python网络爬虫-爬虫实战-(爬取网易云薛之谦歌单里歌曲并下载)
1、导入要用到的库
#导入库
import requests
from fake_useragent import UserAgent
from lxml import etree
import re
很多初学python的同学不知道如何下载第三方库,我在这介绍一种和简单的方法
1:首先准备好下载命令
python -m pip install 想要的库的名称 --trusted-host=pypi.python.org --trusted-host=pypi.org --trusted-host=files.pythonhosted.org
把自己想要下载的库的名称替换掉命令中的"想要的库的名称",比如下载lxml第三方库的命令如下:
python -m pip install lxml --trusted-host=pypi.python.org --trusted-host=pypi.org --trusted-host=files.pythonhosted.org
2:在Pycharm的Terminal中执行这行命令

如图所示,回车即可。
2、分析获取网址
进入网易云官网搜索"薛之谦"

得到一个网址为"https://music.163.com/#/artist?id=5781"
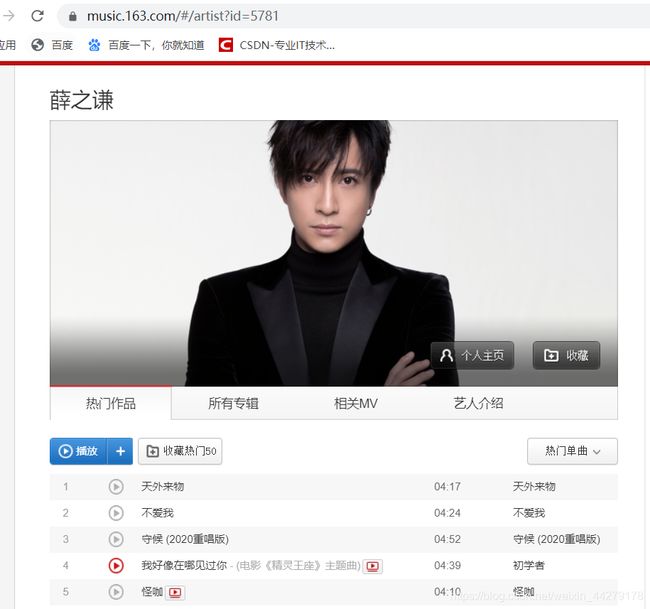
很明显这不是真正的请求网址,检查网页,重新搜索薛之谦在 network doc 下会有一个新的请求文件点进去看到的Request URL: https://music.163.com/artist?id=5781 就是我们想要的请求url
这时候我们可以先把这个页面的内容爬取打印出来,看一下是不是我们要的东西
url = 'https://music.163.com/artist?id=5781'
headers= {
"User-Agent": UserAgent().chrome
}
result = requests.get(url, headers=headers).text
print(result)

看到这就知道确实是爬取了薛之谦第一页歌单的信息
接下来分析每一首歌的网址信息

用同样的方法检查后获取到
Request URL: https://music.163.com/song?id=1463165983
通过简单分析可以知道id就记录是那一首歌
3、删选数据
我们可以看到,爬取的歌单内容里面虽然有我们想要的数据,却也有大量不需要的内容,此时我们需要删选数据获取列表中的歌曲id,储存在一个字典中,里面每个元素为每首歌的id
dom =etree.HTML(result)
# 通过审查元素发现每首歌在 中通过xpath分析得获取所有歌曲id的xpath语句为'//a[contains(@href,"/song?")]/@href'
ids = dom.xpath('//ul[@class="f-hide"]//li/a/@href')
#将数据切片只需要id数值
#正则表达式
for i in range(len(ids)):
ids[i] = re.sub('\D', '', ids[i])
print(ids)

此时我们就获得了这一页薛之谦歌单里的每一首歌的id值并存在了一个字典里
通过一个for循环验证我们的成果
for i in range(len(ids)):
#每一首歌的地址
M_url = f'https://music.163.com/song?id={ids[i]}'
response = requests.get(M_url, headers=headers)
html = etree.HTML(response.text)
music_info = html.xpath('//title/text()')
music_name = music_info[0].split('-')[0]
singer = music_info[0].split('-')[1]
print(music_name, singer)
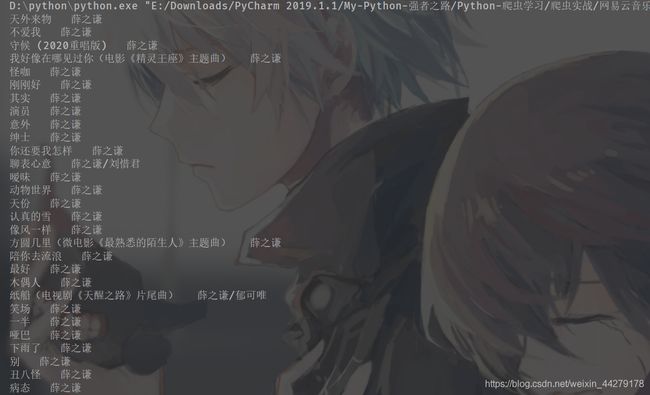
可以看到我们通过每一首歌的网址爬取了每一首歌的歌名和歌手名
4、获取歌源
接下来进入最重要的环节,获取歌源,我们之前做的只是获取到每首歌的url信息但那些并不可以实现播放,我们需要通过外链来生成mp3文件
为网易云音乐的外链地址:
base_url = 'https://link.hhtjim.com/163/'
在这介绍一个可以获取各大音乐平台外链信息的网址 跳转
通过拼接每一首歌的id信息获得每一首歌的外链网址
base_url = 'https://link.hhtjim.com/163/'
for i in range(len(ids)):
#每一首歌的地址
M_url = f'https://music.163.com/song?id={ids[i]}'
response = requests.get(M_url, headers=headers)
html = etree.HTML(response.text)
music_info = html.xpath('//title/text()')
music_name = music_info[0].split('-')[0]
singer = music_info[0].split('-')[1]
print(music_name, singer)
music_url = base_url + str(ids[i]) + '.mp3'
print(music_url)

5、下载歌曲
在项目当前文件下建一个music文件夹来储存爬取的歌曲文件,文件格式为mp3格式 ,
wb: 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
with open('./music/'+music_name+'.mp3', 'wb') as file:
file.write(music)
print("正在下载第"+str(i+1)+"首: "+music_name+singer)
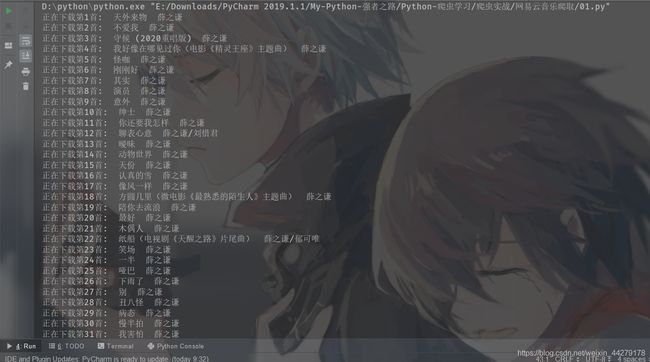

去本地对应的文件下就可以找到这些音乐啦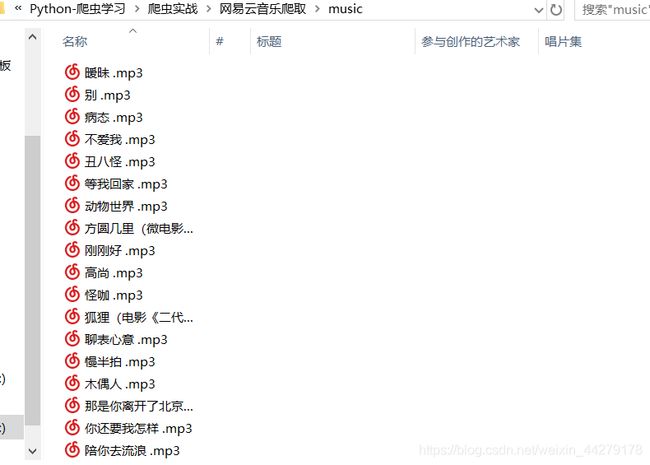
可以用任何音乐播放器播放。
6、总的代码
#导入库
import requests
from fake_useragent import UserAgent
from lxml import etree
import re
#网易云官网 搜索薛之谦跳转网页后 检查 network doc 找到该网页的
#Request URL: https://music.163.com/artist?id=5781
#1、确定url地址(薛之谦的歌单)
url = 'https://music.163.com/artist?id=5781'
#网易云音乐的外链地址
base_url = 'https://link.hhtjim.com/163/'
#2、请求
headers= {
"User-Agent": UserAgent().chrome
}
result = requests.get(url, headers=headers).text
# print(result)
#3、删选数据 拿到列表中的歌曲id 为一个字典 里面有每首个的id
dom =etree.HTML(result)
# 通过审查元素发现每首歌在 中通过xpath分析得获取所有歌曲id的xpath语句为'//a[contains(@href,"/song?")]/@href'
ids = dom.xpath('//ul[@class="f-hide"]//li/a/@href')
#将数据切片只需要id数值
#正则表达式
for i in range(len(ids)):
ids[i] = re.sub('\D', '', ids[i])
#print(ids)
for i in range(len(ids)):
#每一首歌的地址
M_url = f'https://music.163.com/song?id={ids[i]}'
response = requests.get(M_url, headers=headers)
html = etree.HTML(response.text)
music_info = html.xpath('//title/text()')
#print(music_info) #['我好像在哪见过你(电影《精灵王座》主题曲) - 薛之谦 - 单曲 - 网易云音乐']
music_name = music_info[0].split('-')[0]
singer = music_info[0].split('-')[1]
#print(music_name, singer) #我好像在哪见过你(电影《精灵王座》主题曲) 薛之谦
#获取歌源
music_url = base_url + str(ids[i]) + '.mp3'
#print(music_url) #打印出每首歌的外链网址
music = requests.get(music_url).content
#4、保存
with open('./music/'+music_name+'.mp3', 'wb') as file:
file.write(music)
print("正在下载第"+str(i+1)+"首: "+music_name+singer)
欢迎持续关注!
我的个人博客网站 jQueryzk Blog