离线项目(三)数据仓库的设计
离线项目(三)数据仓库的设计
文章目录
-
- 离线项目(三)数据仓库的设计
-
- 一:数据仓库的分层
-
- ODS 层
- DWD层
- DWS层
- ADS层
- 二:关于数据仓库和数据集市
-
- 1.**数据仓库**:
- 2.**数据集市**:
- 3.数据仓库和数据集市的区别:
- 三:数仓模型(星型模型和雪花模型)
-
- 1.星型模型
- 2.雪花模型
- 四:项目相关
-
- 1.分层
-
- ODS层:
- DWD层:
- DWS层:
-
- 1.dws_visit,访客表
- 2.按照时间维度统计
- 3.按照终端维度进行统计
- 4.按照页面维度进行统计分析
- 5.按照来源维度进行统计和分析
- ADS层:
一:数据仓库的分层
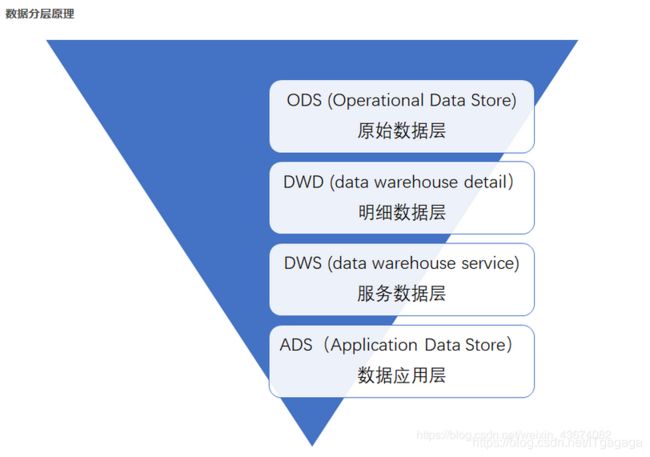
ODS 层
原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。或者只是对数据进行一些很简单的处理。
DWD层
明细数据层
结构和粒度与ods层保持一致,对ods层数据进行清洗(去除空值,脏数据,超过极限范围的数据),可以将数据进行拆分,减低维度,减轻事实表和维度表的关联。本项目中预处理之后的数据,是按照空格进行切分,一行数据一行数据的进行处理,除掉了不完整的数据以及静态页面相关的数据,文件名是dwd_weblog
DWS层
服务数据层
以dwd为基础,进行轻度汇总。一般聚集到以用户当日,设备当日,商家当日,商品当日等等的粒度。
在这层通常会有以某一个维度为线索,组成跨主题的宽表,比如 一个用户的当日的签到数、收藏数、评论数、抽奖数、订阅数、点赞数、浏览商品数、添加购物车数、下单数、支付数、退款数、点击广告数组成的多列表。dws层算是集市层,属于维度建模的范畴 ,这里一般按照主题进行划分 。
ADS层
数据应用层, 也有公司或书把这层成为app层、dal层、dm层,叫法繁多。面向实际的数据需求,以DWD或者DWS层的数据为基础,组成的各种统计报表。统计结果最终同步到RDS以供BI或应用系统查询使用。这一层的数据就可以直接导入到mysql中,方便业务应用
看到https://www.jianshu.com/p/2b0509851df1写的数据仓库的一个架构,感觉蛮好的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YDZhUT2t-1573727897092)(D:\CSDN图片\数据仓库.png)]
二:关于数据仓库和数据集市
进行数据处理的最终目的是生成报表,用于决策。
1.数据仓库:
是一个集成的面向主题的数据集合,设计的目的是支持DSS(决策支持系 统)的功能,在数据仓库里,每个数据单元都和特定的时间相关。数据仓库包括原子级别的 数据和轻度汇总的数据。数据仓库是面向主题的、集成的、不可更新的(稳定性)、随时间不 断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。
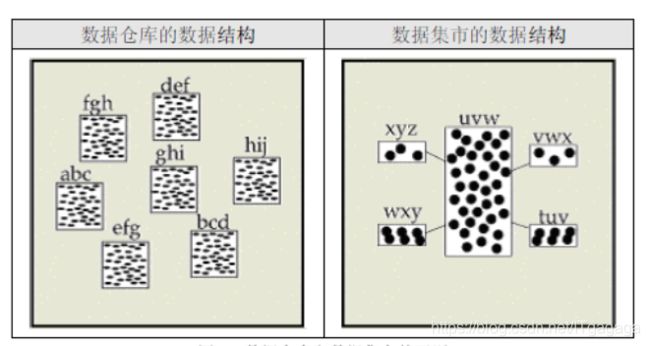
2.数据集市:
是一个小型的部门或工作组级别的数据仓库。有两种类型的数据集市——独 立型和从属型。独立型数据集市直接从操作型环境获取数据。从属型数据集市从企业级数据 仓库获取数据。从长远的角度看,从属型数据集市在体系结构上比独立型数据集市更稳定 。从属型的数据仓库,数据来源与数据仓库的DWS层(服务数据层)
3.数据仓库和数据集市的区别:
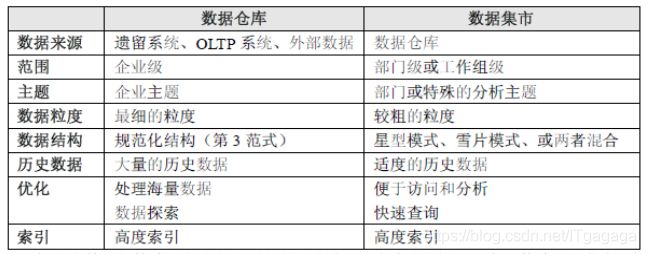
数据仓库中数据结构采用的规范化模式(关系数据库设计理论),数 据集市的数据结构采用的星型模式(多维数据库设计理论);数据仓库中数据的粒度比数据 集市的细 ;
关于数据仓库和数据库,推荐文章http://www.360doc.com/showweb/0/0/872875827.aspx
三:数仓模型(星型模型和雪花模型)
1.星型模型
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余 。例如湖北省有武汉市和黄石市,存储两条数据(湖北省武汉市)(湖北省黄石市),湖北省的信息被存储的两次,产生了冗余
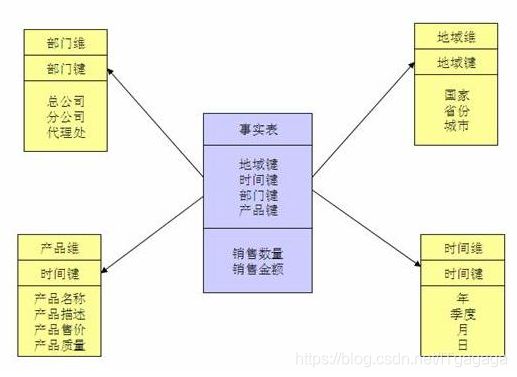
2.雪花模型
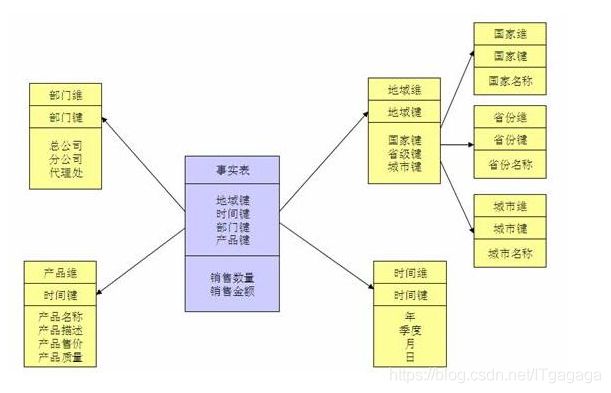
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 ,将地域维表又分解为国家,省份,城市等维表。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
四:项目相关
1.分层
ODS层:
dos_log,存储简单清洗之后的数据
| is_avalible | boolean | 本条数据是否有效 |
|---|---|---|
| remote_addr | String | IP |
| time_local | String | 访问时间 |
| request | String | 请求的URL |
| status | int | 状态码 |
| body_bytes_sent | int | 发送的字节数 |
| http_referer | String | 外部链接 |
| http_user_agent | String | 用户浏览器信息 |
在Hive中创建数据库LOG_ODS,并且建立基础数据表ods_log,可以创建一个分区表,因为日志是每天都会更新的,我们可以创建一个分区表,时间作为分区字段。
create database if not exists LOG_ODS;
use LOG_ODS;
create table if not exists ods_log (
is_avalible String,
remote_addr String,
time_local String,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
ods_log_session,存储进行会话流划分之后的点击流数据,每条数据都有sessionid,处于此次会话的第几个page,以及所有的基础数据,是一个宽表。
| sessionId | String | 会话id |
|---|---|---|
| remote_addr | String | ip |
| time_local | String | 访问时间 |
| request | String | 请求url |
| status | int | 状态码 |
| body_bytes_sent | int | 发送字节数 |
| step | int | 处于会话的第几个页面 |
| staytime | int | 停留时间 |
| http_referer | String | 外部链接 |
| http_user_agent | String | 用户浏览器信息 |
create table if not exists ods_log_session (
sessionId String,
remote_addr String,
time_local String,
request string,
status string,
body_bytes_sent string,
step string,
staytime string,
http_referer string,
http_user_agent string)
partitioned by(datestr string)
row format delimited
fields terminated by '\001';
导入原始数据到ods_log表中,导入点击流数据到ods_log_session表中
load data inpath '/dianshang/data/pre_out' overwrite into table ods_log partition(datestr='2019-11-14');
load data inpath '/dianshang/data/pre_click' overwrite into table
ods_log_session partition(datestr='2019.11.14');
DWD层:
dwd_log对url和时间进行了拆分
| sessionId | String | 会话id |
|---|---|---|
| remote_addr | String | ip |
| time_local | String | 完整访问时间 |
| daystr | String | 访问日期 |
| timestr | String | 访问时间 |
| year | String | 访问年 |
| month | String | 访问月 |
| day | String | 访问日 |
| hour | String | 访问时 |
| request | String | 请求url |
| status | int | 状态码 |
| body_bytes_sent | int | 发送字节数 |
| step | int | 处于会话的第几个页面 |
| staytime | int | 停留时间 |
| http_referer | String | 外部链接 |
| host | String | 外部链接域名 |
| path | String | 外部链接路径 |
| query | String | 外部链接的参数 |
| query_id | String | 外部链接 的参数值 |
| http_user_agent | String | 用户浏览器信息 |
在Hive中创建DWD层的明细数据表dwd_log_insert
create table if not exists dwd_log(
sessionId string comment "会话id",
remote_addr string comment "来源 IP",
time_local string comment "访问完整时间",
daystr string comment "访问日期",
timestr string comment "访问时间",
year string comment "访问年",
month string comment "访问月",
day string comment "访问日",
hour string comment "访问时",
request string comment "请求的 url",
request_host string comment "请求的域名",
status string comment "响应码",
body_bytes_sent string comment "传输字节数",
http_referer string comment "来源 url",
host string comment "来源的 host",
path string comment "来源的路径",
query string comment "来源参数 query",
query_id string comment "来源参数 query 的值",
http_user_agent string comment "客户终端标识")
partitioned by(datestr string)
row format delimited
fields terminated by '\001';
解析 URL 中的信息:
1、抽取 refer_url 到中间:dwd_tmp_referurl
2、将来访 url 分离出 host path query query id
| sessionId | String | 会话id |
|---|---|---|
| remote_addr | String | ip |
| time_local | String | 访问时间 |
| request | String | 请求url |
| status | int | 状态码 |
| body_bytes_sent | int | 发送字节数 |
| step | int | 处于会话的第几个页面 |
| staytime | int | 停留时间 |
| http_referer | String | 外部链接 |
| http_user_agent | String | 用户浏览器信息 |
| host | String | 域名 |
| path | String | 路径 |
| query | String | 参数 |
| query_id | String | 参数值 |
create table dwd_tmp_referurl as
SELECT a.*, b.*
FROM ods_log_session a
LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH', 'QUERY',
'QUERY:id') b
as host, path, query, query_id;
检查一下:
select * from dwd_tmp_referurl a where a.host is not null limit 3;
19a806cd-5377-4aea-bb9b-6283de767fd7
1.202.186.37
2013-09-18 15:39:19
/wp-content/themes/silesia/images/bullets/5.gif
200
62
5
0
“http://blog.fens.me/nodejs-async-windjs/”
“Mozilla/5.0(Macintosh;IntelMacOSX10_8_4)AppleWebKit/537.36(KHTML,likeGecko)Chrome/29.0.1547.65Safari/537.36”
blog.fens.me
/nodejs-async-windjs/
NULL
NULL
解析时间字符串字段:
1、抽取转换 time_local 字段到中间表明细表:dwd_log
2013-09-18 12:26:31
注意:这里的subString()函数默认的下标是1,第一个下标是1,当然0也可以
create table dwd_tmp_timeAndurl as
select b.*,substring(time_local,0,10) as daystr,
substring(time_local,11,9) as tmstr,
substring(time_local,0,4) as year,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,12,2) as hour
From dwd_tmp_referurl b;
检查一下:
select * from dwd_tmp_timeAndurl limit 5;
19a806cd-5377-4aea-bb9b-6283de767fd7
1.202.186.37
2013-09-18 15:39:19
/wp-content/themes/silesia/images/bullets/5.gif
200
62
5
0
“http://blog.fens.me/nodejs-async-windjs/” “Mozilla/5.0(Macintosh;IntelMacOSX10_8_4)AppleWebKit/537.36(KHTML,likeGecko)Chrome/29.0.1547.65Safari/537.36”
2019.11.14
blog.fens.me
/nodejs-async-windjs/
NULL
NULL
2013-09-18
15:39:19
2013
09
18
15
DWS层:
按照多个维度和主题划分的多个宽表,对数据进行了轻度汇总
1.dws_visit,访客表
| sessioned | String | 会话id |
|---|---|---|
| starttime | String | 开始时间 |
| startpage | String | 开始页面 |
| outtime | String | 结束时间 |
| outpage | String | 结束页面 |
| pagecount | String | 访问的页面数 |
| addr | String | ip |
| http_user_agent | String | 用户浏览器信息 |
在hive中建表dws_visit
create table if not exists dws_visit(
sessioned string,
starttime string,
startpage string,
outtime string,
outpage string,
pagecunt string,
addr string)
partitioned by(datestr string)
row format delimited
fields terminated by '\001';
检查一下:
select * from dws_visit limit 6;
00fbf89c-2ea2-409b-b413-fd547e823196
2013-09-18 09:46:57
/tag/ng-view/
2013-09-18 09:47:01
/wp-content/uploads/2013/05/favicon.ico
6
118.166.91.239
2019.11.14
导入数据:
load data inpath '/dianshang/data/visit' overwrite into table dws_visit partition(datestr="2019.11.14");
2.按照时间维度统计
select year, month, day, hour, count(*) from dwd_tmp_timeAndurl group by year, month,day, hour;
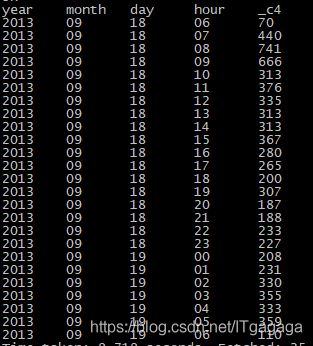
按照时间小时统计的PV,建立表dws_PV_hour
create table dws_PV_hour(year string, month string, day string, hour string, pvs bigint) partitioned by(datestr string);
insert into table dws_PV_hour partition(datestr='2019.11.14')
select a.year as year, a.month as month, a.day as day, a.hour as hour, count(1) as pvs
from dwd_tmp_timeAndurl a
where a.datestr='2019.11.14'
group by a.year, a.month, a.day, a.hour;
检查一下:
select * from dws_PV_hour limit 10;
按照天统计PV,建立表dws_PV_day
create table if not exists dws_PV_day(
year string,
month string,
day string,
pvs bigint);
Insert into table dws_PV_day
select year, month, day,sum(pvs) as pvs
from dws_PV_hour
group by year, month, day having day='18';
select * from dws_PV_day limit 5;
按照月统计PV,建立表dws_PV_year
create table if not exists dws_PV_month(
year string,
month string,
pvs bigint);
insert into table dws_PV_month
select year,month,sum(pvs) as pvs
from dws_PV_day
group by year,month having month="09";
select * from dws_PV_month limit 5;
3.按照终端维度进行统计
create table dws_user_agent as select distinct(http_user_agent) from dwd_tmp_timeAndurl where
http_user_agent like '%Mozilla%';
select * from dws_user_agent limit 10;

4.按照页面维度进行统计分析
每个访问深度有多少个页面
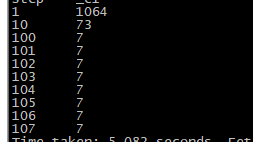
select step,count(1)
from dwd_tmp_timeAndurl
group by step limit 10;
创建表dws_page
create table if not exists dws_page(
step string,count bigint)
clustered by(step)
sorted by(step) into 10 buckets;
insert into table dws_page select step,count(1)
from dwd_tmp_timeAndurl group by step;
select * from dws_page limit 20;
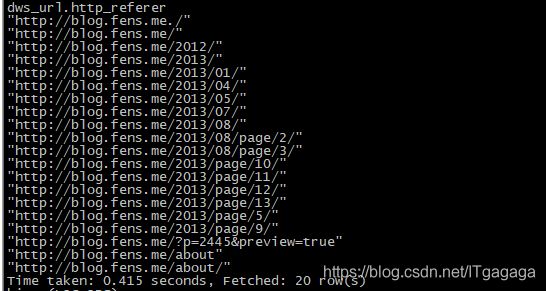
5.按照来源维度进行统计和分析
create table dws_url as select distinct(http_referer) from dwd_tmp_timeAndurl where
http_referer like '%blog.fens.me%';
select * from dws_url limit 20;
ADS层:
PV
DV
UV
VV
人均流量
独立访客
visit分析