基于高光谱遥感影像的分类python
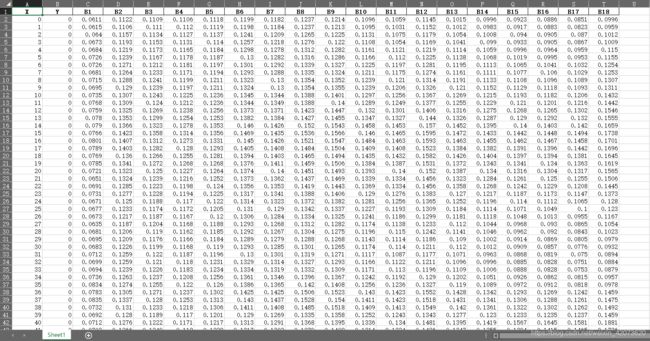
对格式为.xls,数量为16565的样本(下图有颜色区域)进行划分,并训练模型。
资源链接: https://pan.baidu.com/s/1Nc6w_VazFByjp4O1aM2-1w
提取码: ww83
对excel数据进行处理并划分训练集、测试集,以及模型训练
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
def input_excel(path):
col_num = range(3, 21, 1)
bands = pd.read_excel(path, usecols=col_num, sheet_name='All')
classes = pd.read_excel(path, usecols=[21], sheet_name='All')
return bands, classes
def split(bands, classes, train_num):
_data = np.array(bands).tolist()
_target = np.array(classes).tolist()
start = [0, 2039, 4059, 6064, 8246, 10361, 12493, 14541, 16565] # 每个类别ID为1的行号
lables = [['Luwei'], ['Jianpeng'], ['Chengliu'], ['Huanghe'], ['Sea'], ['kengtang'], ['Luotan'], ['Luodi']]
data_train = np.zeros((train_num*8, 18)) # 训练属性集
target_train = np.zeros((1, train_num*8)) # 训练标签集
data_test = np.zeros((16565-train_num*8, 18)) # 测试属性集
target_test = np.zeros((1, 16565-train_num*8)) # 测试标签集
# print(target_test)
a = b = c = d = 0
for i in range(0, 8, 1):
for j in range(0, train_num, 1):
data_train[a] = np.array(_data[start[i] + j])
a = a+1
for k in range(start[i] + j + 1, start[i+1], 1):
data_test[b] = np.array(_data[k])
b = b+1
for i in range(0, 8, 1):
for j in range(0, train_num, 1):
target_train[0][c] = lables.index(_target[start[i] + j])
c = c+1
for k in range(start[i] + j + 1, start[i+1], 1):
target_test[0][d] = lables.index(_target[k])
d = d+1
target_train = (target_train.flatten()).astype(int) # 返回一个一维数组 数据类型转换
target_test = (target_test.flatten()).astype(int)
return data_train, data_test, target_train, target_test
if __name__ == '__main__':
path1 = "E:\CHRIS_120601_18band_Ref\训练样本\8Class_2000.xls"
bands1, classes1 = input_excel(path1)
train_num = range(1300, 2100, 100)
rf = []
et = []
for train_num1 in train_num: #使用不同的训练集大小,其余的为测试集
data_train1, data_test1, target_train1, target_test1 = split(bands1, classes1, train_num1)
clf1 = RandomForestClassifier() # 这里使用了默认的参数设置
clf1.fit(data_train1, target_train1) # 进行模型的训练
with open('RF'+str(train_num1)+'.pickle', 'wb') as f: #保存模型
pickle.dump(clf1, f)
score = clf1.score(data_test1, target_test1)
rf = rf + [score]
clf2 = ExtraTreesClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0)
clf2.fit(data_train1, target_train1)
with open('ET'+str(train_num1)+'.pickle', 'wb') as f: #保存模型
pickle.dump(clf2, f)
score = clf2.score(data_test1, target_test1)
et = et + [score]
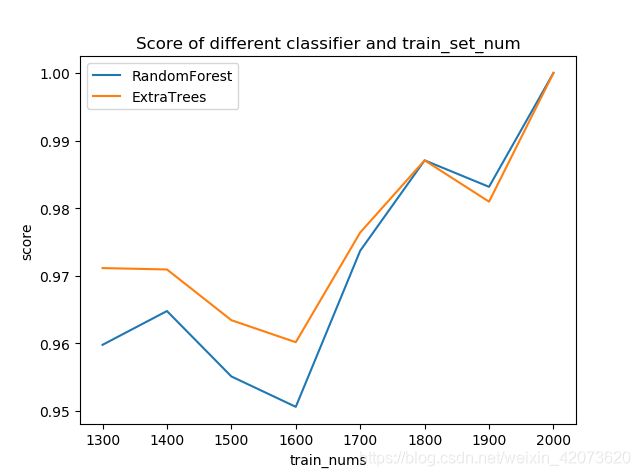
plt.plot(train_num, rf, label='RandomForest')
plt.plot(train_num, et, label='ExtraTrees')
plt.xlabel('train_nums')
plt.ylabel('score')
plt.title('Score of different classifier and train_set_num')
plt.legend()
plt.show() # 绘制RandomForestClassifier与ExtraTreesClassifier在不同训练集与测试集比例下的score
Python+gdal读取遥感影像GEOTiff、ENVI,获取网格化的数据和经纬度,并写入excel
https://blog.csdn.net/NingAnMe/article/details/98587363
import gdal
import os
import numpy as np
import pandas as pd
class Dataset:
def __init__(self, in_file):
self.in_file = in_file # Tiff或者ENVI文件
dataset = gdal.Open(self.in_file)
self.XSize = dataset.RasterXSize # 网格的X轴像素数量
self.YSize = dataset.RasterYSize # 网格的Y轴像素数量
self.GeoTransform = dataset.GetGeoTransform() # 投影转换信息
self.ProjectionInfo = dataset.GetProjection() # 投影信息
def get_data(self, band):
"""
band: 读取第几个通道的数据
"""
dataset = gdal.Open(self.in_file)
band = dataset.GetRasterBand(band)
data = band.ReadAsArray()
return data
def get_lon_lat(self):
"""
获取经纬度信息
"""
gtf = self.GeoTransform
x_range = range(0, self.XSize)
y_range = range(0, self.YSize)
x, y = np.meshgrid(x_range, y_range)
lon = gtf[0] + x * gtf[1] + y * gtf[2]
lat = gtf[3] + x * gtf[4] + y * gtf[5]
return lon, lat
dir_path = r"E:\CHRIS_120601_18band_Ref\预处理后的数据"
filename = "CHRIS_120601_18band_Ref_tiff.tif"
file_path = os.path.join(dir_path, filename)
dataset = Dataset(file_path)
longitude, latitude = dataset.get_lon_lat() # 获取经纬度信息
df = pd.DataFrame(longitude.flatten(), columns=['X'])
df.insert(1, 'Y', pd.DataFrame(latitude.flatten(), columns=['Y'])) # Pandas.DataFrame插入列
for i in range(1, 19, 1):
data = dataset.get_data(i) # 获取第1-18个通道的数据
df.insert(i+1, 'B'+str(i), pd.DataFrame(data.flatten(), columns=['B'+str(i)]))
print(df)
df.to_excel('a.xlsx',index=False)