虚线的形式放入我们的图中
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
#让y轴不显示任何刻度
ax1.set_yticks([])
#让x轴上的刻度显示为我们规定的列表
ax1.set_xticks([-0.1,0,0.2,0.4,0.6,0.8,1])
#开始对第二个图进行处理,首先获取新颜色,由于这里没有循环,因此我们需要一次性生成多个小数来获取多个颜色
colors = cm.nipy_spectral(cluster_labels.astype(float)/n_clusters)
ax2.scatter(x[:,0], x[:,1],
marker='o',#点的形状
s=8,#点的大小
c=colors
)
# 把生成的质心放到图像中去
centers = clusterer.cluster_centers_
# Draw white circles at cLuster centers
ax2.scatter(centers[:,0], centers[:,1], marker='x',c="red", alpha=1,s=200)
# 为图二设置标题,横坐标标题,纵坐标标题
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
# 为整个图设置标题
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data with n_clusters =%d" % n_clusters),
fontsize=14, fontweight='bold',va='top')
plt.show()
返回顶部
◑ 结果展示

当n_cluster等于2的时候,虽然总平均轮廓系数很高,具体到每个簇来看,也都有较高的样本轮扩系数,较为良好
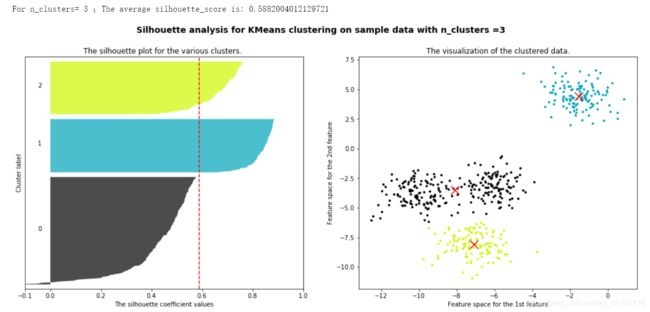
当n_cluster等于3的时候,总平均轮廓系数一般,具体到每个簇来看,灰色簇明显是拉低了整体轮廓系数的,甚至出现了负数。

当n_cluster等于4的时候,总平均轮廓系数较高,具体到每个簇来看,都有对轮廓系数做出贡献,较为良好。

当n_cluster等于5的时候,总平均轮廓系数一般,具体到每个簇来看,3、5两个簇明显低于平均轮廓系数,聚类效果较差。
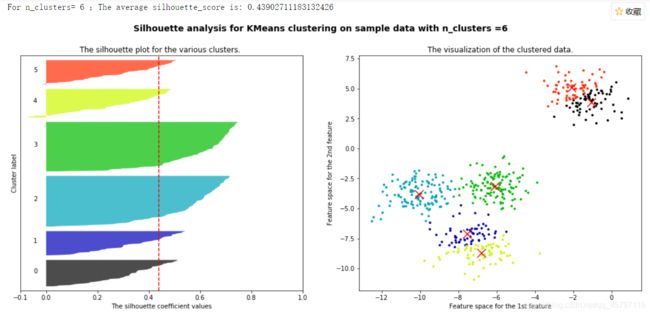
当n_cluster等于6的时候,总平均轮廓系数较低,具体到每个簇来看,4、5两个簇明显含有低于平均轮廓系数,聚类效果较差。

当n_cluster等于7的时候,总平均轮廓系数较低,具体到每个簇来看,虽然每个簇都对轮廓系数有贡献,但是2、7两个簇明显含有低于平均轮廓系数,聚类效果较差。
返回顶部
◑ 分析


根据结果显示,当n_cluster=2时,具有最大的轮廓系数;当n_cluster=4的时候,具有较高的轮廓系数以及细致的聚类,那么该如何选择?
其实两者总和考虑都是可以的,具体的要看实际的业务需求(本人没啥实习经验,姑且这么考虑一下~)。想想也是这样,根据公司业务具体来看,你只需要简单些,那么就没有必要去选择4簇的人群,制定4套业务方案,耗钱又耗时;但是如果业务需要尽可能详细的,那么选择4簇方案无疑,不可能那个2簇的方案去糊弄,实事求是。
返回顶部
六、重要参数 init、random_state、n_init

- init
在 K-Means中有一个重要的环节,就是放置初始质心。如果有足够的时间, K-means一定会收敛,但可能收敛到局部最小值是否能够收敛到真正的最小值很大程度上取决于质心的初始化。init就是用来帮助我们决定初始化方式的参数。

# n_iter_ --- 运行的迭代次数
t0 = time()
plus = KMeans(n_clusters=10).fit(x)
t1 = time()
print(t1-t0) # 0.05385589599609375
print(plus.n_iter_) # 11 8 7 14 9 5 10 7
t2 = time()
random = KMeans(n_clusters=10,init="random",random_state=420).fit(x)
t3 = time()
print(t3-t2) # 0.03390955924987793
print(random.n_iter_) # 11 11 11 11 11 11 11 11
通过结果可以发现使用默认的k-means++方式初始化比random初始化方式迭代的次数要少(不排除多的可能),但是k-means运行的时间却要比random长,可能是内部计算导致。
-
random_state
初始质心放置的位置不同,聚类的结果很可能也会不一样,一个好的质心选择可以让k-Means避免更多的计算,让算法收敛稳定且更快。
在之前讲解初始质心的放置时,我们是使用随机的方法在样本点中抽取k个样本作为始质心,这种方法显然不符合稳定且更快的需求。
为此,我们可以使用 random_state数来控制每次生成的初始质心都在相同位置,甚至可以画学习曲线来确定最优的random_state是哪个整数。

-
n_init
一个random_ state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则 sklearnK-means中的并不会只选择一个随机模式扔出结果,而会在每个随机数种子下运行多次,并使用结果最好的一个随机数种子来作为初始质心。我们可以使用参数n_init来选择,每个随机数种子下运行的次数。
这个参数不常用到,默认10次,如果我们希望运行的结果更加精确,那我们可以增加这个参数n_nit的值来增加每个随机数种子下运行的次数,但是这种方法依然是基于随机性的。

七、重要参数 max_iter、tol
上文曾经讲述到,当质心不再改变的时候,KMeans算法就结束。有时候我们选择的n_cluster并不符合数据集的自然分布,但是又为了能够尽可能的提升结果效果,可以提前结束迭代提高模型的表现。这时就可以用到max_iter(最大迭代次数)、tol(两次迭代之间inertia的下降量)来控制迭代的进程。
![]()

from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 创建数据集
x , y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
random = KMeans(n_clusters=10,init="random",max_iter=10,random_state=421).fit(x)
y_pred_max10 = random.labels_
print(silhouette_score(x,y_pred_max10)) # 0.3288727090246361
random1 = KMeans(n_clusters=10,init="random",max_iter=30,random_state=420).fit(x)
y_pred_max20 = random1.labels_
print(silhouette_score(x,y_pred_max20)) # 0.3266869793678966
很明显,一个迭代10次,一个迭代30次,10次的轮廓系数会高于30次的
返回顶部
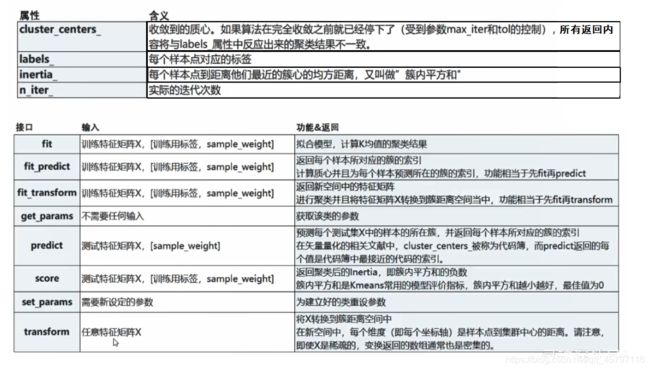
八、总结回顾重要属性与接口
返回顶部
十、cluster.k_means()函数的使用
def k_means(X, n_clusters, sample_weight=None, init='k-means++',
precompute_distances='auto', n_init=10, max_iter=300,
verbose=False, tol=1e-4, random_state=None, copy_x=True,
n_jobs=None, algorithm="auto", return_n_iter=False):
详细参数解释转到官方文档~

from sklearn.datasets import make_blobs
from sklearn.cluster import k_means
from sklearn.metrics import silhouette_score
# 创建数据集
x , y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
# 使用k_means()函数
# 数据集、n_cluster、是否返回最佳迭代次数
result = k_means(x,4,return_n_iter=True)
print(result)
结果
(array([[ -7.09306648, -8.10994454], # 质心坐标
[ -1.54234022, 4.43517599],
[-10.00969056, -3.84944007],
[ -6.08459039, -3.17305983]]),
# 聚类标签
array([0, 0, 2, 1, 3, 1, 3, 3, 3, 3, 0, 0, 3, 1, 3, 0, 3, 0, 1, 3, 2, 2,
3, 1, 3, 3, 1, 1, 2, 3, 0, 1, 3, 0, 3, 0, 2, 2, 0, 2, 3, 2, 1, 3,
3, 0, 2, 3, 1, 1, 1, 2, 2, 3, 0, 2, 2, 2, 2, 3, 1, 1, 2, 3, 1, 3,
0, 3, 2, 2, 0, 2, 3, 0, 3, 3, 0, 3, 3, 2, 1, 1, 2, 1, 1, 2, 2, 1,
2, 2, 1, 0, 2, 3, 1, 0, 0, 3, 0, 1, 1, 0, 1, 2, 1, 3, 3, 1, 1, 2,
3, 0, 1, 2, 1, 2, 1, 3, 1, 3, 2, 0, 0, 2, 3, 2, 1, 0, 0, 3, 1, 2,
2, 2, 2, 0, 1, 3, 1, 1, 3, 0, 3, 1, 1, 1, 3, 3, 0, 0, 2, 2, 1, 0,
1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 0, 0, 0, 3, 1, 0, 2, 3, 0, 1, 2,
2, 2, 2, 0, 3, 2, 1, 0, 0, 2, 3, 0, 0, 3, 1, 1, 0, 0, 3, 1, 3, 0,
0, 1, 0, 2, 1, 3, 3, 0, 3, 2, 0, 3, 2, 3, 2, 0, 3, 3, 3, 1, 2, 1,
3, 0, 2, 3, 2, 2, 2, 1, 2, 1, 0, 2, 0, 2, 1, 1, 2, 0, 1, 0, 3, 2,
0, 0, 0, 0, 3, 2, 0, 2, 3, 1, 1, 3, 3, 1, 2, 3, 2, 1, 3, 1, 2, 2,
1, 3, 0, 0, 2, 2, 2, 3, 1, 1, 3, 1, 2, 0, 1, 0, 1, 0, 0, 1, 0, 1,
1, 3, 2, 2, 2, 3, 3, 2, 0, 1, 0, 0, 0, 3, 2, 3, 0, 2, 0, 0, 2, 0,
0, 2, 1, 0, 3, 3, 1, 1, 2, 0, 1, 1, 3, 0, 1, 1, 3, 2, 1, 2, 3, 0,
0, 1, 2, 0, 3, 1, 1, 3, 3, 3, 0, 3, 1, 1, 2, 1, 1, 1, 1, 0, 0, 3,
1, 2, 3, 0, 1, 2, 1, 3, 1, 2, 3, 2, 1, 3, 3, 0, 1, 0, 0, 0, 0, 0,
0, 2, 0, 1, 0, 1, 1, 2, 1, 3, 2, 2, 0, 1, 2, 1, 3, 0, 2, 2, 0, 2,
2, 1, 1, 0, 2, 3, 1, 3, 3, 0, 0, 3, 0, 2, 2, 0, 2, 0, 2, 1, 0, 1,
2, 3, 1, 2, 3, 1, 0, 3, 1, 1, 2, 3, 2, 3, 0, 1, 0, 3, 1, 0, 0, 0,
2, 1, 3, 0, 3, 3, 2, 2, 0, 3, 3, 3, 3, 3, 3, 0, 3, 2, 0, 3, 1, 3,
1, 3, 2, 2, 1, 1, 1, 2, 3, 2, 0, 2, 1, 3, 0, 1, 0, 1, 0, 3, 1, 1,
0, 2, 3, 0, 2, 2, 2, 0, 3, 1, 2, 3, 0, 0, 0, 3]),
# 簇内平方和
908.3855684760613,
#最佳迭代次数
3)
- k_means()函数和KMeans()类的参数使用基本一致,在普通情况下可以直接使用k_means()函数来进行完成。
返回顶部
本文章是通过学习菜菜老师的课堂,最后个人总结的学习笔记,感谢菜菜老师提供的技术讲解!