DDD-事件总线实现架构原理分析(修订版)
@大鹏开源:别看我有点萌,我可以秒变大鹏

事件总线(EventBus),设计初衷是解耦系统模块,将系统中的各类业务操作抽象为事件模型,我们把产生事件的部分称之为事件的发送者(Publisher),消费事件的部分称之为订阅者(Subcriber)。
DDD领域事件架构简析
领域事件是领域驱动设计(Domain Driven Design)中的一个概念,它用来表示领域中发生的事件,目的是捕获我们所建模的领域中所发生过的各类事件,
领域事件忽略不相关的领域活动,明确业务需求,使得业务开发者只关注和跟踪有业务需要的事件或希望被通知的事件。
结合领域事件和EventBus,我们来看一下基于Today中台架构的EventBus架构模型:
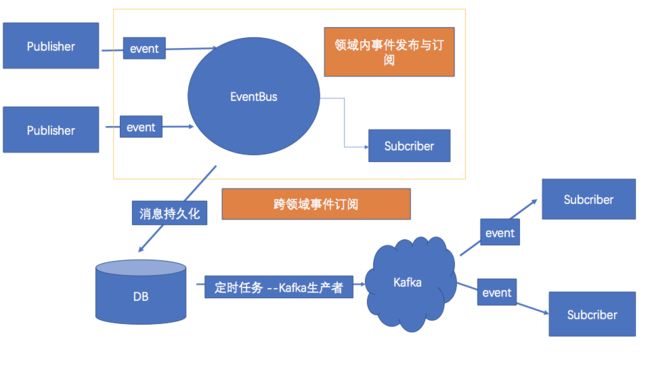
领域事件产生,然后会有监听者进行事件监听。在如此众多的事件中,需要一个消息总线对消息进行统一的管理。
消息总线的作用有:
1.一个大的领域内的各小模块之间的事件的触发和订阅
2.跨领域(跨JVM进程)之间的事件订阅
首先领域内某个方法发布事件,例如registerUser()方法执行成功后,会发布一个用户创建的事件。
这时候,我们只需要调用EventBus.fireEvent()方法,就会将事件发布出去,在EventBus内部,如果本领域内有订阅者订阅此事件,Eventbus就会匹配消息的类型,然后进行相应事件的逻辑处理,这样就做到了领域内的事件监听和处理。
在这种情况下,事件的发布和订阅是强一致性的,两者在同一个处理过程中,当出现错误,触发事件方和订阅方的数据会一起回滚。
不管是领域内事件还是跨领域事件,在EventBus触发事件之后,都会选择将消息持久化到业务数据库。
def fireEvent(event: Any): Unit = {
// 本地事件分发处理
dispatchEvent(event)
//持久化事件
persistenceEvent(event)
}
Kafka事件消息保障
我们的事件总线发布的跨领域(系统)消息,是通过kafka这款消息中间件来进行存储转发的。因为每一条事件消息对业务系统都十分重要,我们要确保发送消息不可丢,并最终能够被订阅者订阅到。
kafka对消息发送的保障
Kafka的语义是很直接的,我们有一个概念,当发布一条消息时,该消息给kafka broker收到后并 committed到了日志,那么在broker看来, 这个消息已经发布成功了, 同时会有一个ack消息返回给生产者。
当网络不可靠时, 我们会碰到这样一种情形:
生产者发送消息时,发生网络错误,这时将无法确保错误发生在broker收到消息前还是在收到消息后(返回ack丢失)。
所以, Kafka给我们提供了三种语义:
At most once
最多一次:消息可能丢失,但绝不会重发。At least once
至少一次:消息绝不会丢失,但有可能重新发送。
- Exactly once
正好一次:这是我们真正想要的,每个消息传递一次且仅一次。
这里我们结合上述三种语义并以发送端(生产者)和接收端(消费者)对消息消费语义的保障分别进行探讨。可分解成两个问题:发送消息时的持久性保障和消费消息的保障。
生产者端:
最多一次:
就是在创建生产者时,将消息发送重试次数配置为0,如下:
properties.put(retries, 0);
当消息发送失败时,不会再尝试进行消息发送,这样虽然保证了消息不会重复发送的问题,代价却是有可能会丢失消息,这是系统不能容忍的。
至少一次:
创建生产者时,配置重试次数大于等于1,如下配置就是重试2次,如果生产者连续发送消息成功而没有收到ack,就会重试两次。
properties.put(retries, 2);
正好一次
在新版本的kafka特性中,增加了kafka发送消息的幂等性配置和事务消息
properties.put(enable.idempotence, "true");
这样kafka在至少一次语义的基础上可以保证重复发送的消息不会导致日志重复,完美做到了发送端正好一次。
它的原理就是kafka-broker为每一个生产者分配了一个PID,以便区分不同的生产者实例,当然这个PID对用户不透明,用户无需进行配置。
开启了消息幂等后,producer在发送每条消息时,都会带上一个序列号(sequnceId),这样可以在重复发送时根据序列号进行去重。
如果我们也会考虑这样一种情况,当业务系统需要进行批量消息发送时,如果中途某条消息发送失败后,需要之前发送成功的消息一起回滚,类似于数据库上的事务回滚。在kafka新版本中完美支持了事务消息。
生产者配置:
properties.put("transactional.id","GOODS_1213");
properties.put("enable.idempotence", "true");
- 首先kafka对事务消息的支持前提是,需要为每个生产者实例显式的配置唯一的事务id号(如上配置),
- 其次需要将kafka消息幂等功能设置为true
通过这样的配置之后,消息在批量进行发送时,如果出现异常时,放弃当前事务即可。
我们实现的eventbus事务发送端代码如下:
创建事务生产者:
private def initTransProducer(transId: String): Unit = {
val builder = KafkaConfigBuilder.defaultProducer
val properties = builder
.withKeySerializer(classOf[LongSerializer])
.withValueSerializer(classOf[ByteArraySerializer])
.bootstrapServers(serverHost)
.withTransactions(transId)
.withIdempotence("true") //幂等性保证
.build
producer = new KafkaProducer[Long, Array[Byte]](properties)
//初始化事务
producer.initTransactions()
}
批量发送的事务保障
def batchSend(topic: String, eventMessage: util.List[EventStore]): Unit = {
try {
producer.beginTransaction()
eventMessage.forEach((eventStore: EventStore) => {
producer.send(new ProducerRecord[Long, Array[Byte]](topic, eventStore.id, eventStore.eventBinary), (metadata: RecordMetadata, exception: Exception) => {
logger.info(
s"""in transaction per msg ,send message to broker successful,
id: ${eventStore.id}, topic: ${metadata.topic}, offset: ${metadata.offset}, partition: ${metadata.partition}""")
})
})
//没有异常,提交事务
producer.commitTransaction()
} catch {
case e: Exception =>
//回滚事务
producer.abortTransaction()
logger.error(e.getMessage, e)
logger.error("send message failed,topic: {}", topic)
throw e
}
}
当然,为了配合事务消息,消费端需要在创建kafka消费者实例时,配置消息获取的隔离级别为,read_committed(读取已经提交的消息)
properties.put("isolation.level", "read_committed");
这样就可以完成事务消息的发送,既可以保障事务消息的发送,又能保障幂等性,在消息发送端不考虑非常极端的情况下,是已经做到了正好一次的语义,考虑极端情况下,也可以做到至少一次。
下面我们来看eventbus消息生产端的处理逻辑
业务系统触发事件之后,会将事件存储在数据库中,然后会有一个定时任务线程定时去轮询数据库获取消息,并使用kafka将消息发送到broker。
设计目的
使用数据库的事务来保障业务服务接口产生的事件跟业务行为保持强一致性,而在定时发送消息时,也会使用数据库事务+kafka的事务,将消息发送出去:
看下面这段发送消息的逻辑:
def doPublishMessages(): Unit = {
// 消息总条数计数器
val counter = new AtomicInteger(0)
// 批量处理, 每次从数据库取出消息的最大数量(window)
val window = 100
// 单轮处理的消息计数器, 用于控制循环退出.
val resultSetCounter = new AtomicInteger(window)
//当一次轮询拿到的消息达到了最大数时,会再次轮询数据库,以确保还有消息没有被发送
while (resultSetCounter.get() == window) {
resultSetCounter.set(0)
//数据库事务开启
dataSource.withTransaction[Unit](conn => {
//AAA
conn.eachRow[EventStore](sql"SELECT * FROM common_event limit ${window} FOR UPDATE")(event => {
conn.executeUpdate(sql"DELETE FROM common_event WHERE id = ${event.id}")
//Kafka事务确保send失败会回滚并抛异常
producer.send(topic, event.id, event.eventBinary)
resultSetCounter.incrementAndGet()
counter.incrementAndGet()
//AAA
})
})
}
}
看上面AAA块的代码,我们将消息获取和kafka生产者发送消息放到了一个事务里,首先获取到消息,然后删除当前消息,再将消息发送到kafka上,保障消息刚好一次的发送。
如果这时候出现异常(kafka发送数据异常或者删除数据库记录异常),事务就会回滚,消息没有被真正删除,下一次轮询会再次执行这个过程。
不考虑极端的情况下,这样的做法可以保证正好一次的消息发送。
考虑极端情况,即消息的删除和kafka发送都成功了,而在事务提交那行代码时,出现异常。这时候,数据库会回滚,但是消息已经被发送到了kafka上,因此这里还是会出现消息的重复发送,但是做到了至少一次, 而且这种情况是极其极端的。
发送端总结:
我们已经在不考虑极端的情况下(服务器宕机)做到了正好一次,考虑极端的情况下,做到了至少一次。
然而,极端情况还是有可能会出现,因此最好的解决方案是,我们还会在事件消息上面标记一个事件唯一ID,以支持用户在业务系统上消费消息的时候做幂等处理。
如下是一个标准的业务事件的定义。(详情参考杨权文章)
case class PublishedSkuEvent(
//事件唯一id
id : Long,
//事件中携带的具体业务
skuIds : List[Long]
)
当然并不是所有的情况都需要这么强力的保障,比如对重复消息不是很敏感的情况,我们不需要做到消息幂等性和事务消息,只需要做到消息不会丢失即可。
对于延迟敏感的,我们允许生产者指定它想要的耐用性水平。如生产者可以指定它获取需等待10毫秒量级上的响应。生产者也可以指定异步发送,或只等待leader(不需要副本的响应)有响应,
eventbus消费端
消费端分为领域内事件消费和跨领域事件消费,领域内由于在同一个事务内,强一致性,实现简单,我们这里不再赘述。现在,我们来分析下如何做到跨领域消息订阅和接收。
消息的编解码
前文没有提到的一点,我们将事件定义为thrift结构体,并将其序列化为字节流之后持久化到数据库中,kafka发送的时候, 消息内容是序列化之后的二进制byte数组,消费端在接收到消息时,需要进行反序列化和解码后,才能得到消息对象。
因此我们设计的api如下:
@KafkaConsumer(groupId = "TEST01", topic ="GOODS")
public class EventConsumer {
//定义消息的解码器
@KafkaListener(serializer = GoodsCreatedEventSerializer.class)
public void onGoodsCreatedEvent(GoodsCreatedEvent event) {
// dosomething
}
@KafkaListener(serializer = GoodsRegisteredEventSerializer.class)
public void onGoodsRegisteredEvent(GoodsRegisteredEvent event) {
// dosomething
}
}
@KafkaConsumer(groupId = "TEST01", topic ="SUPPLIER")
public class EventConsumer {
@KafkaListener(serializer = SupplierCreatedEventSerializer.class)
public void onSupplierCreatedEvent(SupplierCreatedEvent event) {
// dosomething
}
}
@KafkaConsumer标于监听类上,定义消费者组和关心的topic
@KafkaListener标于监听方法上,定义该方法监听的消息类型所需要的序列化器的class。
实现原理
- 业务系统需要把如上两个消息监听类交给Spring进行管理。
- 在启动容器时,eventbus类库里的
MsgAnnotationBeanPostProcessor会对spring管理的bean进行扫描,如果发现有bean类上面有@KafkaConsumer注解时,就会将进一步判断该类下面是否有标有@KafkaListener的方法,代码如下(只显示主要逻辑)
/**
* 实例化及依赖注入完成后、在任何初始化代码(比如配置文件中的init-method)调用之后调用
*/
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class targetClass = AopUtils.getTargetClass(bean);
//获取类上是否有注解 @KafkaConsumer
Optional kafkaConsumer = findListenerAnnotations(targetClass);
//类上是否有注解
final boolean hasKafkaConsumer = kafkaConsumer.isPresent();
if (hasKafkaConsumer) {
//方法列表 ,查找方法上标有 @KafkaListener 的注解
Map> annotatedMethods = MethodIntrospector.selectMethods(targetClass,
(MethodIntrospector.MetadataLookup>) method -> {
Set listenerMethods = findListenerAnnotations(method);
return (!listenerMethods.isEmpty() ? listenerMethods : null);
});
if (annotatedMethods.isEmpty()) {
// throw Exception
}
if (!annotatedMethods.isEmpty()) {
// Non-empty set of methods
for (Map.Entry> entry : annotatedMethods.entrySet()) {
Method method = entry.getKey();
for (KafkaListener listener : entry.getValue()) {
// process annotation information
processKafkaListener(kafkaConsumer.get(), listener, method, bean, beanName);
}
}
logger.info("there are {} methods have @KafkaListener on This bean ", binlogMethods.size());
}
} else {
this.logger.info("No @KafkaConsumer annotations found on bean type: " + bean.getClass());
}
return bean;
}
- 如果当前bean有
@KafkaConsumer注解和@KafkaListener注解,就会创建当前consumer上下文,保存该类的groupId,topic,serializer等信息,并将这些信息注册到KafkaListenerRegistrar上面,KafkaListenerRegistrar会以groupId和topic联合作为key,并创建一个kafkaConsumer实例,放入一个实例列表中,相同的groupId和topic会使用同一个kafkaConsumer实例。代码如下:
public class KafkaListenerRegistrar implements InitializingBean {
//kafkaConsumer实例列表
public static final Map EVENT_CONSUMERS = new HashMap<>();
//注册业务consumer
public void registerEndpoint(ConsumerEndpoint endpoint) {
Assert.notNull(endpoint, "Endpoint must be set");
synchronized (this) {
addConsumer(endpoint);
}
}
//添加consumer到列表,根据key判断
public void addConsumer(ConsumerEndpoint endpoint) {
String groupId = endpoint.getGroupId();
String topic = endpoint.getTopic();
String kafkaHost = endpoint.getKafkaHost();
try {
// 默认 group id
String className = endpoint.getBean().getClass().getName();
groupId = "".equals(groupId) ? className : groupId;
String consumerKey = groupId + ":" + topic;
//判断key
if (EVENT_CONSUMERS.containsKey(consumerKey)) {
EVENT_CONSUMERS.get(consumerKey).addConsumer(endpoint);
} else {
MsgKafkaConsumer consumer = new MsgKafkaConsumer(kafkaHost, groupId, topic);
consumer.addConsumer(endpoint);
EVENT_CONSUMERS.put(consumerKey, consumer);
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
//当所有bean被扫描完后,会调用此方法,启动kafkaConsumer实例
@Override
public void afterPropertiesSet() {
logger.info("ready to start consumer ,event consumer size {}, binlog consumer size {}", EVENT_CONSUMERS.size(), BINLOG_CONSUMERS.size());
EVENT_CONSUMERS.values().forEach(Thread::start);
BINLOG_CONSUMERS.values().forEach(Thread::start);
}
}
- 在上面代码中,创建的实例MsgKafkaConsumer处理消息接收和解码的逻辑,并将解码后生产的具体事件内容作为参数,通过反射调用关注了该topic的方法,主要逻辑如下:
public void run() {
logger.info("[KafkaConsumer][{}][run] ", this.groupId + ":" + this.topic);
this.consumer.subscribe(Arrays.asList(this.topic));
while (true) {
try {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
logger.info("receive message,ready to process, topic: {} ,partition: {} ,offset: {}",
record.topic(), record.partition(), record.offset());
for (ConsumerEndpoint consumer : bizConsumers) {
dealMessage(consumer, record.value());
}
}
try {
consumer.commitSync();
} catch (CommitFailedException e) {
logger.error("commit failed", e);
}
} catch (Exception e) {
logger.error("[KafkaConsumer][{}][run] " + e.getMessage(), groupId + ":" + topic, e);
}
}
}
// 收到消息后具体处理
protected void dealMessage(ConsumerEndpoint consumer, byte[] message) {
logger.info("Iterator and process biz message groupId: {}, topic: {}", groupId, topic);
KafkaMessageProcessor processor = new KafkaMessageProcessor();
String eventType = processor.getEventType(message);
List> parameterTypes = consumer.getParameterTypes();
long count = parameterTypes.stream()
.filter(param -> param.getName().equals(eventType))
.count();
if (count > 0) {
byte[] eventBinary = processor.getEventBinary();
try {
Object event = processor.decodeMessage(eventBinary, consumer.getEventSerializer());
consumer.getMethod().invoke(consumer.getBean(), event);
logger.info("invoke message end ,bean: {}, method: {}", consumer.getBean(), consumer.getMethod());
} catch (IllegalAccessException | InvocationTargetException | IllegalArgumentException e) {
logger.error("参数不合法,当前方法虽然订阅此topic,但是不接收当前事件:" + eventType, e);
} catch (TException e) {
logger.error(e.getMessage(), e);
logger.error("反序列化事件" + eventType + "出错");
} catch (InstantiationException e) {
logger.error(e.getMessage(), e);
logger.error("实例化事件" + eventType + "对应的编解码器失败");
}
} else {
logger.debug("方法 [ {} ] 不接收当前收到的消息类型 {} ", consumer.getMethod(), eventType);
}
}
消费者设置为手动提交偏移量,在一次poll请求中,当消息成功消费后,会批量提交偏移量,并且是同步的。
因此,如果因为消息消费时,在未提交偏移量之前,消息是不会丢失的(未处理),但是当消息消费后,准备提交偏移量是系统出错了,这时候会导致重复消费,因此也是至少一次的语义。
所以这里交给业务系统时,还是需要业务去实现业务去重。
注意
即使两个订阅者方法都订阅了同一个topic,kafka消费者仍然会根据接收到的消息的类型和订阅者方法的所感兴趣的事件类型进行对比,如果当前接收到的事件与订阅事件一致,便会通过反射调用订阅者方法,并将收到的具体事件也传递过去,事件接收成功。
举个例子:
如果kafkaConsumer从broker接收到消息,解码之后发现事件类型为UserCreated,那他只会notify接收参数为UserCreated事件的方法,而不会去调用接收UserRegisted的订阅者方法。
总结
DDD领域事件的消息总线分析就到这里,本文重点讲了跨领域时,通过kafka消息中间件如何做到消息的稳定发送和接收,不出现消息丢失,触发事件而未发送等情况。