#多项式朴素贝叶斯
from sklearn.preprocessing import MinMaxScaler
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.metrics import brier_score_loss
#建立数据集
class_1=500
class_2=500
centers=[[0.0,0.0],[2.0,2.0]]
clusters_std=[0.5,0.5]#设定两个类别的方差
X,y=make_blobs(n_samples=[class_1,class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0,
shuffle=False)
Xtrain,Xtest,ytrain,ytest=train_test_split(X,y,test_size=0.3,random_state=420)
#先要进行归一化,防止导入的数据含有负值
mms=MinMaxScaler().fit(Xtrain)#对训练集和测试集都要进行归一化,但是发现了没有
Xtrain_=mms.transform(Xtrain)
Xtest_=mms.transform(Xtest)#对测试集归一化仍然用的是训练集fit的mms
mnb=MultinomialNB().fit(Xtrain_,ytrain)
mnb.class_log_prior_
#重要属性:调用根据数据获取的,每个标签类的对数先验概率log(P(Y))
#由于概率永远是在[0,1]之间,因此对数先验概率返回的永远是负值
#重要属性:调用根据数据获取的,每个标签类的对数先验概率log(P(Y))
mnb.class_log_prior_
np.exp(mnb.class_log_prior_)#使用exp来查看真正的概率
mnb.feature_log_prob_
#返回的是一个固定标签类别下每个特征的对数概率
#重要属性:返回一个固定标签类别下的每个特征的对数概率log(P(Xi|y))
mnb.class_count_mnb.predict_proba(Xtest_)#返回的时每个样本在每个标签取值下的概率
#重要属性,在fit时每个标签类别下包含的样本数
#当fit接口中的sample_weight 被设置时,该接口返回的值也会收到
#加权的影响,0类别下有351个样本,1类别下有349个样本
#一些传统的接口
mnb.predict(Xtest_)
mnb.predict_proba(Xtest_)#返回的时每个样本在每个标签取值下的概率
mnb.score(Xtest_,ytest)#返回的时准确率
brier_score_loss(ytest,mnb.predict_proba(Xtest)[:,1],pos_label=1)
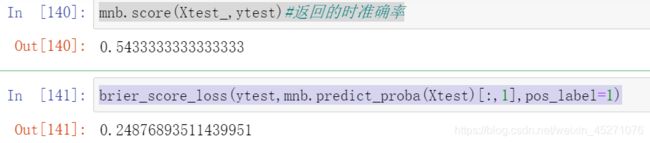
#效果不太好,多项式更擅长分类型数据,归一化之后成为了连续型数据
#所以可以进行分箱,转换为分类型数据
from sklearn.preprocessing import KBinsDiscretizer
kbs=KBinsDiscretizer(n_bins=10,encode="onehot").fit(Xtrain)
Xtrain_=kbs.transform(Xtrain)
Xtest_=kbs.transform(Xtest)
#没有进行归一化时因为分箱后都是0和1
mnb=MultinomialNB().fit(Xtrain_,ytrain)
mnb.score(Xtest_,ytest)
