泰坦尼克号生还者预测机器学习二分类算法+LSTM+GRU ()
源数据包
链接:https://pan.baidu.com/s/1jVqX-WUkwSWZA0J3b-DnFg
提取码:1111
复制这段内容后打开百度网盘手机App,操作更方便哦
import pandas as pd
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error # 评价指标
特征数值化
def read_dataset(data_link):
data = pd.read_csv(data_link, index_col=0) # 读取数据集,取第一列为索引
data.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True) # 删除掉三个无关紧要的特征
labels = data['Sex'].unique().tolist()
data['Sex'] = [*map(lambda x: labels.index(x), data['Sex'])] # 将字符串数值化
labels = data['Embarked'].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda n: labels.index(n)) # 将字符串数值化
data = data.fillna(0) # 将其余缺失值填充为0
return data
train = read_dataset('train.csv')
ceshi= read_dataset('test.csv')
ceshi_label=pd.read_csv("titanic.csv")数据划分
y = train['Survived'].values # 类别标签
x = train.drop(['Survived'], axis=1).values # 所有样本特征
print(y.shape)
print(x.shape)
# 对样本进行随意切割,得到训练集和验证集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)决策树算法
clf = DecisionTreeClassifier() # 先不进行调参,看训练样本和测试样本分数如何
clf.fit(x_train, y_train)
test_pred=clf.predict(x_test) # 进行预测
print("查准率:", metrics.precision_score(y_test,test_pred))
print('召回率:',metrics.recall_score(y_test,test_pred))
print('f1分数:', metrics.f1_score(y_test,test_pred)) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(ceshi_label["Survived"].values,clf.predict(ceshi.values)))
print("查准率:", metrics.precision_score(ceshi_label["Survived"].values,clf.predict(ceshi.values)))
print('召回率:',metrics.recall_score(ceshi_label["Survived"].values,clf.predict(ceshi.values)))
print('f1分数:', metrics.f1_score(ceshi_label["Survived"].values,clf.predict(ceshi.values)))
print('准确率: %.2f' % metrics.accuracy_score(ceshi_label["Survived"].values,clf.predict(ceshi.values))) 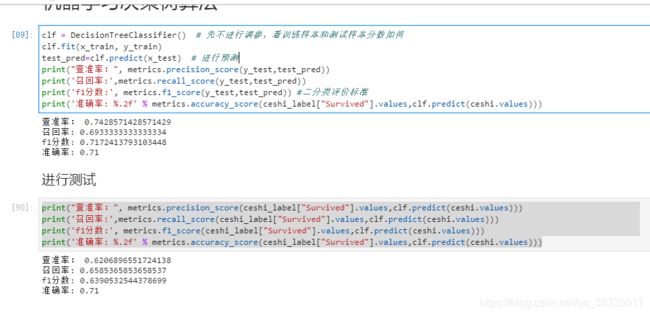
随机森林算法
forest = RandomForestClassifier(criterion='entropy',
n_estimators=10,
random_state=1,
n_jobs=-1)
forest.fit(x_train, y_train)
test_pred=forest.predict(x_test)
print('f1分数:', metrics.f1_score(y_test,test_pred)) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print('f1分数:', metrics.f1_score(ceshi_label["Survived"].values,forest.predict(ceshi.values))) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(ceshi_label["Survived"].values,forest.predict(ceshi.values))) 
KNN算法
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski',n_jobs=-1)
knn.fit(x_train, y_train)
test_pred=knn.predict(x_test) # 进行预测
print('f1分数:', metrics.f1_score(y_test,test_pred)) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print('f1分数:', metrics.f1_score(ceshi_label["Survived"].values,forest.predict(ceshi.values))) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(ceshi_label["Survived"].values,forest.predict(ceshi.values))) 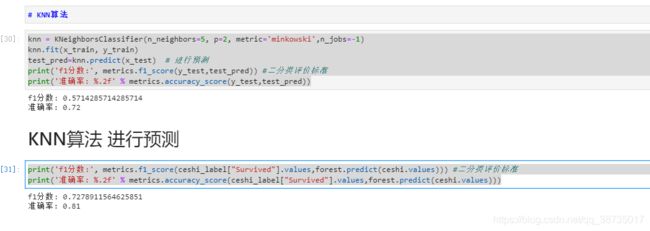
支持向量机(SVM)
svm = SVC(kernel='linear', C=100.0,gamma=100.0, random_state=0)
svm.fit(x_train, y_train)
test_pred= svm.predict(x_test)
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print("查准率:", metrics.precision_score(y_test,test_pred))
print('召回率:',metrics.recall_score(y_test,test_pred))
print('f1分数:', metrics.f1_score(y_test,test_pred)) #二分类评价标准
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print("查准率:", metrics.precision_score(ceshi_label["Survived"].values,svm.predict(ceshi.values)))
print('召回率:',metrics.recall_score(ceshi_label["Survived"].values,svm.predict(ceshi.values)))
print('f1分数:', metrics.f1_score(ceshi_label["Survived"].values,svm.predict(ceshi.values))) #二分类评价标准 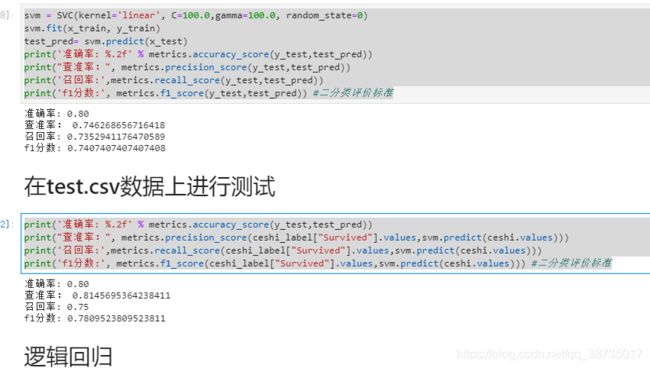
逻辑回归
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(x_train, y_train)
test_pred= lr.predict(x_test)
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print("查准率:", metrics.precision_score(y_test,test_pred))
print('召回率:',metrics.recall_score(y_test,test_pred))
print('f1分数:', metrics.f1_score(y_test,test_pred))
print('准确率: %.2f' % metrics.accuracy_score(y_test,test_pred))
print("查准率:", metrics.precision_score(ceshi_label["Survived"].values,lr.predict(ceshi.values)))
print('召回率:',metrics.recall_score(ceshi_label["Survived"].values,lr.predict(ceshi.values)))
print('f1分数:', metrics.f1_score(ceshi_label["Survived"].values,lr.predict(ceshi.values))) #二分类评价标准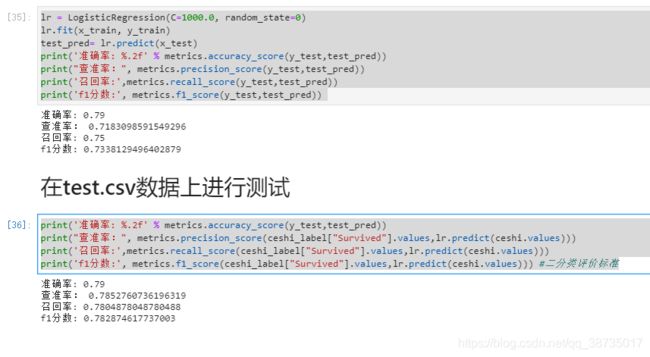
深度学习模型 lstm gru
# 导入库
import pandas as pd
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error # 评价指标
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM,GRU
from keras import optimizers
import keras
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings("ignore")#忽略一些警告 不影响运行
%matplotlib inline
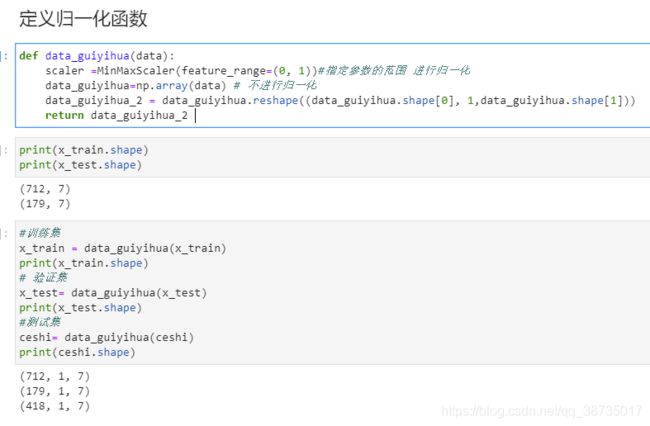
归一化函数
def data_guiyihua(data):
scaler =MinMaxScaler(feature_range=(0, 1))#指定参数的范围 进行归一化
data_guiyihua=np.array(data) # 不进行归一化
data_guiyihua_2 = data_guiyihua.reshape((data_guiyihua.shape[0], 1,data_guiyihua.shape[1]))
return data_guiyihua_2
LSTM
def create_model_1():
model = keras.models.Sequential([
keras.layers.LSTM(50,activation='relu', input_shape=(1,7)),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(1,activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=op)
return model
op = optimizers.RMSprop(lr=0.001)
model1 = create_model_1()
model1.summary()
model1.fit(x_train,y_train,validation_data=(x_test, y_test), epochs=200, batch_size=32,verbose=2, shuffle=True)
model1.save_weights('moxing')#模型保存
#validation_data:元组 (x_val,y_val) 或元组 (x_val,y_val,val_sample_weights), 用来评估损失,以及在每轮结束时的任何模型度量指标。
模型将不会在这个数据上进行训练。这个参数会覆盖 validation_split
#引用上边的模型实例
model_jiazai_1 = create_model_1()
# 加载保存好的模型
model_jiazai_1.load_weights('moxing')
y1_pred = model_jiazai_1.predict(ceshi)
y1_pred=y1_pred.reshape(1,418)[0]
# print(y1_pred)
y_pred=[]
for i in y1_pred:
if abs(i)>=0.5:
y_pred.append(1)
else:
y_pred.append(0)
# print(y_pred)gru
def create_model_2():
model = keras.models.Sequential([
keras.layers.GRU(100,activation='relu', input_shape=(1,7)),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(1,activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=op)
return model
op = optimizers.RMSprop(lr=0.005)
model2 = create_model_2()
model2.summary()
model2.fit(x_train,y_train,validation_data=(x_test, y_test), epochs=200, batch_size=32,verbose=2, shuffle=True)
model2.save_weights('moxing_GRU')#模型保存
#引用上边的模型实例
model_jiazai_2 = create_model_2()
# 加载保存好的模型
model_jiazai_2.load_weights('moxing_GRU')
y2_pred = model_jiazai_2.predict(ceshi)
y2_pred=y2_pred.reshape(1,418)[0]
# print(y1_pred)
y_pred=[]
for i in y2_pred:
if abs(i)>=0.5:
y_pred.append(1)
else:
y_pred.append(0)
# print(y_pred)