一. 概念
K-means:事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
二. 算法流程
- 选择聚类的个数K
- 任意产生k个聚类, 然后确定聚类中心, 或者直接生成K个中心
- 对每个点确定其聚类中心点
- 再计算其聚类新中心
-
重复以上步骤直到满足收敛要求(通常确定的中心点不再改变)
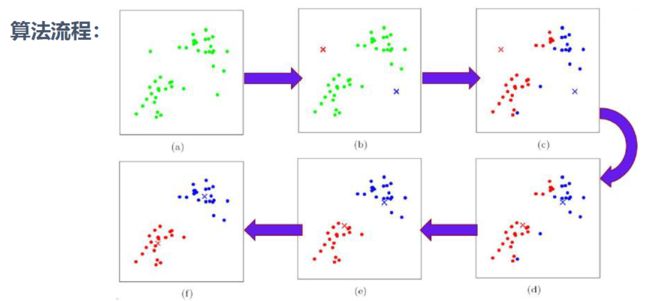 2-1
2-1
三. 案例
将下列数据点用K-means方法进行聚类:
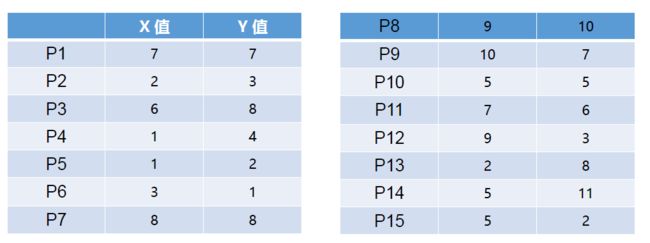
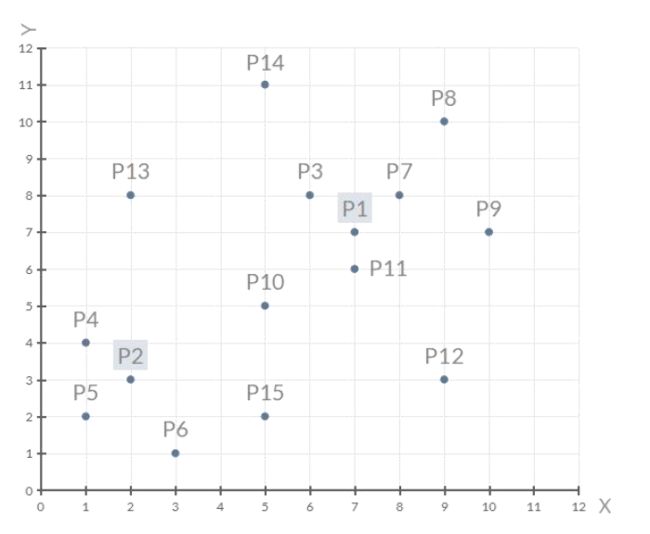
①通过距离公式将分别计算各点到P1,P2数据点距离:
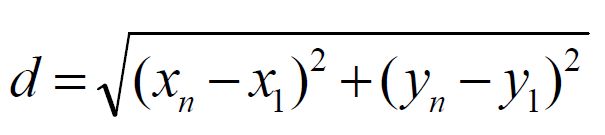
结果如下:
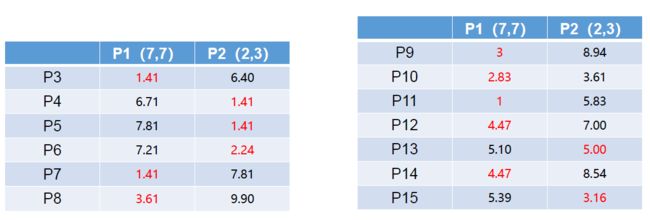
②选取距离较近的点整理进入相应队列:
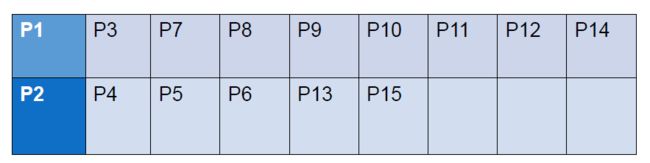
③计算出新一轮的队列中心:
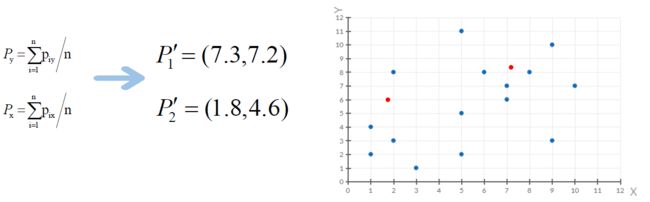
④重复上述步骤,开始新一轮迭代,算距离,取最近:
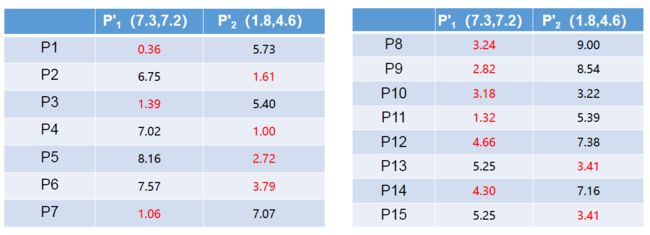
⑤再次选取距离较近的点整理进入相应队列,发现点的队列位置和上一轮并无差别:

⑥当每次迭代结果不变时,认为算法收敛,聚类完成:
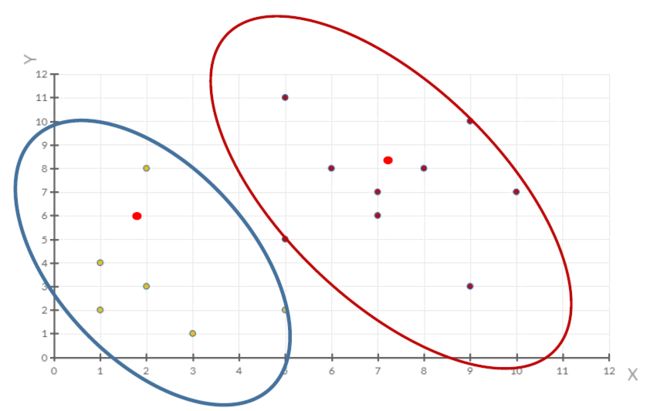
K-Means一定会停下,不可能陷入一直选质心的过程。
四. 算法优缺点
优点
1. 原理简单(看见中心点), 实现容易
2. 聚类效果中上(依赖k的选择)
3.空间复杂度o(N) 时间复杂度o(I * K * N)
* N为样本点个数,K为中心点个数,I为迭代次数缺点
1. 对离群点, 噪声敏感(中心点易偏移)
2. 很难发现大小差别很大的簇及进行增量计算
3. 结果不一定是全局最优,只能保证局部最优(与K的
个数及初值选取有关)。
五. K值确定
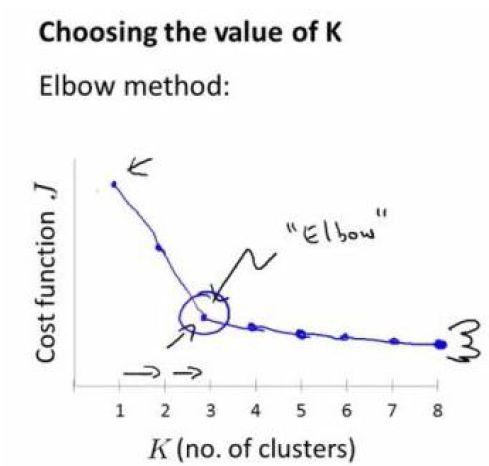
1.Elbow method就是“肘”方法,对于n个点的数据集,迭代计算k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和,可以想象到这个平方和是会逐渐变小的,直到k==n时平方和为0,因为每个点都是它所在的簇中心本身。但是在这个平方和变化过程中,会出现一个拐点也即“肘”点,下图可以看到下降率突然变缓时即认为是最佳的k值。
-
肘方法的核心指标是SSE(sum of the squared errors,误差平方和),Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
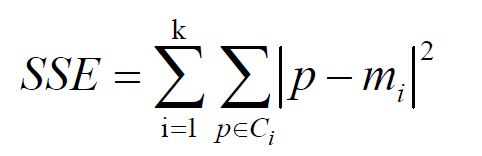 5-2
5-2 -
肘方法的核心思想:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。这也是该方法被称为肘方法的原因。
 5-3
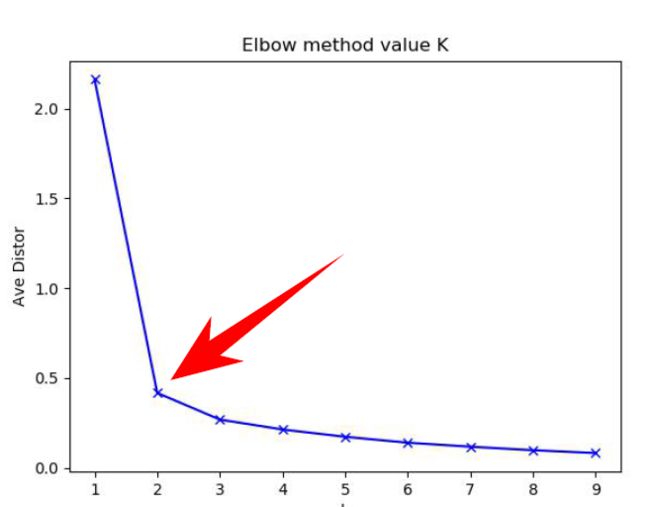
5-3 通过sklearn验证肘方法
import numpy as np
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt
cluster1 = np.random.uniform(0.5, 1.5, (2, 10))
cluster2 = np.random.uniform(3.5, 4.5, (2, 10))
X = np.hstack((cluster1, cluster2)).T
K = range(1, 10)
meandistortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
meandistortions.append(sum(np.min(cdist(X,
kmeans.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])
plt.plot(K, meandistortions, 'bx-')
plt.xlabel('k')
# plt.ylabel('平均畸变程度',fontproperties=font)
plt.ylabel('Ave Distor')
# plt.title('用肘部法则来确定最佳的K值',fontproperties=font);
plt.title('Elbow method value K');
plt.show()
输出结果如下:

六. 轮廓系数法
轮廓系数法(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。
该值处于-1~1之间,值越大,表示聚类效果越好。
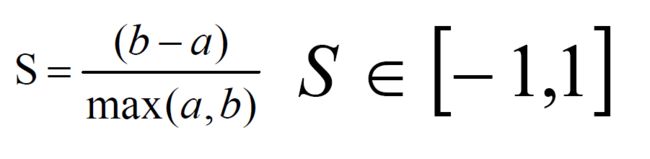
- a是Xi与同簇的其他样本的平均距离,称为凝聚度;
-
b是Xi与最近簇中所有样本的平均距离,称为分离度。
最近簇的定义:
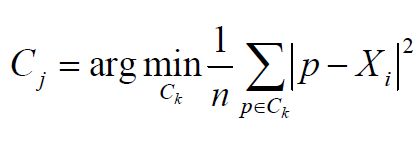 6-2
6-2 - 其中p是某个簇Ck中的样本。即,用Xi到某个簇所有样本平均距离作为衡量该点到该簇的距离后,选择离Xi最近的一个簇作为最近簇。
- 求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。
通过sklearn验证轮廓系数方法: 结果如下: 7. Calinski-Harabasz Index 类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数s会高,分数s高则聚类效果越好 其中m为训练集样本数,k为类别数。Bk为类别之间的协方差矩阵,Wk为类别内部数据的 8. Canopy算法配合初始聚类: ②Canopy+Kmeans: ③Canopy详解: 我们假设每个数据用小圆点来表示。在计算机中用List集合存储。 (2)继续从集合中取点,比如P,计算P到已经产生的所有Canopy的距离,如果到某个Canopy的距离小于T1,则将P加入到该Canopy;如果P到所有Canopy中心的距离都大于T1,则将P作为一个新Canopy,如下图中的Q就是一个新的Canopy。 (3)如果P到该Canopy距离小于T2,则表示P和该Canopy已经足够近,此时将P从从集合中删除,避免重复加入到其他Canopy。 Canopy算法优点: 缺点
已知:
轮廓系数取值为[-1, 1],其值越大越好,且当值为负时,表明 aiimport numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
#分割出6个子图,并在1号作图
plt.figure(figsize=(8, 10))
plt.subplot(3, 2, 1)
#初始化原始数字点
x1 = np.array([1, 2, 3, 1, 5, 6, 5, 5, 6, 7, 8, 9, 7, 9])
x2 = np.array([1, 3, 2, 2, 8, 6, 7, 6, 7, 1, 2, 1, 1, 3])
X = np.array(list(zip(x1, x2))).reshape(len(x1), 2)
#在1号子图做出原始数据点阵的分布
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('Sample')
plt.scatter(x1, x2)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'b']
#点的标号
markers = ['o', 's', 'D', 'v', '^', 'p', '*', '+']
#簇的个数
tests = [2, 3, 4, 5, 8]
subplot_counter = 1#训练模型
for t in tests:
subplot_counter += 1
plt.subplot(3, 2, subplot_counter)
kmeans_model = KMeans(n_clusters=t).fit(X)
for i, l in enumerate(kmeans_model.labels_):
plt.plot(x1[i], x2[i], color=colors[l],marker=markers[l],ls='None')
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('K = %s, SCoefficient = %.03f' % (t,
metrics.silhouette_score(X,kmeans_model.labels_,metric='euclidean')))
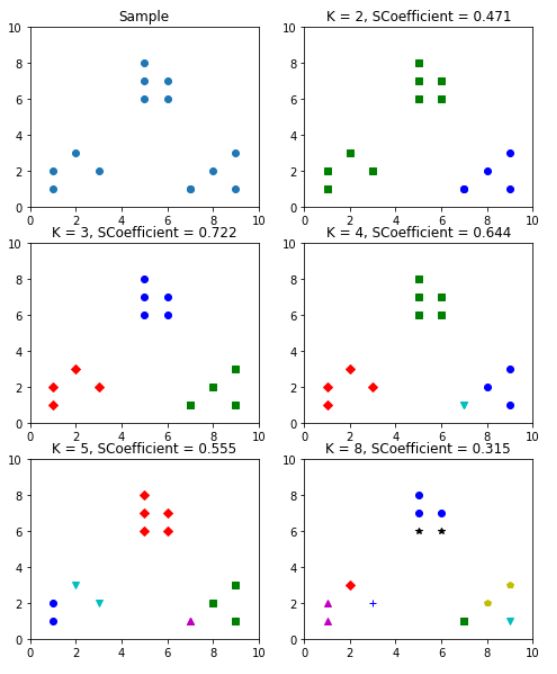
结论:由输入结果可知, 当k=3时, 轮廓系数的值最大
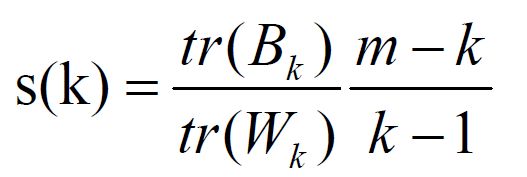
协方差矩阵。tr为矩阵的迹。
①Canopy简介:
Canopy聚类最大的特点是不需要事先指定k值(即clustering的个数),因此具有很大的实际应用价值。Canopy聚类虽然精度较低,但其在速度上有很大优势,因此可以使用Canopy聚类先对数据进行“粗”聚类,得到k值后再使用Kmeans进行进一步“细”聚类。
的对象之间不进行相似性计算。(即,根据Canopy算法产生的Canopies代替初始
的K个聚类中心点,由于已经将所有数据点进行Canopies有覆盖划分,在计算数据
离哪个k-center最近时,不必计算其到所有k-centers的距离,只计算和它在同一
个Canopy下的k-centers这样可以提高效率)
Canopy算法流程图: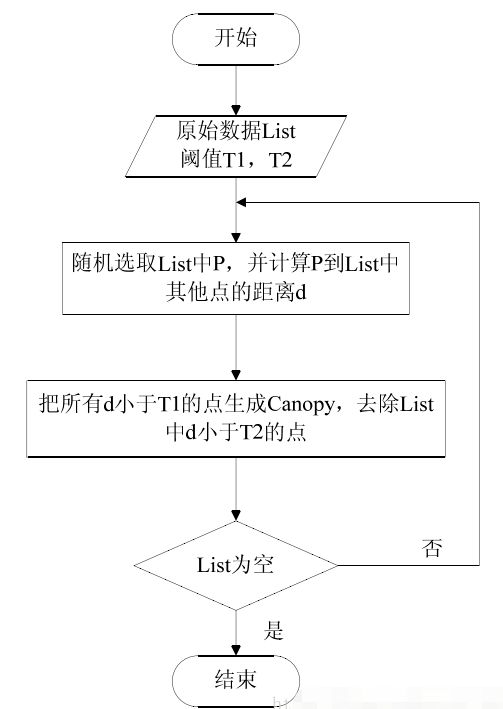
Canopy算法首先选择两个距离阈值:T1和T2,其中T1 > T2
(1)原始状态下的数据还没有分类,所以从集合中取出一点P,将P作为第一个类,我们也将类称为Canopy。
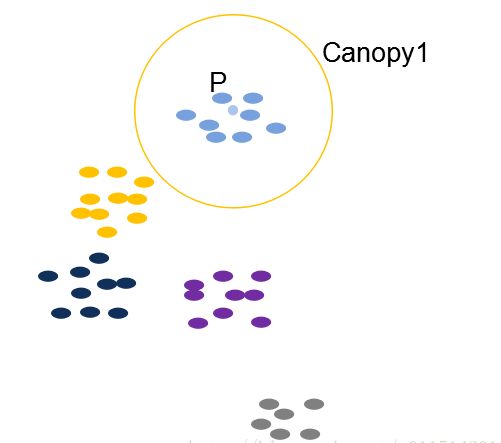
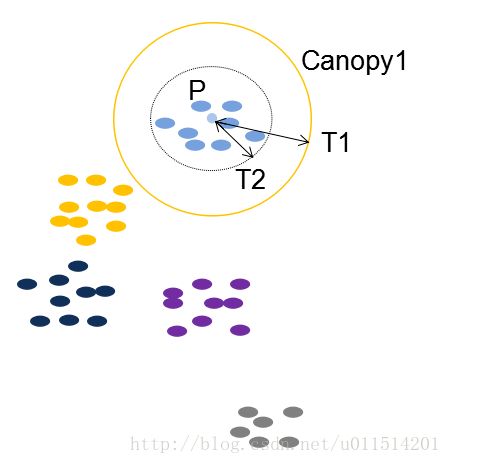
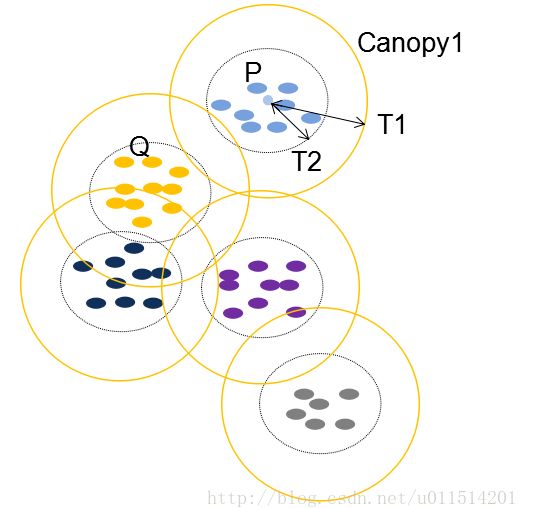
(4)对集合中的点继续执行上述操作直到集合为空,算法结束,聚类完成。
1、Kmeans对噪声抗干扰较弱,通过Canopy对比,将较小的NumPoint的Cluster直接去掉有利于抗干扰。
2、Canopy选择出来的每个Canopy的centerPoint作为K会更精确。
3、只是针对每个Canopy的内做Kmeans聚类,减少相似计算的数量。
算法中 T1、T2(T2 < T1) 的确定问题