八大排序算法(直接插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序,计数排序)
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。分内部排序和外部排序,若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。内部排序的过程是一个逐步扩大记录的有序序列长度的过程。
目录
- 一.插入排序
-
- 1.直接插入排序
- 2.希尔排序
- 二.选择排序
-
- 1.选择排序
- 2.堆排序
- 三.交换排序
-
- 1.冒泡排序
- 2.快速排序
- 四.归并排序
- 五.计数排序
- 六.算法复杂度
一.插入排序
1.直接插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后;
- 重复步骤2~5。
1.动图演示:
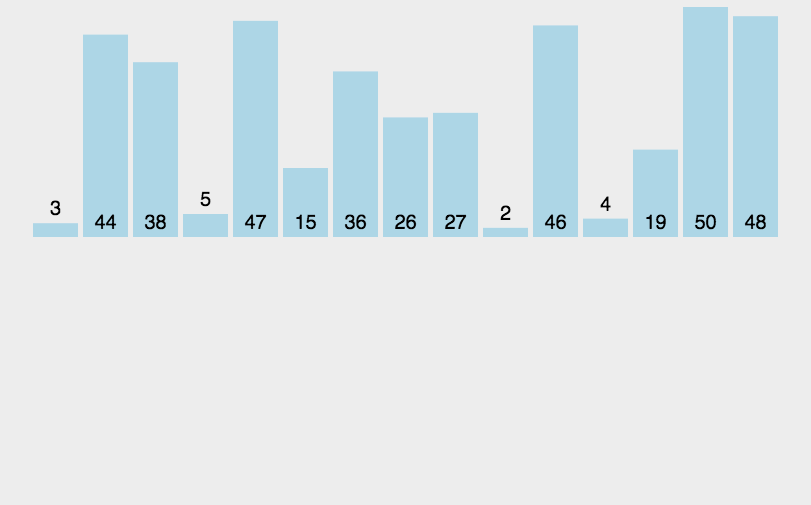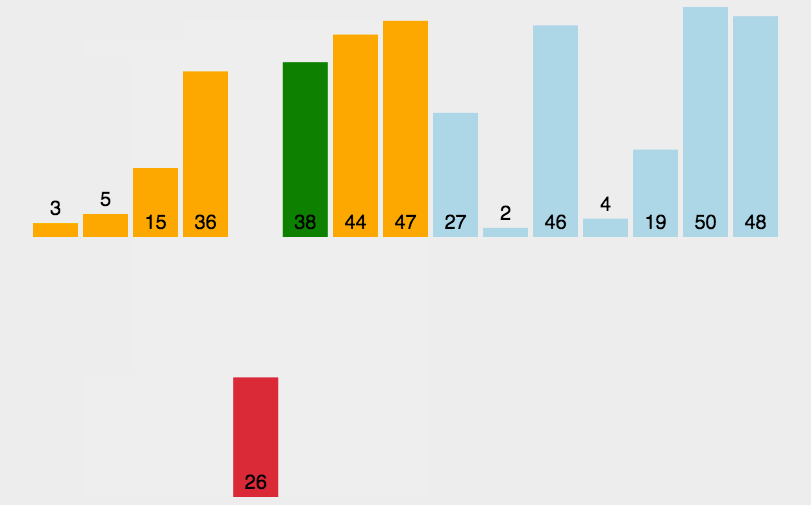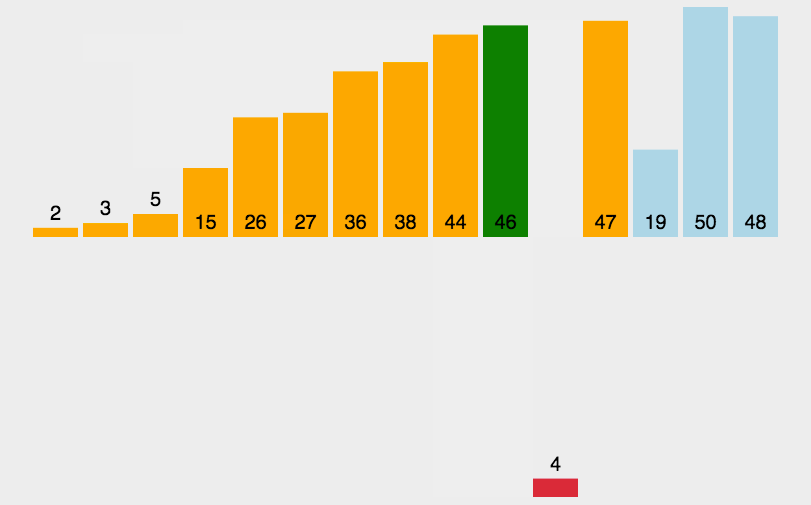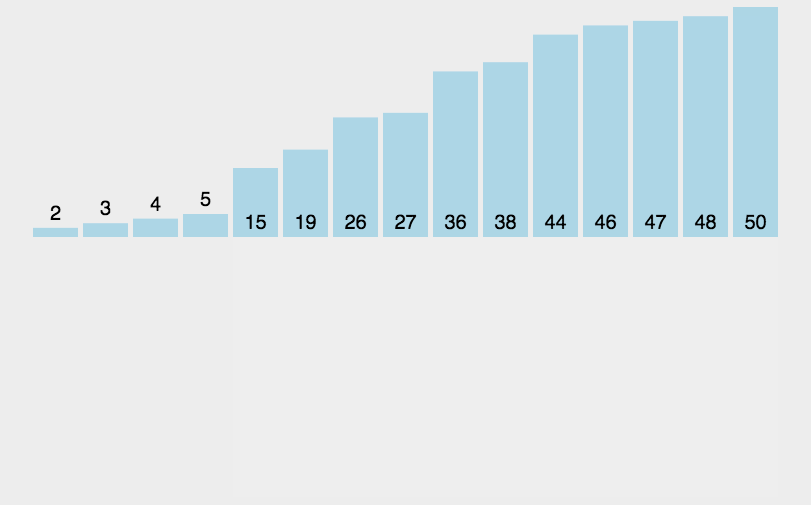
2.源代码:
void InitSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++) {
int end = i;
int number = a[end + 1];
while (end >= 0) {
if (number< a[end]) {
a[end + 1] = a[end];
end--;
}
else {
break;
}
}
a[end + 1] = number;
}
}
2.希尔排序
1959年Shell发明,第一个突破O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
1.动图演示:
2.源代码:
void ShellSort(int* a, int n)
{
int end = 0;
int gap = n;
int number = 0;
while(gap>1){
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++) {
end = i;
number = a[end + gap];
while(end>=0){
if (number < a[end]) {
a[end + gap] = a[end];
end -=gap;
}
else
break;
}
a[end + gap] = number;
}
}
}
二.选择排序
1.选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 初始状态:无序区为R[1…n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
1.动图演示

2.源代码:
void SelectSort(int* a, int n)
{
int k = n;
int m = 0;
while (k >0) {
int min = m;
int number = a[m];
for (int i = m+1; i < n; i++) {
if (number> a[i]) {
number = a[i];
min = i;
}
}
int temp = a[m];
a[m] = a[min];
a[min] = temp;
m++;
k--;
}
}
2.堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序详解链接:堆排序详解入口
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
1.动图演示:
2.源代码:
void AdjustDown(int* a, int n,int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && a[child + 1] > a[child]){
child++;
}
if (a[parent] < a[child]) {
int temp = a[parent];
a[parent] = a[child];
a[child] = temp;
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
void HeapSort(int* a, int n)
{
for (int i = (n - 2) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
int end = n - 1;
while(end>0){
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
AdjustDown(a, end, 0);
end--;
}
}
三.交换排序
1.冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个; 重复步骤1~3,直到排序完成。
1.动图演示:

2.源代码:
void BubbleSort(int* a, int n)
{
int k = 0;
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - 1 - i; j++) {
if (a[j + 1] < a[j]) {
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
k = 1;
}
}
if (k == 0)
break;
}
}
2.快速排序
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
1.动图演示:

2.源代码:
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int GetMidIndex(int *a,int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] > a[mid]) {
if (a[mid] > a[end])
return mid;
else
return end;
}
else {
if (a[begin] > a[end])
return begin;
else
return end;
}
}
int PartSort(int*a, int begin,int end)
{
int Mid = GetMidIndex(a,begin,end);
Swap(&a[Mid], &a[end]);
int key = end;
while (begin < end)
{
while (begin < end && a[begin] <= a[key])
begin++;
while (begin < end && a[end] >= a[key])
end--;
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[key]);
return begin;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int div = PartSort(a, begin, end);
QuickSort(a, 0, div-1);
QuickSort(a, div + 1, end);
}
四.归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
1.动图演示:

2.源代码:
void _MergeSort(int*a, int left, int right,int *tmp)
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid+1, right, tmp);
int left_1 = left;
int right_1 = mid;
int left_2 = mid + 1;
int k = left;
while (left_1 <= right_1 && left_2 <= right) {
if (a[left_1] < a[left_2]) {
tmp[k++] = a[left_1++];
}
else {
tmp[k++] = a[left_2++];
}
}
while (left_1 <= right_1) {
tmp[k++] = a[left_1++];
}
while (left_2 <= right) {
tmp[k++] = a[left_2++];
}
for (int i = left; i <= right; i++) {
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
五.计数排序
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
1.动图演示:
2.源代码:
void count_sort(int *arr, int *sorted_arr, int n)
{
int *count_arr = (int *)malloc(sizeof(int) * 100);
int i;
for(i = 0; i<100; i++)
count_arr[i] = 0;
for(i = 0;i<n;i++)
count_arr[arr[i]]++;
for(i = 1; i<100; i++)
count_arr[i] += count_arr[i-1];
for(i = n; i>0; i--)
{
sorted_arr[count_arr[arr[i-1]]-1] = arr[i-1];
count_arr[arr[i-1]]--;
}
free(count_arr);
}
六.算法复杂度
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
各大算法时间复杂度:
