使用Python,OpenCV实现简单的场景边界/拍摄转换检测器
使用Python,OpenCV进行简单的场景边界/拍摄转换检测器
-
- 1. 效果图
- 2. 实现
-
- 2.1 步骤
- 2.2 什么是“场景边界”和“拍摄过渡”?
- 2.3 代码目录结构
- 2. 源码
- 参考
这篇博客起源于朋友分享蝙蝠侠7更新了,而我没有办法去最近的书店买书。于是下载了电子书,电子书已经实现了左击或者右击自动缩放、滚动。
然而我想自己通过计算机视觉的技术实现——自动从数字漫画中提取每个面板,缩放滚动等;
核心是场景边界检测算法,这篇博客将用100行代码实现此算法;
这篇博客介绍了如何使用OpenCV实现简单场景边界检测算法,并将该算法应用于数字漫画书籍,自动提取了漫画书的每个单独面板。您也可以使用您自己的视频。
1. 效果图
原始视频帧 VS Mask VS 截取的动画帧
过程图
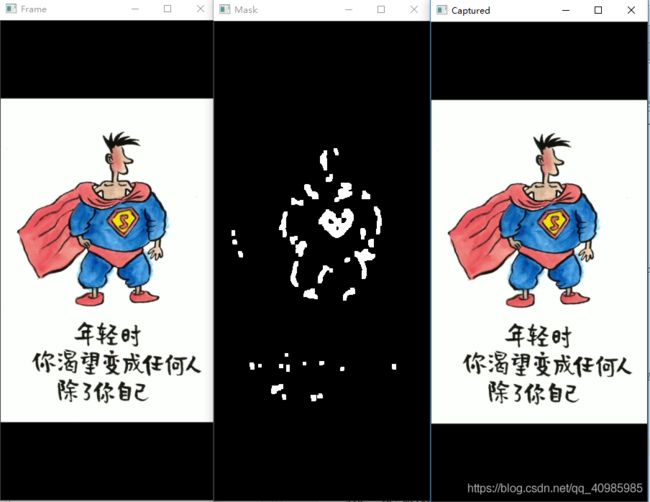
2. 实现
2.1 步骤
- 当正在阅读Comixology App中的漫画时,记录iPhone屏幕;
- 通过使用OpenCV来检测漫画应用完成缩放,滚动等时的后处理视频;
- 将当前的漫画书面板保存到磁盘;
- 重复视频的整个长度。
最终结果将是包含漫画书的每个单板的目录!
2.2 什么是“场景边界”和“拍摄过渡”?
最常见的场景边界是“淡入黑色”,从一个场景到一个场景的过渡;
通过实际应用程序应用场景边界检测 - 从数字漫画书自动提取帧/面板。
场景过渡可以进行检测前景的非黑像素,达到某个值;
2.3 代码目录结构
2. 源码
# 它读取输入视频,然后脚本运行边界场景检测方法以从视频中提取帧。每个帧将导出到输出/output
# 实现基本场景边界检测器,稍后会用于从漫画书中提取面板。
# 该算法基于背景减法/运动检测 - 如果视频中的“场景”在视频中没有任何动作,那么认为漫画内容已完成滚动/缩放给面板,就可以捕获当前面板并将其保存到磁盘。
# USAGE
# python detect_scene.py --video xl.mp4 --output output
# 导入必要的包
import argparse
import imutils
import cv2
import os
# 构建命令行参数及解析
# --video 视频文件,必须项
# --output 漫画帧输出路径 必须项
# --min-percent 运动百分比默认下边界
# --max-percent 帧运动百分比的默认上边界。
# --暖身 构建背景模型的默认帧数
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True, type=str,
help="path to input video file")
ap.add_argument("-o", "--output", required=True, type=str,
help="path to output directory to store frames")
ap.add_argument("-p", "--min-percent", type=float, default=1.0,
help="lower boundary of percentage of motion")
ap.add_argument("-m", "--max-percent", type=float, default=10.0,
help="upper boundary of percentage of motion")
ap.add_argument("-w", "--warmup", type=int, default=200,
help="# of frames to use to build a reasonable background model")
args = vars(ap.parse_args())
# 初始化背景减法器模型
fgbg = cv2.bgsegm.createBackgroundSubtractorGMG()
# 初始化一个布尔值显示是否帧被捕获,以及俩个整数,一个是已捕获帧数,一个是已处理帧数
captured = False
total = 0
frames = 0
# 打开视频流指针,初始化帧的宽度合高度
vs = cv2.VideoCapture(args["video"])
(W, H) = (None, None)
# 遍历视频帧
while True:
# 获取视频帧
(grabbed, frame) = vs.read()
# 如果帧为None,表明已至视频结束,终止循环
if frame is None:
break
# 克隆当前帧,等比例缩放为宽度600(帧越小,算法越快),然后应用背景减法检测器
orig = frame.copy()
frame = imutils.resize(frame, width=300)
mask = fgbg.apply(frame)
# 应用一系列腐蚀膨胀清除噪音
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# 如果宽度、高度为None,获取mask的维度(宽、高)
if W is None or H is None:
(H, W) = mask.shape[:2]
# 计算前景mask的百分比
p = (cv2.countNonZero(mask) / float(W * H)) * 100
# 如果前景少于N%,则认为运动已停止,捕获当前帧并保存在磁盘
if p < args["min_percent"] and not captured and frames > args["warmup"]:
# 展示捕获的帧,并更新捕获变量
cv2.imshow("Captured", frame)
# cv2.waitKey(0) # 查看捕获帧
captured = True
# 构建输出帧路径及文件名,更新捕获帧计数器
filename = "{}.png".format(total)
path = os.path.sep.join([args["output"], filename])
total += 1
# 保存原始的高分辨率帧到磁盘
print("[INFO] saving {}".format(path))
cv2.imwrite(path, orig)
# 否则,帧场景正在变化,预热模型中,更新捕获变量为False
elif captured and p >= args["max_percent"]:
captured = False
# 显示帧并检测是否有按键
cv2.imshow("Frame", frame)
cv2.imshow("Mask", mask)
key = cv2.waitKey(1) & 0xFF
# 按下‘q’键,退出循环
if key == ord("q"):
break
# 增加已处理帧计数器
frames += 1
# 做一些清理工作,释放指针
vs.release()
参考
- https://www.pyimagesearch.com/2019/08/19/simple-scene-boundary-shot-transition-detection-with-opencv/