Java SPI 机制在 Flink 中的应用(源码分析)
我们在使用 Flink SQL 的时候是否有过这样的疑问? Flink 提供了各种各样的 connector 我们只需要在 DML 里面定义即可运行,那它是怎么找到要执行的代码呢? 它是怎么知道代码对应关系的呢? 其实 Flink 是通过 Java 的 SPI(并不是Flink发明创造的) 机制来实现的,下面就来深入源码分析一下其实现过程.
什么是 SPI ?
SPI 全称(Service Provide Interface),在 JAVA 中是一个比较重要的概念,在框架设计中被广泛使用。在框架设计中,要遵循的原则是对扩展开放,对修改关闭,保证框架实现对于使用者来说是黑盒。因为框架不可能做好所有的事情,只能把共性的部分抽离出来进行流程化,然后留下一些扩展点让使用者去实现,这样不同的扩展就不用修改源代码或者对框架进行定制。也就是我们经常说的面向接口编程。
在 JDK6 里面引进的一个新的特性 ServiceLoader,从官方的文档来说,它主要是用来装载一系列的 service provider。而且ServiceLoader 可以通过 service provider 的配置文件来装载指定的 service provider。当服务的提供者,提供了服务接口的一种实现之后,我们只需要在 jar 包的 META-INF/services/ 目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该 jar 包 META-INF/services/ 里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。综上所述,SPI 机制实际上就是 "基于接口的编程+策略模式+配置文件" 组合实现的一种动态加载机制,在 JDK 中提供了工具类:java.util.ServiceLoader 来实现服务查找。
实现 SPI 机制,要遵循下面的一些规范:
服务提供者提供了接口的具体实现后,需要在资源文件夹中创建 META-INF/services 文件夹,并且新建一个以全类名为名字的文本文件,文件内容为实现类的全名(如下面图中的红框);
接口实现类必须在工程的 classpath 下,也就是 maven 中需要加入依赖或者 jar 包引用到工程里.
其实 Java 里使用 SPI 还是比较多的,比如我们常用的 JDBC 连接 Mysql 就是用的 SPI 机制来实现的连接逻辑,下面来看一个简单的 Demo.
接口服务提供
public interface Person {
void eat();
}
实现类
public class Flink implements Person {
@Override
public void eat() {
System.out.println(this.getClass().getSimpleName() + " 执行 eat 方法");
}
}
public class JasonLee implements Person {
@Override
public void eat() {
System.out.println(this.getClass().getSimpleName() + " 执行 eat 方法");
}
}
public class Spark implements Person {
@Override
public void eat() {
System.out.println(this.getClass().getSimpleName() + " 执行 eat 方法");
}
}
META-INF/services 配置文件
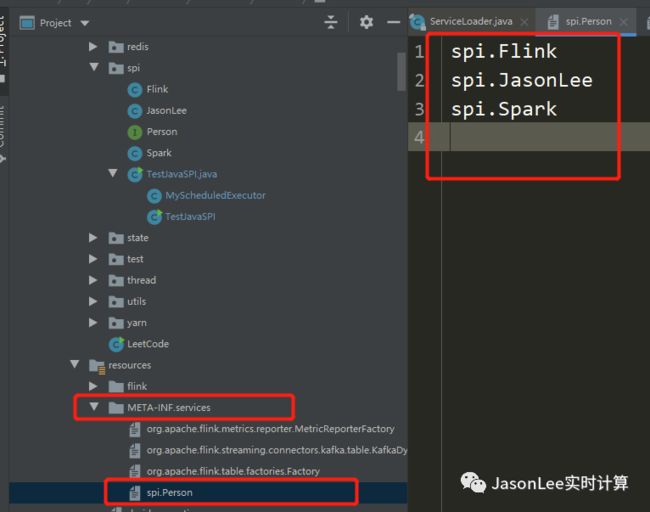
在 source 下面的 META-INF/services 文件夹下面创建 spi.Person 文件,文件的内容是上面实现类的全名(包名.类名)
测试类
public static void main(String[] args) {
ServiceLoader load = ServiceLoader.load(Person.class);
Iterator iterator = load.iterator();
while (iterator.hasNext()) {
Person next = iterator.next();
next.eat();
}
}
执行打印的结果是:
Flink 执行 eat 方法
JasonLee 执行 eat 方法
Spark 执行 eat 方法
可以看到 3 个实现类都被执行了.
然后来分析一下 ServiceLoader#load 方法的源码:
public static ServiceLoader load(Class service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
首先会获取当前线程的类加载器,然后调用另一个重载的 load 方法.
public static ServiceLoader load(Class service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
这个 load 方法会调用 ServiceLoader 的构造方法进行变量初始化.
private ServiceLoader(Class svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
构造方法里面主要是完成了对 service,loader,acc 变量的赋值工作,然后调用 reload 方法
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
providers 其实是一个 LinkedHashMap 用来做缓存用,存储的是用读取到的 services 文件夹下面实现类的实例,所以上来先清空缓存中的数据.然后创建了 LazyIterator 实例,核心的逻辑在 hasNextService 和 nextService 这两个方法中.
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// 获取实现类的全名称
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析实现类
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class c = null;
try {
// 通过反射去创建对象
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
// 对象的实例化
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
我们必须要在 source 下面创建 META-INF/services 文件夹吗 不放在这个位置难道就加载不到吗? 答案是肯定的,如果不创建确实加载不到,因为源码里面的 PREFIX = "META-INF/services/" 这个变量是写死的,所以我们必须创建这个文件夹.这里会遍历文件里面所有的实现类然后通过反射机制去创建对象.
你可能还会发现一个问题 load 方法一开始就获取了 Thread.currentThread().getContextClassLoader() 上下文的类加载器,然后一直往后面传递,最后在 forName 里面用到了,那如果不把 loader 传进来行不行? 答案是确实不行,因为 ServiceLoader 是一个基础类,它是在 java.util 这个包下面的,所以它是由 BootstrapClassLoader 来加载的.而我们自定义的实现类是由 AppClassLoader 去加载的,BootstrapClassLoader 这个类加载器是加载不到我们定义的类的,所以这里 getContextClassLoader 其实是打破了双亲委派模型的.
Flink 中 SPI 实现
在 Flink 源码中大量使用了 Java 的 SPI 机制,比如在 Flink-connector ,Flink-formats ,Flink-metrics 等模块都可以看到 SPI 的身影.比如 Json Format
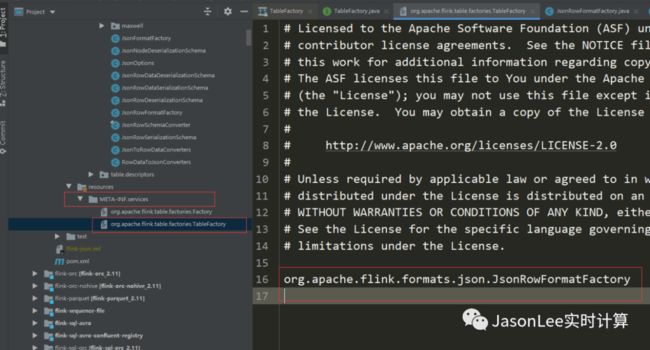
那么 Flink 是如何保证正确的 TableFactory 实现类被加载的呢?直接来看 TableFactoryService#findSingleInternal 方法的源码
private static T findSingleInternal(
Class factoryClass,
Map properties,
Optional classLoader) {
// 加载所有的实现类
List tableFactories = discoverFactories(classLoader);
// 过滤出满足条件的
List filtered = filter(tableFactories, factoryClass, properties);
if (filtered.size() > 1) {
throw new AmbiguousTableFactoryException(
filtered, factoryClass, tableFactories, properties);
} else {
return filtered.get(0);
}
}
其中 discoverFactories 方法用来发现并加载 Table 的服务提供类,filter 方法则是用来筛选出满足条件的 TableFactory 的实现类。前者最终调用了 ServiceLoader 的相关方法,如下:
private static List discoverFactories(Optional classLoader) {
try {
List result = new LinkedList<>();
ClassLoader cl = classLoader.orElse(Thread.currentThread().getContextClassLoader());
ServiceLoader.load(TableFactory.class, cl).iterator().forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for table factories.", e);
throw new TableException("Could not load service provider for table factories.", e);
}
}
可以看到 Java 的 SPI 机制就是在这里用的,查找并加载 TableFactory 所有的实现类,然后保存在 List 里面.然后在过滤中满足条件的一个.
总结:
SPI 机制的优缺点都非常明显,优点是实现解耦,使得接口的定义和具体业务实现分离,易于动态扩展,帮忙我们灵活的插件化开发.
缺点也很明显,不能按需加载,虽然 ServiceLoader 做了延迟加载,但是会把接口的实现类全部加载并实例化一遍,可能会造成浪费,获取某个实现类的方式比较单一,只能通过 iterator 形式获取,不能根据参数的形式获取.
推荐阅读
Flink SQL 如何实现列转行?
Flink SQL 结合 HiveCatalog 使用
Flink SQL 解析嵌套的 JSON 数据
Flink SQL 中动态修改 DDL 的属性
Flink WindowAssigner 源码解析
Flink 1.11.x WatermarkStrategy 不兼容问题
Flink mysql-cdc connector 源码解析

如果你觉得文章对你有帮助,麻烦点一下赞和在看吧,你的支持是我创作的最大动力.