Pyppeteer 的基本使用方法
什么是 Puppeteer?
要想知道什么是 Pyppeteer,首先应该先了解一下 Puppeteer:
Puppeteer 是 Google 基于 Node.js 开发的一个工具,拥有 Puppeteer 即可通过 JavaScript 来控制 Chrome 浏览器的一些操作,也可以用于网络爬虫上,其 API 极其完善,功能非常强大。
什么是 Pyppeteer?
Pyppeteer 是 Puppeteer 的 Python 实现,Pyppetter 基于 Chromium 浏览器通过执行一些动作来进行网页渲染,Pyppeteer 基于 Python 的新特性 async 实现,因此它也支持异步操作,效率相对于 Selenium 也有一定的提高。
使用 Pyppeteer 进行页面渲染

豆瓣电影筛选页面页面是 JavaScript 渲染生成的,此处使用 Pyppeteer,模拟浏览器的操作,直接用浏览器把页面渲染出来,然后再直接获取渲染后的结果。
import asyncio
from lxml import etree
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
async def main():
browser = await launch()
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.goto(URL, options={
'timeout': 10000})
doc = etree.HTML((await page.content()))
titles_xpath = "//div[@class='list']/a[@class='item']/div/img/@alt"
titles = doc.xpath(titles_xpath)
print(titles)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:
['心灵奇旅', '无依之地', '迈阿密的一夜', '捕鲸男孩', '绿洲', '我是大哥大 电影版', '除暴', '女人的碎片', '波斯语课', '穷途鼠的奶酪梦', '一秒钟', '刻在你心底的名字', '神奇女侠1984', '白虎', '玫瑰岛的不可思议的历史', '2020去死', '沐浴之王', '我和我的家乡', '夺冠', '信条']
具体分析如下:
使用 launch 方法新建一个 Browser 对象,相当于启动浏览器;接着 browser 调用 newPage 方法新建了一个 Page 对象,相当于浏览器新建一个选项卡,随后调用 setUserAgent 方法设置 User-Agent,然后 Page 对象调用了 goto 方法访问目标页面,相当于在浏览器中输入目标 URL,浏览器跳转到了对应页面进行加载;页面加载完成后再调用 content 方法获取当前浏览器页面的源代码,即 JavaScript 渲染后的结果;最后使用 lxml 进行解析并提取电影名称。
可以看到 Pyppeteer 的代码比 Selenium 更简洁易读,且环境配置更方便,还实现了异步爬取。
除此以外,我们还可以尝试 Pyppeteer 的其他功能:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport(viewport={
'width': 1280, 'height': 800})
await page.setUserAgent(fake.user_agent())
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(4.12)
await page.screenshot(path='screenshot.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:
{
'width': 1263, 'height': 800, 'deviceScaleFactor': 1.0000000149011612}
此处使用 setViewport 方法设定了浏览器窗口大小并模拟了网页截图,此外还执行了自定义的 JavaScript 以获得特定的内容。
截图如下:
最后调用 evaluate 方法执行 JavaScript 代码,其传入一个函数,返回网页的宽高、像素大小比率,最后得到一个 JSON 格式的对象。
Pyppeteer 常用方法
launch
使用 Pyppeteer 的第一步是调用 launch 方法来启动浏览器,首先通过官方文档查看 launch 方法的定义:
pyppeteer.launcher.launch(options: dict=None, **kwargs) → pyppeteer.browser.Browser
launch 方法处于 launcher 模块中,参数没有在声明中特别指定,返回类型是 browser 模块中的 Browser 对象,launch 方法是 async 修饰的方法,因此调用时需要使用 await。
launch 方法的参数如下:
| 参数 | 描述 |
|---|---|
| ignoreHTTPSErrors (bool) | 是否要忽略 HTTPS 的错误,默认是 False。 |
| headless (bool) | 是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。 |
| executablePath (str) | 可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。 |
| slowMo (int or float) | 通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。 |
| args (List[str]) | 在执行过程中可以传入的额外参数。 |
| ignoreDefaultArgs (bool) | 不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。 |
| handleSIGINT (bool) | 是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认是 True。 |
| handleSIGTERM (bool) | 是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。 |
| handleSIGHUP (bool) | 是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。 |
| dumpio (bool) | 是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默认是 False。 |
| userDataDir (str) | 即用户数据文件夹,即可以保留一些个性化配置和操作记录。 |
| env (dict) | 环境变量,可以通过字典形式传入。 |
| devtools (bool) | 是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。 |
| logLevel (int or str) | 日志级别,默认和 root logger 对象的级别相同。 |
| autoClose (bool) | 当一些命令执行完之后,是否自动关闭浏览器,默认是 True。 |
| loop (asyncio.AbstractEventLoop) | 事件循环对象。 |
有头模式和调试模式
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
async def main():
browser = await launch({
'headless': False,
'devtools': True,
})
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:
使用调试模式后,每开启一个界面就会弹出一个调试窗口。

禁用页面顶端提示条
有头模式时可以看到页面顶端提示条:“Chrome 正受到自动测试软件的控制”,可以使用 args 参数来关闭:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars']
})
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())

防止 WebDriver 检测
我们试着访问美团美食网:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://gz.meituan.com/meishi/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars']
})
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
可以看到 HTTP 状态码 为 403(403 Forbidden),即使我们设置了 User-Agent,美团依然能够检测到 WebDriver。
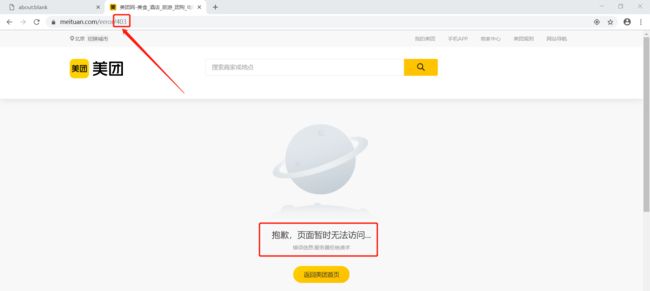
Pyppeteer 的 Page 对象有一个 evaluateOnNewDocument 方法,可以在每次加载网页的时候执行某个语句,此处执行将 WebDriver 隐藏的命令 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})':
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://gz.meituan.com/meishi/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars']
})
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.evaluateOnNewDocument('function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
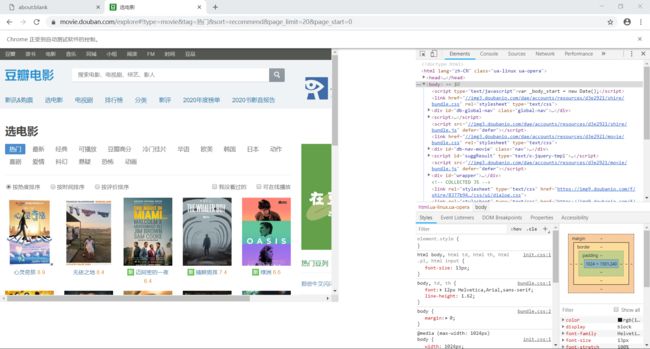
如下图可以看到绕过了 WebDriver 的检测,成功访问页面并加载出美团美食内容:

页面大小调整
上图中可发现页面大小与浏览器大小不统一,可以使用 setViewport 方法进行调整:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://gz.meituan.com/meishi/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars']
})
page = await browser.newPage()
await page.setViewport({
'width': 1530, 'height': 800})
await page.setUserAgent(fake.user_agent())
await page.evaluateOnNewDocument('function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
可以看到页面大小调整为正常状态:

用户数据持久化
平时访问网站时关键 Cookies 已经保存到本地浏览器,因此下次登录时可以直接读取并保持登录状态,这些信息保存在用户目录下,其不仅包含浏览器的基本配置信息,还有一些 Cache、Cookies 等信息,若能在浏览器启动时读取这些信息,则可以恢复一些历史记录以及登录状态信息。
Pyppeteer 提供了实现手段,即在启动的时候设置 userDataDir:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://www.zhihu.com/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars'],
'userDataDir': './userdata'
})
page = await browser.newPage()
await page.setViewport({
'width': 1530, 'height': 800})
await page.setUserAgent(fake.user_agent())
await page.evaluateOnNewDocument('function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
第一次启动时先手动登录:
登录后相关信息会保存在用户目录下,下次登录时即可直接读取:

此后再启动,无需重新登录(除非 Cookies 过期)。

Browser
launch 方法返回的是 Browser 对象(浏览器对象),即 Browser 类的一个实例,其拥有许多用于操作浏览器的方法。
无痕模式
无痕模式的好处就是环境干净,不与其他的浏览器示例共享 Cache、Cookies 等内容,其开启方式可以通过 createIncognitoBrowserContext 方法,其返回一个 context 对象,用其创建新选项卡:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://gz.meituan.com/meishi/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars'],
'userDataDir': './userdata'
})
context = await browser.createIncognitoBrowserContext()
page = await context.newPage()
await page.setViewport({
'width': 1530, 'height': 800})
await page.setUserAgent(fake.user_agent())
await page.evaluateOnNewDocument('function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto(URL, options={
'timeout': 10000})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
访问美团后先登录:

第二次使用无痕模式访问的时候,仍然需要登录:

Page
Page 对象即一个选项卡,对应一个页面。
提取网页资源
成功访问网页后,可以通过 Page 对象的 xpath 方法提取资源,并使用 getProperty 方法和 .jsonValue() 获取资源:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
URL = 'https://www.zhihu.com/'
async def main():
browser = await launch({
'headless': False,
'args': ['--disable-infobars'],
'userDataDir': './userdata'
})
page = await browser.newPage()
await page.setViewport({
'width': 1530, 'height': 800})
await page.setUserAgent(fake.user_agent())
await page.evaluateOnNewDocument('function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto(URL, options={
'timeout': 10000})
title_elements = await page.xpath("//div[@class='Card TopstoryItem TopstoryItem--old TopstoryItem-isRecommend']//a[@target='_blank']")
for element in title_elements:
title = await (await element.getProperty('textContent')).jsonValue()
url = await (await element.getProperty('href')).jsonValue()
print(title)
print(url)
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())

获取和切换选项卡
新建选项卡使用的是 newPage 方法,下面是获取和切换操作:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
page = await browser.newPage()
await page.goto('https://www.bilibili.com/')
pages = await browser.pages() # 获取所有页面
print('Pages:', pages)
page1 = pages[1]
# 等候2秒后切换选项卡
await asyncio.sleep(2)
await page1.bringToFront()
await asyncio.sleep(4)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
此处调用了 newPage 方法新建了两个选项卡并访问了两个网站。若要切换选项卡,只需调用 pages 方法获取所有页面,然后选一个页面调用其 bringToFront 方法即可切换到该页面对应的选项卡。
页面的前进、后退、刷新、截图、关闭功能
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.setUserAgent(fake.user_agent())
await page.setExtraHTTPHeaders(headers={
})
await page.evaluateOnNewDocument(
'function(){Object.defineProperty(navigator, "webdriver", {get: () => undefined})}')
await page.goto('https://www.bilibili.com/')
await page.goto('https://www.toutiao.com/')
await page.goBack()
await page.goForward()
await page.reload()
await page.screenshot()
await page.close()
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
输入文本、点击操作
输入文本使用 Page 对象的 type 方法:
-
第一个参数为选择器;
-
第二个参数为所输入的内容。
点击操作使用 Page 对象的 click 方法:
- 第一个参数为选择器;
- button:left、middle、right;
- clickCount:点击次数;
- delay:延迟点击(ms)。
import asyncio
from faker import Faker
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com/')
await page.type('#kw', 'Python') # 输入文本
await page.click('#su', options={
'button': 'left',
'clickCount': 1,
'delay': 3000, # 延迟点击(ms)
})
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:

获取源代码和 Cookies
Page 对象获取源代码使用 content 方法,获取 Cookies 使用 cookies 方法。
import asyncio
from faker import Faker
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com/')
print(await page.content())
print(await page.cookies())
await asyncio.sleep(412)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:
<!DOCTYPE html><html><head><script type="text/javascript" charset="utf-8" src="https://dss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/js/components/guide-8759cd328f.js"></script><script type="text/javascript" charset="utf-8" src="https://dss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/js/components/qrcode-da919182da.js"></script><script type="text/javascript" charset="utf-8" src="https://dss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/js/super_load-a97cbd2188.js"></script><script type="text/javascript" charset="utf-8" src="https://dss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/js/components/tips-e2ceadd14d.js"></script><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。">
[{
'name': 'PSTM', 'value': '1611901664', 'domain': '.baidu.com', 'path': '/', 'expires': 3759385311.821295, 'size': 14, 'httpOnly': False, 'secure': False, 'session': False}, {
'name': 'BIDUPSID', 'value': '6361BE73058980E68337B0E3AAA39F48', 'domain': '.baidu.com', 'path': '/', 'expires': 3759385311.821179, 'size': 40, 'httpOnly': False, 'secure': False, 'session': False}, {
'name': 'H_PS_PSSID', 'value': '33425_33516_33440_33259_33344_33585_26350_33544', 'domain': '.baidu.com', 'path': '/', 'expires': -1, 'size': 57, 'httpOnly': False, 'secure': False, 'session': True}, {
'name': 'BAIDUID', 'value': '6361BE73058980E68E74F842C5A4CEBB:FG=1', 'domain': '.baidu.com', 'path': '/', 'expires': 1643437664.821377, 'size': 44, 'httpOnly': False, 'secure': False, 'session': False}, {
'name': 'BD_HOME', 'value': '1', 'domain': 'www.baidu.com', 'path': '/', 'expires': -1, 'size': 8, 'httpOnly': False, 'secure': False, 'session': True}, {
'name': 'BD_UPN', 'value': '12314753', 'domain': 'www.baidu.com', 'path': '/', 'expires': 1612765665, 'size': 14, 'httpOnly': False, 'secure': False, 'session': False}, {
'name': 'BA_HECTOR', 'value': '8pak0l852g812l0guh1g17an10r', 'domain': '.baidu.com', 'path': '/', 'expires': 1611905265, 'size': 36, 'httpOnly': False, 'secure': False, 'session': False}]
执行 JavaScript 代码
使用 Page 对象的 evaluate 方法即可执行 JavaScript 代码:
import asyncio
from faker import Faker
from pyppeteer import launch
fake = Faker()
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.setViewport({
'width': 1530, 'height': 800})
await page.goto('https://www.bilibili.com/')
await asyncio.sleep(2)
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果:
{
'width': 465, 'height': 658, 'deviceScaleFactor': 1.25}
除了 evaluate 方法,还有 exposeFunction、evaluateOnNewDocument、evaluateHandle 方法也可以执行 JavaScript 代码。
延时等待
| 方法 | 描述 |
|---|---|
| waitForFunction | 等待某个 JavaScript 方法执行完毕或返回结果 |
| waitForNavigation | 等待页面跳转,如果没加载出来就会报错 |
| waitForRequest | 等待某个特定的请求被发出 |
| waitForResponse | 等待某个特定的请求收到了回应 |
| waitFor | 通用的等待方法 |
| waitForSelector | 等待符合选择器的节点加载出来 |
| waitForXPath | 等待符合 XPath 的节点加载出来 |
Reference:https://kaiwu.lagou.com/course/courseInfo.htm?courseId=46#/detail/pc?id=1679