JAVA内存模型(JMM)和JAVA虚拟机内存模型(JVM)
JAVA内存模型(JMM)
操作系统内存模型解决的问题
在现代计算机硬件体系中,CPU的数据处理速度远比从内存条读写数据的速度要快,为了更好地利用CPU的运算能力,每个CPU都配备了寄存器和CPU缓存来提高IO吞吐,降低CPU等待数据的耗时。
既然是高速缓存,其高成本就导致存储空间必然有限,也就不会将全量数据都装载,因此只会将CPU当下计算所需的数据副本拷贝到高速缓存中。虽然提高了CPU读写数据的IO吞吐,也带来的数据不一致问题。
对于数据不一致问题,不同的操作系统有不同的系统级指令的解决方案,来约束线程的数据在何时从主内存读取,何时写入主内存。
JAVA内存模型解决的问题
市面上的操作系统百花齐放,而Java作为一个跨平台的语言,势必要为用户屏蔽底层细节。因此在操作系统内存模型的基础上,对共性抽象提出了Java 内存模型。
Java内存模型

JMM规定:
1、主内存:也就是虚拟机内存(可以类比理解为物理硬件的内存条),所有共享变量均在主内存存储
2、工作内存:JMM 的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器等。每个线程均有自己的工作内存,其中存储的是线程工作所需的主内存数据的拷贝副本。
3、线程无法获取其它线程的工作内存的数据,因此线程通信的方式有两种,其一是共享内存传递数据,其二是消息通信。
Java内存模型,也即在Java虚拟机中实现的内存模型,约束了将变量存储到内存和从内存中取出变量这样的底层细节。具体分为以下三个层面
原子性
指的是一组指令在cpu执行过程中,cpu不会被中断,也即这一组指令要么不执行,要么执行且全部完成。
有序性
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序,可能会打乱代码执行顺序。
1、指令重排需要满足两个条件
- 在不改变单线程程序语义的前提下
- 存在数据依赖关系的不允许重排序
2、重排序分三种类型
- 编译期的重排序。从java源码到编译成class文件,可以重新安排语句的执行顺序。
- CPU指令级并行的重排序。处理器可以改变语句对应机器指令的执行顺序,多条指令可以并行执行。即时编译器JIT也会做指令重排
- 内存系统的重排序。线程工作内存与主内存同步延迟,这使得加载和存储操作看上去可能是在乱序执行。
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
![]()
3、禁止重排序的手段——内存屏障(memory barrier)
内存屏障是一个CPU指令,能达到两个效果:
- 确保一些特定操作执行的顺序,禁止指令重排序
- 影响数据可见性,写屏障会将线程工作内存的数据强制写入主内存,读屏障会强制从工作内存读取数据
可见性
指的是多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
1、保证可见性的手段——happens-before原则
如果 A happens-before B,那么 Java 内存模型则保证: A 操作的结果将对 B 可见,且 A 的执行顺序排在 B 之前
- 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile 变量规则:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
- 传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
JAVA虚拟机模型(JVM)
jvm规定的虚拟机内存分配模型
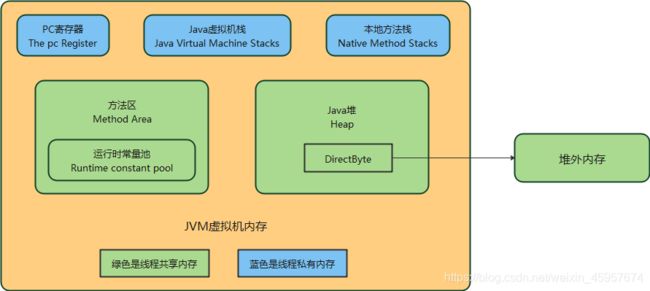
JDK8按照JVM规范的具体实现
程序计数器
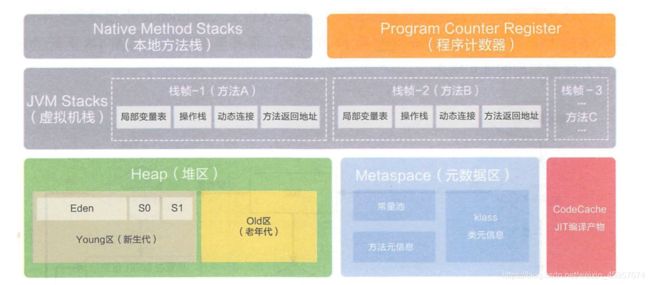
程序计数器是描述CPU运行的存储结构。CPU自带的存储介质是寄存器,CPU运行计算所需的任何数据都需要从寄存器获取。每个线程在创建后,都会产生自己的程序计数器和栈帧。
由于CPU的时间片轮转特性,一个线程承载的任务可能在一个CPU时间片内无法完成,此时操作系统会会随机选择下一个线程执行,因此需要程序计数器存放执行指令的偏移量和行号指示器等,线程执行或恢复都要依赖程序计数器。
生命周期:和线程同生共死,线程创建时诞生,线程结束时消亡
虚拟机栈
虚拟机栈是描述方法执行的存储结构,用后进先出的栈结构,按照方法执行顺序记录方法地址。每个线程的虚拟机栈的栈顶指示的就是所有活动方法列表。
生命周期:和线程同生共死,线程创建时诞生,线程结束时消亡
本地方法栈
本地方法栈和虚拟机栈实现的功能相同,只不过虚拟机栈是为虚拟机执行Java方法(也就是字节码)服务,本地方法栈则为虚拟机使用到的Native方法服务。
生命周期:和线程同生共死,线程创建时诞生,线程结束时消亡
堆内存
对象创建所需申请的空间,不要求磁盘的物理连续性,只要求逻辑连续性即可,所有线程共享的存储区域
方法区
方法区是JVM虚拟机规范,也称堆外内存。方法区是所有线程共享的存储区域,存放数据如下:类信息、常量、静态变量、即时编译器编译后的代码,其中常量存储在运行时常量池中。
当.java编译成.class文件后,除了会生成类名、字段、方法等信息外,还有就是常量信息(包含这个java类定义的各种常量字符串和符合引用),这个常量信息就会被放到运行时常量池中。
永久代是JDK7的HotSpot对于方法区的具体实现,元空间(Metaspace)是JDK8对于方法区的具体实现。元空间与永久代之间区别在于
1、元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制
2、符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap
之所以把数据存储从永久代转移到堆上,主要是为了尽量将变化和不变的分开,数据在堆上能有更好的垃圾回收效率。
直接内存
直接内存相当于跳过JVM直接向操作系统申请的内存空间,这不是JVM管控的内存空间,不会被垃圾回收。
优点:这片空间适用场景在于频繁的IO操作,因为申请Direct Memory就避免了在java堆和native堆的数据拷贝,减少了IO次数,提升了性能。
缺点:空间垃圾回收不归JVM管控
总结
线程共享角度来看内存的分配,堆内存、元空间、直接内存都是线程共享的,程序计数器、虚拟机栈、本地方法栈都是线程私有的。
JMM和JVM的关联
- JMM屏蔽了不同操作系统差异,是跨平台可用的内存模型,用来描述线程的数据在何时从主内存读取,何时写入主内存,解决线程间数据共享和传递的问题。
- JVM用来描述Java程序运行过程中,对象创建所占用的不同内存区域,在线程级别定义了数据的共享性和私有性。例如:堆和方法区是共享数据的,PC寄存器、虚拟机栈、本地方法栈是线程独享的数据区域。
- 二者在本质上并没有关联,毕竟是为解决不同问题而诞生。但以“先有鸡还是先有蛋”的角度来考虑这个问题,二者的关联可以简单理解,JMM描述的【工作内存】,就是JVM描述的【PC寄存器、虚拟机栈、本地方法栈】;JMM描述的【主内存】,就是JVM描述的【堆和方法区】
参考文章
Java内存模型原理
Java内存模型(JMM)总结