TensorFlow2.0入门到进阶系列——2_TensorFlow-Keras实战
2_TensorFlow-Keras实战
- 1、内容结构
- 2、理论部分
-
- 2.1、Tensorflow-keras简介
-
- 2.1.1、keras是什么
- 2.1.2、Tensorflow-keras是什么
- 2.1.3、Tensorflow-keras和keras的联系
- 2.1.4、Tensorflow-keras和keras的区别
- 2.1.5、Tensorflow-keras和keras如何选择
- 2.2、分类问题、回归问题、损失函数
-
- 2.2.1、分类问题、回归问题
- 2.2.2、目标函数
- 3、实战部分
-
- 3.1、Keras搭建分类模型
-
- 3.1.1、数据读取与展示
- 3.1.2、模型构建
- 3.1.3、模型训练参数查看
- 3.1.4、数据归一化处理
- 3.2、Keras回调函数
- 3.3、Keras搭建回归模型
- 3.4、Keras搭建深度神经网络
-
- 3.4.1、实战深度神经网络
- 3.4.2、实战批归一化、激活函数、dropout
- 3.5、Keras实现wide&deep模型
-
- 3.5.1 wide&deep模型
- 3.5.2 实战
- 3.6、Keras与scikit-learn实现超参数搜索
1、内容结构
- 内容如何安排
- 实战与理论并存,实战为主,理论为辅
- 小知识点第一次遇见会讲
- 大知识点独立为一个小节
- 代码的TensorFlow版本
- 大部分都是tf2.0
- 课程以tf.keras API为主,因而部分代码可以在tf1.3+运行
- 另有少量tf1.*版本代码(方便大家读懂老代码)
2、理论部分
- Tensorflow-keras简介;
- 分类问题、回归问题、损失函数;
- 神经网络、激活函数、批归一化、Dropout;
- Wide & deep 模型;
- 超参数搜索
2.1、Tensorflow-keras简介
2.1.1、keras是什么
- 基于python的高级神经网络API;
- Francois Chollet于2014-2015年编写keras;
- 以Tensorflow、CNTK或者Theano为后端运行,keras必须有后端才可以运行;
- 后端可以切换,现在多用TensorFlow
- 极方便于快速实验,帮助用户以最少的时间验证自己的想法;
2.1.2、Tensorflow-keras是什么
- Tensorflow对keras API规范的实现;
- 相对于以Tensorflow为后端的keras,Tensorflow-keras与Tensorflow结合更加紧密;
- 实现在tf.keras空间下;
2.1.3、Tensorflow-keras和keras的联系
- 基于同一套API
- keras程序可以通过改导入方式轻松转为tf.keras程序;
- 反之可能不成立,因为tf.keras有其他特性;
- 相同的JSON和HDF5模型序列化格式和语义;
2.1.4、Tensorflow-keras和keras的区别
- Tf.keras全面支持eager mode
- 只是用keras.Sequential和keras.Model时没影响
- 自定义Model内部运算逻辑的时候会有影响
- Tf低层API可以使用keras的model.fit等抽象
- 适用于研究人员
- Tf.keras支持基于tf.data的模型训练;
- Tf.keras支持TPU训练;
- Tf.keras支持tf.distribution中的分布式策略;
- 其他特性
- Tf.keras可以与Tensorflow中的estimator集成
- Tf.keras可以保存为SavedModel
2.1.5、Tensorflow-keras和keras如何选择
- 如果想用tf.keras的任何一个特性,那么选tf.keras;
- 如果后端互换性很重要,那么选择keras;
- 如果都不重要,那就随便。
2.2、分类问题、回归问题、损失函数
2.2.1、分类问题、回归问题
- 分类问题预测的是类别,模型的输出是概率分布
- 三分类问题输出例子:[0.2,0.7,0.1]
- 回归问题预测的是值,模型的输出是一个实数值
2.2.2、目标函数
为什么需要目标函数?
- 参数是逐步调整的
- 目标函数可以帮助衡量模型的好坏
- Model A:[0.1,0.4,0.5]
- Model B:[0.1,0.2,0.7]
分类问题:
- 需要衡量目标类别与当前预测的差距
- 三分类问题输出例子:[0.2,0.7,0.1] (1 ->one_hot -> [0,1,0])
- 三分类真实类别:2 -> one_hot -> [0,0,1]
- One-hot编码,把正整数变为向量表达
- 生成一个长度不小于正整数的向量,只有正整数的位置处为1,其余位置都为0
- 分类问题损失函数
- 平方差损失;
- 交叉熵损失;
- 平方差损失举例
- 预测值:[0.2,0.7,0.1]
- 真实值:[0,0,1]
- 损失函数值:[(0.2-0)^2 + (0.7-0) ^2 + (0.1-1) ^2 ] * 0.5 = 0.67
回归问题:
- 预测值与 真实值的差距
- 平方差损失
- 绝对值损失
模型的训练就是调整参数,使得目标函数逐渐变小的过程
3、实战部分
- Keras搭建分类模型;
- Keras回调函数;
- Keras搭建回归模型;
- Keras搭建深度神经网络;
- Keras实现wide&deep模型;
- Keras与scikit-learn实现超参数搜索。
3.1、Keras搭建分类模型
3.1.1、数据读取与展示
先导入各种需要的库
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
查看导入的库的版本信息
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)

查看使用的数据集的结构
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data()
x_valid,x_train = x_train_all[:5000],x_train_all[5000:] #前5000张做验证集 后55000做训练集
y_valid,y_train = y_train_all[:5000],y_train_all[5000:] #前5000张做验证集 后55000做训练集
print(x_valid.shape,y_valid.shape)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)

看一下数据集里面的图片是什么样的(了解数据集是机器学习很重要的一部分)
#定义一个函数,可以显示一张图像
def show_single_image(img_arr):
plt.imshow(img_arr,cmap="binary") #这里是灰度图,其他图像具体参数请百度imshow()函数
plt.show()
show_single_image(x_train[0])

查看多张照片
#显示很多张图片
def show_image(n_rows, n_cols, x_data, y_data, class_names):
assert len(x_data) == len(y_data) #验证x样本数和y样本数一样
assert n_rows * n_cols < len(x_data) #验证行和列的乘积不能大于样本数
plt.figure(figsize = (n_cols * 1.4, n_rows * 1.6)) #定义一张大图1.4 1.6 就是缩放的图片
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col #计算当前位置图片的索引
plt.subplot(n_rows, n_cols, index + 1) #大图上画子图(之前index是从0开始的,这里要从1开始)
plt.imshow(x_data[index], cmap="binary", interpolation='nearest') #interpolation缩放图片时,插值的方法
plt.axis('off') #坐标系关掉
plt.title(class_names[y_data[index]]) #给每一张小图都加上title
plt.show()
class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
show_image(3, 5, x_train, y_train, class_names)

3.1.2、模型构建
#tf.keras.models.Sequential()
'''
#构建模型
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28, 28]))
model.add(keras.layers.Dense(300, activation = "relu"))
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
'''
#模型构建的另一种等价写法
model = keras.models.Sequential([
keras.layers.Flatten(input_shape = [28, 28]), #将输入为28 * 28的图像展开(28*28的二维矩阵展成784的一维向量)
keras.layers.Dense(300, activation = "relu"),
keras.layers.Dense(100, activation = "relu"),
keras.layers.Dense(10, activation = "softmax")
])
# relu: y = max(0, x)
# softmax: 将变量变成概率分布。 x = [x1,x2,x3],
# y = [e^x1/sum, e^x2/sum, e^x3/sum, sum = e^x1 + e^x2 + e^x3]
# reason for sparse: y->index. y->one_hot->[]
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "adam",
metrics = ["accuracy"])
查看模型层数
model.layers

查看模型概况
model.summary()

训练模型
'''
[None, 784] * w + b -> [None, 300] 其中,w.shape->[784,300], b = [300]
'''
history = model.fit(x_train, y_train, epochs=10, validation_data = (x_valid, y_valid))
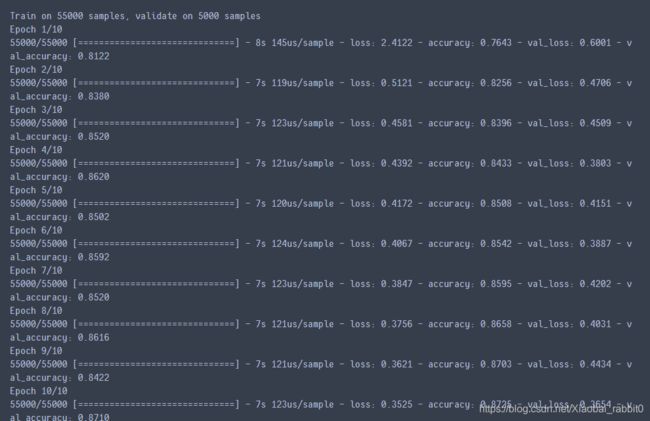
3.1.3、模型训练参数查看
history.history #查看history里面存储的一些值
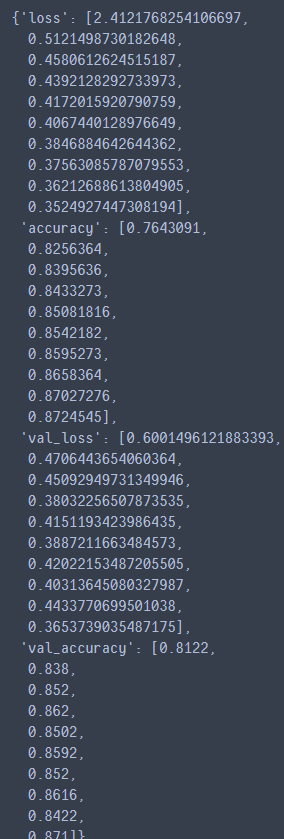
绘图查看history中的变量变化过程
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5)) #将数据转换成DataFrame,然后调用plot实现
plt.grid(True) #绘制网格
plt.gca().set_ylim(0, 1) #设定y坐标的范围
plt.show()
plot_learning_curves(history)

3.1.4、数据归一化处理
归一化分两种,数据归一化,批归一化
查看归一化之前数据的最大值最小值
print(np.max(x_train), np.min(x_train))
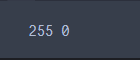
数据归一化
#数据归一化
# x = (x - u) / std
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train:[None, 28, 28] -> [None, 784]
x_train_scaler = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) #之前数据是int的,因为要做除法,所以先转换成float32的
#scaler.fit_transform()函数要求输入参数是二维数据,
#所以先变成二维数据,然后再变回三维数据
#scaler.fit_transform()函数有fit功能,记录训练的均值和方差(因为后面验证集和测试集数据归一化的时候,都要使用训练集的均值和方差)
#验证集和测试集归一化,用scaler.transform()即可
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
查看归一化之后数据的最大值最小值
print(np.max(x_train_scaler), np.min(x_train_scaler))

重新训练模型
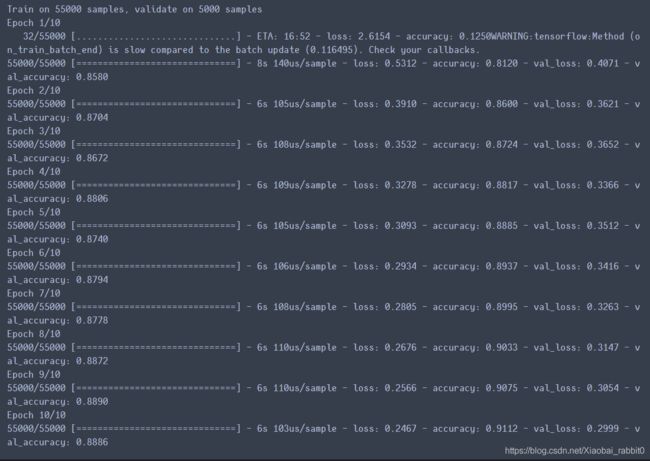
history = model.fit(x_train_scaler, y_train, epochs=10, validation_data = (x_valid_scaled, y_valid))

绘图查看history中的变量变化过程
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5)) #将数据转换成DataFrame,然后调用plot实现
plt.grid(True) #绘制网格
plt.gca().set_ylim(0, 1) #设定y坐标的范围
plt.show()
plot_learning_curves(history)

由结果可以看出对数据进行归一化处理之后,模型的精度有所提升(87.1%->89.2%)
#在测试集上进行测试
model.evaluate(x_test_scaled, y_test)

3.2、Keras回调函数
callbacks(回调函数)是在训练过程中做一些监听,所以要添加到fit函数中
修改训练模型为
#这里演示,使用三个常用的callbaks:TensorBoard, EarlyStopping, ModelCheckpoint
#对于Tensorboard需要一个文件夹,对于ModelCheckpoint来说需要一个文件名
#定义一个文件夹,和文件名
logdir = './callbacks'
#logdir = os.path.join("callbacks")
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir, "fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3),
]
#callbacks是在训练过程中做一些监听,所以要添加到fit函数中
history = model.fit(x_train_scaler, y_train, epochs=10,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)
在根目录下,生成callbacks文件夹。

打开Anaconda Powershell Prompt

在命令行中输入:tensorboard --logdir=callbacks,会得到一个网址
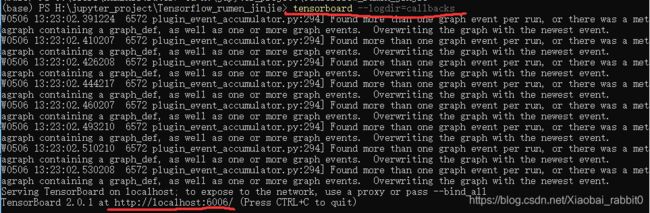
用浏览器打开网址,就打开tensorboard了
SCALARS:显示训练趋势图

GRAPHS:显示模型结构
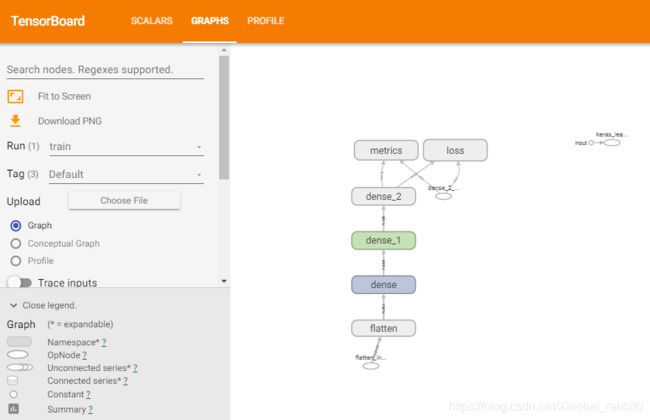
PROFILE:记录内存和CPU的使用量
3.3、Keras搭建回归模型
加载数据库,并显示版本信息
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
加载加福利尼亚房价数据集
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape)
输出前5个数据查看,这里使用pprint()函数输出,他是一种标准、格式化输出方式。
import pprint
pprint.pprint(housing.data[0:5])
pprint.pprint(housing.target[0:5])
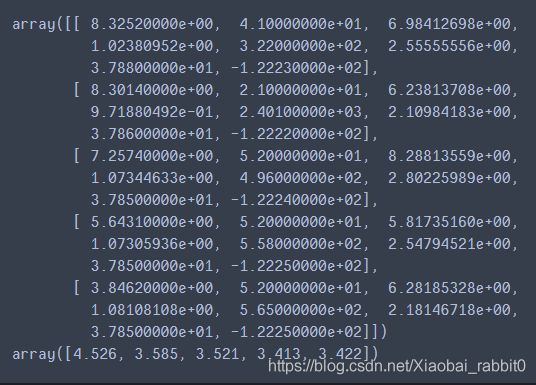
切分数据集
#切分数据集
from sklearn.model_selection import train_test_split
#切分出测试集
x_train_all,x_test,y_train_all,y_test = train_test_split(
housing.data, housing.target, random_state = 7, test_size = 0.25)
#总体数据按照3:1的比例划分,可以通过添加test_size参数调整比例 (不写,默认就是0.25)
#切分出训练集和验证集
x_train, x_valid, y_train, y_valid = train_test_split(
x_train_all, y_train_all, random_state = 11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)

数据归一化
#数据归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
构建模型
#构建模型
model = keras.models.Sequential([
keras.layers.Dense(30,activation='relu',input_shape=x_train.shape[1:]), #这里取8(读取第二维的长度),因为x_train.shape -> (11610,8)
keras.layers.Dense(1),
])
model.summary() #打印model的信息
model.compile(loss="mean_squared_error",optimizer="sgd") #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]

训练模型
#训练模型
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs = 100,
callbacks = callbacks)
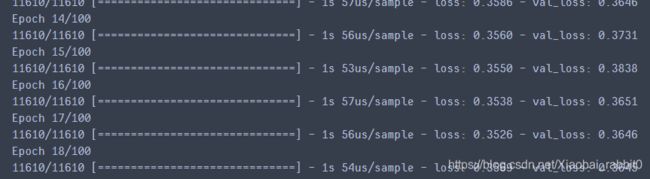
这里训练到18轮就停止训练了,因为损失进度的变换已经小于设定的1e-3,提前停止了训练。
绘图显示
#绘图显示
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
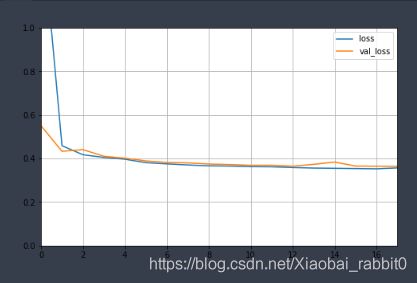
测试集验证模型
model.evaluate(x_test_scaled,y_test)

3.4、Keras搭建深度神经网络
- 激活函数

- 归一化与批归一化
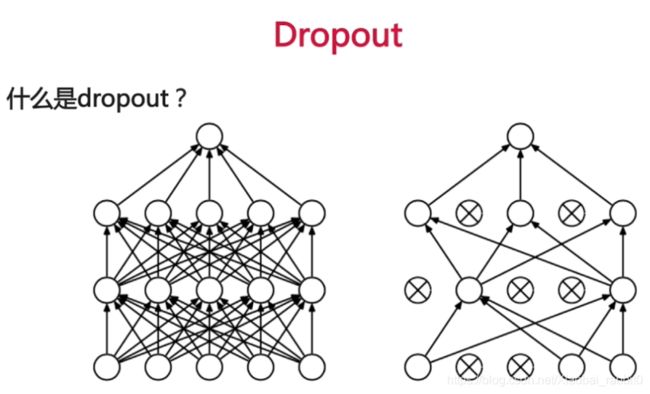
批归一化就是,从对输入数据进行归一化,扩展到网络的每层的激活值上。


- Dropout

3.4.1、实战深度神经网络
修改构造模型部分即可
#tf.keras.models.Sequential()
'''
#构建模型(浅层神经网络)
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28, 28]))
model.add(keras.layers.Dense(300, activation = "relu"))
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
'''
#深度神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28,28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
model.summary()
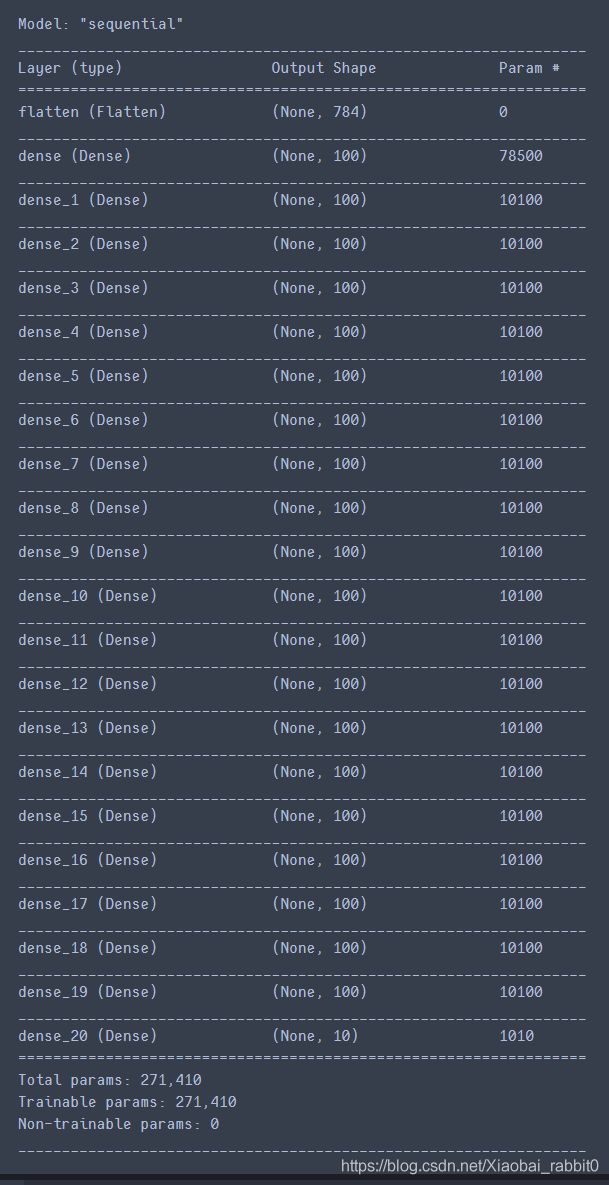
3.4.2、实战批归一化、激活函数、dropout
- 加入批归一化,只需修改模型构建部分代码
#tf.keras.models.Sequential()
'''
#构建模型(浅层神经网络)
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28, 28]))
model.add(keras.layers.Dense(300, activation = "relu"))
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dense(10, activation = "softmax"))
'''
#深度神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28,28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
#加 批归一化 层
model.add(keras.layers.BatchNormalization())
'''
#激活函数放在批归一化BN的后面
model.add(keras.layers.Dense(100))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation('relu'))
'''
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
model.summary()

训练模型
#这里演示,使用三个常用的callbaks:TensorBoard, EarlyStopping, ModelCheckpoint
#对于Tensorboard需要一个文件夹,对于ModelCheckpoint来说需要一个文件名
#定义一个文件夹,和文件名
#logdir = './dnn-callbacks'
logdir = os.path.join("dnn-bn-callbacks")
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir, "fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3),
]
#callbacks是在训练过程中做一些监听,所以要添加到fit函数中
history = model.fit(x_train_scaler, y_train, epochs=10,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)

加入批归一化BN层,准确率有所提升。
- 修改激活函数:relu -> selu(自带批归一化功能的激活函数)
修改模型构建部分代码
#深度神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28,28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu")) #selu函数自带批归一化功能。所以,这里就不需要批归一化处理了。
# #加 批归一化 层
# model.add(keras.layers.BatchNormalization())
# '''
# #激活函数放在批归一化BN的后面
# model.add(keras.layers.Dense(100))
# model.add(keras.layers.BatchNormalization())
# model.add(keras.layers.Activation('relu'))
# '''
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
- 添加Dropout层
#深度神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = [28,28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu")) #selu函数自带批归一化功能
# #加 批归一化 层
# model.add(keras.layers.BatchNormalization())
# '''
# #激活函数放在批归一化BN的后面
# model.add(keras.layers.Dense(100))
# model.add(keras.layers.BatchNormalization())
# model.add(keras.layers.Activation('relu'))
# '''
model.add(keras.layers.AlphaDropout(rate=0.5)) #更加强大的Dropout(常用)
'''
AlphaDropout强大之处:
1、均值和方差不变
2、归一化性质不变
'''
#model.add(keras.layers.Dropout(rate=0.5)) #rate丢掉的比例
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
model.summary()

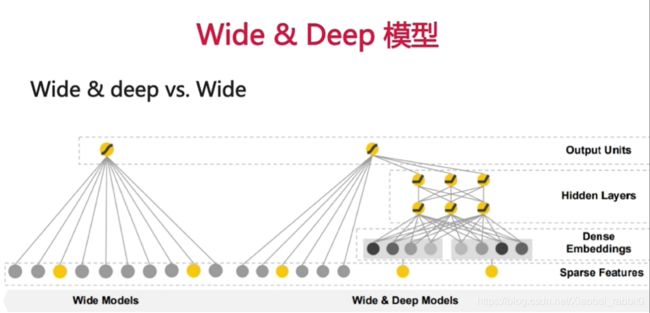
3.5、Keras实现wide&deep模型
3.5.1 wide&deep模型
- google在16年发布,用于分类和回归
- 这个算法已经应用到了Google play中的应用推荐
稀疏特征
- 离散值特征(eg:性别)
- One-hot表示(离散值用One-hot表示的时候,就认为是稀疏特征)
- eg:专业={计算机,人文,其他}。人文=[0,1,0]
- eg:词表={人工智能,你,他,慕课网,…}。他=[0,0,1,0,…]
- 稀疏特征可以进行叉乘={(计算机,人工智能),(计算机,你),…}
- 叉乘之后
- 稀疏特征做叉乘获取共现信息
- 实现记忆的效果
- 优点
- 有效,广泛用于工业界(推荐算法等)
- 缺点
- 需要人工设计
- 可能过拟合,所有特征都叉乘,相当于记住每一个样本
密集特征
- 向量表达
- eg:词表={人工智能,你,他,慕课网}
- 他=[0.3,0.2,0.6,(n维向量)]
- Word2vec工具(将词语转换为向量的工具,通过向量之间的距离可以得到成语之间的距离)
- 优点
- 带有语义信息,不同向量之间有相关性
- 兼容没有出现过的特征组合
- 更少人工参与
- 缺点
- 过度泛化,推荐不怎么相关的产品
wide&deep模型结构

3.5.2 实战
- wide&deep模型
- 功能API(函数式API)
- 子类API
- 多输入与多输出
代码实现
- 功能API(函数式API)
#构建模型
# model = keras.models.Sequential([
# keras.layers.Dense(30,activation='relu',input_shape=x_train.shape[1:]), #这里取8(读取第二维的长度),因为x_train.shape -> (11610,8)
# keras.layers.Dense(1),
# ])
#使用函数式API(功能API)
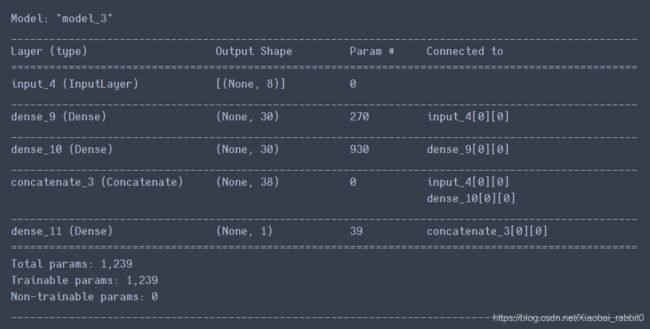
input = keras.layers.Input(shape=x_train.shape[1:]) #这里取8(读取第二维的长度),因为x_train.shape -> (11610,8)
hidden1 = keras.layers.Dense(30,activation='relu')(input) #函数式API 本层30个单元
hidden2 = keras.layers.Dense(30,activation='relu')(hidden1)
#这样的结构,更像是复合函数的结构:f(x) = h(g(x))
concat = keras.layers.concatenate([input,hidden2]) #hidden2是deep模型的输出,input是wide模型的输入
output = keras.layers.Dense(1)(concat)
#将函数式API定义的模型固化下来
model = keras.models.Model(inputs = [input],
outputs = [output])
model.summary() #打印model的信息
model.compile(loss="mean_squared_error",optimizer="sgd") #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
- 子类API
#构建模型
#子类API实现模型
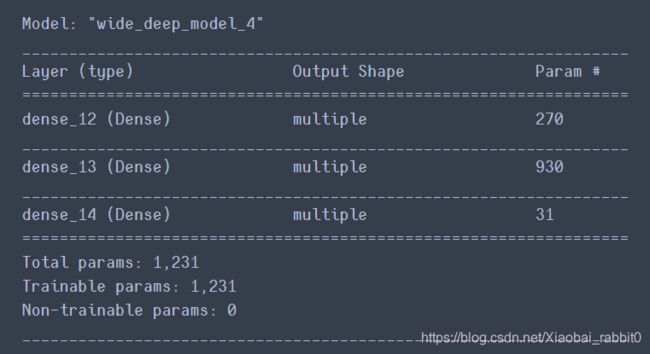
class WideDeepModel(keras.models.Model):
def __init__(self):
super(WideDeepModel,self).__init__()
'''定义模型的层次'''
self.hidden1_layer = keras.layers.Dense(30,activation='relu')
self.hidden2_layer = keras.layers.Dense(30,activation='relu')
self.output_layer = keras.layers.Dense(1)
def call(self,input):
'''完成模型的正向计算'''
hidden1 = self.hidden1_layer(input)
hidden2 = self.hidden2_layer(hidden1)
concat = keras.layers.concatenate([input,hidden2])
output = self.output_layer(hidden2)
return output
model = WideDeepModel()
model.build(input_shape=(None,8))
model.summary() #打印model的信息
model.compile(loss="mean_squared_error",optimizer="sgd") #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
- 多输入
#多输入
input_wide = keras.layers.Input(shape=[5])
input_deep = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30,activation='relu')(input_deep)
hidden2 = keras.layers.Dense(30,activation='relu')(hidden1)
concat = keras.layers.concatenate([input_wide,hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.model.Model(inputs = [input_wide,input_deep],outputs = [output])
model.summary() #打印model的信息
model.compile(loss="mean_squared_error",optimizer="sgd") #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
x_train_scaled_wide = x_train_scaled[:,:5] #输入前5个特征
x_train_scaled_deep = x_train_scaled[:,2:] #输入后6个特征(一共8个特征)
x_valid_scaled_wide = x_valid_scaled[:,:5]
x_valid_scaled_deep = x_valid_scaled[:,2:]
x_test_scaled_wide = x_test_scaled[:,:5]
x_test_scaled_deep = x_test_scaled[:,2:]
#训练模型
history = model.fit([x_train_scaled_wide,x_train_scaled_deep], y_train,
validation_data = ([x_valid_scaled_wide,x_valid_scaled_deep], y_valid),
epochs = 100,
callbacks = callbacks)
- 多输出(针对多任务学习)
#构建模型
#多输入+多输出
input_wide = keras.layers.Input(shape=[5])
input_deep = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30,activation='relu')(input_deep)
hidden2 = keras.layers.Dense(30,activation='relu')(hidden1)
concat = keras.layers.concatenate([input_wide,hidden2])
output = keras.layers.Dense(1)(concat)
output2 = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs = [input_wide,input_deep],outputs = [output,output2])
model.summary() #打印model的信息
model.compile(loss="mean_squared_error",optimizer="sgd") #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
x_train_scaled_wide = x_train_scaled[:,:5] #输入前5个特征
x_train_scaled_deep = x_train_scaled[:,2:] #输入后6个特征(一共8个特征)
x_valid_scaled_wide = x_valid_scaled[:,:5]
x_valid_scaled_deep = x_valid_scaled[:,2:]
x_test_scaled_wide = x_test_scaled[:,:5]
x_test_scaled_deep = x_test_scaled[:,2:]
#训练模型
history = model.fit([x_train_scaled_wide,x_train_scaled_deep], [y_train, y_train],
validation_data = ([x_valid_scaled_wide,x_valid_scaled_deep], [y_valid, y_valid]),
epochs = 100,
callbacks = callbacks)
model.evaluate([x_test_scaled_wide,x_test_scaled_deep],[y_test,y_test])
3.6、Keras与scikit-learn实现超参数搜索
为什么要超参数搜索
- 神经网络有很多训练过程中不变的参数
- 网络结构参数:几层,每层宽度,每层激活函数等;
- 训练参数:batch_size,学习率,学习率衰减算法等。
- 手工去试耗费人力
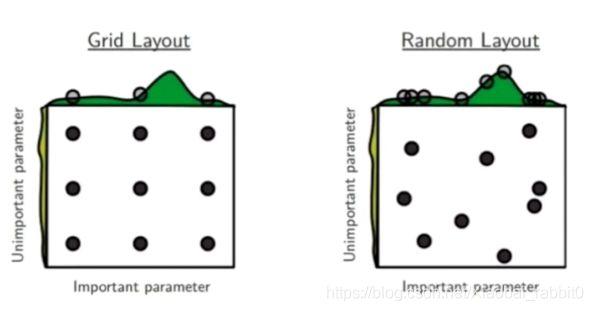
搜索策略
- 网格搜索;

- 随机搜索;
- 参数的生成方式为随机
- 可探索的空间更大
- 遗传算法搜索;
- 对自然界的模拟;
- A.初始化候选参数集合 -> 训练 -> 得到模型指标作为生存概率;
- B.选择 -> 交叉 -> 变异 -> 产生下一代集合;
- C.重新到A。
- 启发式搜索。
- 研究热点-AutoML
- 使用循环神经网络来生成参数
- 使用强化学习来进行反馈,使用模型来训练生成参数。
实战
- 超参数搜索
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape)
#切分数据集
from sklearn.model_selection import train_test_split
#切分出测试集
x_train_all,x_test,y_train_all,y_test = train_test_split(
housing.data, housing.target, random_state = 7, test_size = 0.25)
#总体数据按照3:1的比例划分,可以通过添加test_size参数调整比例 (不写,默认就是0.25)
#切分出训练集和验证集
x_train, x_valid, y_train, y_valid = train_test_split(
x_train_all, y_train_all, random_state = 11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
#数据归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train) #归一化的同时,可以算出均值和方差
x_valid_scaled = scaler.transform(x_valid) #利用在训练集得到的均值和方差来归一化
x_test_scaled = scaler.transform(x_test)
重点
#learning_rate:[1e-4,3e-4,1e-3,3e-3,1e-2,3e-2]
# w = w + grad * learning_rate
learning_rates = [1e-4,3e-4,1e-3,3e-3,1e-2,3e-2]
histories = []
for lr in learning_rates:
#构建模型
model = keras.models.Sequential([
keras.layers.Dense(30,activation='relu',input_shape=x_train.shape[1:]), #这里取8(读取第二维的长度),因为x_train.shape -> (11610,8)
keras.layers.Dense(1),
])
optimizer = keras.optimizers.SGD(lr)
model.compile(loss="mean_squared_error",optimizer=optimizer) #编译
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
#训练模型
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs = 100,
callbacks = callbacks)
histories.append(history)
#绘图显示
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
for lr,history in zip(learning_rates,histories):
print("Learning rate:",lr)
plot_learning_curves(history)
上述方法实现了lr的超参数搜索,但是有两个很明显的缺点:
1、实际超参数远远不止一个,所以需要使用20层或者更多层的for循环来实现超参数搜索;
2、这里使用for循环来实现超参数搜索,这样就导致只能等上一个模型训练完成之后,后面的模型才能开始训练,没有一个并行化的处理,增加了模型实现的时间复杂度,很费时间。
所以,我们需要会用一些现有的库来实现超参数搜索。
- 使用scikit实现超参数搜索
将tf.keras的model转化为sklearn支持的model - 封装函数可以在Tensorflow官网API查到
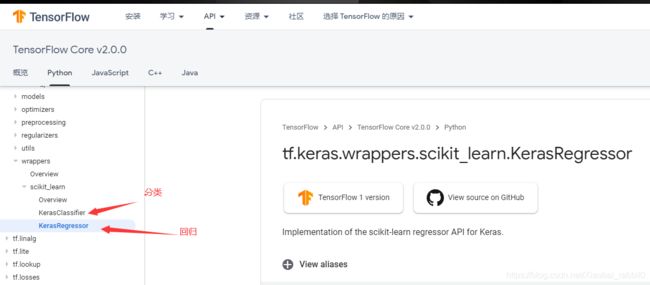
#RandomizedSearchCV
#1.将tf.keras的model转化为sklearn支持的的model (sklearn_model = keras.wrappers.scikit_learn.KerasRegressor(build_model))
#2.定义参数集合
#3.搜索参数(hidden_layers、layer_size、learning_rate)
def build_model(hidden_layers = 1,layer_size = 30,learning_rate = 3e-3): #中间层的层数、每一层的单元数、学习率
model = keras.models.Sequential() #定义model
model.add(keras.layers.Dense(layer_size,activation='relu',input_shape = x_train.shape[1:]))
#上面这一层单独拿出来,不放在for里面,因为第一层需要指定输入的数据大小
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size,activation='relu')) #全连接层
model.add(keras.layers.Dense(1)) #输出层
optimizer = keras.optimizers.SGD(learning_rate) #学习率可变,所以自定义optimizer
model.compile(loss = 'mse',optimizer = optimizer) #mse是mean_squared_error的缩写
return model
#将model转换为sklearn_model
sklearn_model = keras.wrappers.scikit_learn.KerasRegressor(build_model)
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
history = sklearn_model.fit(x_train_scaled,y_train,epochs = 100,
validation_data = (x_valid_scaled,y_valid),
callbacks = callbacks)

#绘图显示
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)

model.evaluate(x_test_scaled,y_test)
sklearn中没有evaluate这个函数
from scipy.stats import reciprocal
#reciprocal分布的分布函数 f(x) = 1/(x*log(b/a)) a <= x <= b
#定义搜索空间
param_distribution = {
"hidden_layers":[1,2,3,4],
"layer_size":np.arange(1,100),
"learning_rate":reciprocal(1e-4,1e-2), #使用reciprocal分布生成数据
}
#搜索参数
from sklearn.model_selection import RandomizedSearchCV
random_search_cv = RandomizedSearchCV(sklearn_model,
param_distribution, #参数空间
n_iter = 10, #从param_distribution中生成多少参数集合
#n_jobs = 5, #有多少任务在并行处理
cv = 3, #默认就是3
n_jobs = 1) #现在还不能并行化(所以,改成1)
#运行搜索算法
random_search_cv.fit(x_train_scaled,y_train,epochs = 100,
validation_data = (x_valid_scaled,y_valid),
callbacks = callbacks)

注:查看reciprocal分布生成的数据

'''
在超参数搜索的过程中每个epoch遍历7740个样本,而不是之前的11000多个。
这是因为,在做超参数搜索的时候用了cross_validation。
cross_validation:把训练集平均分成n份,用n-1份去训练,最后一份验证。(交叉验证)
默认n=3
'''
#查看最好的参数和最好的分值都是多少
print(random_search_cv.best_params_) #最好参数
print(random_search_cv.best_score_) #最好分值
print(random_search_cv.best_estimator_) #最好的model

#获取最好的model
model = random_search_cv.best_estimator_.model
model.evaluate(x_test_scaled,y_test)
