4、python分析酷我音乐
4、python分析酷我音乐
1、环境依赖:
需要安装requests和jsonpath这两个模块
2、步骤:
(1)首先,进入酷我音乐官网

(2)鼠标右键点击检查,选择notework 这一栏中的Media 是筛选音频文件、视频文件的,点击播放音乐时,就会出现一个以 .mp3 结尾的链接(下面我们随机播放一首《白月光与朱砂痣》)

(3)双击第二个红色框框:

https://gmsycdn.kuwo.cn/24f98891bc5dfcea33d18fc0bfba483e/6039162b/resource/n2/73/81/1062648582.mp3
这个URL地址就是音频文件地址!
(4)下面我们要根据音频文件地址找到音乐地址来源,我们从上面URL可以发现:其实后面的数字非常像音乐的ID,我们可以用开发者工具,搜索一下

(5)然后我们点击这个可以看到一下信息:

由上图可以知道这个数据包返回的内容包括音乐的URL真正来源地址。我们侧视图中也可以很明显的看到如果想要获取这个音乐的url就必须要有参数rid
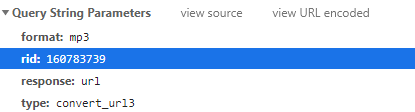 我们再通过这个rid搜索一下:
我们再通过这个rid搜索一下:
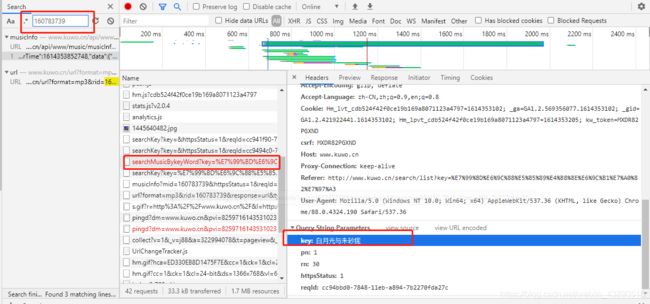
这里显示的是通过keyword去查找rid
(6)下面主要是代码的实现:
import requests
import jsonpath
# cookies的时效性啊????session 保持cookies 维持回话
# 进入首页 得到 cookies csrf保存在cookies里
def get_csrf():
url = 'https://kuwo.cn/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': '_ga=GA1.2.773350284.1614335668; _gid=GA1.2.764530357.1614335668; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1614335668; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1614343336; kw_token=9LVH3GVO6NG',
'Host': 'kuwo.cn',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
}
s.get(url, headers=headers)
csrf = s.cookies.get_dict()['kw_token']
return csrf
# 音乐的索引 特征值
def get_rid(csrf):
url = f'https://kuwo.cn/api/www/search/searchMusicBykeyWord?key={keyword}&pn=1&rn=30&httpsStatus=1'
headers = {
# 'Accept': 'application/json, text/plain, */*',
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control': 'no-cache',
# 'Connection': 'keep-alive',
# 'Cookie': '_ga=GA1.2.773350284.1614335668; _gid=GA1.2.764530357.1614335668; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1614335668; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1614341909; kw_token=3PB45UN366F',
'csrf': csrf,
# 'Host': 'kuwo.cn',
# 'Pragma': 'no-cache',
'Referer': f'https://kuwo.cn/search/list?key={keyword}',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
}
# 防止跨站点攻击,
r = s.get(url, headers=headers).json()
rid = jsonpath.jsonpath(r, '$..rid')[0]
return rid
# 得到 音乐的下载地址
def get_music_url(rid):
# 下载一首歌
url = f'https://kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&t=1614342354424&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': '_ga=GA1.2.773350284.1614335668; _gid=GA1.2.764530357.1614335668; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1614335668; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1614342187; kw_token=PEL47GQVIED',
'Host': 'kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'https://kuwo.cn/search/list?key={keyword}',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
}
r = s.get(url, headers=headers).json()
music_url = r.get("url")
return music_url
# 下载音乐
def get_music(music_url):
#requests.utils.unquote(keyword)将
with open(f'{requests.utils.unquote(keyword)}.mp3', 'wb') as f:
f.write(requests.get(music_url).content)
if __name__ == '__main__':
keyword = input('请输入你需要下载的音乐名字:')
keyword = requests.utils.quote(keyword)
# 保持cookies 维持会话.
s = requests.session()
csrf = get_csrf()
rid = get_rid(csrf)
music_url = get_music_url(rid)
get_music(music_url)
说明:代码中的headers信息在这里获取

(7)运行测试:

下载成功!
![]()
3、总结
整个爬取酷我VIP音乐的流程大概有以下几点:
- 获取音乐的rid值
- 将得到的音乐rid值接口数据url当中,获取音乐真实的url地址
- 请求音乐url地址 保存音乐文件至本地
- 最后嘿嘿你喜欢的话就点个赞啦