Python进阶7——字典与集合
1.创建字典的五种方式
d1=dict(one=1, two=2)
d2={'one':1, 'two':2}
d3=dict(zip(['one', 'two'], [1,2]))
d4=dict([('two', 2), ('one', 1)])
d5=dict({'one':1, 'two':2})
print(d1==d2==d3==d4==d5)
其中,四种是通过dict函数创建字典,d3中的zip函数的作用是将列表中的元素按照索引值对应打包成元组,并返回对应的迭代器
print(zip(['one', 'two'], [1,2]))
print(tuple(zip(['one', 'two'], [1,2])))
print(list(zip(['one', 'two'], [1,2])))
print(dict(zip(['one', 'two'], [1,2])))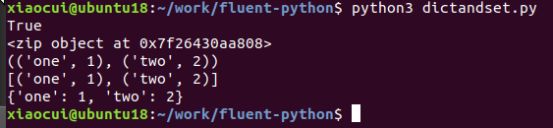
2.字典解析式
字典解析式和列表解析式类似
nums=['one', 'two', 'three', 'four', 'five']
vals=[val for val in range(1,6)]
zipped=list(zip(nums, vals))
numlist={num:val for num, val in zipped}
print(numlist)
numlistpart={num:val for num, val in numlist.items() if val > 3}
print(numlistpart)
3.找不到key时,该怎么做
上述的numlist中只存取了1到5的键值对,如果查找key为six的值时,默认情况下,会抛出异常
print(numlist['five'])
print(numlist['six'])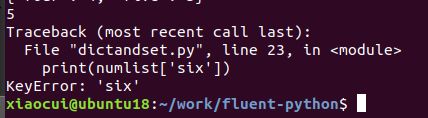
如果不想抛出异常,可以使用dict中的成员函数setdefault来实现
numlist.setdefault('six', []).append('no six')
print(numlist['six'])
print(numlist)
setdefault函数返回的是一个空的列表,可以向列表中添加元素。执行完setdefault后,对应的key value被自动添加到字典中
除了setdefault成员函数,还可以使用defaultdict来避免keyerror异常
import collections as col#defaultdict在collections模块中
nums=['one', 'two', 'three', 'four', 'five']
vals=[val for val in range(1,6)]
zipped=list(zip(nums, vals))#打包元素,返回元组列表
dd=col.defaultdict(list)#创建一个defaultdict,dd的value是列表
for k, v in zipped:
dd[k].append(v);#给dd赋值
print(dd)
print(dd['six'])#打印一个不存在的键,返回空列表
没有出现keyerror,defaultdict中的参数表明了value值的类型,如果传入的是其他类型,value的类型也发生变化
当把参数改为int后的输出结果如下:

4.特殊的魔术方法__missing__
字典访问一个不存在的键并且不抛出异常的原因就是因为魔术方法__missing__,当执行d[k]操作时,会调用__getitem__魔术方法,当找不到对应的key时,会调用魔术方法__missing__,在该方法中捕获异常并返回默认值
举例:定义一个能将字符串key转为int类型key的字典
class strkeydict(dict):
def __missing__(self, key):
print('__missing__')
if isinstance(key, int):#如果执行了__missing__并且key的类型是int,说明key不存在,抛出异常
raise KeyError(key)
return self[int(key)]#否则将其他类型的key转为int再次尝试查找
def get(self, key, default=None):
print('get')
try:
return self[key]
except KeyError:
return default;
def __contains__(self, key):
print('__contains__')
return key in self.keys() or int(key) in self.keys()
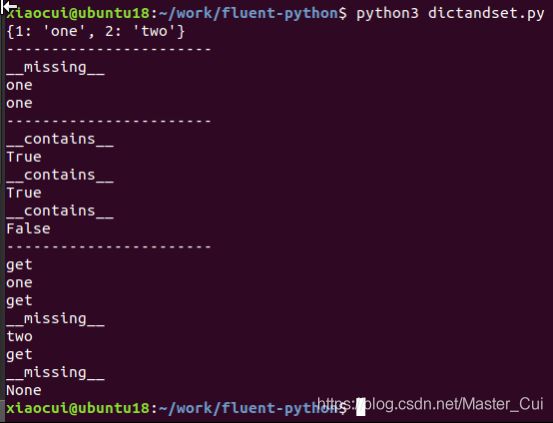
strkd=strkeydict([(1,'one'), (2, 'two')])#因为继承
print(strkd)
print('-----------------------')
print(strkd['1'])#无法找到key为'1'对应的值,调用__missing__,然后执行return self[int(key)]
print(strkd[1])#直接调用__getitem__
print('-----------------------')
print(2 in strkd)
print('1' in strkd)
print(3 in strkd)#strkd中无key为3
print('-----------------------')
print(strkd.get(1))
print(strkd.get('2'))#无法找到key为'2'对应的值,先调用__missing__,然后执行return self[int(key)]
print(strkd.get(3))#无法找到key为3对应的值,触发__missing__调用,抛出KeyError异常,然后由get函数捕获异常,返回None
上述代码和核心就是当执行self[k]的操作时,会调用__getitem__, 如果不成功,再继续调用__missing__
此外__missing__中的isinstance判断必不可少,如果没有该判断,会产生无限递归,因为return self[int(key)]如果失效,会再一次调用__missing__,然后再return self[int(key)]
def __missing__(self, key):
print('__missing__')
# if isinstance(key, int):
# raise KeyError(key)
return self[int(key)]
print(strkd[3])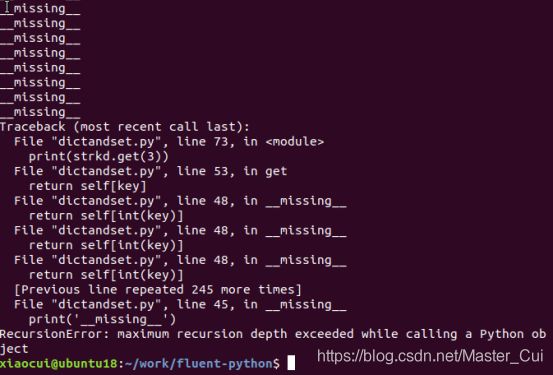
上述代码还可以换一种写法
import collections as col
class strkeydict1(col.UserDict):
def __missing__(self, key):
print('__missing__')
if isinstance(key, int):
raise KeyError(key)
return self[int(key)]
def __contains__(self, key):
print('__contains__')
return int(key) in self.data
def __setitem__(self, key, item):
print('__setitem__')
self.data[key]=item
def get(self, key, default=None):
print('get')
try:
return self[key]
except KeyError:
return default
strkd=strkeydict1([(1,'one'), (2, 'two')])
print(strkd)
print('-----------------------')
print(strkd['1'])
print(strkd[1])
print('-----------------------')
print(2 in strkd)
print('1' in strkd)
print(3 in strkd)
print('-----------------------')
print(strkd.get(1))
print(strkd.get('2'))
print(strkd.get(3))
print('-----------------------')
strkd[3]='three'
print(strkd)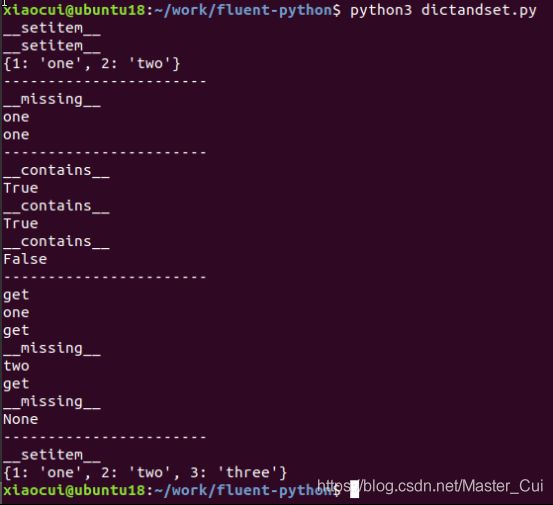
主要的变化就是继承了collections.UserDict,好处是可以直接访问存储字典实例的属性data,简化了__contains__的实现,也更方便的实现了__setitem__,核心思想仍然不变
5.字典视图MappingProxyType
字典视图MappingProxyType位于types模块中,能够动态的监视绑定字典的变化,只读不可写
import types as t
d=dict({1:'one',2:'two'})
dview=t.MappingProxyType(d)#绑定字典d,可以随时查看d的数据
print(dview, d)
d[3]='three'
print(dview, d)
6.集合
集合的本质是一堆无重复的数据(也是用{}表示,只不过没有键值对),所以可以用来去重(字典中重复的键值只会保留最后面的)
d=dict({1:'one',2:'two', 1:'six'})
s={1,1,2,3,4,5,5}
print(s,d)
交集,并集,补集
s1=set([x for x in range(0,6)])
s2=set([x for x in range(1,7)])
print(s1, s2)
print(s1&s2, s1|s2, s1-s2, s2-s1)
print(len(s1&s2))
&表示交集,|表示并集,用减号表示补集,求取交集之后,可以用len函数计算集合交集的个数。用来检查某个集合在另一个集合中出现了多少次
由于&只能用于集合,如果想对两个列表或元组求公共部分,需要先用set函数转化为集合,再使用&
l1=(x for x in range(0,6))
l2=(x for x in range(1,7))
print(set(l1)&set(l2))![]()
空集合与空字典
集合与字典都用大括号{}表示,如果只写了一个{},表示的是空字典而不是空集合
d={}
s=set()
print(type(d), type(s))
空集合用set()表示,空字典用{}表示
集合推导与字典推导和列表解析式类似
s={x for x in range(0,10)}
print(s)
参考:
《流畅的Python》
欢迎大家评论交流,作者水平有限,如有错误,欢迎指出