kaggle房价预测特征意思_房价的预测
这篇文章是关于kaggle上的一个房价预测的竞赛项目。官网链接:
House Prices: Advanced Regression Techniqueswww.kaggle.comHouse Prices的竞赛有两个版本,一个是针对初学者,一个是正儿八经的竞赛项目,两个版本的数据集都是一样的。

Top3的得分,是初学者课程里面的竞赛。我完全是跟着课程走了一遍,结果很懵逼,得分还挺高,只用到了XGBRegressor一个算法,过程也很简单。但是同样的代码提交到竞赛里面就不行了,排名只有28%。所以只好参考排名靠前的kenral,学习大神们都是怎么做的。
参考的kenral如下,如果英文还过得去的话,可以好好研究这两篇文章。
https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard#Modelling
https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python/data#1.-So...-What-can-we-expect?
一、数据探索
导入处理数据和可视化的库,读取数据文件
#处理数据的库
import pandas as pd
import numpy as np
#数据可视化的库
import matplotlib.pyplot as plt
import seaborn as sns
#配置sns的风格,图表的颜色
sns.set(style = 'white')
plt.rcParams['figure.facecolor'] = 'white'
plt.rcParams['axes.facecolor'] = 'white'
#读取数据
train = pd.read_csv("../input/house-prices-advanced-regression-techniques/train.csv")
test = pd.read_csv("../input/house-prices-advanced-regression-techniques/test.csv")熟悉一下数据
print(train.shape)
print(train.columns)
train.head()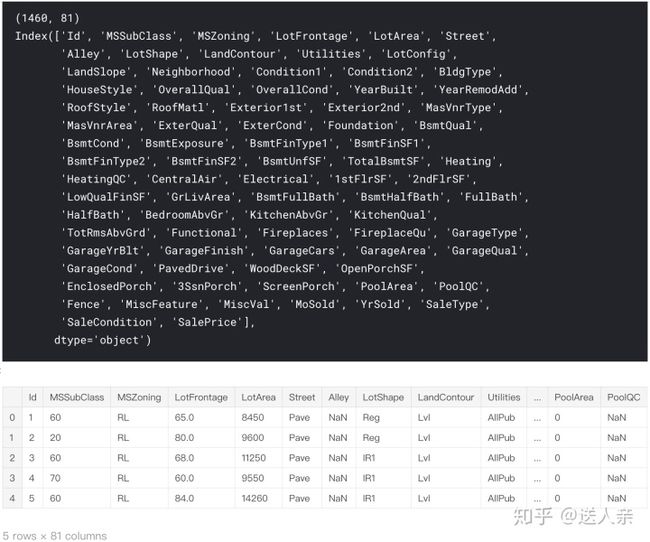
train.dtypes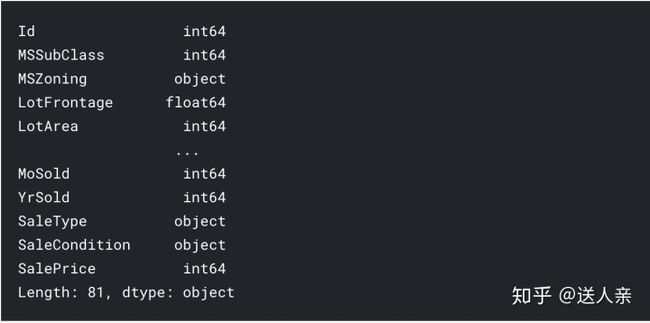
目标变量
由于我们需要根据各种特征,比如房屋质量、面积、公共设施等特征预测房屋的价格,所以我们先来研究一下训练集中的房价,看看有什么规律
train['SalePrice'].describe()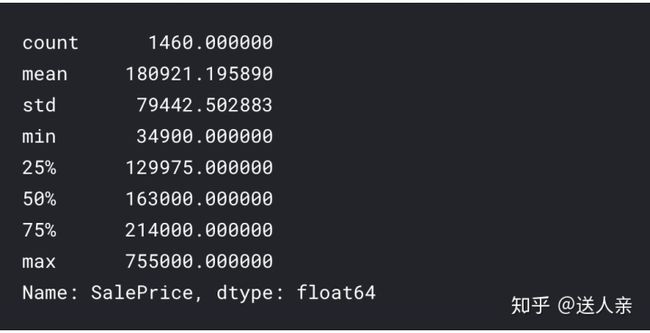
训练集中房价的平均值是18万美元(美国的房屋数据,房价以美元计价,应该没什么毛病),中位数是16万,平均值大于中位数,图形是右偏的。说明有一些房屋的价格是偏大,所以拉高了平均值。下面我们看看房价的直方图,这样比较直观。
#直方图
plt.figure(figsize=(10,6))
sns.distplot(train['SalePrice'])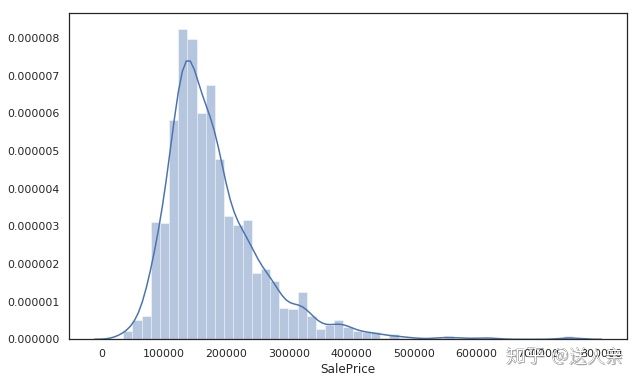
可以很明显的看到,图形右边的尾巴比较长。我们看看整体的偏度和峰度是多少。
#偏度、峰度
print("Skewness: %f" % train['SalePrice'].skew())
print("Kurtosis: %f" % train['SalePrice'].kurt())
在做统计分析的时候,我们经常会对数据进行变换,这样做的目的在于使数据的呈现方式接近我们所希望的前提假设,从而更好的进行统计推断。对数变换是数据变换的一种常用方式。现在我们对房价做一些对数的转换,使房价的分布,更符合统计学上的正态分布。
#导入scipy相关统计工具
from scipy import stats
from scipy.stats import skew, norm
from scipy.special import boxcox1p
from scipy.stats.stats import pearsonr
fig,ax = plt.subplots(1,2,figsize=(16,6))
#我们使用numpy的函数log1p,对SalePrice这一列的所有值进行转换
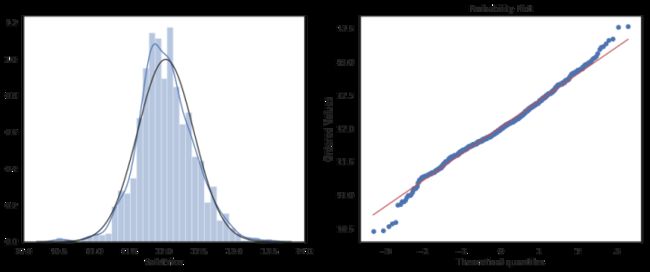
train["SalePrice"] = np.log1p(train["SalePrice"])
#直方图、概率图
sns.distplot(train['SalePrice'] , fit=norm,ax = ax[0])
stats.probplot(train['SalePrice'], plot=plt)
plt.show()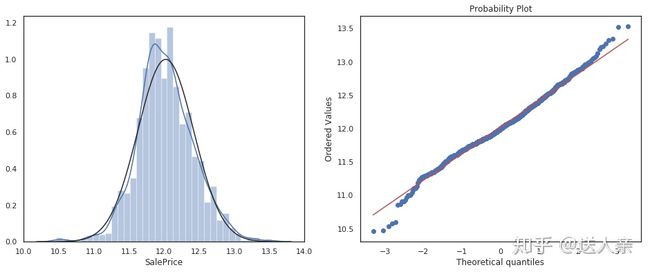
经过对数转换之后,目标变量SalePrice已经近似正态分布了。看完了目标变量,接下来我们再来研究目标变量之外的其他变量。
二、研究特征并处理缺失值
数据中的ID字段,对于我们分析没有意义。每个ID对应的是卖掉的房子在系统中的编号。
由于预测的是ID对应的saleprice,所以删除之前,我们先将训练集和测试集的ID赋予其他两个变量。
train_ID = train['Id']
test_ID = test['Id']
#删除掉Id字段
train.drop("Id", axis = 1, inplace = True)
test.drop("Id", axis = 1, inplace = True)先看一下缺失值的情况。我们目前并不知道训练集和测试集的缺失字段有什么规律,两者大部分缺失的字段比例是一样还是不一样?
#训练集数据缺失情况
train_data_missing = (train.isnull().sum()/len(train))*100
train_data_missing = train_data_missing.drop(train_data_missing[train_data_missing == 0].index).sort_values(ascending = False)
train_data_missing = pd.DataFrame({'train_missing_ratio':train_data_missing})
train_data_missing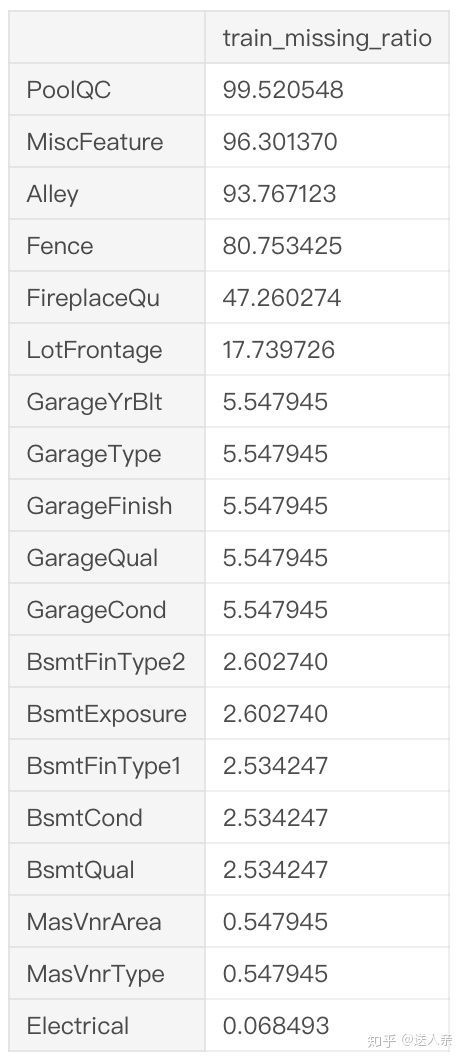
#测试集数据缺失情况
test_data_missing = (test.isnull().sum()/len(test))*100
test_data_missing = test_data_missing.drop(test_data_missing[test_data_missing == 0].index).sort_values(ascending = False)
test_data_missing = pd.DataFrame({'test_missing_ratio':test_data_missing})
test_data_missing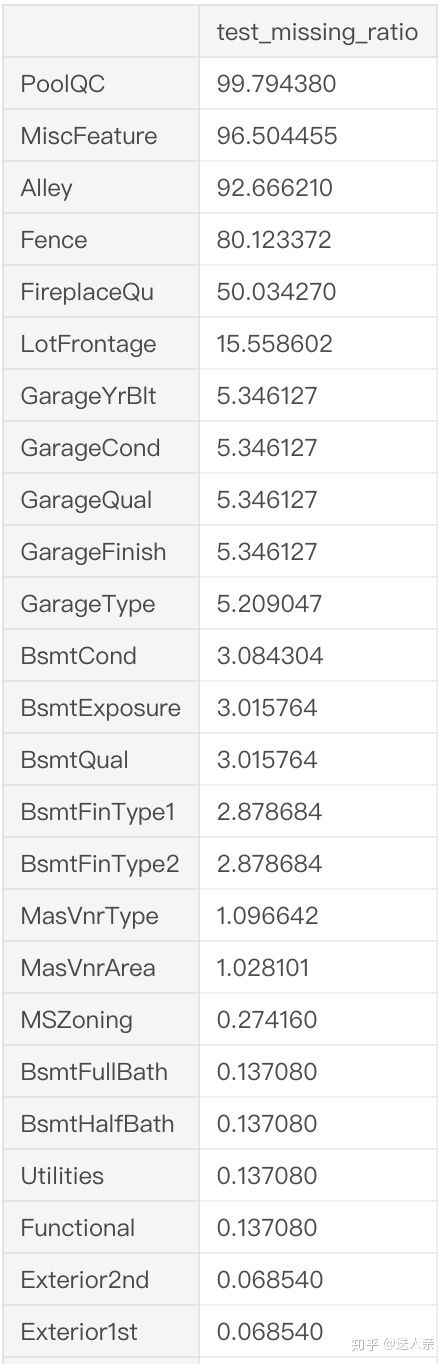
#训练集和测试集缺失的相同字段
commen_index = list(set(train_data_missing.index)&set(test_data_missing.index))
commen_data = pd.concat([train_data_missing.loc[commen_index],test_data_missing.loc[commen_index]],axis = 1)
commen_data.plot.bar(rot = 45,figsize=(15,12))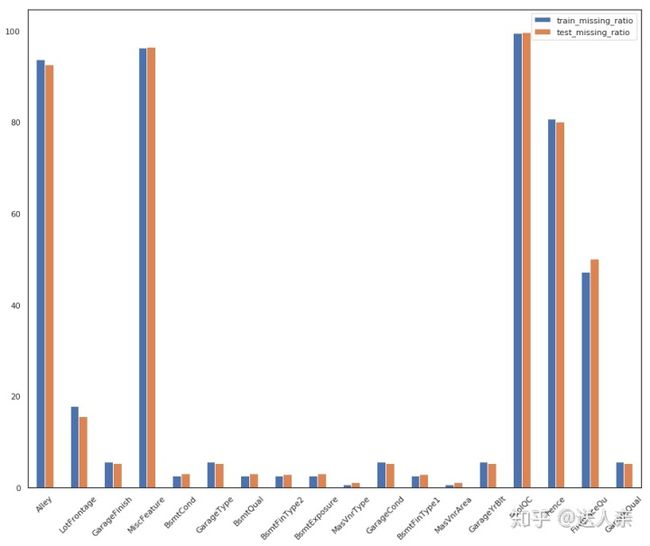
看数字可能不太直观,但是从输出的图形中,我们可以很明显的看到训练集和测试集缺失数据非常接近。两者在PoolQC、MiscFeature、Alley、Fence、FireplaceQu、LotFrontage、GarageYrBlt等字段缺失的占比比较大,而且缺失的占比也差不多。在我看来,两者缺失的数据符合才是正常的。因为如果这是一份完整的数据集,随机抽取一部分数据作为测试集,没有理由测试集的缺失数据与训练集差异很大。
既然训练集和测试集的缺失数据类似,所以我们就直接将两部分数据合并处理,这样就不需要分别填充缺失值
num_train = train.shape[0]
num_test = test.shape[0]
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)关于缺失值的处理,看了一些Kernels,有的是直接删除了这些缺失的字段,这种方法我也试过,效果不算太好,最终得分还是0.12左右,与我第一次提交没有太大的进步。后来看了排名较高的Kernels,大部分缺失字段都是用各种方式填充,最后结合融合模型,得分进入到0.11,进步算是很大了。所以我还是采用填充的方式,而不是简单粗暴的删除。
在data_description.txt文件中关于字段的描述,PoolQC:NA means "No Pool",MiscFeature:NA means "no misc feature",所以这些字段用空值None填充。
没有地下室,那么地下室评级、地下室面积、地下室浴室这些都不会有,所以用0填充就可以。
其他字段都是同样的道理,有的分类字段会用众数填充,就是出现次数最多的字段。
关于如何填充这些缺失字段,下面的这段代码不一定是最优的,这个也是参考排名前面的答主,有兴趣的话,也可以自己尝试其他的办法
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
all_data["Alley"] = all_data["Alley"].fillna("None")
all_data["Fence"] = all_data["Fence"].fillna("None")
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
all_data["LotFrontage"] = all_data.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('None')
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
all_data = all_data.drop(['Utilities'], axis=1)
all_data["Functional"] = all_data["Functional"].fillna("Typ")
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")填充完之后,我们再次检查一下,合并之后的数据集中是否有缺失值
all_data[all_data.isnull().values==True]
处理完之后,数据集不再包含空值,接下来就对分类数据进行处理。
分类数据可以分为两类:定序数据、定类数据。定类数据仅仅是一种标志,没有次序关系,比如性别,男1,女0,1和0是一种标志,没有谁大谁小,谁优谁劣之分。定序数据,有一定的顺序关系,小学=1,中学=2,高中=3等,不满意,中立,满意等分类的数据。
#游泳池的质量、壁炉的质量、出售的年月、月份都是有一定的顺序,所以用LabelEncoder转换
from sklearn.preprocessing import LabelEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
# process columns, apply LabelEncoder to categorical features
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(all_data[c].values))
all_data[c] = lbl.transform(list(all_data[c].values))整体的面积等于地下室的面积+一楼面积+二楼面积
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']Box-Cox变换是Box和Cox在1964年提出的一种广义幂变换方法,是统计建模中常用的一种数据变换,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式,Box-Cox变换可以明显地改善数据的正态性、对称性和方差相等性,对许多实际数据都是行之有效的。
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
# Check the skew of all numerical features
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print("nSkew in numerical features: n")
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(20)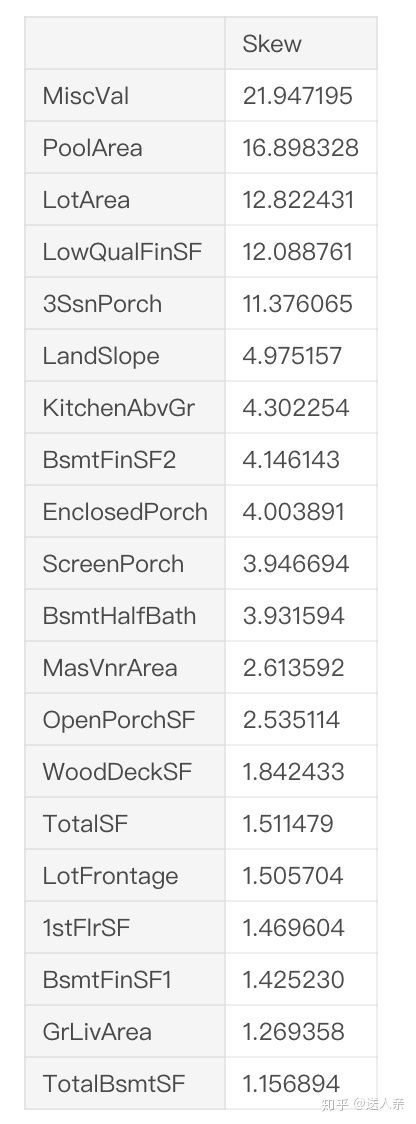
之前看原作者下面的评论,有人说 skewness = skewness[abs(skewness.Skew)>0.75]这样才是正确的,实际上改成这样,得分反而会低0.001左右
skewness = skewness[abs(skewness) > 0.75]
print("There are {} highly skewed numerical features to Box Cox transform".format(skewness.shape[0]))
skewed_features = skewness.index
lam = 0.15
for feat in skewed_features:
#all_data[feat] += 1
all_data[feat] = boxcox1p(all_data[feat], lam)对类别数据进行one-hot独热编码转换,直接使用pandas函数的get_dummies
all_data = pd.get_dummies(all_data)训练集和测试集分开
train = all_data[:num_train]
test = all_data[num_train:]三、建立模型
关于模型,我最开始只是很简单的使用了XGBRegressor这一种算法,得分0.12,排名大概28%左右,后续很难再提高了。有些排名靠前的Kenral使用了Stacking模型融合,说实话对于模型融合我的理解还比较肤浅,毕竟之前都没接触过。模型融合我的理解就是,使用多个算法对训练集进行训练,每次验证的结果作为新的特征来进行处理,最后对每个模型赋予不同的权重,来预测房价。
#导入回归相关的算法
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
import xgboost as xgb
import lightgbm as lgb
#导入数据预处理相关的方法
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
#导入模型调参相关的包
from sklearn import model_selection
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import ShuffleSplit#引入均方根误差,对模型进行评分。kaggle的score排名应该用的就是RMSE
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)参数的话,都是可以调节的。至于为什么选定这些参数,可以通过不断的测试得分来进行调整。我直接用了排名前面的Kenral里面的参数
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)模型得分初步评估
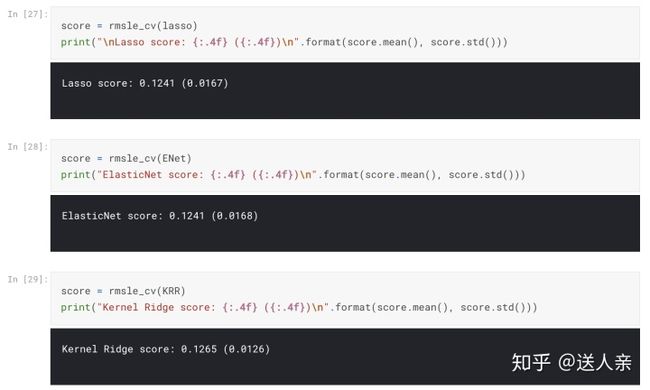
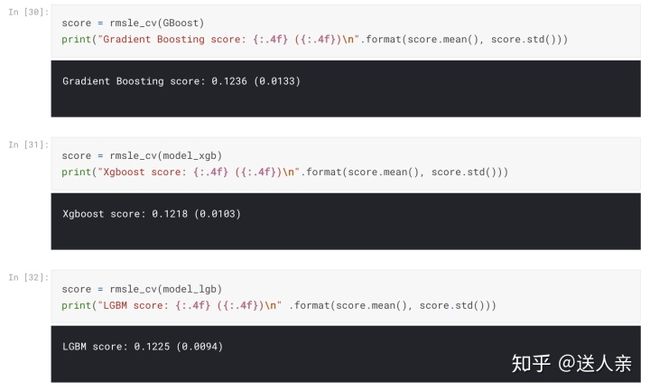
stacking models模型融合
from sklearn.base import BaseEstimator,RegressorMixin,TransformerMixin,clone
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1) # 返回所有预测结果的平均值# 选择了基本6个模型ENET,GBoost,KRR,Lasso,model_lgb
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso,model_lgb))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})n".format(score.mean(), score.std()))
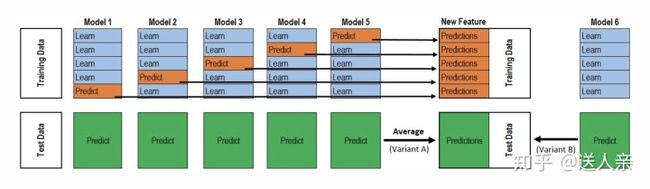
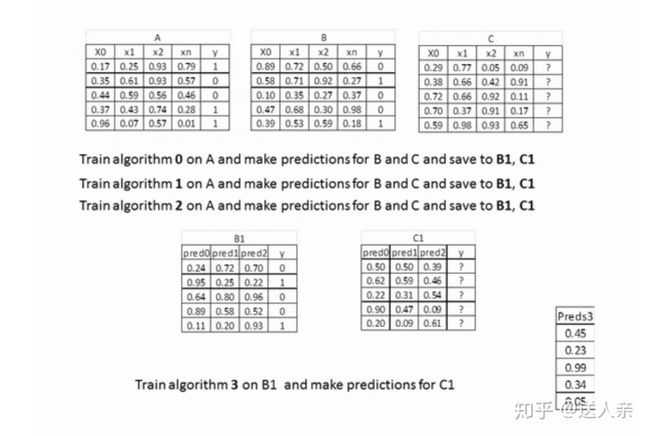
增加metal模型
- 将原始的train set 分割为两部分,train1,验证集(其对应的目标数据为y-valid) Train several base models on the first part (train)
- 用基模型在train1训练得到不同的基模型M1,M2,M3,M4... Test these base models on the second part (holdout)
- 用上面的模型预测 验证集,得到rsult1,result2,reuslt3,result4... Use the predictions from 3) (called out-of-folds predictions) as the inputs, 将result1,result2,result3,result4....组成新的训练集作为输入 train2 and the correct responses (target variable) 验证集的y-valid as the outputs to train a higher level learner called meta-model. y-valid 作为输出,然后可以训练得到一个更加高级的模型
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_fold=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_fold = n_fold
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models] # 创建空列表,用于放kfold中的各个模型
self.meta_model_ = clone(self.meta_model)
k_fold = KFold(n_splits=self.n_fold, shuffle=True, random_state=43)
out_of_flods_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, hold_index in k_fold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[hold_index])
out_of_flods_predictions[hold_index, i] = y_pred
self.meta_model_.fit(out_of_flods_predictions, y)
return self
def predict(self, X):
meta_features = np.column_stack([np.column_stack([model.predict(X) for model in base_models]).mean(
axis=1) for base_models in self.base_models_])
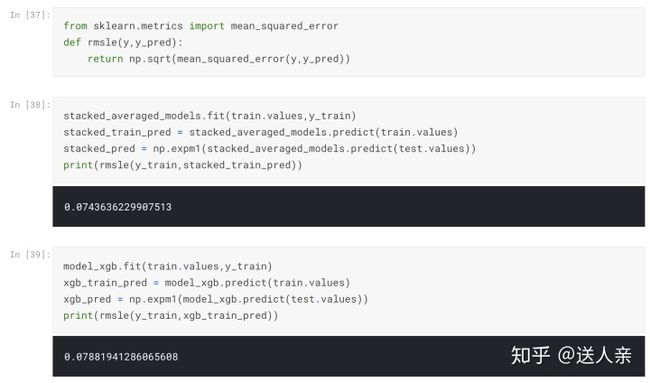
return self.meta_model_.predict(meta_features)stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR),
meta_model = lasso)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))

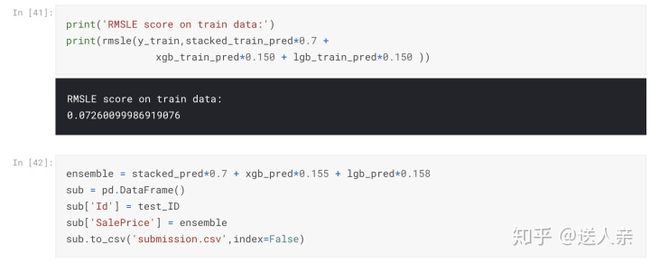
大家比较有争议的是,为什么stacked_pred的权重是0.7,xgb_pred是0.155,lgb_pred是0.158?这个有什么依据。原作者只是说从https://mlwave.com/kaggle-ensembling-guide/这篇文章得到的启发。文章是全英文,讲的是模型融合,看起来还比较吃力,有兴趣的可以看一下。我自己调了权重,比如0.8,0.1,0.1;0.7,0.1,0.2测试过,最终提交的得分效果始终没有原作者的得分高,相差在0.02左右。