CentOS7上安装Hadoop2.9.2集群
1.首先要有软件
Centos7(自己找,我懒!!!)
hadoop2.9.2 这这这!!!
安装位置推荐: /opt/hadoop
安装方法: 安装shell6操作虚拟机,打开到/opt/hadoop文件下,使用shell6的rz命令进行下载,把本地的安装包导入虚拟机中,注意如果不去克隆操作那么每个虚拟机都需要导入

JDK 这这这!!!
1.不建议用自带的java环境,容易找不到安装路径
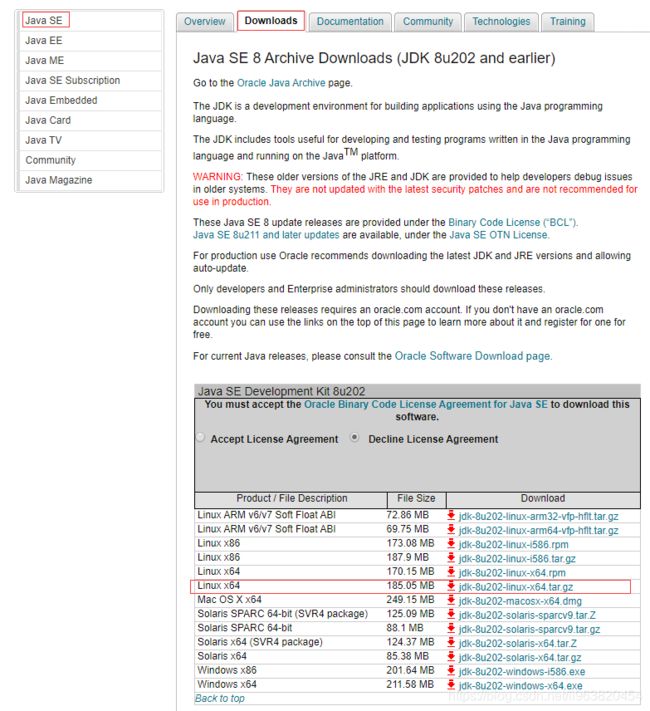
2.大版本保证是:jdk-8u 安装环境是:linux-x64.tar.gz(自选) 至于202 203 还是204 问题不大
2.安装三个虚拟机
安装方式:
1.命名随意,但注意名称太难记就是作死…
2.命名:依次 hservice1,hservice2,hservice3. (即H服务器1,H服务器2,H服务器3)
其中 H1为主节点,其他为从节点
3.主节点:主要配置,配置完主节点,为了方便通过克隆得到2,3从节点 再去修改他的ip hostname 和一些配置
3.配置关系
1.通过 ip addr 查看ip地址
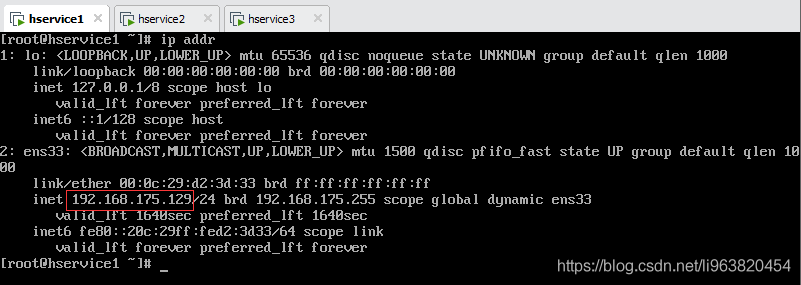
2.通过 hostname 查看当前主机名
3.通过 hostname + 空格 + 新主机名 更改主机名称

4.把三个虚拟机的主机名改为与虚拟机名称相同,名称很重要,配置中需要用到不可马虎
5.修改/etc/hosts文件 vi /etc/hosts
注: 点击 i 进行修改,修改之后 ESC 然后冒号 : wq 保存 ( :q 是不保存)
若不克隆三个都要改…
改完检查三个虚拟机是否可以ping通


7.配置使hservice1主节点可以通过ssh免密登录 hservice2 hservice3
1.在主节点下输入
ssh-keygen生成默认格式的密匙key,此过程会在/root/.ssh/文件件夹下生成id_rsa(私钥)和id_rsa.pub(公钥)。
2.四次回车
3.ssh-copy-id hservice1即可免密连接hservice1 自己 (原理自己查没空写)
4.ssh-copy-id hservice2即可通过h1免密连接hservice2
5.ssh hservice1连接回hservice1(不连接回是操作h2了)
6.ssh-copy-id hservice3即可通过h1免密连接hservice3
7.ssh分别测试是否连接成功
4.安装hadoop以及修改配置文件
- 把下载的hadoop-2.9.2.tar.gz包上传到 /opt/hadoop ,hadoop文件夹需要通过
mkdir hadoop创建,然后通过 shell6的rz命令上传(其他任意方法均可) - 解压压缩包
tar -xvf hadoop-2.9.2.tar.gz - 在根目录(/root)下创建hadoop的工作目录
mkdir /root/hadoop mkdir /root/hadoop/tmp mkdir /root/hadoop/var mkdir /root/hadoop/dfs mkdir /root/hadoop/dfs/name mkdir /root/hadoop/dfs/data - 修改配置文件(位置:
/opt/hadoop/etc/hadoop)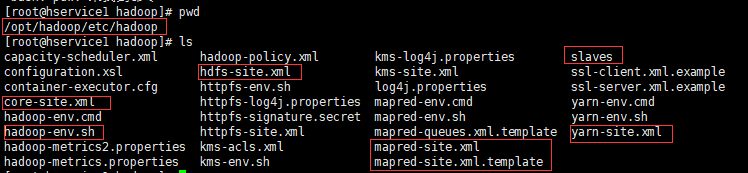
- core-site.xml
如此:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hservice:9000</value>
</property>
这般:

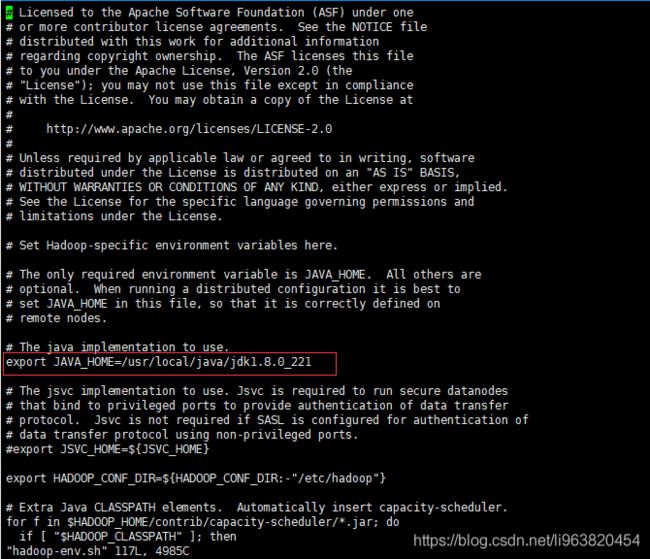
- hadoop-env.sh
如此:
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
//(自己的JDK安装路径)获取方法上面有
这般:
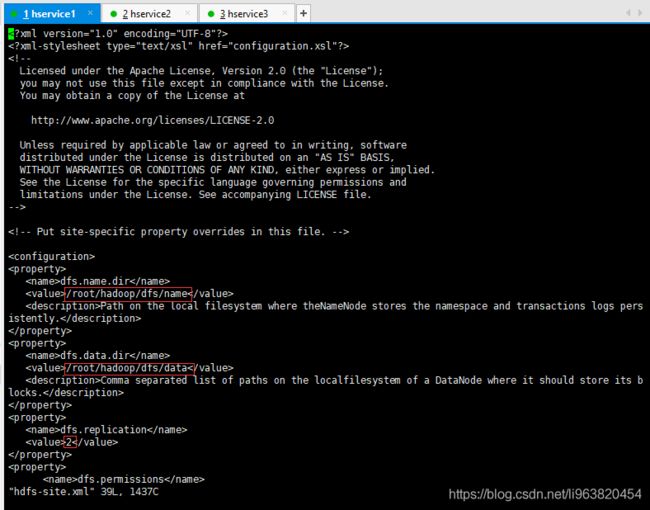
- hdfs-site.xml
如此:
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
这般:
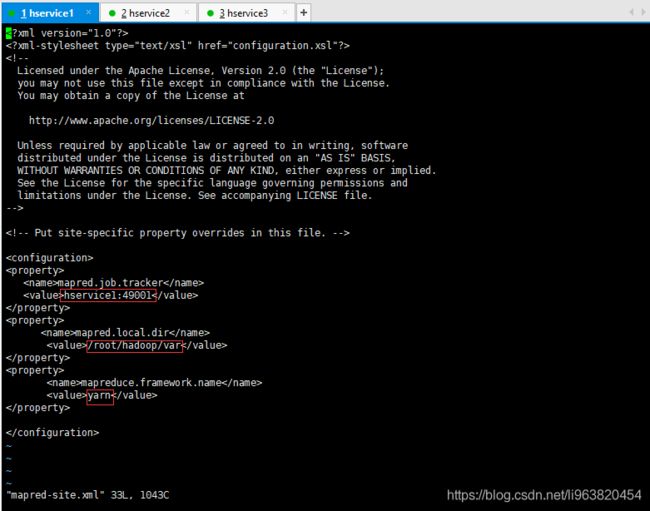
- mapred-site.xml
目录下应该存在名字mapred-site.xml.template的文件,把这个文件进行复制,然后重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
需要在本文件夹下运行,不然需要增加物理路径复制
如此:
<property>
<name>mapred.job.tracker</name>
<value>hservice1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
这般:
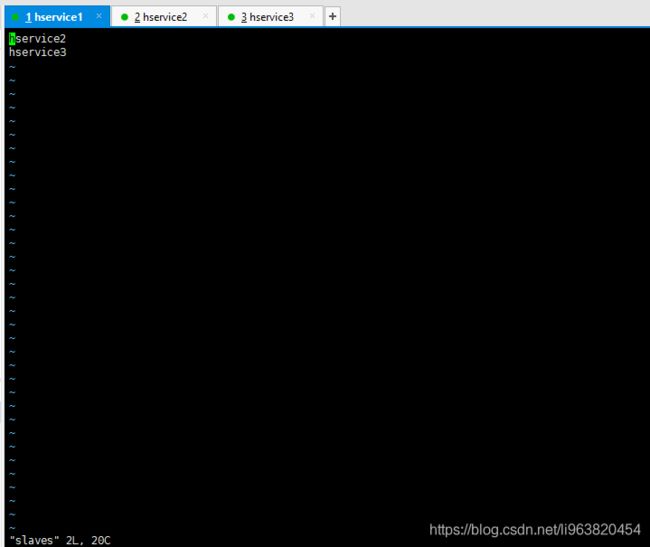
- slaves
删除localhost,添加内容:hservice2,hservice3
如此:
hserver2
hserver3
这般:
- yarn-site.xml
如此:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hservice1</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${
yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${
yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${
yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${
yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${
yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${
yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
这般:

5. 重复4步骤在从节点虚拟机
6.启动hadoop
- 找到bin目录和超级bin目录

- 初始化
hservice1为namenode(主节点),hservice2和hservice3都是datanode(从节点),只需要对hserver1进行初始化操作,即对hdfs进行格式化。
在bin目录下执行(一定是bin)
./hadoop namenode -format
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件出现如图表示成功:

- 了解包含的各种启动方式(一定是sbin)

7.关闭防火墙
若不关闭外网连接时会被防护墙拦截,导致失败
8.测试
用本地浏览器访问: ip+端口号 (需要自己虚拟机的ip)
http://192.168.175.134:50070
这般:

9.有用的杂乱的
注1:
防火墙操作命令(CentOS7)
- systemctl stop firewalld.service #关闭防火墙
- systemctl disable firewalld.service #禁止防火墙开机启动
- firewall-cmd --state #查看防火墙状态,是否是running
4.firewall-cmd --reload #重启防火墙- firewall-cmd --zone=public --add-port=80/tcp --permanent开启端口
命令含义:
–zone #作用域
–add-port=80/tcp #添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
注2:
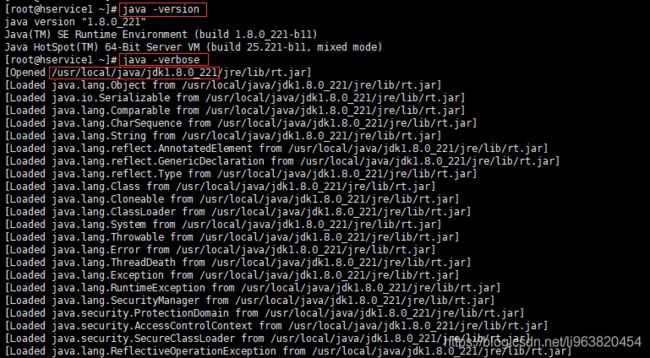
java安装路径寻找:
java -version #查看版本
java -verbose #在输出设备上显示虚拟机运行信息
路径如图: