预备知识:
1、Ngram语言模型:
》该模型基于这样一种假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
》假设一个字符串w=w1w2….wn; wi可以是一个字,一个词或者一个短语,我们把一个可以计算 P(W) 或者P(wn|w1,w2…wn-1) 的模型称为语言模型,Language model,或者写成LM。
》目的:在给定语料库中,计算一个字符串出现的概率问题。
作用:a、机器翻译 P(high winds tonight) > P(large winds tonight);b、拼写纠正,The office is about fifteen minuets from my house P(about fifteen minutes from) > P(about fifteen minuets from);c、语音识别 P(I saw a van) >> P(eyes awe of an);d、文本分类;还有自动摘要生成、问答系统等。
》如何计算字符串W出现的概率,即如何计算p(w)
例如:如何计算P(its, water, is, so, transparent, that)出现的概率呢?
这就涉及联合概率和条件概率的知识了。
回顾一下联合概率公式:
P(A,B,C,D) = P(A)P(B|A)P(C|A,B)P(D|A,B,C) (1)
一般地: P(x1,x2,x3,…,xn) = P(x1)P(x2|x1)P(x3|x1,x2)…P(xn|x1,…,xn-1) (2)
即
所以字符串“its water is so transparent”出现的概率计算方法是
P(“its water is so transparent”) =
P(its) × P(water|its) × P(is|its water)
× P(so|its water is) × P(transparent|its water is so)
但是,但我们计算P(wn|w1,w2…wn-1)的时候,比如

由于要计算wi出现的概率,就要去统计前i-1词出现的情况,假设词库中有M个词,就有M^(i-1)种可能,这样导致计算量太大了。
于是,我们做一个简单的马尔科夫假设(Markov Assumption):假设第i个词出现的概率只与前面的N--1个词有关,这就是N-gram语言模型的由来。比如计算 的概率时候,我们假设单词the出现的概率只与前面出现的一个词有关,那么
。
因此,在假设第i个词出现的概率只与前面的N-1个词出现有关的前提下,在计算p(wi|w1w2…wi-1)的时候,就变成了公式4,在计算p(w)=p(w1w2….wn)的时候就变成了公式5,这就是N-gram语言模型。
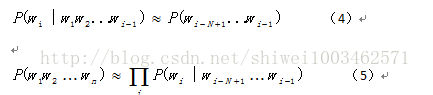
当N=1的时候,
,叫一元模型,Unigram model;
N=2的时候,
,叫二元模型,Bigram model;
当N=3的时候,
,叫 三元模型,trigram model;
好了,接下来针对二元模型,我们如何去估计这些概率参数呢?
用的方法就是最大似然估计,也就是公式(6)和(7)了!
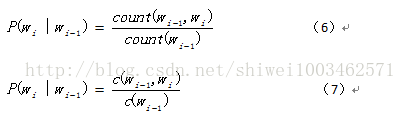
C(wi-1)表示词wi-1在语料库中出现的频数。
一、项目的整体工作流程:
后端:在hadoop上构建两个Job,一个用于从数据集构建Ngram Library,一个根据概率来构建Library model,生成数据导入database中。(N-gram)
前端:利用JQuery, PHP, Ajax来调用database数据,实现实时autocompletion,在网页端展示搜索引擎的Auto Completion 功能。
二、主要实现部分:
1、job1:
Map:从HDFS中读入数据集,拆分成2-n个单词的组合,发送给Reduce处理
Reduce:统计key出现的次数,结果输出至HDFS中。
2、job2:
Map:读取Job1 的处理结果,如读入的为: this is cool/t20,则将其处理为:outputkey:this is ,outputvalue:cool=20的形式,发送至Reduce
Reduce:接收的形式为如this ->