Spark SQL
楔子
SparkSQL ,基于Spark 2.版本
Spark 相关内容
以下内容是从相关书籍中,阅读Spark部分笔记
企业大数据处理Spark、Druid、Flume、Kafka应用实践
2 Spark详解
Spark是开源的分布式大规模数据处理通用引擎,具有高吞吐、低延迟、通用易扩展、高容错等特点。Spark内部提供了丰富的开发库,集成了数据分析引擎Spark SQL、图计算框架GraphX、机器学习库MLlib、流计算引擎Spark Streaming。Spark在函数式编程语言Scala中实现,提供了丰富的开发API,支持Scala、Java、Python、R等多种语言。同时Saprk还提供了多种运行模式,即可以采用独立部署的方式运行,也可以依托Hadoop YARN等资源管理器任务调度。
2.1.1 Spark概述
1 核心概念介绍
- Client :客户端进程,负责提交作业。
- Driver:一个Spark作业有一个Spark Context,一个SparkContext对应一个Driver进程,作业的main函数运行在Driver中,Driver主要负责Spark作业的解析,以及通过DAGScheduler划分Stage,将Stage转化为TaskSet提交给TaskScheduler任务调度器,进而调度Task到Ececutor上执行。
- Executor:负责执行Driver分发的Task任务。集群中一个节点可以启动多个Executor,每个Executor可以执行多个Task任务
- Catche:Spark提供了对RDD不同的缓存策略,分别可以缓存到内存、磁盘、外部分布式内存存储系统等Rachyon等。
- Application:提交的一个任务就是Application,一个Application只有一个SparkContext。
- JOB:RDD执行一次Action操作就会生成一个Job
- Task:Spark运行的基本单位,负责处理RDD计算逻辑
- Stage:DAGScheduler将JOB任务分为多个Stage,Stage的划分界限为Shuffle的产生,Shuffle标志着一个Stage的介绍和下一个Stage的开始。
- RDD:弹性分布式数据集,可以理解为一种只读的分布式多分区的数组,Spark计算操作都是基于RDD进行的,
- DAG:有向无环图。
2 RDD介绍
RDD可以认为是一种分布式多分区只读的数组,Spark计算操作都是基于RDD进行的,RDD具有几个特性:只读、多分区、可以将HDFS块文件转为RDD,也可以由一个或多个RDD转化成新的RDD,失效自动构建。基于这些特性,RDD在分布式环境下能够高效地并行处理。
(1) 计算类型
在Spark中RDD提供了Transformation和Action两种计算类型。Transformation操作非常丰富,采用延迟执行的方式,在逻辑上定义了RDD的依赖关系和计算逻辑,但并不会真正触发执行动作,只有等到Action操作才会真正执行操作,Action操作常用于最终结果输出。
常用Transformation操作如下
| 函数名 | 描述 |
|---|---|
| map(func) | 接收一个处理函数并行处理源RDD中的每个元素,返回与源RDD元素一一对象的新RDD |
| filter(func) | 并行处理源RDD中的每个元素,接收一个处理函数,并根据定义的规则对RDD中的每个元素进行过滤处理,返回结果为true的元素重新组成新的RDD |
| flatMap(func) | flatMap是map和flatten的组合操作,与map函数相似,不过map函数返回新RDD包含元素可能是嵌套类型,flatMAP接收一个处理嵌套会将嵌套类型的元素展开映射成多个元素组成新的RDD |
| mapPartitions(func) | 与map函数应用于RDD中每个元素不同,mapPartitions应用于RDD中的每个分区。mapPartitions函数接收的参数为func函数,func接收参数为每个分区的迭代器,返回值为每个分区处理之后组成新的迭代器,func会作用于分区中的每个元素,有一个典型的场景,比如待处理分区中的数据需要写入到数据库,如果使用map函数,每个元素都是创建一个数据库连接对象,非常耗时并且容易引起问题发生,如果使用mapPartitions函数只会在分区中创建一个数据库连接对象,性能提高明显 |
| mapPartitionsWithIndex(func) | 作用于mapPartitions函数相同,只是接受的参数func函数需要传入两个参数,分区的索引作为第一个参数传入,按照分区的索引对分区元素进行处理 |
| union(otherDataset) | 将两个RDD合并,返回结果为RDD元素(不去重) |
| intersection(otherDataset) | 将两个RDD进行交集运算,返回为无重复的RDD |
| groupByKey(numTasks) | 在KV类型的RDD中按key分组,将相同的元素聚集到同一个分区,次函数不能接受函数作为参数,值接受一个可选参数任务书,所以不能再RDD分区本地进行聚合计算,如需按Key对value聚合计算,只能对groupByKey返回的新RDD继续使用其他函数运算 |
| reduceByKey(func,[numTasks]) | 对KV类型的RDD按key分组,接受两个参数,第一个参数为处理函数,第二个参数可选参数设置reduce的任务数。reduceByKey函数能够在RDD |
| sortByKey([assending],[numTasks]) | 对KV类型的RDD内部元素安装KEY进行排序 |
| join(otherDataset,[numTasks]) | 对KV类型的RDD进行关联,只能是两个RDD之间关联,超过两个RDD关联需要使用多次join函数,join函数只会关联出具有相同key的元素,相当于SQL语句中的inner join |
常用的Action操作
| 函数名 | 描述 |
|---|---|
| reduce(func) | 处理RDD中两两之间元素的聚集操作 |
| collect() | 返回RDD中所有数据元素 |
| count() | 返回RDD中元素的个数 |
| first() | 返回第一个RDD中的元素 |
| take(n) | 返回RDD中的钱n个元素 |
| saveAsTextFile(path) | 将RDD写入文本文件,保存至本地文件系统或者HDFS中 |
| countByKey() | 返回KV类型的RDD每个Key包含的元素个数 |
| foreach(func) | 遍历RDD中所有元素,接收参数为func函数 |
| saveAsSequenceFile(path) | 将KV类型的RDD写入SequenceFile文件,保存至本地文件系统或者HDFS中 |
(2) 缓存
在Spark 中RDD 可以缓存到内存或者磁盘上,提供缓存的主要目的是减少同一数据集被多次使用的网络传输次数,提高Spark的计算性能。Spark提供对RDD的多种缓存级别 ,可以满足不同场景的RDD使用需求,RDD缓存具有容错性,如果分区丢失,可以通过系统自动重新计算。
代码中使用cache或者persist(StorageLevel.DISK_ONLY())来缓存
使用unpersist()取消缓存
3 运行模式
Spark运行模式主要是以下几种:
- 1 local模式:本地采用多线程的方式执行,主要用于开发测试
- 2 On Yarn 模式:Spark On Yarn 两种模式分别是 yarn-client和yarn-cluster模式。yarn-clinet模式中,Driver运行在客户端,其作业运行日志在客户端查看,适合返回小数据量结果交互式常见使用。yarn-cluster模式中,Driver运行在集群中某个节点,节点选择有YARN调度,作业日志通过yarn管理名称查看,也可以在yarn的web ui中查看。适合大数据量非交互式场景使用。
2.2 Spark SQL
Spark SQL是spark的重要组成模块,也是大数据生成环境中最广泛的技术之一,主要用于结构化数据处理。Spark SQL的API设计简洁高效,使用简单方便,可用与hive表直接进行交互,并支持JDBC/ODBC连接,Spark 先后引入了DataFrame和DataSet两种数据结构,一遍更加高效地处理各种数据。
2.2.1 SparkSession
Spark2.0引入SparkSession,用于Spark SQL开发过程中初始化上下文,用户提供统一的入口。用户可以通过SparkSession API直接创建DataFrame的DataSet。Spark2.0之前版本初始化上下文需要创建SparkContext、SQLContext、HiveContext、SparkConf。从2.0版本之后 不需要之前复杂的操作,所有运行时参数设置、获取都可以通过conf方法实现。conf方法返回RuntimeConfig对象,RuntimeConfig对象包括Spark、Hadoop等运行时的配置信息。
/**
* 2.0版本创建sparkSession
*/
public static void buildSparkSession() {
SparkSession sparkSession = SparkSession.builder().appName("MyLocal").master("local")
.config("key", "value").getOrCreate();
}
支持hive的SparkSession
/**
* 2.0版本创建支持hive的sparkSession
*/
public static void buildSparkSessionEnableHive() {
SparkSession sparkSession = SparkSession.builder().appName("MyLocal").master("local").config("key", "value").enableHiveSupport().getOrCreate();
}
如果环境中已经创建过SparkSession ,可以使用如下方法获取已经存在的SparkSession
SparkSession.builder().getOrCreate()
/**
* 2.0版本创建支持hive的sparkSession
*/
public static SparkSession buildSparkSessionEnableHive() {
SparkSession sparkSession = SparkSession.builder().appName("MyLocal").master("local").config("key", "value").enableHiveSupport().getOrCreate();
return sparkSession;
}
public static void main(String[] args) {
SparkSession sparkSession = buildSparkSessionEnableHive();
RuntimeConfig runtimeConfig = sparkSession.conf();
Map<String, String> confAll = runtimeConfig.getAll();
System.out.println(confAll);
/**
*
* spark.driver.host -> 169.254.86.190
* spark.driver.port -> 59254
* hive.metastore.warehouse.dir ->
* file:/E:/lun/work/hd/spark-warehouse/
* spark.app.name -> MyLocal
* key -> value
* spark.executor.id -> driver
* spark.master -> local
* spark.app.id -> local-1542467177838
*/
}
从代码中看出SparkSession没有显示地创建SparkContext、SQLcontext、SparkConf对象,因为SparkSession内部进行了封装,对用户完全透明。SparkSession提供了对hive大部分功能的内置支持,包括hiveSQL查询、使用自定义的UDF函数、读取表元素等。
2.2.2 DatFrame
Spark1.3版本。用户使用SparkSQL时需要直接操作RDD API,学习成本相对较高,代码结构相对复杂,为了提高任务执行性能。需要调优。Spark1.3版本引入DataFrame,DataFrame是一种带有Schema元信息的分布式数据集,类似于传统数据库的二维表,定义有字段名称和类型,用户可以像操作数据库表一样使用DataFrame。DataFrame的开发API简洁高效、代码结构清晰,并且Spark针对DataFrame的操作进行了丰富的优化。DataFrame支持Java、Python、Scala等多种开发语言。
1 创建DataFrame
SparkSession可以通过RDD转换、读取Hive表、读取不同格式(TXT,JSON,Parquet)文件数据、通过JDBC连接数据库表等方式创建DataFrame
1)通过读取指定路径文件创建DataFrame,SparkSession支持读取多种文件格式
/**
* 读取 json
*/
public static void readJson() throws IOException {
String path = Resources.getResourceAsFile("json/person.json").getAbsolutePath();
SparkSession sparkSession = buildSparkSession();
//此处我使用本地文件,hdfs是hdfs://ip/data.json
Dataset<Row> json = sparkSession.read().json(path);
System.out.println(json.collectAsList());
}
/**
* 2.0版本创建sparkSession
*/
public static SparkSession buildSparkSession() {
SparkSession sparkSession = SparkSession.builder().appName("MyLocal").master("local").config("key", "value").getOrCreate();
return sparkSession;
}
读取csv文件
/**
* CSV文件
*
* @throws IOException
*/
public static void readCsv() throws IOException {
String path = Resources.getResourceAsFile("csv/per.csv").getAbsolutePath();
SparkSession sparkSession = buildSparkSession();
// 此处我使用本地文件,hdfs是hdfs://ip/data.json
// TODO 这两种加载方法效果一样
// Dataset load = sparkSession.read().json(path);
Dataset<Row> load = sparkSession.read().format("csv").load(path);
System.out.println(load.collectAsList());
// [[grq,25,��], [lfeng,25,��]]
}
- 通过RDD转化成DataFrame,需要引入spark.implicits包进行隐士转换
3)通过JDBC连接数据库,将数据转换成DataFrame
/**
* JDBC连接数据库,将数据库表转换为DataFrame
*/
public static void loadFormMySQL() {
SparkSession sparkSession = buildSparkSession();
Dataset<Row> load = sparkSession.read().format("jdbc")// JDBC
.option("url", "jdbc:mysql://localhost:3306/life").option("dbtable", "family")// 表名
.option("user", "root")// 用户
.option("password", "root").load();
System.out.println(load.collectAsList());
}
/**
* JDBC连接数据库,将数据库表转换为DataFrame
*/
public static void loadFormMySQL2() {
Properties connprop = new Properties();
connprop.put("user", "root");
connprop.put("password", "root");
SparkSession sparkSession = buildSparkSession();
Dataset<Row> load = sparkSession.read().jdbc("jdbc:mysql://localhost:3306/life", // url
"family",// tableName
connprop);
System.out.println(load.collectAsList());
}
2 DataFrame常用操作
DataFrame常用操作有3中:toDF、as、printSchema、show、createTempView、createOrReplaceTempView、createGlobalTempView
-
toDF函数
作为DataSet的一种特殊形式,函数的作用是将RDD转换为DataFrame
-
as函数
返回一个制定别名的新dataset
-
printSchema函数
打印DataFrame的Schema信息(打印字段信息)
-
show函数
默认以表格展现DataFrame数据集的前20行数据,字符串类型长度超过20个字符就会被截断。
-
createTempView函数和createOrReplaceTempView函数
创建临时视图,临时视图会随着创建该视图会话的终止自动删除,不会绑定到任何数据库
-
createGlobalTempView函数
创建全局临时视图,该视图的声明周期与Spark应用程序周期关联,随着Spark应用程序的终止而自动删除。它与系统保留的数据库“_global_temp”绑定,该视图的引入方式为“_global_temp.view”
/**
* JDBC连接数据库,将数据库表转换为DataFrame
*/
public static void loadFormMySQL2() {
Properties connprop = new Properties();
connprop.put("user", "root");
connprop.put("password", "root");
SparkSession sparkSession = buildSparkSession();
Dataset<Row> load = sparkSession.read().jdbc("jdbc:mysql://localhost:3306/life", // url
"family",// tableName
connprop);
// 创建视图
load.createOrReplaceTempView("fam");
Dataset<Row> sql = sparkSession.sql("select name,id from fam where id >145");
sql.show();
}
DataFrame持久化
Spark提供了DataFrame保存数据的多种方式,DataFrame 可以以不同文件格式输出到制定路劲,可以保存到hive表,还可以通过JDBC连接输出到数据库表中。DataFrame有4中保存模式。
- SaveMode.Append:如果数据或目标表存在,数据会追加到原数据或目标表数据的后面
- SaveMode.ErrorIfExists:如果输出数据或者目标表存在抛出异常
- SaveMode.Ignore:如果数据或目标表存在,则不做任何操作,源数据不收任何影响
- SaveMode.Overwrite:如果数据或目标表存在删除原数据,新数据覆盖原数据
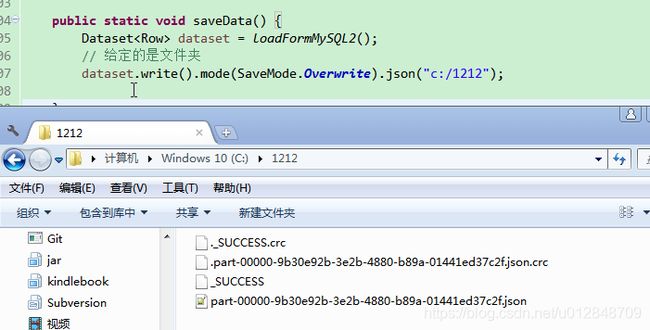
/**
* 数据持久化
*/
public static void saveData() {
// 前面获取的数据
Dataset<Row> dataset = loadFormMySQL2();
// 给定的是文件夹
dataset.write().mode(SaveMode.Overwrite).json("c:/1212");
// 保存到数据库
Properties connprop = new Properties();
connprop.put("user", "root");
connprop.put("password", "root");
dataset.write().mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/life", "family_bak", connprop);
}
2.2.3 DataSet
DataSet是一个特定域的强类型的不可变数据集,每个DataSet都有一个非类型化视图DataFrame(DataFrame是DataSet[Row]的一种表示形式)。DataFrame可以通过调用as函数转化为DataSet,而DataSet可以通过调用toDF函数转为DataFrame,两者之间可以灵活转换操作DataSet可以像操作RDD一样使用各种转换算子并行操作。