TensorFlow-Keras 12.多输出模型
一.引言
上一篇文章介绍了 TensorFlow-Keras 多输入模型,利用相同的方法,还可以使用函数式 API 构建具有多个输出即多头的模型,一个简单的例子就是利用同一个数据,一次性预测某个体多个属性,例如输入某个用户的评论信息,预测该用户的社会属性
比如年龄,收入,性别等等。
二.多输出模型
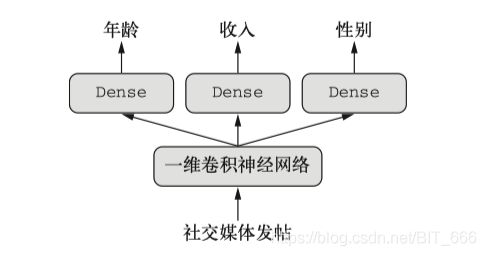
1.模型结构
通过解析用户的评论信息,通过 Embedding 层进行文本向量化,随后利用 LSTM 进行处理,分别接入 Dense 层预测年龄,性别,收入,另外使用 GRU 预测用户的兴趣偏好,从而该模型是一个输入对四个输出的多输出模型。
兴趣分100类,收入分10类,所以都使用 categorical_crossentropy 损失函数,年龄是 0-100 岁,采用 mse 损失函数,年龄是二值,采用 binary_crossentropy 损失函数。
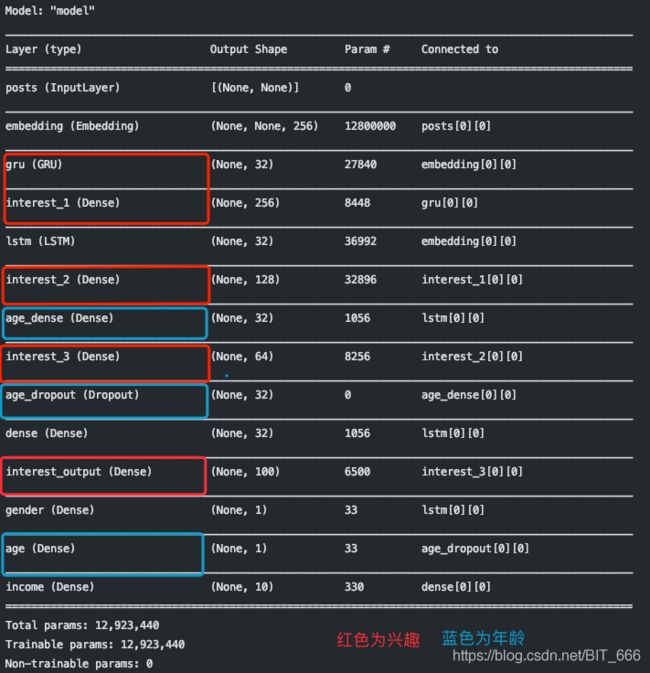
2.模型构建
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None,), dtype='int32', name='posts')
# embedding层
embedded_posts = layers.Embedding(input_dim=vocabulary_size, output_dim=256, input_length=100, name='embedding')(posts_input)
# LSTM 通用层
lstm_out = LSTM(32)(embedded_posts)
# 兴趣
x = GRU(32)(embedded_posts)
x = Dense(256, activation='relu', name='interest_1')(x)
x = Dense(128, activation='relu', name='interest_2')(x)
x = Dense(64, activation='relu', name='interest_3')(x)
interest_prediction = Dense(100, activation='softmax', name='interest_output')(x)
# 性别
gender_prediction = Dense(1, activation='sigmoid', name='gender')(lstm_out)
# 年龄
age_output = layers.Dense(32, activation='relu',name='age_dense')(lstm_out)
age_dropout = layers.Dropout(0.5, name='age_dropout')(age_output)
age_prediction = layers.Dense(1, name='age')(age_dropout)
# 收入
income_output = layers.Dense(32, activation='relu')(lstm_out)
income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(income_output)
model = Model(inputs=posts_input, outputs=[interest_prediction, gender_prediction, age_prediction, income_prediction])
model.compile(optimizer='rmsprop',
loss={'interest_output': 'categorical_crossentropy', 'gender': 'binary_crossentropy', 'age': 'mse', 'income': 'categorical_crossentropy'},
loss_weights={'interest_output': 1., 'gender': 10., 'age': 0.25, 'income': 1.})
model.summary()多输出模型需要注意为不同的输出目标制定不同的损失函数以及权重,构建模型时需要指定对应的输出层:
model = Model(inputs=posts_input, outputs=[interest_prediction, gender_prediction, age_prediction, income_prediction])编译模型时需要对模型损失进行对应,可以根据定义模型的顺序通过列表直接输入损失函数,也可以用过字典的形式将 layer.name 与损失函数对应传入,除此之外,多输出模型的损失是所有输出的损失之和,并在训练过程中最小化这个全局损失,
如果某一个损失严重不平衡将会导致模型针对单个损失值最大的任务优先优化,从而影响整体的效果,所以需要为不同的损失定义不同的权重,该参数通过 loss_weights传入,同样支持列表顺序传入与字典对应传入:
model.compile(optimizer='rmsprop',
loss={'interest_output': 'categorical_crossentropy', 'gender': 'binary_crossentropy', 'age': 'mse', 'income': 'categorical_crossentropy'},
loss_weights={'interest_output': 1., 'gender': 10., 'age': 0.25, 'income': 1.})
3.模型训练
# 构造数据
num_samples = 10000
max_length = 100
posts = np.random.randint(1, vocabulary_size, size=(num_samples, max_length))
age_targets = np.random.rand(num_samples) * 100
age_targets = np.asarray(age_targets).astype('float32')
income_targets = np.random.randint(0, 10, size=(num_samples,))
income_targets = utils.to_categorical(income_targets, 10)
gender_targets = np.random.randint(0, 2, size=(num_samples,))
gender_targets = np.asarray(gender_targets).astype('float32')
interest_targets = np.random.randint(0, 100, size=(num_samples,))
interest_targets = utils.to_categorical(interest_targets, 100)
print("interest:", interest_targets.shape)
# print(interest_targets[0:5])
print("age:", age_targets.shape)
# print(age_targets[0:5])
print('income:', income_targets.shape)
# print(income_targets[0:5])
print('gender:', gender_targets.shape)
# print(gender_targets[0:5])
print("Input data:", posts.shape)
model.fit(posts, [interest_targets, gender_targets, age_targets, income_targets], epochs=10, batch_size=128)原始评论数据生成与上文一致,主要是生成训练 label,年龄范围为 0-100 的 float 数值,收入为 0-9 个 level, 性别为 0,1, 兴趣为 0-99 个 level,通过 np.array,to_categorical 的得到最终的格式,训练即可,这里同样支持列表与字典传入预测 label。
interest: (10000, 100)
age: (10000,)
income: (10000, 10)
gender: (10000,)
Input data: (10000, 100)
Epoch 1/10
79/79 [==============================] - 12s 132ms/step - loss: 733.5626 - interest_output_loss: 4.6054 - gender_loss: 0.7233 - age_loss: 2877.6659 - income_loss: 2.3081
Epoch 2/10
79/79 [==============================] - 15s 185ms/step - loss: 397.2195 - interest_output_loss: 4.6028 - gender_loss: 0.6931 - age_loss: 1533.5176 - income_loss: 2.3067
......
79/79 [==============================] - 15s 185ms/step - loss: 107.7369 - interest_output_loss: 2.0794 - gender_loss: 0.6770 - age_loss: 386.3323 - income_loss: 2.3044
Epoch 9/10
79/79 [==============================] - 14s 183ms/step - loss: 101.2791 - interest_output_loss: 1.6510 - gender_loss: 0.6664 - age_loss: 362.6405 - income_loss: 2.3037
Epoch 10/10
79/79 [==============================] - 15s 185ms/step - loss: 97.0463 - interest_output_loss: 1.3308 - gender_loss: 0.6446 - age_loss: 347.8586 - income_loss: 2.3047以最后一列数据为例进行分析 interest_loss * 1 + gender_loss * 10 + age_loss * 0.25 + income_loss * 1 = 97.04615
![]()
与运行结果得到的 loss = 97.0463 基本一致,可以看到 age 的 loss 占了绝大多数的份额 ( 86.96465 / 97.04615 = 0.896116435324843 ) ,这里是模拟数据,如果是现实情况中则需要调整损失的权重,或者检查数据的可靠性,以保证多输出任务不被一个任务主导。