Hive 超详细基础知识指南,手把手带你进入Hive殿堂
Hive学习指南
你好,这是一个初学者对于Hive学习的一个知识体系框架,写这篇博客的目的是想对自己的一个知识体系进行一个全方位的概括,同时也希望自己的心得体会能够帮助到大家。
前言
我是在大三下暑假实习的时候接触HIVE数据库的,因为学校没有学过,所以在公司自学时就不像在学校有同学和老师的那种学习环境,所有东西都要自己去了解自己去体会,而且Hive并没有好的文档,所以本篇博客的目的是帮助引导那些初学CS领域或者和我一样年轻的大学生朋友。如果有讲解的不够彻底或者您对我博客改进有建议的可以多多交流。
1.基础知识
hive目前岗位需求一般为基于大数据平台,开发和维护数据仓库相关,对业务需求部门进行数据支持;根据业务部门需求,充分利用现有数据资源,进行数据提取、整理和挖掘(ETL)。学好一个东西我认为应从底层原理了解起来,例如一辆汽车为何可以运动其原理是什么,类似的在学习过程中多思考才能激发自己的对所学东西的兴趣。
1.1 Hive的起源
hive最初的背景是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,他的出现时为了解决用户如何从现有的数据基础架构转移到Hadoop上,而这个基础架构是基于传统关系型数据库和结构化查询语句(SQL)的,此过程在当时有很多局限性并且这些常见的数据运算对应到底层的MapReduce API也是十分令人繁琐的,因此Hive的出现就是为了帮助人们解决这一难题,让用户只关注查询本身。(Hive可以将大多数查询任务转换成MapReduce任务)
1.1.1缺点
1.Hive不是一个完整的数据库,他的最大的限制是不支持记录级别的更新,插入或者删除操作,但是用户可以通过查询生成新表或者将查询结果导入到文件中。
2.同时Hive又是一个面向批处理的系统,而Mapreduce任务(job)的启动过程比较缓慢,所以Hive的查询延时比较严重。
3.不支持OLTP(联机事物处理)所需的关键功能
1.1.2优点
对于HIve来说,他的优势是能帮助开发者更好的上手,只要你会SQL,就能够维护其海量的数据和对数据进行挖掘。(数据仓库应用程序)
1.2数据库和数据仓库的区别
a .数据库,对于数据会做精细化的管理,具有事物的概念。 数据仓库,存储数据的格式就类似于打包,没有事物的概念 b.操作方式的区别 数据库:noSql语法 put\get\scan 数据仓库:SQL语法 c.用途的区别: 数据库: OLTP 联机事务处理 增删改 数据仓库: OLAP 联机分析处理 查询 d.模式的区别 数据库: 写模式 数据仓库: 读模式**
1.3 Hive和MapReduce基本概述
如果熟悉Hadoop和MapReduce计算模型的话可以跳过本章节虽然用户可以不精通MapReduce就可以上手Hive,但是理解MapReduce基本原理才可以更好的帮助用户了解Hive的底层是如何运行的
Mapreduce是一种计算模型,他是把一个任务进行分布式换算成多个单个的任务并在服务器集群中执行,这些任务合在一起计算就是最终的结果
MapReduce这个术语有两个基本数据转换操作:RAP过程和REDUCE过程。
MAP过程:将集合中的元素转换成另一种元素,输入的键值对会被转换成多个键-值对输出,其中输入和输出的键必须完全不同
REDUCE过程:某个键的所有键-值对都会被分发到同一个reduce操作中,目的是将值的集合转换成一个值(例如对一组数据求和或者求平均值,或者转换成另一个集合)这个Reduce最终会产生一个键-值对。
链接:Word Count基于Mapreduce的基础算法入门(Link)
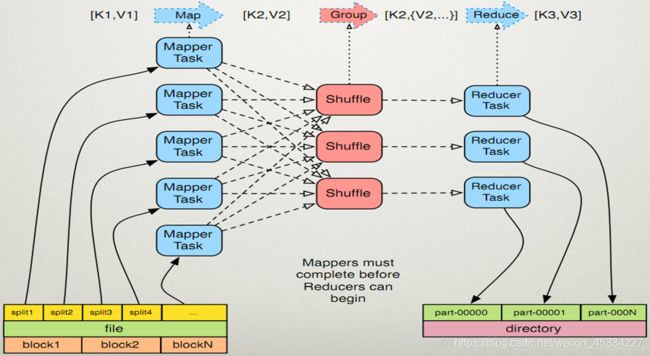
图片是关于Mapreduce的执行过程的直观图,大家可以参考一下,或者直接点击上面链接去查看Word Count算法详解。
1.4 Hive 组成模块

1)Client 用户接口,主要包含CLI(command language
interface)、JDBC或ODBC、WEBUI(以浏览器访问hive); (2)Thrift Server
提供JDBC/ODBC接入的能力,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口;
(3)Metastore 元数据,包括表名、表所属的数据库、表的拥有者、列/分区字段、表的类型、表的数据所在目录等内容;
(4)Driver:(实现将HQL转化为MR过程)
核心组件,整个Hive的核心,它的作用是将我们写的HQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架;
具体的编译过程: SQL解析器:将SQL字符串(准确说HiveQL)转化为抽象语法树AST; 编译器:将AST编译生成逻辑执行计划;;
逻辑优化器:对逻辑执行计划进行优化; 物理执行器:将逻辑执行计划转成可执行的物理计划,如MR/Spark;
(5)HDFS&MapReduce 指的是hive使用HDFS进行存储,使用MapReduce进行计算。
用户创建完表之后,只需要根据业务需求编写Sql语句,而后将由Hive框架将Sql语句解析成对应的MapReduce程序,通过MapReduce计算框架运行job,便得到了我们最终的分析结果。
2.数据类型和文件格式
2.1 基本数据类型
每一个数据库都需要了解数据类型,因为这是建表的基础,下图中就是关于数据类型的详解,但其实在工作中,根据我一个个表的观察发现,STRING,INT,BOOLEAN,FLOAT,DOUBLE这些类似的多,也就是说数据类型并不是学的越多越好,而是秉着无忧所需的概念,会使用大众的就行,若要用到高阶的只需网上查找就行。

2.2 集合数据类型

大多数的关系型数据库并不支持这些集合数据类型,因为使用它们会趋向于破坏标准格式。破坏标准带来的问题是会增大数据冗余风险,进而导致不必要的磁盘空间,还有可能造成数据不一致,因为当数据发生改变时冗余的拷贝数据可能无法进行相应的同步
这里有一个用于演示如何使用这些数据类型的表结构声明语句,这是一张虚拟的人力资源应用程序的员工表
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:STRING>
);
2.3 文本文件数据编码
常见的文本文件的格式,有以逗号和制表符分隔的文本文件,也就是所谓的逗号分隔值(CSV)或制表符分隔值(TSV)。只要用户需要,Hive是支持这些文件格式的。然而,这两种格式的文件有一个共同的缺点,那就是:
用户需要对文本文件中那些不需要作为分隔符处理的逗号或者制表符格外小心
也因此,Hive默认使用了几个控制字符,这些字符很少出现在字段值中。Hive使用术语field来表示替换分隔符的字符。
Hive中默认的记录和字段分隔符如下表:

EXAMPLE:

用户可以不使用这些默认分隔符,而指定使用其他分隔符。下面这个表结构和和之前那个表是一样的,不过这里明确制定了分隔符:
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
我个人感觉想了解这个原理可以去接触JSON格式,他能帮助你更深刻的了解文本文件数据编码的原理
JSON 名称/值对
"firstName" : "John"
JSON 对象
{ "firstName":"John" , "lastName":"Doe" }
JSON 数组
{
"employees": [
{ "firstName":"John" , "lastName":"Doe" },
{ "firstName":"Anna" , "lastName":"Smith" },
{ "firstName":"Peter" , "lastName":"Jones" }
]
}
链接: JSON教程(link)
3. 数据定义
讲数据定义之前我们要先明白,我们所创建的数据库的表其实就是存放在HDFS上的文件夹里面,顾名思义就是一个文件,所以以后想通过脚本或者shell命令操作hive表的话,直接对hive表存放地址文件操作就行,这个是我和前辈们学习而收获到的经验总结。
具体操作
1.创建表
2.分区表
3.删除表
4.修改表
3.1 创建表
先beeline进入数据库以后,然后选择自己的数据库,或者重新创建一个。
create database (name);
查看数据库
show database;
删除数据库
drop database if exists (数据库名字);
这时你就可以创建你想要的表了,语句如下:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
这是官网教程建表,但是我们可能有时候用不到这么多的条件
CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常.(这个在写脚本文件的时候特别好用)
EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)(一般在工作中都建外部表,因为外部表不会改变内部表的结构和数据)
LIKE允许用户复制现有的表结构,但是不复制数据 COMMENT可以为表与字段增加描述
COMMENT可以为表与字段增加描述
此外用户还可以指定SerDe,也就是第三方输入输出格式,Inputfomat和Outputformat
STORED AS
SEQUENCEFILE
| TEXTFILE
| RCFILE
| INPUTFORMAT input_format_classname OUTPUTFORMAT
我们有时候会根据业务需求来对文件输出格式进行选择,比如常用的有parquet,orc,avro。
3.2 外部表
1.外部表和内部表的区别就是有无external
2.内部表的存储路径是默认的,而外部表的存储路径需要自己定义,上面的基础语法就讲到过
3.内部表是直接控制metastore的,因此内部表的操作很敏感,因为他们会直接对真实表文件进行修改
外部表只是内部表的一个倒影,所以对外部表进行操作对原文件没有改变
通过上面的基础学习那让我们看一看代码,我将建一个外部表
CREATE EXTERNAL TABLE page_view
(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '' ;
从中我们可以看出external是一个外部表,此外数据类型是string,int和bigint(区别不大,一个是4bite长度,一个是8bite长度),comment是对字段增加了描述(相当于注释),row是对文件格式进行了说明,stored as是为了让其变成自己需要的格式,最后的location是指定外部表的存放地址
3.3 分区表
这是一个很有意思的概念,目前我所接触到的数据量中没有用到过分区表的概念,但我猜想,在亿级别的数据量中可能会用到分区的概念,他的好处是什么呢,比如说你以时间为分区,那么查找的时候就能快速定位当天时间的那个分区中,然后在该分区中查找符合该信息的表,这就像列式数据库的查找方法一样。
create table test_partition (
id string comment 'ID',
name string comment '名字'
)
comment '测试分区'
partitioned by (year int comment '年')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
其中我们可以看到partitioned by(内容)
这一部分就是写的外部分区的信息,或者说是查找分区表的条件。
3.3.1 查看分区信息
show partition (table_name);
3.3.2 添加新分区
alter (table) add partition(内容) local '(地址)'
增加地址能把心分区保存到自己想存放的文件夹下
3.3.3 插入数据到分区表
insert into table (table) partition(内容) values(内容)
唯一要注意的是插入操作我们需要添加partition的条件
3.3.4 删除分区表
alter table (表名字)drop if exists partition(内容);
3.4 删除表
其实这个就是基本的SQL操作,具体命令如下:
drop table if exists (table名字);
3.5 修改表
3.5.1.表重命名
alter table (原表名字) rename (新表名字);
3.5.2.修改列信息
alter table(表名字) change column (原列名)(新列名)(新列名格式)
3.5.3.增加列
alter table(表名字) add columns(列名,列格式)
3.5.4.删除或者替换列
alter table (表名字)drop column (列名);
alter table (表名字)replace columns(新列名,新列格式)
注意替换是把表内容里面的所有内容进行替换
4. HIVE QL数据操作
4.1 向表中装载数据
这一部分对我来说是一个麻烦的点,为什么呢,因为我是用公司电脑进行操作的,所以就出现了一个权限的问题,因为权限原因你不能装载数据到我们需要的表中,所以我们在装载数据的时候要注意文件是否有权限进行移动和装载。
此外hive没有行级别的数据插入,数据更新和删除操作,那么往表中进行大批量的插入数据就是装载操作,接下来我会带领大家一起来了解如何装载。
load data local inpath '文件地址' into table (表名);
load data inpath '文件地址' into table (表名)
partition(country='us',sex='male');
这里我们需要注意的是,我加了local是指把文件存放到我们本地目录夹下面,然后装载到Hive表中,如果你发现local环境下不行,那就去掉local,这个时候你就要把文件存放到HDFS环境下的目录来进行装载。此外如果有分区则写上partition命令进行区别。
并且该装载操作是在shell交互式命令里面完成的而不是在Hive环境下。
4.2 通过查询语句向表中插入数据
用这种方法就不用自己建造数据来进行装载
insert overwrite table employee
partition(country='us',state='or')
select * from staged_employee se//对staged_employee进行重新命名 se,方便后面的写法。
where se.country='us' and se.state='or';
这里我们需要注意的是overwrite,他指的是覆盖之前的内容,把之前的内容删除,再加入新的内容。这段语句的意思是往employee表中的分区加入数据,并且该数据是在staged_employee查找出来的且符合查找标准的数据。
4.2.1 tips:动态分区插入
说到插入,我们就需要考虑一个性能问题,我们上面做的只是静态分区插入,参数值需要我们一个一个设置,这样是很麻烦的,因此hive提供了动态分区插入。
insert overwrite table employee
partition(country,state)
select ..., se.country, se.state
from staged_employee se;
这里的动态分区是指根据查询参数推断出需要创建的分区名称,假设表staged_employee中共有100个国家和洲的话,执行完上面的查询后employee就会有100个分区。
4.3 单个查询语句中创建表并加载数据
create table employee
as select name,salary,sex
from a_employee a
where a.sex='male';
这就是通过查询来直接创建表,并且表的DDL和查询表一样,而且数据装载操作也一并执行
4.4 导出数据
Insert…Directory…(在hive中去执行)
insert overwrite local directory '路径地址'
select name,sex
from employee
where country='China';
这是在hadoop中进行操作,当我们的数据保存文件的格式是我们所需要的时候
hadoop fs -cp 原地址 目的地址
注意:hadoop上全地址是hdfs://master-server/tmp/hello
学会了装载数据同时也需要了解导出数据,这也就需要用到了hive的基础内容,他的表数据保存在哪里,虽然我们知道表数据的存放位置,但是你也需要学会导出数据的操作。
5. 查询操作
5.1.SELECT 查询
select * from employee;
这是sql语句中的基础,*你可以换成你自己想要的列
select name address[0] from employee;
这用了索引查询,当address是一个复合函数时候,就可以用这种方法进行尝试。
5.1.1 正则表达式查询
select 'price.*' from employee;
指查找以price开头的列,相当于一个模糊查询,
5.1.2列值计算和函数使用
这个概念我不做详细解释,因为如果你工作中要用到,在进行网上检索信息就行,不用太去强调背诵的概念。
count() 计算总值 count(distinct name)//计算排重以后的name
avg() 平均值
upper() 变大写
5.1.3 Limit
select * from employee limit 2; 限制返回的行数是2行
5.1.4 列别名
select count(salary) as total_salary 重新定义想输出的列的名字
from employee;
5.1.5 case … when … then
适合于单个查询语句的简化
select name,salary,
case
when salary<1000 then 'low',
when salary>=5000 then 'no bad',
else 'very high'
end as bracket from employee;
5.2 Where 语句
5. 2.1嵌套查询
用嵌套查询的原因是where语句中不能使用别名,此外也可能是因为业务量的多少进行操作,具体学习可以根据你的任务或者浏览器检索他人的代码进行学习
select e.* from(
select name,salary,count(distinct jobs )as total_jobs
from employee)e
where e.total_jobs > 1000;
)
5.2.2 Like查询
我觉得这是所有SQL语句中最重要的一个点,因为他能帮助你查询到相关信息,当你不知道如何去静态的输入所需要查询的东西的时候
select name,address,salary from employee where address like '%China';
5.3 Group By 语句
group by 经常和聚合函数在一起使用,所以使用者需要注意对接的函数最好是group by
select name,count(salary) from employe
where sex='male'
group by count(salary);
Having是group by语句中的过滤语句,其实也就是条件判断语句
select name,count(salary),avg(price) from employe
where sex='male'
group by count(salary)
having avg(price)>1000;
5.4 Join语句
select a.name,b.price,
from employee a join stocks b
on a.name=b.name
where a.symbol='AAPL' and b.symbol='IBM';
On指定了两个表之间数据连接条件,Where限制左右表的链接条件
后面还有 left/right/full outer join 的学习,读者可以去别的网站进行学习,这里我就不一一讲解了
5.5 Order by 和 Sort by 排序
select name,price,sex
from employee e
order by e.name ASC;
这里需要注意ASC是升序排序,DESC是降序排序
tips:一般来说Order by运行时间过长,hive要求这样的语句需要加limit语句进行限制
6.视图
视图在工作中常用的是基于一个或多个列的值来限制输出结果,常用的业务场景是你给用户展示数据时候,但你又不希望让他能访问到敏感数据,所以用视图的方式来展现数据。
create view test
as
select name,salary,sex
from employee
where sex = 'male';
使用视图还有一个好处是建立好视图以后你就不用再去写复杂的查询语句了,使用时候自动调视图就行