由于本人初学机器学习&Tensorflow,文章中若有错误,希望评论指出,不胜感谢。
一、Word2Vec问题是什么?
Word2Vec 即 Word to vector,词汇转向量。
我们希望词义相近的两个单词,在映射之后依然保持相近,词义很远的单词直接则保持很远的映射距离:如下图所示,这里介绍到了 t-SNE 方法可以很好的达到效果:
关于t-SNE这里推荐一篇文章:
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis

二、从实例代码中学习
起初看了网上很多资料,关于 Word2Vec 真心学的云里雾里。在 Tensorflow 中 Vector Representations of Words 字词的向量表示这一章卡了很久。于是我尝试看 word2vec_basic.py 的源码来理解一下Word2Vec最简单的实现。
看完200多行的源码, Tensorflow 自身的注释 就关于Word2Vec实例总结为6步:
- 下载数据
- 将原词汇数据转换为字典映射
- 为 skip-gram模型 建立一个扫描器
- 建立并训练 skip-gram 模型
- 开始训练模型
- 结果可视化
这里忽视第六步,从第1步到第5步,我将使用图片和一些代码来贯通Word2Vec整个过程。
首先打开下载进来的word词汇数据,由于是无监督学习,并没有标签,就只是整整100M大小文本数据。
这是第一步下载得到的数据:

然后开始第二步将原词汇数据转换为字典映射,比如我取出这段文本的头一句,它会进行如下变换:

现在我们的词汇文本变成了用数字编号替代的格式以及词汇表和逆词汇表。逆词汇只是编号为key,词汇为value。
接着开始第三步,为skip-gram 模型建立一个扫描器,首先看一下扫描器函数:
def generate_batch(batch_size, num_skips, skip_window):
batch_size是指一次扫描多少块,skip_window为左右上下文取词的长短,num_skips输入数字的重用次数。假设我们的扫描器先扫这大段文字的前8个单词,左右各取1个单词,重用次数为2次。我们就会观察到如下结果:
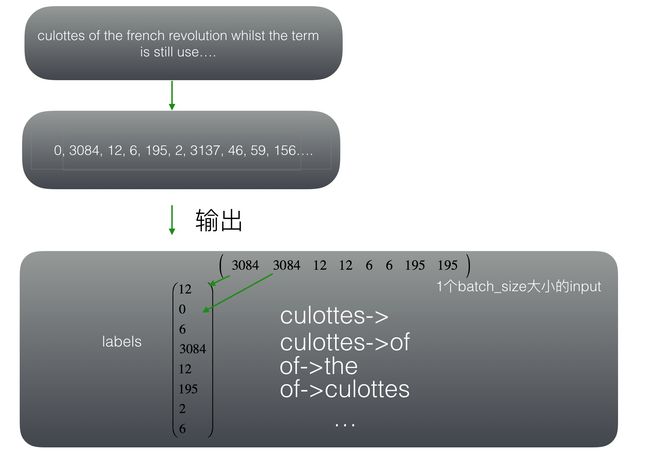
现在通过上面一步,我们构造出了input和label,就可以进行监督学习,下面

什么是NCE Loss呢?这里为什么不用更为常见的Softmax + Cross-Entropy 呢?
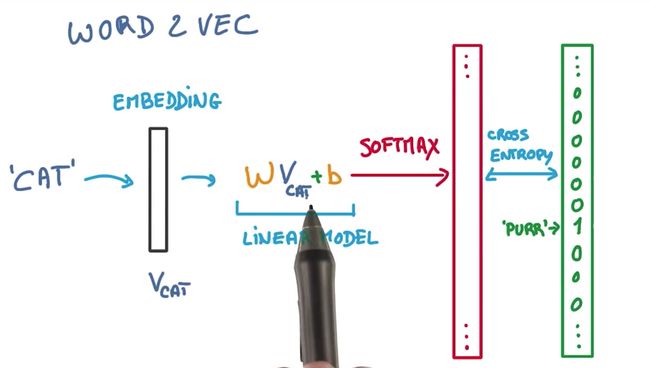
因为如果在这里使用Softmax + Cross-Entropy作为损伤函数会有一个问题,Softmax当有几万+的分类时,速率会大大下降。
其速度对比如下:
10000 个类,Softmax每秒处理 10000 个样本,NCE每秒处理 30000 个样本
100000 个类,Softmax每秒处理 1000 个样本,NCE每秒处理 20000 个样本
此实验结论由其他同学得出,给出实验链接:https://zhuanlan.zhihu.com/p/21642643
这里再整理出其他同学关于 NCE LOSS 源码的理解,下面就是一段 NCE LOSS 的实现代码,但不得而知 Tensorflow 是否使用该NCE LOSS的实现。
def nce_loss(data, label, label_weight, embed_weight, vocab_size, num_hidden, num_label):
label_embed = mx.sym.Embedding(data = label, input_dim = vocab_size,
weight = embed_weight,
output_dim = num_hidden, name = 'label_embed')
label_embed = mx.sym.SliceChannel(data = label_embed,
num_outputs = num_label,
squeeze_axis = 1, name = 'label_slice')
label_weight = mx.sym.SliceChannel(data = label_weight,
num_outputs = num_label,
squeeze_axis = 1)
probs = []
for i in range(num_label):
vec = label_embed[i]
vec = vec * data
vec = mx.sym.sum(vec, axis = 1)
sm = mx.sym.LogisticRegressionOutput(data = vec,
label = label_weight[i])
probs.append(sm)
return mx.sym.Group(probs)
NCE的主要思想是,对于每一个样本,除了本身的label,同时采样出N个其他的label,从而我们只需要计算样本在这N+1个label上的概率,而不用计算样本在所有label上的概率。而样本在每个label上的概率最终用了Logistic的损失函数。

这里可谓是整个 Word2Vec 的关键。
至此,已经搭建好训练模型,然后便可以进行分批次的训练即可。那么下一个问题是完成训练后,我们如何判断两个词汇的相似度?

这里我们使用 cos 来表示相似度会比使用 l2 向量差值会好一些。
这是根据训练方式所决定的,因为向量的长度与分类无关,
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
参考自Udacity中文本和序列的深度模型一课:https://classroom.udacity.com/courses/ud730/