hadoop分布式安装(CENTOS7)
001 集群机器
| 主机 | ip |
|---|---|
| master | 10.13.7.43 |
| slave01 | 10.13.7.40 |
| slave02 | 10.13.7.41 |
1.修改主机名
hostnamectl set-hostname master
其他机器按照同样的方法修改主机名
2.修改hosts文件
vi /etc/hosts
配置如下:
127.0.0.1 localhost
10.13.7.43 master
10.13.7.40 slave01
10.13.7.41 slave02
010 SSH免密登录
1.测试ssh能否连接到本机
ssh localhost
2.不能连接的话,下载openssh-server
yum -y install openssh-server
3.配置ssh免密登录
ssh-keygen -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
4.将master的公钥发送到slave01和slave02,实现ssh免密登录slave01和slave02
scp ~/.ssh/id_rsa.pub root@slave01:~/.ssh/
scp ~/.ssh/id_rsa.pub root@slave02:~/.ssh/
5.ssh 连接slave01和slave02,将master的公钥添加到authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
6.测试master是否ssh免密登录slave01和slave02
ssh slave01
011 安装JAVA环境和Hadoop
1.安装openJDK
yum -y install java-1.7.0-openjdk java-1.7.0-openjdk-devel
2.获取JDK安装路径
rpm -ql java-1.7.0-openjdk-devel | grep '/bin/javac'
安装路径:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el7_3.x86_64
3.添加JDK环境变量
vi /etc/profile
添加以下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el7_3.x86_64
觉得路径长的话,可以修改路径名。
4.生效环境变量
source /etc/profile
5.检验配置是否生效
java -version

6.安装hadoop
可以通过清华源https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/下载hadoop,这里用的是hadoop 2.8.0版本,下载完之后,解压文件
tar -zxvf hadoop-2.8.0.tar.gz -C /usr/local
cd /usr/local/
mv hadoop-2.8.0 hadoop
8.添加hadoop环境变量
vi /etc/profile
添加以下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
8.生效环境变量
source /etc/profile
9.测试配置是否生效
hadoop

100 配置hadoop集群
1.进入hadoop配置文件存放的目录
cd /usr/local/hadoop/etc/hadoop
2.修改slave文件
vi slave
添加DATANODE的主机名
slave01
slave02
3.修改core-site.xml文件
vi core-site.xml
在< configuration>< /configuration>之间添加以下内容
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://master:9000
4.修改hdfs-site.xml文件
vi hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
/usr/local/hadoop/tmp/dfs/name
5.复制mapred-site.xml.template,修改文件名为mapred-site.xml,并修改这个文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
在< configuration>< /configuration>之间添加以下内容
mapreduce.framework.name
yarn
6.修改yarn-site.xml文件
vi yarn-site.xml
在< configuration>< /configuration>之间添加以下内容
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
7.将master配置好的hadoop文件夹打包复制到各slave节点,master节点执行
cd /usr/local
tar -zcf hadoop.tar.gz ./hadoop
scp hadoop.tar.gz slave01:/usr/local
scp hadoop.tar.gz slave02:/usr/local
8.创建namenode临时文件存放路径,仅master节点执行
mkdir /usr/local/hadoop/tmp/dfs/name
8.在各slave节点解压hadoop文件
cd /usr/local
tar -zxvf hadoop.tar.gz -C /usr/local
101 启动hadoop集群
1.master主机执行启动命令
hdfs namenode -format
start-all.sh
2.运行后,在master,slave01,slave02 执行jps命令,查看运行情况
maser:

slave01:
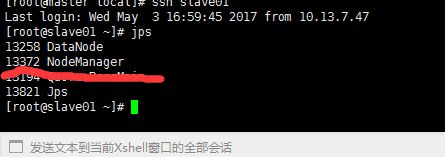
slave02:
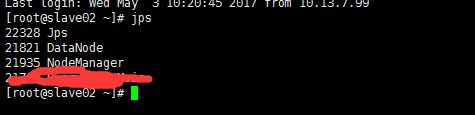
ok!!!大功告成!!!