【推荐实践】阿里飞猪“猜你喜欢”推荐排序实践

导读:飞猪猜你喜欢排序模型由线性模型升级到端到端的深度模型,并进行了多个版本的迭代。本文分享模型迭代中的一些技术沉淀。
引言
俗话说有多少米,就下多大锅。在特征体系构建上,我们已经准备了很多米了,并且在线性模型 FTRL 上拿到了一些甜头。下一阶段我们换了锅,对模型进行了升级,从线性模型转为 end-to-end 的深度模型,并进行了多个版本的迭代,包括 pure deep 模型(Pure Adaptive L2 Model,PALM),引入实时点击和实时未点击行为(FeedBack-PALM,FB-PALM),引入全网序列特征(Global Local Attention-PALM,GLA),并拿到了一些收益。下面对这个阶段的技术细节进行介绍。

问题分析
固定的特征体系下精巧的模型结构也能显著发挥现有特征的潜力。end-to-end 的深度模型一方面可以隐式和显示的进行特征交叉增加特征的表达能力。另一方面可以很 flexible 的引入真实行为序列特征等复杂结构特征。但是任何事情都有两面性,end-to-end 的深度模型相较于 FTRL 虽然对特征组合要求较少,但是对特征的筛选要求精细,数值型特征以及 id 类特征的选择和处理方法都会对最后的模型效果起决定性的作用。另外模型泛化性,训练过拟合问题以及模型复杂度和线上 rt 的关系也是需要关注的问题。经过多个版本的迭代,包括对现有的多种点击率深度积木模型的复现,引入用户实时点击和未点击 set 特征,引入用户全网序列特征,引入宝贝一阶近邻和预训练向量,加入 time-aware attention 等。下面分阶段进行介绍,包括面对的问题,模型结构,模型离线/在线效果,以及一些思考。
模型迭代
PALM (Pure Adaptive L2 Model) 模型
问题
在新的特征体系下,我们在 FTRL 上拿到不错的结果,很自然的想法是把 FTRL 上的特征复用到 Wide and deep 模型上,然后增加隐式高阶交叉的 deep 侧,来在原来的基础上增加模型表达能力。但是经过几轮的调试,离线指标一直和 FTRL 相比微正向,这不符合对 deep 模型的期望。后来发现把 wide 侧上的特征慢慢迁移到 deep 侧,包括 id 特征,数值特征,命中特征等,离线评测指标涨幅较大,后面也沿用这个思路,采用 pure deep 模型,将所有的特征都迁移到 deep 侧,并拿到了一些收益。但是 pure deep 模型和 wide and deep 模型相比,非常容易过拟合,并且对数值特征以及命中特征的处理方式有一定的要求。其中对离线指标提升较明显的几个点如下:
1)宝贝 id,用户 id,trigger id 等高维 id 类特征需要谨慎加入。航旅这种低频场景,这种高维 id 特征分布一般长尾较严重,大部分 id 的训练数据非常少,噪声较多,模型容易过拟合。在尝试中,正则以及 dropout 等常用抑制过拟合的方式一直没有较好的效果。后续借鉴 DIN 中介绍的 adaptive l2 regularization 的方式,挑选了一批类似用户id这种高维稀疏 id 类特征做动态正则。对正则系数做适当调整后,模型训练正常,全量数据过 5 个 epoch 也不会出现过拟合现象。
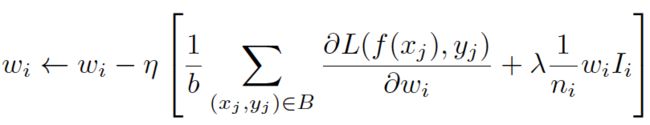
2)命中特征(lookup 特征)在目前的 rtp fg 过程中如果没有命中的话,是不存在这个特征结果的,也没有默认值。反映到模型中,如果没有命中,那么 dense 类型输出为 0,id 类型经过 embedding 操作之后输出全零的向量。在神经网络这种对数据分布敏感的模型中,我们考虑了两种使用方式。第一种是采用 dense 类型,命中之后有大于零的值,没有命中的话为零,符合正常数据分布。第二种是 id 类型,命中之后输出一个 id,经过 embedding 操作之后输出均值为零的向量,没有命中的话输出全零向量,也是符合正常数据分布的。经过试验第二种优于第一种,但是第二种方式 embedding 的维度不适合选择太大,因为命中特征本身较稀疏,输出全零向量的可能性较多,会影响模型训练过程。
3)Warm-up+Adam+learning rate decay 的方式相较于其他优化方法对离线指标的提升较大,非常值得一试。
4)batch normalization 在模型训练中起了非常大的作用。由于 deep 侧包括大量的高阶 look up 特征和归一化之后的数值型特征,离散化之后的数值型 id 特征以及普通 id 类特征的 embedding 结果,输入到网络中的数值非常不规范。后面发现 batch normalization 能有效规范这种多种来源的特征组合输入,保证网络的正常收敛。经过尝试在 embedding 层之后加前置 BN,后续接 fully_connected + BN + relu 的这种形式在离线指标上表现最好。
模型结构
最终的网络结构如图:
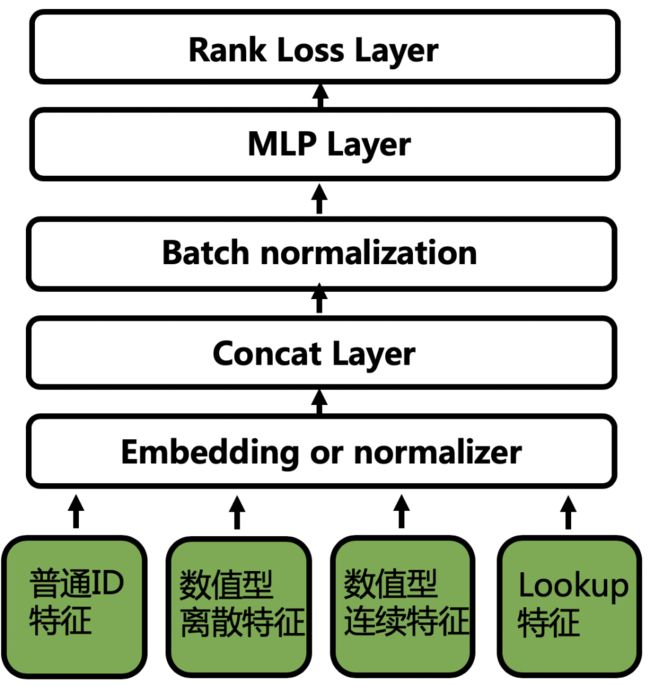
图中的模型细节就不累述了。该模型的 loss function 和后续的迭代版本都是采用 pointwise 的形式。离线评测都采用同样时间区间的训练数据的 T + 1 评测 AUC。
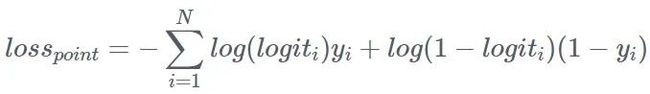
模型效果分析
同样的时间窗口,采用 30 天数据训练,T + 1 评测,离线指标如下,提升还是很明显的。
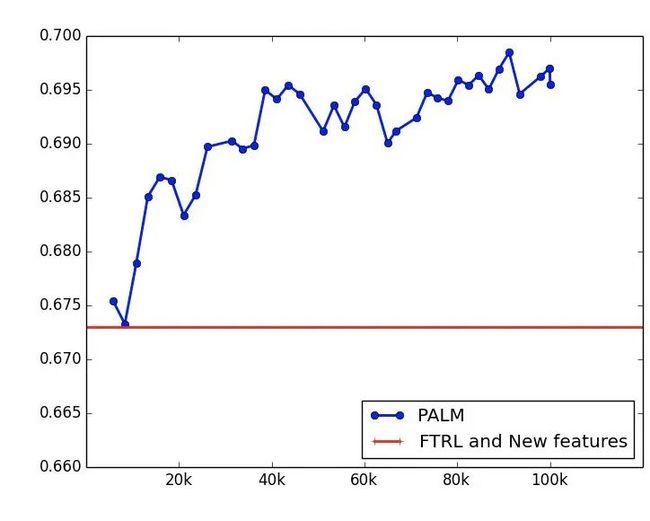
效果
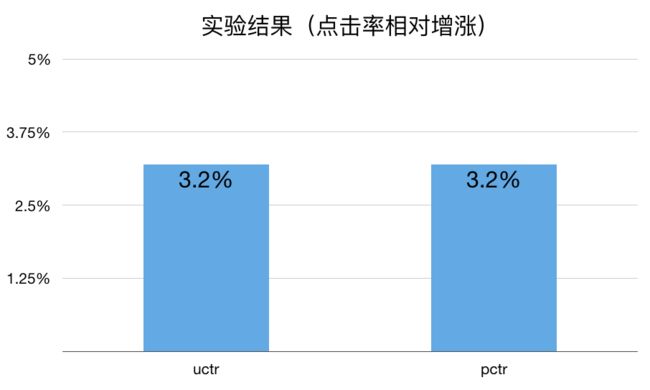
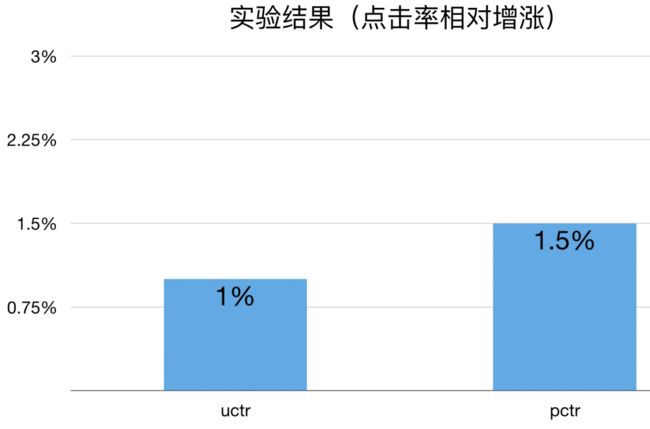
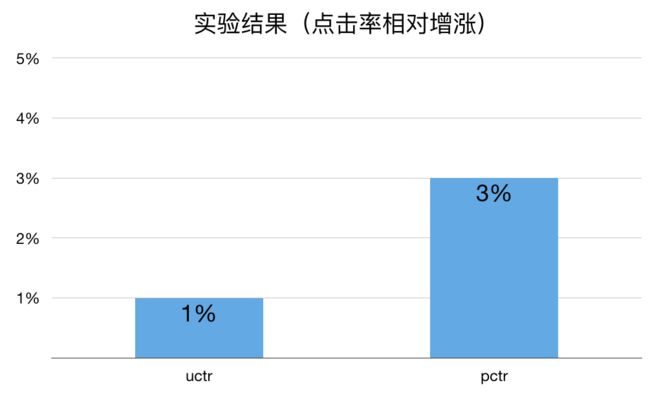
上线实验观察 4 天,相较于新特征的 FTRL,uctr 平均提升 3.2%,pctr 平均提升 3.2%。
FB-PALM (FeedBack-PALM) 模型
问题
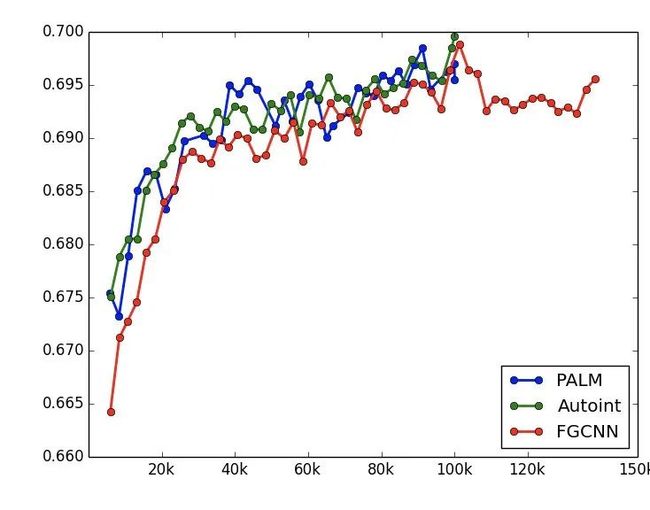
前一个版本在 pure deep 模型上拿到不错的收益。很自然的想法是尝试各种点击率深度积木模型,比如 DCN,DeepFM,XDeepFM,PNN,Autoint,FGCNN 等,但是经过几版实现以及调优,发现这些 model 结构和上一个版本相比提升微弱,如下图。本来以为是模型复杂度高了,于是对于 FGCNN 多训练了 20k 步,发现模型处于收敛状态。猜想原因为目前 pure deep 模型中已经包含了大量高阶特征,特征不变的情况下,特征的隐式高阶组合已经足够了,显示的高阶组合带来的收益较少。
但是模型还是要继续迭代的,于是切换了思路,通过引入原始特征体系中没有的更多复杂结构特征来实现模型的性能提升。这一版主要添加了用户短期全网实时宝贝点击序列以及用户短期场景内宝贝曝光未点击序列特征,序列中的宝贝考虑 Id,目的地,类目, Poi,Tag 以及行为类型和行为次数等属性。模型结构上没有太多的创新,对于两组序列特征,以待推荐宝贝的 Id,目的地,类目,Poi,Tag 综合起来作为 query,对两组序列进行 attention pooling。然后将 pooling 的结果加入 Pure deep 的输入层,其他结构不变。其中对离线指标提升较明显的几个点如下:
1)对于序列特征中的宝贝并不是考虑越多的属性效果会更好,选择的属性需要覆盖度高,不然序列中太多的属性默认值会导致模型训练不佳。
2)这里对于两组序列,因为同样采用宝贝 id 特征,所以为了防止过拟合,也加入了动态正则的技巧。但是这里需要注意的是虽然待推荐宝贝 id,点击宝贝 id 以及曝光未点击宝贝 id 都是宝贝 id,但是由于来源不同,id 出现的频次也会不同,因此这三类 id 都采用自己各自出现的频次分布进行动态正则。另外这三类宝贝 id 也都采用不同的 embedding matrix,避免正则之间的影响。
模型结构
最终的网络结构如图:
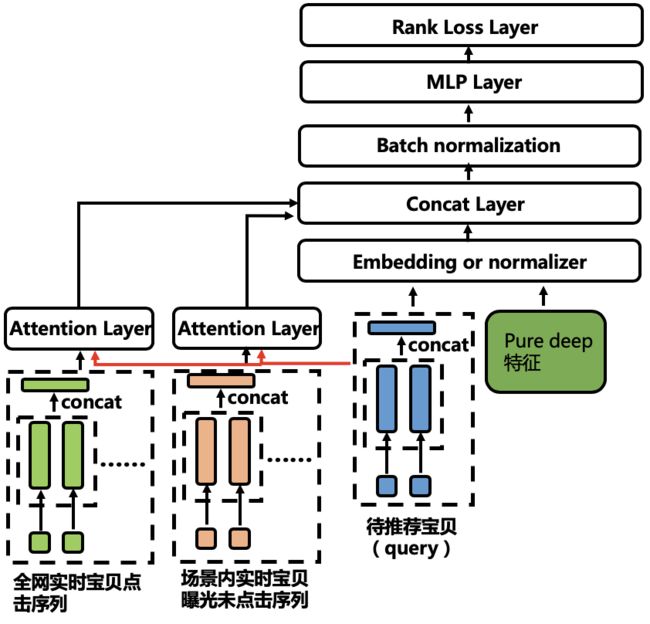
下面对模型的核心部分进行详细描述:
1)对于宝贝维度,模型存在三类信息,包括点击宝贝行为,曝光未点击的宝贝行为以及待推荐宝贝。除了宝贝id以外,我们将行为类型,目的地,类目,tag,poi 等 side information 加入模型中。这里融合采用 concat 的方式。令待推荐宝贝的多个特征经过 embedding 之后得到的向量分别为:![]() ,其中 L 为特征的类型数,则可以得到待推荐宝贝的表达为:
,其中 L 为特征的类型数,则可以得到待推荐宝贝的表达为:
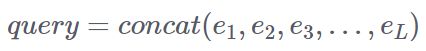
类似的可以得到点击宝贝行为以及曝光未点击宝贝行为的表达为 ![]() 和
和 ![]() ,其中 M 和 N 分别为点击宝贝行为和曝光未点击宝贝行为的个数。
,其中 M 和 N 分别为点击宝贝行为和曝光未点击宝贝行为的个数。
2)通过待推荐宝贝作为 query,对点击宝贝行为以及曝光未点击宝贝行为进行 attention pooling。这里由于维度不一致的原因,采用复杂度较高的加性 attention。attention 的过程如下,其中函数 H 为多层前馈神经网络。这里以点击宝贝行为为例,曝光未点击宝贝行为类似。需要注意的是由于这两类序列信息意义相差较大,所以两个 attention pooling 操作参数是不 sharing 的。
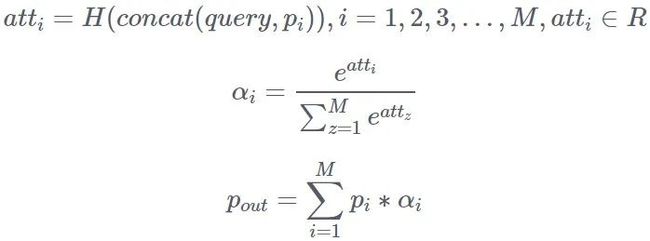
3)最后将点击宝贝行为以及曝光未点击宝贝行为的 pooling 结果 ![]() 和
和 ![]() 与 pure deep 模型的输入层特征进行 concat 一起送入到多层前馈神经网络,输出最后的打分 logit,并进行相应 loss 计算。
与 pure deep 模型的输入层特征进行 concat 一起送入到多层前馈神经网络,输出最后的打分 logit,并进行相应 loss 计算。
模型效果分析
同样的时间窗口,采用 30 天数据训练,T + 1 评测,离线指标如下,提升还是很明显的。
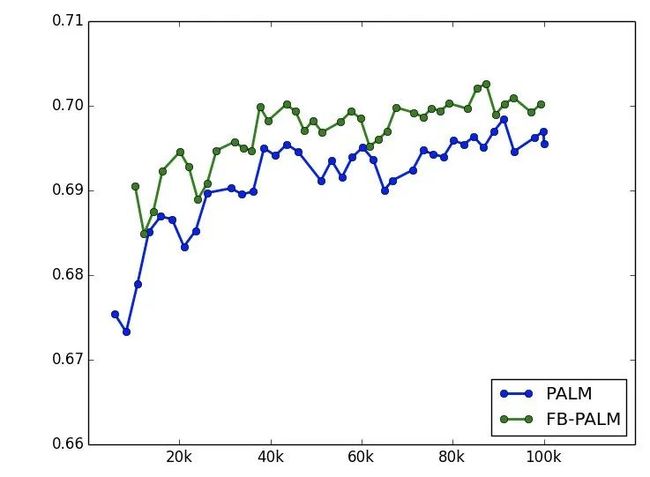
效果
上线实验观察7天,包括三天正向桶以及四天反向桶,相较于 pure deep 模型,uctr 平均提升 1.0%,pctr 平均提升 1.5%。
GLA(Global Local Attention-PALM) 模型
问题
上一个版本主要添加了用户短期全网实时宝贝点击序列以及用户短期场景内宝贝曝光未点击序列特征,并拿到了不错的效果。但是分析特征组成以及模型结构之后,发现还存在一些不足:
1)宝贝行为序列只能覆盖一部分航旅用户,另外一部分航旅用户没有宝贝相关行为,只有机票、火车票、酒店等行业下的行为,但是目前模型中考虑的序列还没有 cover 这部分用户。
2)上一版模型对宝贝点击序列以及宝贝曝光未点击序列只是做了加性 attention pooling 的操作,只考虑了 query(待推荐宝贝)和序列中的每一个元素的相关性。我们还应该考虑序列中每一个元素之间的相关性。
针对上述不足,在这一版本迭代过程中:
1)加入用户全网行为序列,包括机票,火车票,酒店,宝贝等行业。需要注意的是在实践过程中,发现全网行为序列中的 id 属性维度会造成模型的过拟合现象,加入动态正则之后还是没能缓解。分析原因有可能是 id 属性在机票、火车票、酒店以及宝贝的混合序列中分布太杂乱,因此去除 id 属性,只考虑覆盖度高的目的地、类目、Poi、Tag 以及行为类型等属性。用户全网行为序列的 pooling 方式采用在意图模型中积累的 Multi-CNN + attention 的方式,具体细节可参考飞猪用户旅行意图。
2)对宝贝点击序列以及宝贝曝光未点击序列的 pooling 方式,我们采用 transformer + attention 的形式,在原来加性 attention 的上一层,我们先通过 transformer 对序列中个体之间的相关性通过 self-attention 进行描述,然后再通过 attention 进行 pooling。当然和上一个版本一样宝贝点击序列以及宝贝曝光未点击序列的 pooling network 的参数是不 sharing 的。
模型结构
最终的网络结构如图:
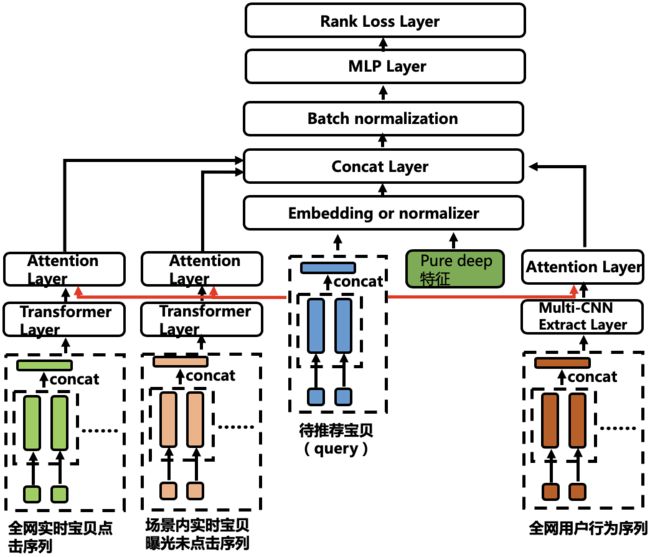
下面对模型的核心部分进行详细描述,一些通用性的模块的细节不详细介绍。
1)对于用户全网行为序列,我们只考虑行为类型,目的地,类目,tag,poi 等覆盖度高的粗粒度属性,不考虑 id 这一维属性,防止过拟合。融合的方式采用 concat 的方式。
2)用户全网行为序列的 pooling 方式采用 Multi-CNN + attention 的方式。通过 Multi-CNN 抽取不同区间范围内的局部特征(units),同时考虑 local 和 global 信息。区间越小,更加关注于局部,区间越大,更加关注于全局。比如区间为 1 时,考虑的是 point level。unit 中包含多种目的地类型,包括酒店,宝贝,火车票,机票等。通过 d 个形状为 d ∗ h 的 filters 对输入 ![]() 进行步长为1的卷积,卷积方式为 SAME。经过 m 次类似的操作,每一次操作filter的形状为
进行步长为1的卷积,卷积方式为 SAME。经过 m 次类似的操作,每一次操作filter的形状为 ![]() ,最后输出为 m 个和输入形状一致的序列向量,
,最后输出为 m 个和输入形状一致的序列向量,![]() 。因为混合序列的形式,序列长度过长,如果采用RNN的形式一方面计算量大,另一方面长时依赖较弱。然后复用上一版模型中的加性 attention 对 Multi-CNN 抽取出来的多组序列进行 attention pooling,并将 pooling 的结果和 pure deep 模型的输入层 concat。需要注意的是这里多组序列的 attention pooling 参数是共享的。
。因为混合序列的形式,序列长度过长,如果采用RNN的形式一方面计算量大,另一方面长时依赖较弱。然后复用上一版模型中的加性 attention 对 Multi-CNN 抽取出来的多组序列进行 attention pooling,并将 pooling 的结果和 pure deep 模型的输入层 concat。需要注意的是这里多组序列的 attention pooling 参数是共享的。
对于点击宝贝行为,曝光未点击的宝贝行为的 pooling 过程,在 attention 之前添加一层 transformer 操作,通过 self-attention 来捕获序列内个体之间的关系,然后再进行加性 attention pooling。其他的操作不变。
模型效果分析
同样的时间窗口,采用 30 天数据训练,T + 1 评测,离线指标如下,提升还是很明显的。这里和上一版模型的离线结果图在 AUC 范围上有所不同是因为切换了时间窗口。
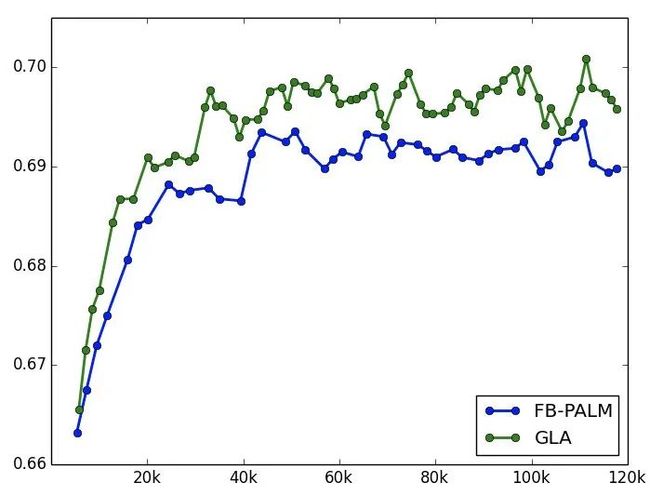
效果
上线实验观察,相较于 FB-PALM 模型,uctr 平均提升 1.0%,pctr 平均提升 3.0%。
其他的尝试
宝贝的一阶近邻信息和宝贝 pretrain embedding
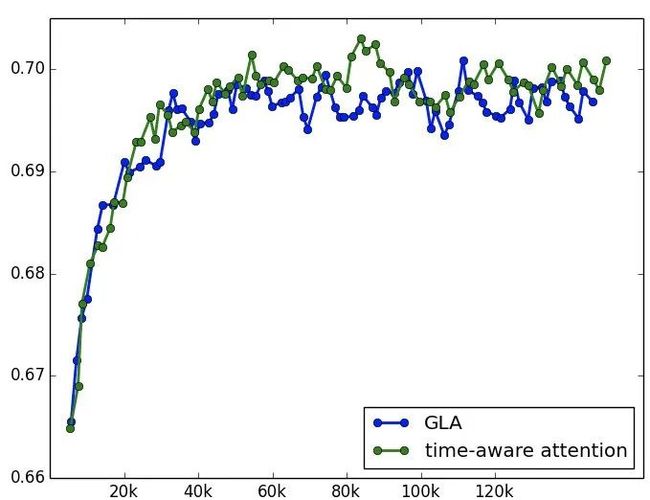
前面后两版模型是在用户侧增加了复杂序列特征,而宝贝侧一直很薄弱。因此考虑增加宝贝的一阶近邻信息和宝贝的 pretrain embedding 向量。一阶近邻通过统计历史一年用户 session 行为中宝贝的共现关系来获得。而宝贝的 pretrain embedding 向量包括文本向量,图像向量以及基于随机游走产出的 deepwalk 向量。实验下来单独增加这些 trick 和 pure deep 模型相比能拿到很大的提升,但是叠加到后续的模型版本上效果不明显。应该需要再探索更加精细的融合方式,而不是直接都 concat 到输入层。两次实验结果如下,确实很微弱,因此没有上线验证。
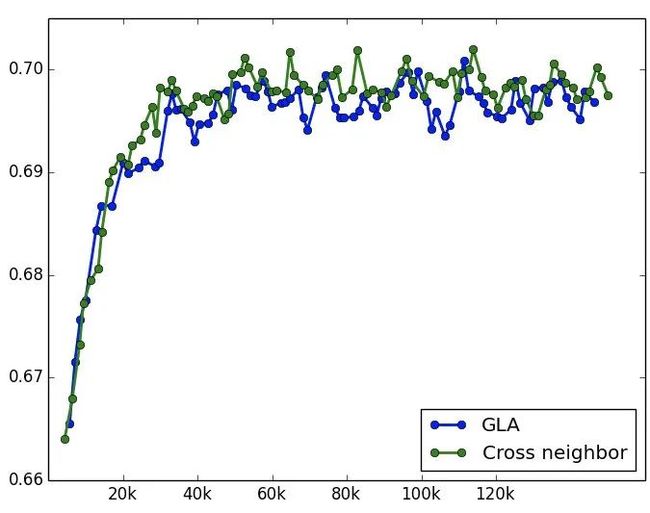
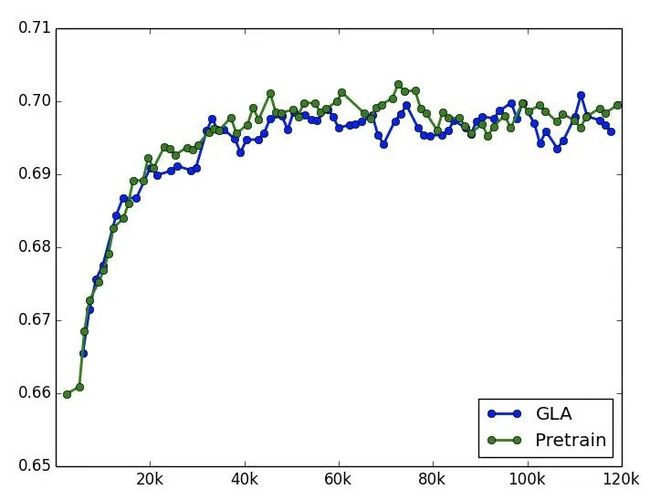
time-aware attention
前几个版本的模型中 time 的信息都是通过 side information 的方式加入,类似于 pos embedding。但是 time 的信息在行为序列刻画过程中十分重要。调研了一些方法,包括 time-LSTM 等,但是由于 RNN 的计算复杂度太高,也放弃了。后续尝试将 time 的信息后置,直接加到 attention 的过程中,在离线表现上有一些收益,但是也不明显,暂时没有上线,后续这个也是值得探索的。
未来展望
目前飞猪首页猜你喜欢数据来源非常多,如何在不同数据来源的混合数据集下学习出在多场景下都很 solid 的模型是值得探索的。
目前几版模型在特征显示交叉的模型结构上没有拿到多少收益,后续需要探索这个问题,从特征体系,到模型结构,到数据来源上一起分析这个问题。
「 更多干货,更多收获 」
全景揭密阿里文娱智能算法-搜索推荐等.pdf(附下载链接)
【招聘内推】阿里巴巴创新事业群实习招聘【招聘内推】阿里巴巴1688推荐算法团队招聘【报告分享】2020年中国知识图谱行业研究报告.pdf智能推荐算法在直播场景中的应用
推荐系统工程师技能树
【电子书分享】美团机器学习实践.pdf
【白岩松大学演讲】:为什么读书?强烈建议静下心来认真看完
关注我们
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|

一个「在看」,一段时光????