机器学习之逻辑回归(手推公式版)
文章目录
-
- 前言
- 1. Sigmoid函数
- 2. 模型参数估计
- 3. 模型参数求解
-
- 3.1 梯度下降法求解
- 3.2 牛顿法求解
- 4. 正则化
- 5. 模型实现
- 结束语
前言
逻辑回归 ( L o g i s t i c (Logistic (Logistic R e g r e s s i o n ) Regression) Regression)虽冠有“回归”之名,却并不是真正意义上的回归,它其实是统计学中经典的分类方法,主要解决的是二分类问题。
对于逻辑回归,书上说法不一,李航老师的《统计学习方法》将逻辑回归称为
逻辑斯谛回归,周志华老师的西瓜书中将逻辑回归称为对数几率回归,简称对率回归,英文名亦称为Logit Regression。
1. Sigmoid函数
在线性回归这篇博客中我们介绍到线性回归模型 z = w T x + b z=\bm {w^Tx}+b z=wTx+b产生的预测值是一个实数值,对应的是连续型的变量,比如公司的股价、产品的销量等等。对于二分类问题,它的预测值是一个离散的变量,要么是0,要么是1,不会再由其他值。那么如何将线性回归模型的值变成离散的呢?这里就引入了一个连接函数 ( l i n k (link (link f u n c t i o n ) function) function)------- S i g m o i d Sigmoid Sigmoid函数。
S i g m o i d Sigmoid Sigmoid函数是形似 S S S的函数,也称为 L o g i s t i c Logistic Logistic函数,表达式如下: y = 1 1 + e − z y=\frac {1} {1+e^{-z}} y=1+e−z1 根据下面的 S i g m o i d Sigmoid Sigmoid函数函数图像,我们可以看出,该函数的输入值为 − ∞ -\infty −∞到 + ∞ +\infty +∞,输出值为 ( 0 , 1 ) (0,1) (0,1)。这样对于任意 z = w T x + b z=\bm {w^Tx}+b z=wTx+b,通过 S i g m o i d Sigmoid Sigmoid函数,我们都能得到0到1之间的概率值,也就实现了分类。
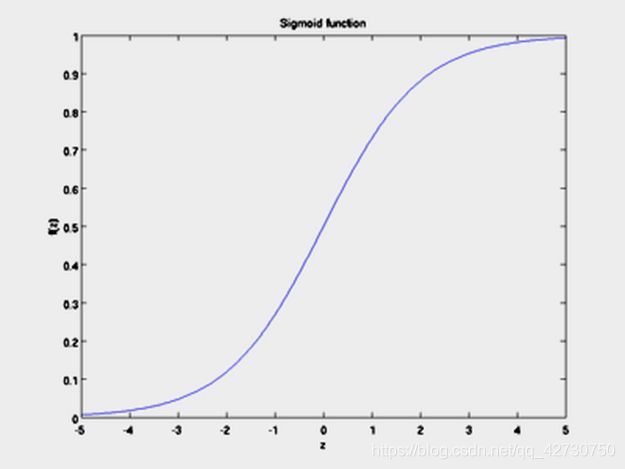
更为准确的说, L o g i s t i c Logistic Logistic函数是 S i g m o i d Sigmoid Sigmoid函数最重要的代表。
下面给出一些 S i g m o i d Sigmoid Sigmoid函数的相关性质及其证明:

纠正一下:把
性质3里面的倒数符号 d \mathrm {d} d 改成偏倒数符号 ∂ \partial ∂
权值向量和输入向量依旧记作 w , x \bm w,\bm x w,x,这时,逻辑回归模型就是下面这样: P ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b P ( y = 0 ∣ x ) = 1 1 + e w T x + b P(y=1|x)=\frac {e^{\bm {w^Tx}+b}} {1+e^{\bm {w^Tx}+b}} \\ P(y=0|x)=\frac {1} {1+e^{\bm {w^Tx}+b}} P(y=1∣x)=1+ewTx+bewTx+bP(y=0∣x)=1+ewTx+b1 对于给定的输入实例 x x x,按照上述模型可以求得 P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x)和 P ( y = 0 ∣ x ) P(y=0|x) P(y=0∣x),通过比较两个条件概率值的大小,将实例 x x x分到概率值较大的那一类。
一个事件的几率 ( o d d s ) (odds) (odds)是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是 p p p,那么该事件的几率是 p 1 − p \frac {p} {1-p} 1−pp,该事件的对数几率 ( l o g o d d s ) (log odds) (logodds)或 l o g i t logit logit函数是 l o g i t ( p ) = ln p 1 − p logit(p)=\ln \frac {p} {1-p} logit(p)=ln1−pp 对逻辑回归而言,上式又可以写成如下形式: ln P ( y = 1 ∣ x ) 1 − P ( y = 1 ∣ x ) = w T x + b \ln \frac {P(y=1|x)} {1-P(y=1|x)}=\bm {w^Tx}+b ln1−P(y=1∣x)P(y=1∣x)=wTx+b 也就是说,在逻辑回归模型中,输出 y = 1 y=1 y=1的对数几率是输入 x x x的线性函数,或者说,输出 y = 1 y=1 y=1的对数几率是由输入 x x x的线性函数表示的模型,即逻辑回归模型。
对几率取对数,即对数几率。
2. 模型参数估计
根据上述可知,在逻辑回归模型中,需要求解的参数是 w \bm w w和 b b b,我们可以通过极大似然估计法来估计模型参数。
对于给定的数据集 T = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , … , ( x N , y N ) } T=\{(x_1,y_1),(x_1,y_1),\dots,(x_N,y_N)\} T={ (x1,y1),(x1,y1),…,(xN,yN)},其中, x i ∈ R , y i ∈ { 0 , 1 } x_i \in \mathbb {R},y_i \in \{0,1\} xi∈R,yi∈{ 0,1},设 P ( y = 1 ∣ x ) = p ( x ) P ( y = 0 ∣ x ) = 1 − p ( x ) P(y=1|x)=p(x) \\[3pt] P(y=0|x)=1-p(x) P(y=1∣x)=p(x)P(y=0∣x)=1−p(x),则似然函数为:
L ( w ) = ∏ i = 1 N [ p ( x i ) ] y i [ 1 − p ( x i ) ] 1 − y i L(\bm w)=\prod_{i=1}^N[p(x_i)]^{y_i}[1-p(x_i)]^{1-y_i} L(w)=i=1∏N[p(xi)]yi[1−p(xi)]1−yi L ( w ) L(\bm w) L(w)是乘积形式,可将似然函数先取对数,转为对数似然函数:

这样,问题就变成了以 E ( w ) E(\bm w) E(w)为目标函数的最优化问题,似然函数 L ( w ) L(\bm w) L(w)最大化转换成了损失函数 E ( w ) E(\bm w) E(w)的最小化,然后就可以利用梯度下降法或牛顿法来求其最优解了。此时的 E ( w ) E(\bm w) E(w)称为交叉熵 ( c r o s s − e n t r o p y ) (cross-entropy) (cross−entropy)损失函数,没错,交叉熵损失函数其实就是对似然函数先取对数再取相反数得到的。
3. 模型参数求解
先求出损失函数 E ( w ) E(\bm w) E(w)对 w \bm w w一阶偏导数和二阶偏导数:

3.1 梯度下降法求解
梯度下降法要求目标函数 E ( w ) E(\bm w) E(w)是一个具有一阶连续偏导数的函数,大致求解过程为:先取适当的初值 w ( 0 ) \bm w^{(0)} w(0),不断迭代,更新 w \bm w w的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负梯度方向更新 w \bm w w的值,从而达到减少函数值的目的。
设 g k \bm g_k gk为 E ( w ) E(\bm w) E(w)在 w ( k ) \bm w^{(k)} w(k)的梯度, g k = ∂ E ( w ) ∂ w \bm g_k=\frac {\partial E(\bm w)} {\partial \bm w} gk=∂w∂E(w) 则第 k + 1 k+1 k+1次迭代值 w k + 1 \bm w^{k+1} wk+1为: w k + 1 = w k + λ ( − g k ) \bm w^{k+1}=\bm w^{k}+\lambda (-\bm g_k) wk+1=wk+λ(−gk) 当 ∣ ∣ g k ∣ ∣ < ϵ ||\bm g_k||<\epsilon ∣∣gk∣∣<ϵ时,迭代结束,得到近似解 w ∗ = w k \bm w^*=\bm w^{k} w∗=wk。
当 ∣ ∣ E ( w k + 1 ) − E ( w k ) ∣ ∣ < ϵ ||E(\bm w^{k+1})-E(\bm w^{k})||<\epsilon ∣∣E(wk+1)−E(wk)∣∣<ϵ或 ∣ ∣ w k + 1 − w k ∣ ∣ < ϵ ||\bm w^{k+1}-\bm w^{k}||<\epsilon ∣∣wk+1−wk∣∣<ϵ时,迭代结束,得到近似解 w ∗ = w k + 1 \bm w^*=\bm w^{k+1} w∗=wk+1。
3.2 牛顿法求解
牛顿法要求目标函数 E ( w ) E(\bm w) E(w)是一个具有二阶连续偏导数的函数,求解过程和梯度下降法差不多,这里面引入了一个矩阵 H H H,称为黑塞矩阵 ( H e s s i a n (Hessian (Hessian m a t r i x ) matrix) matrix)。
设 g k \bm g_k gk为 E ( w ) E(\bm w) E(w)在 w ( k ) \bm w^{(k)} w(k)的梯度, g k = ∂ E ( w ) ∂ w \bm g_k=\frac {\partial E(\bm w)} {\partial \bm w} gk=∂w∂E(w) H k H_k Hk为为 E ( w ) E(\bm w) E(w)在 w ( k ) \bm w^{(k)} w(k)的黑塞矩阵, H k = ∂ 2 E ( w ) ∂ w ∂ w T H_k=\frac {\partial^2 E(\bm w)} {\partial \bm w \partial \bm w^T} Hk=∂w∂wT∂2E(w) 则第 k + 1 k+1 k+1次迭代值 w k + 1 \bm w^{k+1} wk+1为: w k + 1 = w k − H k − 1 g k \bm w^{k+1}=\bm w^{k}-H_k^{-1}\bm g_k wk+1=wk−Hk−1gk 当 ∣ ∣ g k ∣ ∣ < ϵ ||\bm g_k||<\epsilon ∣∣gk∣∣<ϵ时,迭代结束,得到近似解 w ∗ = w k \bm w^*=\bm w^{k} w∗=wk。
当 ∣ ∣ E ( w k + 1 ) − E ( w k ) ∣ ∣ < ϵ ||E(\bm w^{k+1})-E(\bm w^{k})||<\epsilon ∣∣E(wk+1)−E(wk)∣∣<ϵ或 ∣ ∣ w k + 1 − w k ∣ ∣ < ϵ ||\bm w^{k+1}-\bm w^{k}||<\epsilon ∣∣wk+1−wk∣∣<ϵ时,迭代结束,得到近似解 w ∗ = w k + 1 \bm w^*=\bm w^{k+1} w∗=wk+1。
4. 正则化
正则化是用来防止模型过拟合的一种策略,在损失函数的基础之上加上一个正则化项 ( r e g u l a r i z e r ) (regularizer) (regularizer)或惩罚项 ( p e n a l t y (penalty (penalty t e r m ) term) term),损失函数改变,基于损失函数的最优化来求解的参数取值必然改变,以此来调节模型拟合的程度。
常用的有 L 1 L1 L1正则化和 L 2 L2 L2正则化两种选项,其中, L 1 L1 L1范数表现为参数向量中的每个参数的绝对值之和, L 2 L2 L2范数表现为参数向量中的每个参数的平方和然后再求平方根。
即 ∣ ∣ w ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + ⋯ + ∣ w N ∣ ∣ ∣ w ∣ ∣ 2 = ∣ w 1 ∣ 2 + ∣ w 2 ∣ 2 + ⋯ + ∣ w N ∣ 2 ||\bm w||_1=|w_1|+|w_2|+\dots+|w_N| \\[3pt] ||\bm w||_2=\sqrt {|w_1|^2+|w_2|^2+\dots+|w_N|^2} ∣∣w∣∣1=∣w1∣+∣w2∣+⋯+∣wN∣∣∣w∣∣2=∣w1∣2+∣w2∣2+⋯+∣wN∣2 E ( w ) L 1 = E ( w ) + λ ∣ ∣ w ∣ ∣ 1 E ( w ) L 2 = E ( w ) + λ 2 ∣ ∣ w ∣ ∣ 2 2 E(\bm w)_{L1}=E(\bm w)+\lambda||\bm w||_1 \\[3pt] E(\bm w)_{L2}=E(\bm w)+\frac {\lambda} {2} ||\bm w||_2^2 E(w)L1=E(w)+λ∣∣w∣∣1E(w)L2=E(w)+2λ∣∣w∣∣22 上述这种形式在书中很常见,通过控制正则项来调整损失函数。
E ( w ) L 1 = C ∗ E ( w ) + λ ∣ ∣ w ∣ ∣ 1 E ( w ) L 2 = C ∗ E ( w ) + λ 2 ∣ ∣ w ∣ ∣ 2 2 E(\bm w)_{L1}=C*E(\bm w)+\lambda||\bm w||_1 \\[3pt] E(\bm w)_{L2}=C*E(\bm w)+\frac {\lambda} {2} ||\bm w||_2^2 E(w)L1=C∗E(w)+λ∣∣w∣∣1E(w)L2=C∗E(w)+2λ∣∣w∣∣22 上述这种形式是 s k l e a r n sklearn sklearn正则化形式,通过控制损失函数前的系数 C C C直接调整损失函数。
可能有些小伙伴们会有个疑问:为啥上述的正则化中 L 2 L_2 L2范式要带个平方?这是因为啊 L 2 L_2 L2范式是先求平方和再开根号,带个平方是为了省去开根号的操作,简化运算,哈哈哈哈。
5. 模型实现
这里使用sklearn.linear_model里的LogisticRegression进行逻辑回归建模来解决分类问题,数据集为sklearn自带的乳腺癌数据集breast_cancer,数据集详情大致如下:
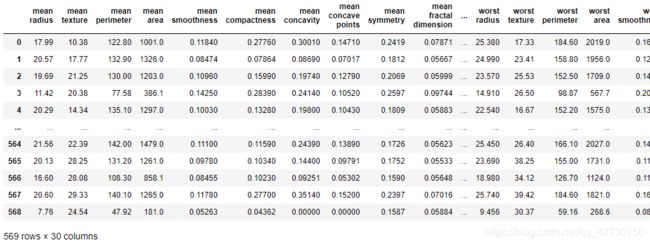


该数据集有30个特征,2个类别,详情可打印
irisdata.DESCR
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
breast = load_breast_cancer()
# penalty: 正则化选项, 默认L2
# C: 控制系数, 默认1.0
# solver: 求解最优模型参数的方法, 默认liblinear, 用于小数据集或简单二分类
# 大数据集可以选择SAG或SAGA
# max_iter: 最大迭代次数
model1 = LogisticRegression(penalty='l1', C=0.5, solver='liblinear', max_iter=1000)
model2 = LogisticRegression(penalty='l2', C=0.5, solver='liblinear', max_iter=1000)
model1.fit(breast.data, breast.target)
model2.fit(breast.data, breast.target)
print('model1: ', model1.coef_)
print('model2: ', model2.coef_)

由上也可以看出, L 1 L1 L1正则化越强,参数向量中就含有越多为0的参数,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。相对的, L 2 L2 L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0。
下面对比一下系数 C C C对 L 1 L1 L1正则化和 L 2 L2 L2正则化的影响:
x_train, x_test, y_train, y_test = train_test_split(breast.data, breast.target,test_size=0.3,random_state=128)
l1 = []
l2 = []
l1_test = []
l2_test = []
for i in np.linspace(0.05, 1.0, 20):
model1 = LogisticRegression(penalty='l1', C=i, solver='liblinear', max_iter=1000)
model2 = LogisticRegression(penalty='l2', C=i, solver='liblinear', max_iter=1000)
model1.fit(breast.data, breast.target)
model2.fit(breast.data, breast.target)
l1.append(accuracy_score(y_true=y_train, y_pred=model1.predict(x_train)))
l2.append(accuracy_score(y_true=y_train, y_pred=model2.predict(x_train)))
l1_test.append(accuracy_score(y_true=y_test, y_pred=model1.predict(x_test)))
l2_test.append(accuracy_score(y_true=y_test, y_pred=model2.predict(x_test)))
plt.figure(figsize=(6, 6))
plt.plot(np.linspace(0.05, 1.0, 20), l1, c="green", label='L1')
plt.plot(np.linspace(0.05, 1.0, 20), l2, c="blue", label='L2')
plt.plot(np.linspace(0.05, 1.0, 20), l1_test, c="red", label='L1_test')
plt.plot(np.linspace(0.05, 1.0, 20), l2_test, c="gray", label='L2_test')
plt.legend(loc='lower right')
plt.show()
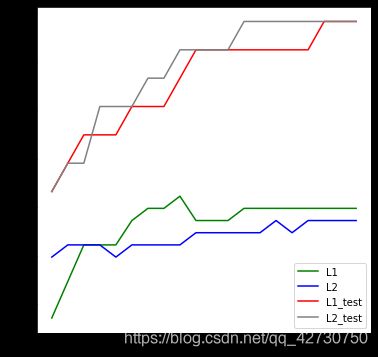
有关
LogisticRegression的详细参数说明可参考官方手册。
结束语
持续充电中,博客内容也在不断更新补充中,如有错误,欢迎来私戳小编哦!共同进步,感谢Thanks♪(・ω・)ノ
