dataframe类型数据的遍历_Go数据分析处理开箱体验丨篇二
上一篇主要探讨了gota/series模块,而[]series则组成了接下来我们需要探讨的gota/dataframe。
先回忆下使用pandas.DataFrame的美好生活:
at,iat,loc,iloc傻傻分不清楚。
apply的性能瓶颈。
agg自定义聚合溜得飞起,最靓的仔就是你。
诸如此类。
好了,现在回到现实,看看这副轮子如何:
官方文档:
https://pkg.go.dev/github.com/kniren/gota/dataframe?tab=doc
dataframe是什么?
dataframe可以视为二维表的表数据集,该数据集的列表示特征(series.Series),行表示度量值。兼容NaN。关系型数据库里的表知道吧,对,就暂时把他想象成那玩意儿。
这就是一个dataframe:
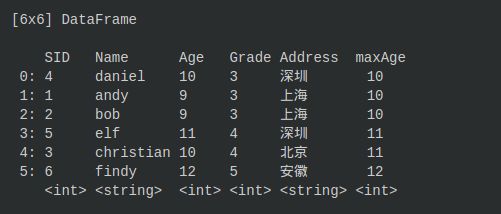
那使用dataframe能做什么?
1. 数据清洗。
2. 数据过滤,归并,派生,聚合,转换。
3. 矩阵运算。
概念就扯这么多,开箱试用才是正道!
首先在项目中获取包:
go get github.com/go-gota/gota
然后项目中引入dataframe:
import "github.com/go-gota/gota/dataframe"
基本数据类型dataframe.Dataframe
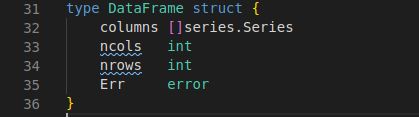
又见私有属性哦,所以真正暴露出来的只有Err。columns就是一列列series.Series。ncols和nrows表示列数和行数。这种数据类型将贯穿整个数据处理过程。
数据加载数据源的多样性要求,dataframe提供了丰富的数据加载方式,

我们大致可以将他们分为以下几种场景:
1.从接口载入数据:ReadJSON, LoadStructs, LoadMaps
2.从文件载入数据:ReadCSV
3. 根据上下文载入数据:LoadStructs, LoadMaps, LoadRecords
4.列方式载入数据: New
5.从数据库中载入数据:LoadStructs
下面展示两个例子,一个从CSV中读取数据,一个从数据库中加载数据。
从CSV读取课程分数数据
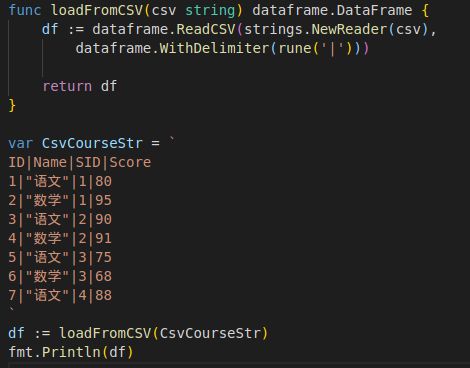
从数据库读取学生信息数据
由于没有提供直接将数据库中数据转变为dataframe的方法,我们需要借道LoadStructs。

这里需要注意的是入参类型LoadOption,他使用了自定义数据类型loadOptions,这里看下源码:

也就是说我们在初始化dataframe的时候,可以通过设置LoadOption来控制元数据信息,例如默认类型,数据第一行是否为列名,什么样值为NaN,分隔符等等。
ReadCSV从CSV中获取数据时,默认分隔符为逗号:
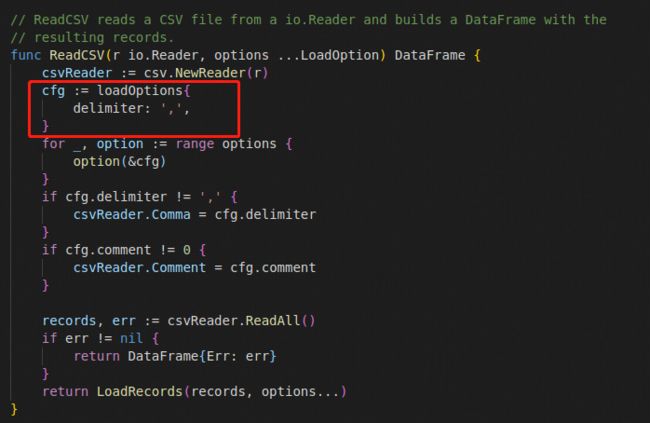
而我们在例子中将其重置为了“|”。
元数据
1. 获取维度数据
gota/dataframe可以直接通过下面两种方式获取维度信息
func (df DataFrame) Dims() (int, int)
(https://pkg.go.dev/github.com/go-gota/[email protected]/dataframe?tab=doc#DataFrame.Dims)
func (df DataFrame) Ncol() int
(https://pkg.go.dev/github.com/go-gota/[email protected]/dataframe?tab=doc#DataFrame.Ncol)
func (df DataFrame) Nrow() int
(https://pkg.go.dev/github.com/go-gota/[email protected]/dataframe?tab=doc#DataFrame.Nrow)

2. 获取列名
func (df DataFrame) Names() []string
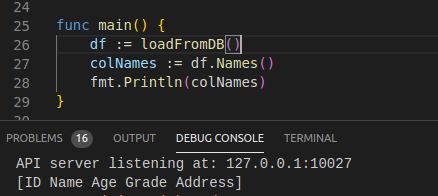
由于dataframe中并没有直接记录各列的列名,因此源码需要遍历各列,以获取Series.Name。
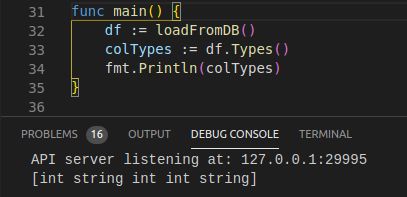
3. 获取列类型
func (df DataFrame) Types() []series.Type
由于dataframe中并没有直接记录各列的类型,因此源码需要遍历各列,以获取Series. Type()。
1. 修改列名①
func (df DataFrame) Rename(newname, oldname string) DataFrame
注意:1)方法返回新的dataframe,并不改变原有dataframe列名。
2)第一个参数为新列名。如果新旧列名写反会返回一个空dataframe。

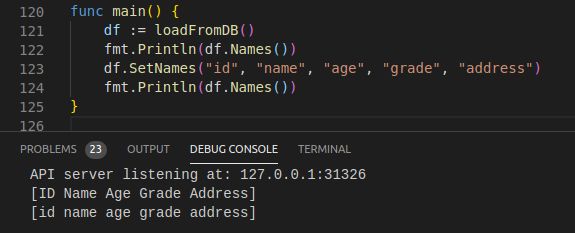
2. 修改列名②
func (df DataFrame) SetNames(colnames ...string) error
注意会原地修改列名。
如果传入新列名与原有列名数量不一致时会返回error:setting names: wrong dimensions
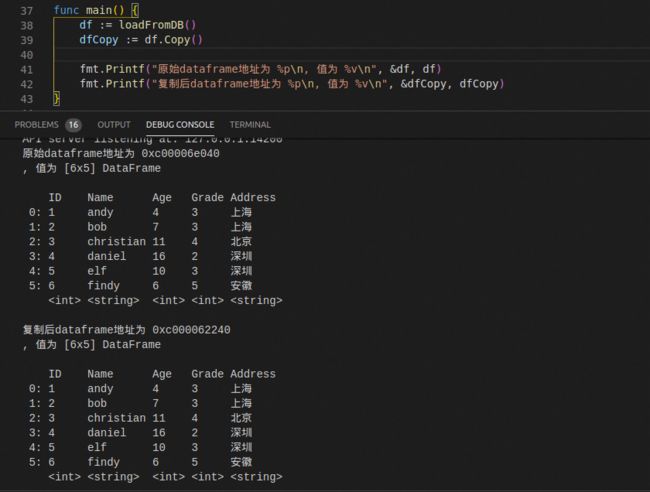
1. 深复制
func (df DataFrame) Copy() DataFrame
2. 转二维字符串数组
func (df DataFrame) Records() [][]string
由于全部转成字符串类型,在进一步处理数据的时候需要转回原始类型。

3. 转map数组
func (df DataFrame) Maps() []map[string]interface{}
同样由于数据转为interface{}类型,在进一步处理数据的时候需要类型断言。

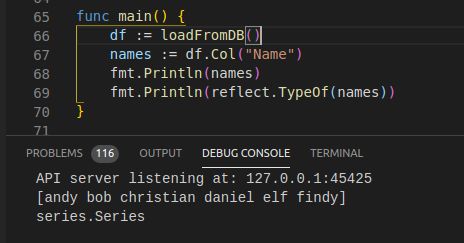
4. 获取单列数据
func (df DataFrame) Col(colname string) series.Series
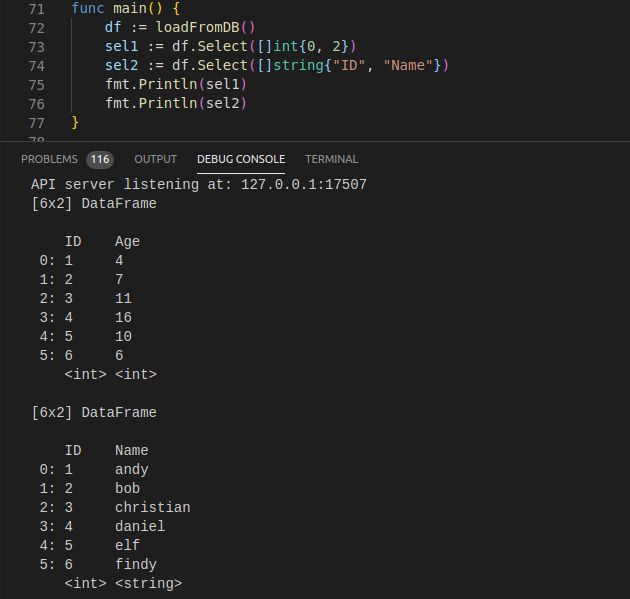
5. 获取所选列数据
func (df DataFrame) Select(indexes SelectIndexes) DataFrame
当入参为整形数组时,是按照位置获取所列出的列数据。
入参可以是单个整形值,表示列号,也可以是整形数组,表示一组列号。同时也可以是一个或多个列名。
6. 获取所选行数据
func (df DataFrame) Subset(indexes series.Indexes) DataFrame
获取所列rownum的行数据。
嗯,问题是如果我想取一个范围内行的数据怎么办?好像没有提供呀,难道要完全枚举……

7. 获取单元格数据
func (df DataFrame) Elem(r, c int) series.Element
输入row index和colunm index。

8. 过滤查询数据
func (df DataFrame) Filter(filters ...F) DataFrame
单个Filter内每一个dataframe.F入参作为OR条件表达。
多个Filter形成chain的时候,每一个dataframe.F作为AND条件表达。
下面是两个栗子:
OR:
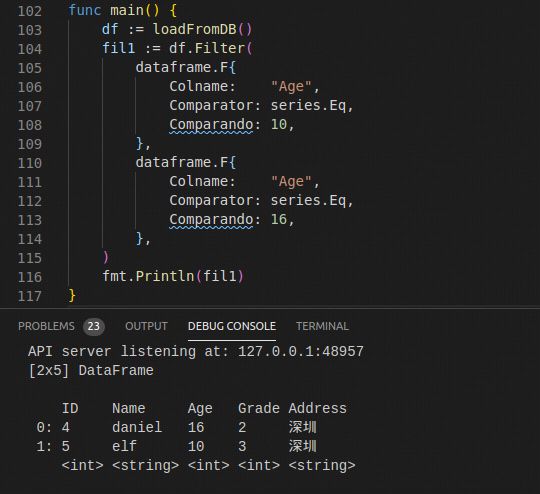
AND:

9. 数据排序
func (df DataFrame) Arrange(order ...Order) DataFrame
示例:
根据age asc,address desc重排列生成新的dataframe。

这里要提下Order类型,要针对哪个列排序,是正序还是反序。

10. 关联查询
作用与SQL中join基本相同。
缺点:不能细分左键和右键,不够灵活。
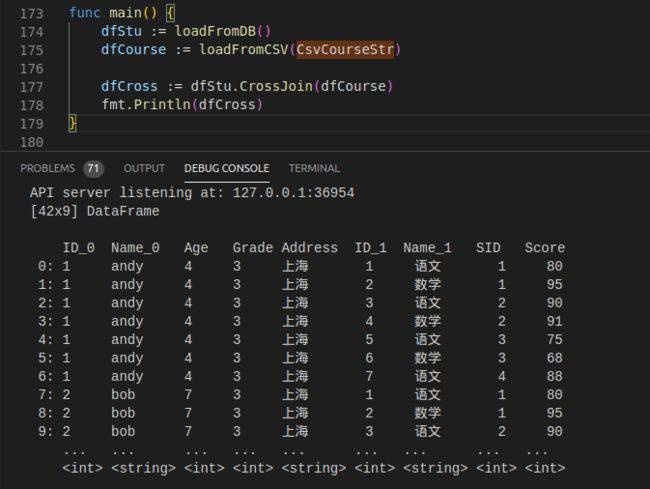
1)CrossJoin
func (df DataFrame) CrossJoin(b DataFrame) DataFrame
笛卡尔积
2)InnerJoin
func (df DataFrame) InnerJoin(b DataFrame, keys ...string) DataFrame
keys可以理解为join on里的条件(on df.key1 = b.key1 and df.key2 = b.key2…)
注意keys一定是两个dataframe都包含的列名。故本例中将student dataframe中ID列换成SID。

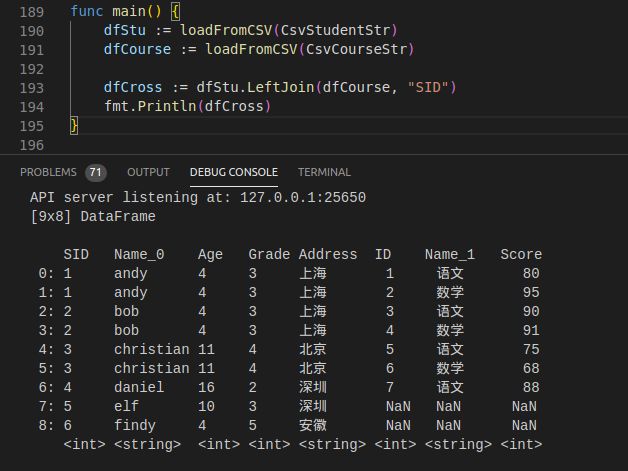
3)LeftJoin
func (df DataFrame) LeftJoin(b DataFrame, keys ...string) DataFrame
使用方式和InnerJoin相同,当左边dataframe中的join key在右边不存在时,右边列值使用NaN替代。当右边dataframe的join key在左边不存在时舍弃。
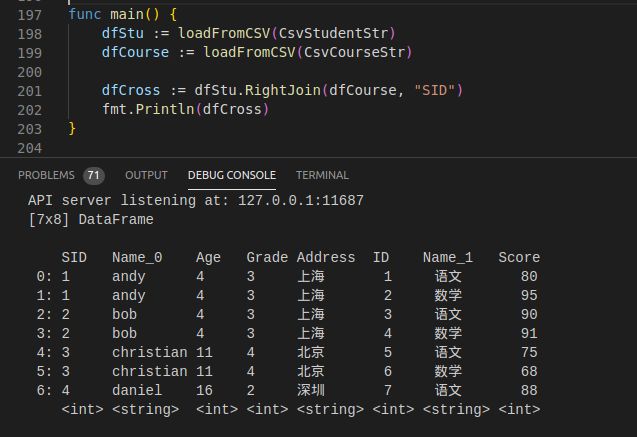
4)RightJoin
func (df DataFrame) RightJoin(b DataFrame, keys ...string) DataFrame
使用方式同LeftJoin,匹配方式相反。
5)OuterJoin
func (df DataFrame) OuterJoin(b DataFrame, keys ...string) DataFrame
结合了LeftJoin和RightJoin特点。

修改数据
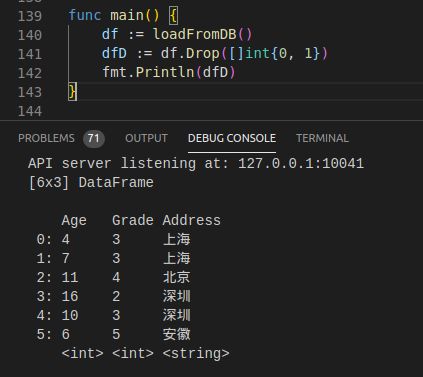
1. 删除列数据
func (df DataFrame) Drop(indexes SelectIndexes) DataFrame
1)按照列索引删除列
2) 按照列名删除列

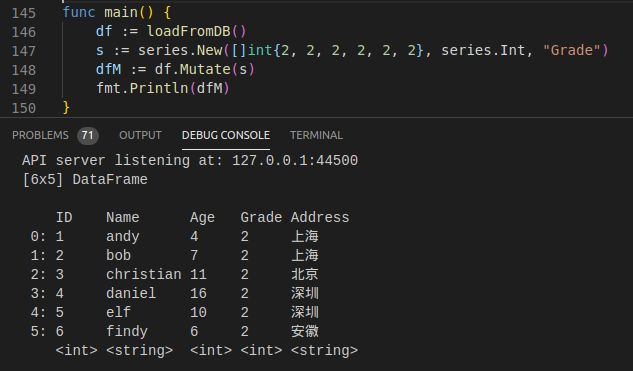
2. 替换|新增列
func (df DataFrame) Mutate(s series.Series) DataFrame
列名存在则替换,反之则新增。
1) 替换Age列
2)新增level列
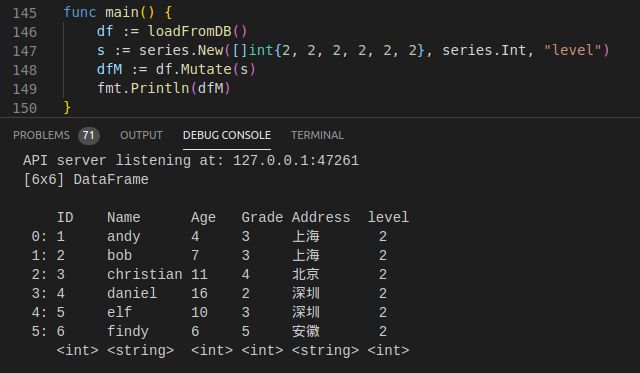
3. 行数据替换
func (df DataFrame) Set(indexes series.Indexes, newvalues DataFrame) DataFrame
整行数据替换

4. 合并dataframe
func (df DataFrame) CBind(dfb DataFrame) DataFrame

使用自定义函数
1. 在同一列间各行上使用自定义函数
func (df DataFrame) Capply(f func(series.Series) series.Series) DataFrame

2. 在同一行各列间上使用自定义函数
func (df DataFrame) Rapply(f func(series.Series) series.Series) DataFrame

好了,没有了,dataframe里面就提供了这么多的API。
也许有同学要问了,好像没有聚合函数啊,你看看pandas里

简洁,帅气,强大!

然而回头看看,是的,gota里确实没有,但是作者也提到了这点, 并提供了解决方案:
Split-Apply-Combine methods for DataFrames #13(https://github.com/go-gota/gota/issues/13)
Added Split() methods for both pkgs with tests included #24(https://github.com/go-gota/gota/pull/24)
Add support for GroupBy and Summarize #33(https://github.com/go-gota/gota/issues/33)
作者就说了,有Capply和Rapply这俩零件了,你们自己去造轮子吧,哥没时间!
好吧,拿人手短,那我们就自己造一个看看。
我们有一个学生表
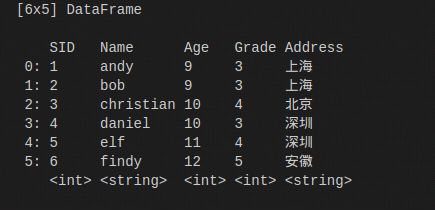
目标是生成一个新列,存放各个年纪中最年长的岁数。
首先创建数据类型,其中df为原始数据,tmp为中间处理数据。

然后需要使用Capply对原始数据根据grade列进行排序和分组,并生成最终分组列。
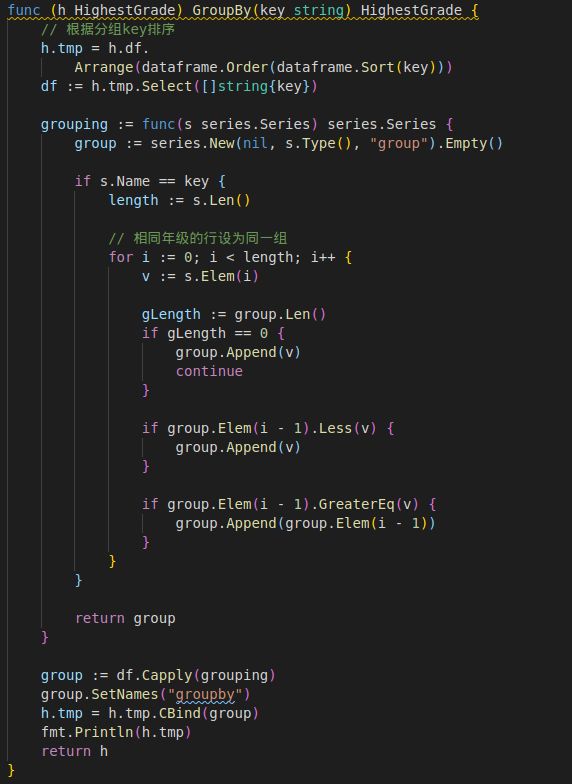
其次根据分组列对Age进行计算maxAge,并将之附着于原dataframe上。

最终采用链式调用的方式使用。

执行结果:
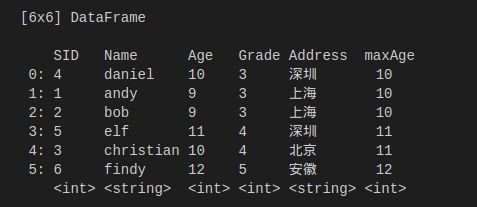
总结,对于这个需求如果不按照作者的设计意图来做可能更加方便,但无论如何都比不上pandas的溺爱。
所以gota/dataframe在数据聚合处理这块还需要提供更多的功能模块,也需要更多的志愿者加入来不断完善。
