【文献阅读】MMQA——基于图像、文本和表格的问答(Alon Talmor等人,ICLR,2021)
一、背景
文章题目:《MultiModalQA: Complex Question Answering Over Text, Tables and Images》
文章下载地址:https://arxiv.org/pdf/2104.06039.pdf
文章引用格式:Alon Talmor, Ori Yoran, Amnon Catav, Dan Lahav, Yizhong Wang, Akari Asai, Gabriel Ilharco, Hannaneh Hajishirzi and Jonathan Berant. "MultiModalQA: Complex Question Answering Over Text, Tables and Images." In The International Conference on Learning Representations (ICLR), 2021
项目地址:https://allenai.github.io/multimodalqa. (这个是数据集的下载地址)
二、文章摘要
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA (MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1 of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1.
当人类回答一个复杂的问题的时候,能够很容易的结合视觉,文本和表格信息。近些年来人们对推理多重证据的模型具有兴趣,但对于需要跨模态推理的问答模型的成果较少。这篇文章提出了MMQA,即一个问答数据集,它需要联合文本,表格和图像进行推理。作者使用一个新的框架来构建MMQA,该框架能够生成复杂的多模态问题,从维基百科种获取表格,对表格中出现的实体附加相应的图像和文本段落。然后,我们定义一种形式语言,允许我们回答可以从单一模态得到答案的问题,并将它们组合起来生成跨模态问题。最后,众包员工会把这些自动生成的问题用更流利的语言表达出来。一共创建了29918个问题。最后作者的跨模态模型ImplicitDecomp,在跨模态问题上获得了51.7的F1分数,这比当前最好的模型的38.2的F1得分要好很多,但与人类90.1的F1得分仍有很大差距。
三、文章介绍
目前,在多模态证据中推理的问答模型引起了广泛关注。在此前的相关工作中,只有很少的工作是需要跨模态整合信息的。最近提出的一个数据集ManyModalQA,每个问题的信息都是来自多个模态,但是回答这个问题只需要一个模态的信息即可,并且不需要跨模态的信息推理。因此这项工作的重心是寻找相关模态。近期还有一个HybridQA数据集,它需要表格和文本数据来推理,它需要跨模态来推理,但是并没有涉及到视觉信息。本文提出的数据集和这两个数据集的比较结果如下:

本文提出了一个MMQA数据集,是第一个需要整合跨模态信息的QA数据集,其中35.7%的问题需要进行跨模态推理。一些示例如下图所示:

从上面的Ben Piazza表格中,哪一个电影更早一些:是Sage Stallone儿子开始参与的电影还是海报上有半边人脸的电影?这里需要涉及到的步骤包括:i)分解这个问题为简单的问题;ii)判断每一个简单问题的对应模态并且回答;iii)整合信息来回答问题。
作者针对MMQA数据集设计的方法涉及到了步骤:(a)背景构建Context construction。表格从维基百科中获取,对应的文本和图像从Reading Comprehension (RC)数据集中查找。(b)问题生成Question generation。采用了之前工作的方法Following past work (Talmor & Berant, 2018),获得语言都是机翻(pseudo-language)的。(c)解析:众包模式,将机翻语言解析为流利的英语。
为了处理MMQA数据,作者使用了ImplicitDecomp模型。总的来说,本文的主要贡献如下:
• MMQA: a dataset with 29,918 questions and answers, 35.7% of which require cross-modal reasoning. 提出了MMQA数据集,其中35.7%的问题都需要跨模态推理
• A methodology for generating multimodal questions over text, tables and images at scale. 一种生成多模态问题的方法
• ImplicitDecomp, A model for implicitly decomposing multimodal questions, which improves on a single-hop model by 13.5 absolute F1 points on questions requiring cross-modal reasoning. 提出了ImplicitDecomp模型,不用分解多模态问题,相较于单步模型,在跨模态推理问题中提升13.5的F1分数。
• Our dataset and code are available at https://allenai.github.io/multimodalqa. 数据目前可以下载
1. 数据生成
数据集生成的过程如下图所示:

(1)Wikipedia tables as anchors:提取维基百科中的表格。
(2)Connecting Images and Text to Tables Images:图片有两种,一种是表格中的图片,另一种是WikiEntities页面中的图片。文本则是来自于reading comprehension datasets数据集中。
(3)Generating Single-Modality Questions Tables:使用范式“In [table title] of [Wikipedia page title] which cells in [column X] have the [value Y] in [column Z]?”来生成单模态问题。对于图像,采用众包模式来生成问题,问题可以是针对单张图片或者针对一系列图片。对于文本,利用现有的阅读理解数据集来生成,包括Natural Questions (NQ),BoolQ,HotpotQA,作者构建文本元组的思路是,根据问题和答案,找到阅读理解数据集中相应的段落。
(4)Generating multimodal complex questions:第一步,引入一个formal language,能将回答单模态的问题结合起来。下表就介绍了16种结合的方法:

这里进行这16种操作采用的是逻辑操作函数(Logical Operations Functions),它返回一个类似机翻(pseudo-language (PL))的问题。
(5)Paraphrasing using AMT:将机翻的问题解析为自然语言,还是众包的模式来做。这里作者提到了平均一个样本要花费0.33刀。
(6)Adding distractors to the context Images:为背景图像增加干扰项。对于single-image问题,随机的从WikiEntities中添加干扰的图像,每组最多15个干扰项。对于文本,使用信息检索模型DPR,来检索所有问题的干扰项。
2. 数据分析
数据集的分析只有三个方面key statistics, domains, and lexical richness。
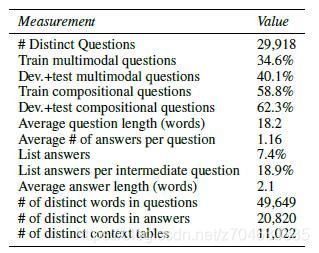
Key Statistics:问题平均长度18.2个单词,答案平均长度2.1个单词,一些统计结果如下图所示:
Domain Diversity:多样性如下图:
Lexical Richness:NL questions的平均长度20.02,PL questions的平均长度22.16。唯一性单词前者包含39 319,后者包含 37 108。
3. 模型
(1)单模态QA模型
Text QA Module:这里是参考了之前的工作,即(Min et al., 2019a; Asai et al., 2020),输入问题和段落,答案在段落中,预测答案的起始位置和最终位置。
Table QA Module:参考(Herzig et al., 2020)的工作,输入问题和图表,选择图表的部分来整合操作,计算答案。
Image QA Module:使用multimodal transformer来处理。对于输入的一个问题和一系列图像来说,分别提取问题和所有图像的特征,然后对于每一个问题和特征,都对其预测相应的答案。
(2)多模态QA模型
Multi-Hop Implicit Decomposition (ImplicitDecomp):数据集是为了测试跨模态推理能力的,首先基于RoBERTa-large来训练question-type classifier,这里先输入一个问题,然后预测16种可能的问题类型,这个问题类型可以明确对应的模态,还有logical operations。然后将这一步得到的答案作为输入,模型就可以使用这个信息来进行跨模态推理,得到最终答案。结构图如下所示:

Single-Hop Routing (AutoRouting):在没有跨模态推理的情况下回答问题的一种简单方法是,首先确定答案可能出现的模态,然后运行相应的单模态模块。因此使用前面提到的question type classifier,来判断答案可能出现的模态,将问题和预测模态的上下文路由到相应的模块中,并使用输出作为最终答案。
Question-only and Context-only baselines:这里使用了question-only and context-only baselines。
(3)训练和监督
训练是采用监督的模式来做的。
4. 实验
评价指标采用F1和Exact Match (EM),分别检测只需单模态回答的问题,需多模态推理回答的问题,和所有问题,结果如下表所示:

为了说明ImplicitDecomp确实能够进行推理,回答跨模态问题,作者分析了模型对使用Compose, Compare and Intersect operations操作来生成的多模态问题的预测结果,结果如下:

5. 相关工作
这里作者介绍了VQA,ManyModalQA和HybridQA.