linux搭建kafka单机+集群环境+demo
一. 单机环境
- 准备工作:
1.1. 一台或两台centos虚拟机,一台给zookeeper(192.168.56.13),一台给kafka(192.168.56.10)。也可以将zookeeper和kafka放在同一台虚拟机上
1.2. jdk 1.8
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
1.3. zookeeper
https://zookeeper.apache.org/releases.html
1.4. kafka
http://kafka.apache.org/downloads
我所有的工具软件都安装再/usr/local/soft目录下
- 安装jdk
2.1 切换到/usr/local目录下,创建soft目录,并将下载的jdk放到/usr/local/soft目录下解压
cd /usr/local
mkdir soft
cd soft
tar -zxvf jdk-8u261-linux-x64.tar.gz
配置java环境变量
vi /etc/profile
2.2 在profile文件末尾添加如下配置,
export JAVA_HOME=/usr/local/soft/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
保存退出后,执行source /etc/profile 使修改立即生效
查看是否配置成功 java -version 如果出现如下内容,则说明配置成功

在添加配置时,千万要小心不要把PATH 配置错了,如果出错,你的几乎所有命令都会执行不了,曾经我就做了这样一件傻事,查了老半天才解决,如果你也跟我一样傻,那就要重新给path赋值,path后面的值需要在一台正常的linux上执行echo $PATH命令查看
重新给PATH赋值
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
然后重新配置环境变量
- 安装zookeeper ,zookeeper依赖jdk 所以,要在jdk安装完成之后再安装zookeeper
3.1 将zookeeper安装文件放到soft目录下,进行解压。
这是zookeeper的目录结构
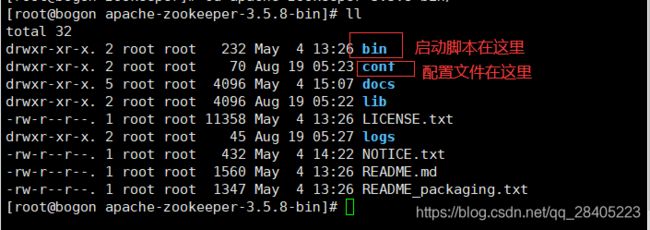
刚开始安装的zookeeper在conf目录下提供了一个配置文件的模板,名字为zoo_sample.cfg. 但是zookeeper的默认配置文件是zoo.cfg 所以这里要改一下名字,你可以复制一份,再改名字,我这里是直接改了:
mv zoo_sample.cfg zoo.cfg
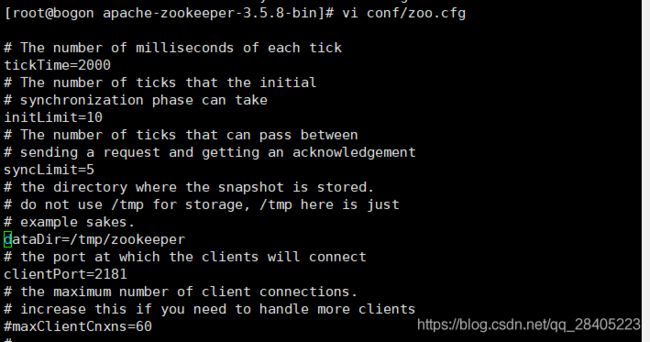
zoo.cfg文件内容:如果只是平时学习之类的,配置不用修改,可以直接使用,生产环境需要配置
3.2. 启动zookeeper。操作在zookeeper根目录下执行的命令
./bin/zkServer.sh start
关闭zookeeper
./bin/zkServer.sh stop
- 终于到kafka了
4.1 将下载的kafka安装文件放到soft目录下,解压
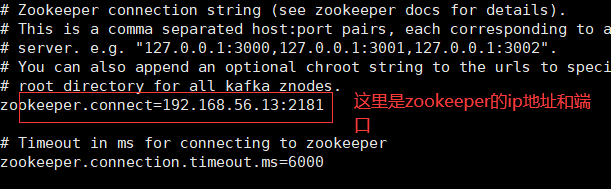
4.2 启动kafka,要修改配置文件中的zookeeper地址
tar -zvxf kafka_2.11-2.0.0.tgz
vi config/server.properties
以守护进程的方式启动kafka
sh bin/kafka-server-start.sh -daemon config/server.properties
创建topic
bin/kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092
在topic下发送消息
bin/kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092
hello kafka
消费者消费topic中的消息
bin/kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9092
停止kafka
./bin/kafka-server-stop.sh
到此就完成了kafka的搭建,官方也有很详细的quickstart 指导
http://kafka.apache.org/quickstart
二. 集群环境搭建
这是我要搭的集群环境的
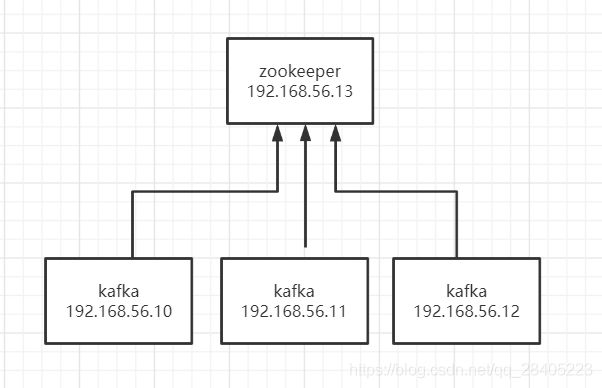
- 准备工作
四台centos7虚拟机,jdk 1.8, zookeeper, kafka.
zookeeper 使用单机环境安装的那台机器
这里按照单机环境安装方式分别给另外三台虚拟机安装kafka,xshell提供了一种快捷方式,可以同时操作多个窗口
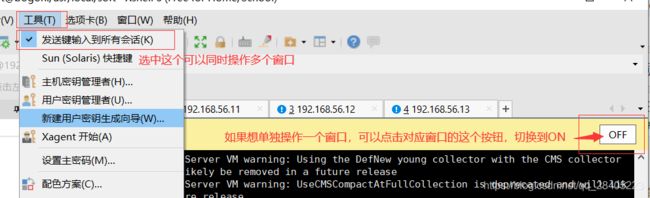
这样子,在一个窗口敲命令,其他窗口也会有响应,就可以同时给三台机器安装kafka了。
安装完成之后要修改conf/server.properties文件,有三处地方需要修改,注意一下,如果你打开了同时操作多个窗口,修改配置文件的时候一定要关掉,单独修改。
如果出现broker.id冲突的问题,确认一下,每个kafka的broker.id是否唯一,另外,在/tmp/kafka-logs目录下有一个meta.properties文件,其中也有配置broker.id ,要确保这个id和server.properties中的id要一致
broker.id=2 //这个id要保证唯一,三台机器不能相同
listeners=PLAINTEXT://192.168.56.12:9092 //这个ip要改成当前centos的ip
zookeeper.connect=192.168.56.13:2181 //这里是zookeeper的ip地址
然后按照之前的方式启动就ok了
最奉上一个小demo
依赖的组件
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.0.0version>
dependency>
生产者:SypKafkaProducer.java
package com.syp.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
/**
* @Author: SYP
* @Date: 2020/8/19
* @Description:
*/
public class SypKafkaProducer extends Thread{
KafkaProducer<Integer,String> producer;
String topic;
public SypKafkaProducer(String topic){
this.topic = topic;
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.10:9092,192.168.56.11:9092,192.168.56.12:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"syp-consumer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartition.class);
producer = new KafkaProducer<Integer, String>(properties);
}
@Override
public void run() {
int num = 0;
String msg = "mymsg"+num;
while(num < 20){
try{
RecordMetadata recordMetadata = producer.send(new ProducerRecord<Integer, String>(topic,msg)).get();
System.out.println(recordMetadata.offset()+"->"+recordMetadata.partition()+"->"+recordMetadata.topic());
TimeUnit.SECONDS.sleep(2);
++num;
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new SypKafkaProducer("test").start();
}
}
消费者:SypKafkaConsumer.java
package com.syp.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @Author: SYP
* @Date: 2020/8/19
* @Description:
*/
public class SypKafkaConsumer extends Thread{
KafkaConsumer<Integer,String> consumer;
String topic;
public SypKafkaConsumer(String topic){
this.topic = topic;
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.10:9092,192.168.56.11:9092,192.168.56.12:9092");
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "syp-consumer");
//group_id用来解决发布订阅模式
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "syp-gid");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumer = new KafkaConsumer<Integer, String>(properties);
}
@Override
public void run() {
consumer.subscribe(Collections.singleton(this.topic));
while(true){
ConsumerRecords<Integer, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
consumerRecords.forEach(record ->
System.out.println(record.key()+"->"+record.value()+"->"+record.offset()));
}
}
public static void main(String[] args) {
new SypKafkaConsumer("test").start();
}
}