ELK笔记
ELKStack高级实战培训
http://files.cnblogs.com/files/MYSQLZOUQI/ELKStack%E9%AB%98%E7%BA%A7%E5%AE%9E%E6%88%98%E5%9F%B9%E8%AE%AD.rar
ELK Stack深入浅出PPT.rar
http://files.cnblogs.com/files/MYSQLZOUQI/ELKStack%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BA.rar
https://www.rizhiyi.com/docs/upload/rsyslog.html
以下操作假定您拥有root或sudo权限,在通用的Linux平台使用5.8.0或更高版本的rsyslog。配置完成后您新增的日志文件将通过UDP协议的514端口发送到日志易
logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
http://www.ttlsa.com/?s=elk
http://www.ttlsa.com/elk/elk-upgrade-logstash-to-2-and-logstash-forwarder-to-filebeat/
http://www.ttlsa.com/elk/elk-logstash-structure/
http://www.ttlsa.com/elk/elk-logstash-process-pipeline/
http://www.ttlsa.com/elk/elk-logstash-configuration-syntax/
http://www.ttlsa.com/log-system/installing-logstash-on-rhel-and-centos/
Logstash:负责日志的收集,处理,索引
Elasticsearch:负责日志检索和分析和储存
Kibana:用于搜索和可视化的日志的Web界面,通过nginx反代
Logstash Forwarder: 安装在将要把日志发送到logstash的服务器上,作为日志转发的道理,通过 lumberjack 网络协议与 Logstash 服务通讯
注意:logstash-forwarder要被beats替代了,关注后续内容。后续会转到logstash+elasticsearch+beats上。
组件预览
JDK - http://www.oracle.com/technetwork/java/javase/downloads/index.html
Elasticsearch - https://www.elastic.co/downloads/elasticsearch
Logstash - https://www.elastic.co/downloads/logstash
Kibana - https://www.elastic.co/downloads/kibana
redis - http://redis.io/download
文章:http://www.ttlsa.com/bigdata/elk-platform-for-log-management/
---------------------------------------------------
ELK 常见错误处理
ELK 这里就不介绍了,如何安装请参考博客之前的文章。在这里感谢ttlsa团队,同时,我很荣幸能加入到ttlsa团队中,分享点滴,凉白开说发文章有红包,期待这篇群主能给多少红包。哈哈。
好了,不闲扯,下面总结下ELK使用过程中遇到的常见问题以及解决方案。
1. Kibana No Default Index Pattern Warning
当访问kibana页面时,出现下面的信息:
Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
下面是截图:
Elasticsearch
这就说明logstash没有把日志写入到elasticsearch。
解决方法:
检查logstash与elasticsearch之间的通讯是否有问题,一般问题就在这。
2. Kibana Unable to connect to Elasticsearch
访问kibana出现下面错误信息:
Fatal Error
Kibana: Unable to connect to Elasticsearch
Error: Unable to connect to Elasticsearch
Error: Bad Gateway
Fatal Error
Kibana: Unable to connect to Elasticsearch
Error: Unable to connect to Elasticsearch
Error: Bad Gateway
这个问题很明显,Kibana不能连接到Elasticsearch ,可能 Elasticsearch没有运行 或Kibana 没有配置正确的elasticsearch服务地址。
解决方法:
检查kibana目录下的config/kibana.yml文件,查看elasticsearch配置是否正确。
3. logstash Configuration Contains a Syntax Error
logstash 语法错误,这个问题一般各种各样的。主要是logstash配置文件不对导致的。
解决方法:
在启动logstash前,先检查下logstash配置文件是否有问题,可通过下面命令检测:
/opt/logstash/bin/logstash --configtest -f /etc/logstash/conf.d/30-lumberjack-output.conf
后面指定你自己的配置文件。
4. logstash-forwarder Configuration Contains a Syntax Error
/etc/logstash-forwarder.conf 是一个json格式的配置文件。出错一般是json格式不对,如{}、[]不匹对。
5. SSL Certificate is Missing or Invalid
logstash forwarder 与 logstash 之间通讯需要SSL。如果缺少SSL,服务是启动不了的。需要将logstash上生产的证书拷贝到logstash forwarder服务器上。
同时,还要考虑到生产证书时候, 如果/etc/ssl/openssl.cnf文件[ v3_ca ] 段 subjectAltName = IP: logstash_server_private_ip。logstash forwarder配置文章指定的logstash服务的IP地址要与证书的相匹配。
文章:http://www.ttlsa.com/log-system/troubleshooting-elk-common-issues/
---------------------------------------------------
解析elasticsearch的config下的配置文件
network.bind_host: 192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host: 192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host: 192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
文章:http://blog.csdn.net/an74520/article/details/8219814
------------------------------------------------
配置logstash
logstash配置文件是以json格式设置参数的,配置文件位于/etc/logstash/conf.d目录下,配置包括三个部分:输入端,过滤器和输出端。
# vi /etc/logstash/conf.d/11-nginx.conf
filter {
if [type] == "nginx" {
grok {
match => { "message" => "%{IPORHOST:clientip} - %{NOTSPACE:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:method} %{NOTSPACE:request}(?: %{URIPROTO:proto}/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} (?:%{NUMBER:upstime}|-) %{NUMBER:reqtime} (?:%{NUMBER:size}|-) %{QS:referrer} %{QS:agent} %{QS:xforwardedfor} %{QS:reqbody} %{WORD:scheme} (?:%{IPV4:upstream}(:%{POSINT:port})?|-)" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
add_tag => [ "geoip" ]
fields => ["country_name", "country_code2","region_name", "city_name", "real_region_name", "latitude", "longitude"]
remove_field => [ "[geoip][longitude]", "[geoip][latitude]" ]
}
}
}
这个过滤器会寻找被标记为“nginx”类型(Logstash-forwarder定义的)的日志,尝试使用“grok”来分析传入的nginx日志,使之结构化和可查询。
type要与logstash-forwarder相匹配。
同时,注意将nginx日志格式设置成下面的:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $upstream_response_time $request_time $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http_x_forwarded_for" "$request_body" '
'$scheme $upstream_addr';
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $upstream_response_time $request_time $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http_x_forwarded_for" "$request_body" '
'$scheme $upstream_addr';
日志格式不对,grok匹配规则要重写。
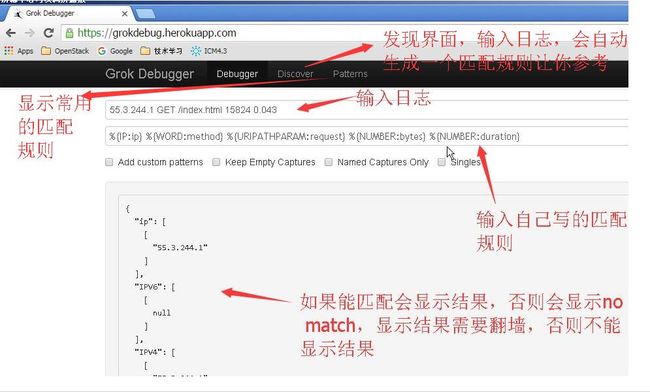
通过http://grokdebug.herokuapp.com/ 在线工具进行调试。
logstash默认自带了apache标准日志的grok正则
grok 匹配日志不成功,不要往下看了。搞对为止先
Discover:输入日志,会自动生成一个匹配规则让你参考
patterns:显示常用的匹配规则
显示匹配结果需要FQ,否则不能显示结果
文章:http://www.ttlsa.com/elk/howto-install-elasticsearch-logstash-and-kibana-elk-stack/
----------------------------------------------------
ELK 产品支持的平台和软件
c. 支持的kibana版本
Kibana Version ES Version Compatibility Shield Version Compatibility
3.1x 0.90.9 and greater 1.0.x-1.2.x
4.0.0-4.1.x 1.4.x-1.7.x 1.0.x-1.3.x
4.2.0+ 2.0.0 2.0.0
e. 支持的watcher版本
Watcher Version ES Version Compatibility
1.0.0 1.5.0 and greater
2.0.0 2.0.0
f. 支持的logstash版本
Logstash Version ES Version Compatibility Shield Version Compatibility
1.5.x 1.0.0 and greater 1.0.0 and greater
2.0.x 1.0.0 and greater 1.0.0 and greater
logstash 1.5.x 版本仅支持ES 2.0.0 以及更高版本的HTTP协议
文章:http://www.ttlsa.com/elk/elk-supported-platforms-and-software/
---------------------------------------------------
ELK elasticsearch 核心术语(2nd)
NRT
elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒。
集群
集群就是一个或多个节点存储数据,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。
一个集群可以只有一个节点。
强烈建议在配置elasticsearch时,配置成集群模式。
节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为elasticsearch的集群。
索引
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。
类型
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
文档
文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的行记录。
分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
水平分割扩展,增大存储量
分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE - 128)。 可通过_cat/shards来监控分片大小。
Elasticsearch
这里的所言的复制和副本是同一个意思。
这部分内容比较枯燥无味,不过蛮重要的,贯穿于整个elasticsearch。
文章:http://www.ttlsa.com/elk/elk-elasticsearch-core-concept/
---------------------------------------------------
1. jdk
elasticsearch只支持Oracle java 和 OpenJDK。
文章:http://www.ttlsa.com/elk/elk-elasticsearch-install/
elasticsearch 2.0.0版本不能以root用户启动。
useradd elasticsearch -M -s /sbin/nologin
---------------------------------------------------
elasticsearch滚动升级过程,不会造成服务中断。elasticsearch提供两种升级类型:全集群重启和滚动升级。
elasticsearch版本所支持的升级类型如下表:
Upgrade From Upgrade To Supported Upgrade Type
0.90.x 1.x, 2.x Full cluster restart
< 0.90.7 0.90.x Full cluster restart
>= 0.90.7 0.90.x Rolling upgrade
1.0.0 - 1.3.1 1.x Rolling upgrade (if indices.recovery.compress set to false)
>= 1.3.2 1.x Rolling upgrade
1.x 2.x Full cluster restart
重要的事情再强调一遍,在执行升级之前,务必先备份数据,这将给你留条后路,如果升级后出现问题还允许你回滚到之前的版本,否则死无葬身之地。
文章:http://www.ttlsa.com/elk/elk-elasticsearch-1-7-2-upgrade-to-2-0-0/
---------------------------------------------------
插件能额外扩展elasticsearch功能,提供各类功能等等。有三种类型的插件:
java插件
只包含JAR文件,必须在集群中每个节点上安装而且需要重启才能使插件生效。
网站插件
这类插件包含静态web内容,如js、css、html等等,可以直接从elasticsearch服务,如head插件。只需在一个节点上安装,不需要重启服务。可以通过下面的URL访问,如:http://node-ip:9200/_plugin/plugin_name
混合插件
顾名思义,就是包含上面两种的插件。
安装中文分词插件ik,请参考之前的文章
kibana的附加功能是通过插件模块来实现的。可以通过bin/kibana plugin命令来管理插件。
文章:http://www.ttlsa.com/elk/elk-elasticsearch-plugin-management/
---------------------------------------------------
ELK kibana查询与过滤(17th)
创建查询
在Discover界面的搜索栏输入要查询的字段。查询语法是基于Lucene的查询语法。允许布尔运算符、通配符和字段筛选。注意关键字要大写。如查询类型是http,且状态码是302。type: http AND http.code: 302。
字符串查询
查询可以包含一个或多个字或者短语。短语需要使用双引号引起来。如:
每个字段都会匹配过去。要搜索一个确切的字符串,需要使用双引号引起来。
如果不带引号,将会匹配每个单词。
kibana会忽略特殊字符。
基于字段的查询
只搜索特定的字段。
正则表达式查询
kibana支持正则表达式过滤器和表达式。
返回查询
允许一个字段值在某个区间。[] 包含该值,{}不包含。
布尔查询
布尔运算符(AND,OR,NOT)允许通过逻辑运算符组合多个子查询。
运算符AND/OR/NOT必须大写。
NOT type: mysql
mysql.method: SELECT AND mysql.size: [10000 TO *]
(mysql.method: INSERT OR mysql.method: UPDATE) AND responsetime: [30 TO *]
创建过滤器
可通过单击可视化中的元素进行筛选。
绿色filter for value 红色filter out value。
文章:http://www.ttlsa.com/elk/elk-kibana-query-and-filter/
---------------------------------------------------
ELK logstash 部署指南与版本变化(
新版本改变
logstash2.0版本的一些改变与以前的版本不兼容
文章:http://www.ttlsa.com/elk/elk-install-guide-and-version-changes/
---------------------------------------------------
---------------------------------------------------
将从logstash1.5版本升级到2.1版本,以及将《ELK部署指南》中使用的logstash-forwarder转移到Filebeat上。
升级步骤
1.停止logstash以及发送到logstash的所有管道。
2.更新apt或yum源或者下载新版包。
3.安装新版的logstash。
4.测试logstash配置文件是否正确。
5.启动logstash以及第一步停止的管道。
关闭logstash以及输入的管道。
# /etc/init.d/topbeat stop
# /etc/init.d/packetbeat stop
# /etc/init.d/filebeat stop
# /etc/init.d/logstash-forwarder stop
# /etc/init.d/logstash stop
这节会将logstash-forwarder迁移到Filebeat上了,后续不再启动logstash-forwarder了。
2. 升级logstash,添加yum源参见前文。
# yum update logstash
3. 检查配置文件
我的配置文件是以《ELK部署指南》中的配置文件为原型的。
# /opt/logstash/bin/logstash --configtest -f /etc/logstash/conf.d/01-lumberjack-input.conf
Configuration OK
# /opt/logstash/bin/logstash --configtest -f /etc/logstash/conf.d/10-active.conf
Configuration OK
文章:http://www.ttlsa.com/elk/elk-upgrade-logstash-to-2-and-logstash-forwarder-to-filebeat/
---------------------------------------------------
ELK logstash 结构
在命令行中指定-e参数,从标准输入到标准输出,并格式化结果。
# /opt/logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
www.ttlsa.com
Settings: Default filter workers: 2
Logstash startup completed
{
"message" => "www.ttlsa.com",
"@version" => "1",
"@timestamp" => "2015-12-07T06:57:01.981Z",
"host" => "localhost"
}
# /opt/logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
www.ttlsa.com
Settings: Default filter workers: 2
Logstash startup completed
{
"message" => "www.ttlsa.com",
"@version" => "1",
"@timestamp" => "2015-12-07T06:57:01.981Z",
"host" => "localhost"
}
logstash会给事件添加一些额外的信息,如@timestamp,标注事件发生的时间。host标注事件发生的主机。此外,还可能有下面几个信息:
type:标记事件的唯一类型
tags:标记事件某方面属性,可以有多个标签。
每个事件就是一个ruby对象,可以随意的给事件添加或者删除字段。每个logstash过滤插件,都会有四个方法add_tag,remove_tag,add_field, remove_field,它们在过滤匹配成功时生效。
logstash管道必须要有input和output元素,filter元素是可选的。input插件定义数据来源,filter插件用来修改用户指定的数据,output插件定义数据写入何地。
logstash结构如下所示:
ELK
下面是一个配置管道:
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}
在现实情况下,数据来源可能有多个,以及将数据写入到不同的目的地。logstash管道可以使用多个input和output来处理这些需求。
下面的例子从Twitter feed和Filebeat input,将信息发送到elasticsearch集群和直接写入到文件。
input {
twitter {
consumer_key =>
consumer_secret =>
keywords =>
oauth_token =>
oauth_token_secret =>
}
beats {
port => "5043"
ssl => true
ssl_certificate => "/path/to/ssl-cert"
ssl_key => "/path/to/ssl-key"
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => /path/to/target/file
}
}
input {
twitter {
consumer_key =>
consumer_secret =>
keywords =>
oauth_token =>
oauth_token_secret =>
}
beats {
port => "5043"
ssl => true
ssl_certificate => "/path/to/ssl-cert"
ssl_key => "/path/to/ssl-key"
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => /path/to/target/file
}
}
Filebeat debug信息:
# filebeat -d 'publish' -e
2015/12/07 07:46:12.170451 publish.go:100: DBG Publish: {
"@timestamp": "2015-12-07T07:46:09.670Z",
"beat": {
"hostname": "elk.ttlsa.com",
"name": "elk.ttlsa.com"
},
"count": 1,
"fields": null,
"input_type": "log",
"message": "218.28.24.98 - - [07/Dec/2015:15:46:07 +0800] \"POST /www.ttlsa.com HTTP/1.0\" 200 0.139 0.141 3890 \"-\" \"Apache-HttpClient/UNAVAILABLE (java 1.4)\" \"\" \"\" http 127.0.0.1:9000",
"offset": 12145391,
"source": "/data/logs/nginx/www.ttlsa.com-access.log",
"type": "nginx"
}
# filebeat -d 'publish' -e
2015/12/07 07:46:12.170451 publish.go:100: DBG Publish: {
"@timestamp": "2015-12-07T07:46:09.670Z",
"beat": {
"hostname": "elk.ttlsa.com",
"name": "elk.ttlsa.com"
},
"count": 1,
"fields": null,
"input_type": "log",
"message": "218.28.24.98 - - [07/Dec/2015:15:46:07 +0800] \"POST /www.ttlsa.com HTTP/1.0\" 200 0.139 0.141 3890 \"-\" \"Apache-HttpClient/UNAVAILABLE (java 1.4)\" \"\" \"\" http 127.0.0.1:9000",
"offset": 12145391,
"source": "/data/logs/nginx/www.ttlsa.com-access.log",
"type": "nginx"
}
停止logstash服务的失效检测
正常关闭logstash服务的步骤如下:
关闭所有的input、filter和output插件
处理完正在处理的事件
中止logstash进程
下列因素影响关闭过程:
input插件缓慢的接收数据
缓慢的filter
output插件断开连接等待重连
这些情况使成功关闭logstash的服务不可预知。
logstash具有分析管道行为和插件停止的失效检测机制。这种机制周期性的产生有关内部事件队列和一系列繁忙工作线程的信息。
为了强制logstash停止,可以在启动时加上--allow-unsafe-shutdown参数。不过不推荐使用,以免丢失数据。
文章:http://www.ttlsa.com/elk/elk-logstash-structure/
---------------------------------------------------
ELK logstash处理流程
logstash处理事件有三个阶段:input ---> filter ---> output。input产生事件,事件是一个ruby对象
input 、filter 、output是插件
当前logstash线程模型是:
input threads | filter worker threads | output worker
input单线程
filter 多个worker线程 因为多个过滤器 filter workers默认是1,在启动logstash时,可以通过-w指定。
output 多个worker线程 因为多个输出地点 output当前工作模式是一个线程。output接收事件的顺序是以配置文件定义的输出顺序,output可以缓存事件,避免像elasticsearch停止响应而发生整个logstash罢工
logstash通常至少有3个线程,如果没有filter只有2个。一个input线程,一个filter worker线程,和一个output线程。
文章:http://www.ttlsa.com/elk/elk-logstash-process-pipeline/
---------------------------------------------------
ELK logstash 配置语法
数据类型
logstash支持的数据类型有:
array
数组可以是单个或者多个字符串值。
path => [ "/var/log/messages", "/var/log/*.log" ]
path => "/data/mysql/mysql.log"
如果指定了多次,追加数组。此实例path数组包含三个字符串元素。
boolean
布尔值必须是TRUE或者false。true和false不能有引号,从elasticsearch2.0开始里面存储的是1和0。
ssl_enable => true
bytes
指定字节单位。支持的单位有SI (k M G T P E Z Y) 和 Binary (Ki Mi Gi Ti Pi Ei Zi Yi)。Binary单位基于1024,SI单位基于1000。不区分大小写和忽略值与单位之间的空格。如果没有指定单位,默认是byte。
my_bytes => "1113" # 1113 bytes
my_bytes => "10MiB" # 10485760 bytes
my_bytes => "100kib" # 102400 bytes
my_bytes => "180 mb" # 180000000 bytes
Codec
logstash编码名称用来表示数据编码。用于input和output段。便于数据的处理。如果input和output使用合适的编码,就无需单独的filter对数据进行处理。
codec => "json"
hash
键值对,注意多个键值对用空格分隔,而不是逗号。
match => {
"field1" => "value1"
"field2" => "value2"
... }
number
必须是有效的数值,浮点数或者整数。
port => 33
password
一个单独的字符串。
my_password => "password"
path
一个代表有效的操作系统路径。
my_path => "/tmp/logstash"
string
name => "Hello world"
name => 'It\'s a beautiful day'
文章:http://www.ttlsa.com/elk/elk-logstash-configuration-syntax/
---------------------------------------------------
Logstash 日志管理工具
/usr/local/kibana/config/kibana.yml
您还可以修改default_route参数,默认打开logstash仪表板而不是Kibana欢迎页面:
default_route : '/dashboard/file/logstash.json',
通过web界面访问
文章:http://www.ttlsa.com/log-system/installing-logstash-on-rhel-and-centos/
---------------------------------------------------
Hello World
每位系统管理员都肯定写过很多类似这样的命令:cat randdata | awk '{print $2}' | sort | uniq -c | tee sortdata。这个管道符 | 可以算是 Linux 世界最伟大的发明之一(另一个是“一切皆文件”)。
Logstash 就像管道符一样!
你输入(就像命令行的 cat )数据,然后处理过滤(就像 awk 或者 uniq 之类)数据,最后输出(就像 tee )到其他地方。
当然实际上,Logstash 是用不同的线程来实现这些的。如果你运行 top 命令然后按下 H 键,你就可以看到下面这样的输出:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21401 root 16 0 1249m 303m 10m S 18.6 0.2 866:25.46 |worker
21467 root 15 0 1249m 303m 10m S 3.7 0.2 129:25.59 >elasticsearch.
21468 root 15 0 1249m 303m 10m S 3.7 0.2 128:53.39 >elasticsearch.
21400 root 15 0 1249m 303m 10m S 2.7 0.2 108:35.80
21470 root 15 0 1249m 303m 10m S 1.0 0.2 56:24.24 >elasticsearch.
小贴士:logstash 很温馨的给每个线程都取了名字,输入的叫xx,过滤的叫|xx
数据在线程之间以 事件 的形式流传。不要叫行,因为 logstash 可以处理多行事件。
Logstash 会给事件添加一些额外信息。最重要的就是 @timestamp,用来标记事件的发生时间。因为这个字段涉及到 Logstash 的内部流转,所以必须是一个 joda 对象,如果你尝试自己给一个字符串字段重命名为 @timestamp 的话,Logstash 会直接报错。所以,请使用 filters/date 插件 来管理这个特殊字段。
此外,大多数时候,还可以见到另外几个:
host 标记事件发生在哪里。
type 标记事件的唯一类型。
tags 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
你可以随意给事件添加字段或者从事件里删除字段。事实上事件就是一个 Ruby 对象,或者更简单的理解为就是一个哈希也行。
小贴士:每个 logstash 过滤插件,都会有四个方法叫 add_tag, remove_tag, add_field 和 remove_field。它们在插件过滤匹配成功时生效。
标准的 service 方式
采用 RPM、DEB 发行包安装的读者,推荐采用这种方式。发行包内,都自带有 sysV 或者 systemd 风格的启动程序/配置,你只需要直接使用即可。
以 RPM 为例,/etc/init.d/logstash 脚本中,会加载 /etc/init.d/functions 库文件,利用其中的 daemon 函数,将 logstash 进程作为后台程序运行。
所以,你只需把自己写好的配置文件,统一放在 /etc/logstash/ 目录下(注意目录下所有配置文件都应该是 .conf 结尾,且不能有其他文本文件存在。因为 logstash agent 启动的时候是读取全文件夹的),然后运行 service logstash start 命令即可。
Logstash 设计了自己的 DSL —— 有点像 Puppet 的 DSL,或许因为都是用 Ruby 语言写的吧
--config 或 -f
意即文件。真实运用中,我们会写很长的配置,甚至可能超过 shell 所能支持的 1024 个字符长度。所以我们必把配置固化到文件里,然后通过 bin/logstash -f agent.conf 这样的形式来运行。
此外,logstash 还提供一个方便我们规划和书写配置的小功能。你可以直接用 bin/logstash -f /etc/logstash.d/ 来运行。logstash 会自动读取 /etc/logstash.d/ 目录下所有的文本文件,然后在自己内存里拼接成一个完整的大配置文件,再去执行。
--configtest 或 -t
意即测试。用来测试 Logstash 读取到的配置文件语法是否能正常解析。Logstash 配置语法是用 grammar.treetop 定义的。尤其是使用了上一条提到的读取目录方式的读者,尤其要提前测试。
--log 或 -l
意即日志。Logstash 默认输出日志到标准错误。生产环境下你可以通过 bin/logstash -l logs/logstash.log 命令来统一存储日志。
--filterworkers 或 -w
意即工作线程。Logstash 会运行多个线程。你可以用 bin/logstash -w 5 这样的方式强制 Logstash 为过滤插件运行 5 个线程。
注意:Logstash目前还不支持输入插件的多线程。而输出插件的多线程需要在配置内部设置,这个命令行参数只是用来设置过滤插件的!
提示:Logstash 目前不支持对过滤器线程的监测管理。如果 filterworker 挂掉,Logstash 会处于一个无 filter 的僵死状态。这种情况在使用 filter/ruby 自己写代码时非常需要注意,很容易碰上 NoMethodError: undefined method '*' for nil:NilClass 错误。需要妥善处理,提前判断。
--pluginpath 或 -P
可以写自己的插件,然后用 bin/logstash --pluginpath /path/to/own/plugins 加载它们。
--verbose
输出一定的调试日志。
小贴士:如果你使用的 Logstash 版本低于 1.3.0,你只能用 bin/logstash -v 来代替。
--debug
输出更多的调试日志。
小贴士:如果你使用的 Logstash 版本低于 1.3.0,你只能用 bin/logstash -vv 来代替。
文章:http://udn.yyuap.com/doc/logstash-best-practice-cn/get_start/hello_world.html
http://udn.yyuap.com/doc/logstash-best-practice-cn/get_start/full_config.html
http://udn.yyuap.com/doc/logstash-best-practice-cn/get_start/full_config.html
---------------------------------------------------
---------------------------------------------------
读取文件(File)
start_position 仅在该文件从未被监听过的时候起作用。如果 sincedb 文件中已经有这个文件的 inode 记录了,那么 logstash 依然会从记录过的 pos 开始读取数据。所以重复测试的时候每回需要删除 sincedb 文件。
因为 windows 平台上没有 inode 的概念,Logstash 某些版本在 windows 平台上监听文件不是很靠谱。windows 平台上,推荐考虑使用 nxlog 作为收集端,参阅本书稍后章节。
文章:http://udn.yyuap.com/doc/logstash-best-practice-cn/input/file.html
---------------------------------------------------
编码插件(Codec)
Codec 是 logstash 从 1.3.0 版开始新引入的概念(Codec 来自 Coder/decoder 两个单词的首字母缩写)。
在此之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,这全是因为有了 codec 设置。
所以,这里需要纠正之前的一个概念。Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
事实上,我们在第一个 "hello world" 用例中就已经用过 codec 了 —— rubydebug 就是一种 codec!虽然它一般只会用在 stdout 插件中,作为配置测试或者调试的工具。
文章:http://udn.yyuap.com/doc/logstash-best-practice-cn/codec/index.html
---------------------------------------------------
时间处理(Date)
时区问题的解释
很多中国用户经常提一个问题:为什么 @timestamp 比我们早了 8 个小时?怎么修改成北京时间?
其实,Elasticsearch 内部,对时间类型字段,是统一采用 UTC 时间,存成 long 长整形数据的!对日志统一采用 UTC 时间存储,是国际安全/运维界的一个通识——欧美公司的服务器普遍广泛分布在多个时区里——不像中国,地域横跨五个时区却只用北京时间。
对于页面查看,ELK 的解决方案是在 Kibana 上,读取浏览器的当前时区,然后在页面上转换时间内容的显示。
所以,建议大家接受这种设定。否则,即便你用 .getLocalTime 修改,也还要面临在 Kibana 上反过去修改,以及 Elasticsearch 原有的 ["now-1h" TO "now"] 这种方便的搜索语句无法正常使用的尴尬。
以上,请读者自行斟酌。
文章:http://udn.yyuap.com/doc/logstash-best-practice-cn/filter/date.html
---------------------------------------------------
Rsyslog
Rsyslog 是 RHEL6 开始的默认系统 syslog 应用软件(当然,RHEL 自带的版本较低,实际官方稳定版本已经到 v8 了)。官网地址:http://www.rsyslog.com
目前 Rsyslog 本身也支持多种输入输出方式,内部逻辑判断和模板处理。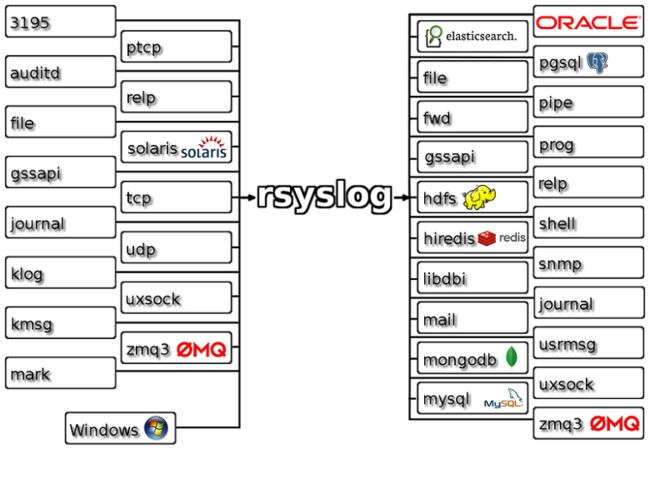
文章:http://udn.yyuap.com/doc/logstash-best-practice-cn/ecosystem/rsyslog.html
---------------------------------------------------
nginx从1.7开始,加入了syslog支持,淘宝的tengine则更早,这样,我们可以通过syslog直接发送日志
nginx的配置如下
acces_log syslog:server=unix:/data0/rsyslog/nginx.sock locallog;
或者直接发送给logstash机器
acces_log syslog:server=192.168.0.2:514,facility=local6,tag=nginx-acces,severity=info logstashlog;
UDP协议的514端口 rsyslog
默认情况下,nginx使用local7.info等级,以nginx为标签发送数据,注意使用syslog发送日志时,无法配置buffer=16K选项
nginx错误日志没有统一明确的分隔符也没有特别方便的正则模式 P62
Linux上的系统日志,即syslog的处理,对于windows平台,也有类似syslog的设计,叫eventlog P67
Nxlog配置注意 P67
1、ROOT位置必须是nxlog的实际安装路径
2、输入模块,在win2003及之前版本,不叫im_msvistalog而叫im_mseventlog
接收端设置 P68 如果使用nxlog,架构是 nxlog-》logstash agent-》redis-》logstash indexer——》elasticsearch-》kIbana
采集端是logstash,不需要特别设置,因为主要字段都已经生成,如果采集端是nxlog,那么我们需要把一些nxlog生成的字段转换为logstash风格
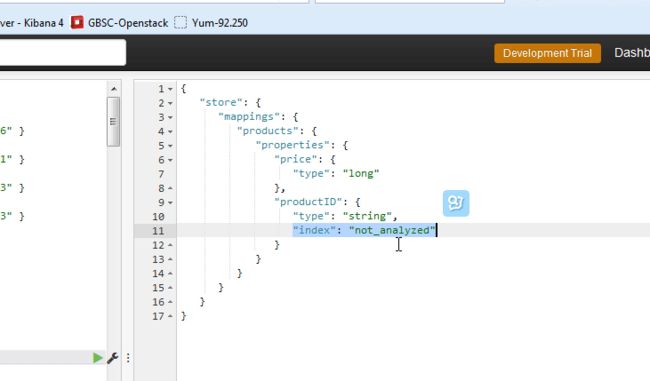
因为elasticsearch中默认按小写来检索,所以需要尽量把数据小写化,但是nxlog中,不单数据内容,字段名称也是大小写混用的
除非重新生成映射,设置字段的属性为 not_analyzed,宝哥的ELK视频
pv命令,pv命令的作用就是做实时的标准输入,标准输出监控 P78
我们这里就用他来监控标准输出
./bin/logstash -f generator_dots.conf |pv -abt >/dev/null
如果你在centos上通过yum安装的pv命令,版本太低,可能还不支持-a参数,单纯靠-bt参数看起来还是有点累
通过JVM平台上通用的JMX接口可以监控JVM的heap,threadcount等细节信息 P80
logstash是一个运行在JVM上的软件,也就意味着JMX这种对JVM的通用监控方式对logstash也是一样有效果的
有JMX以后,可以通过Jconsole界面查看,也可以通过zabbix等监控系统长期监控。
JMX启动参数方式 P82
zabbix里面提供了专门针对JMX的监控项
详细配置内容
https://www.zabbix.com/documentation/2.4/manual/config/items/itemtypes/jmx_monitoring
zabbix-server本身并不直接对JMX发起请求,而是单独有一个JavaGateway作为中间代理层角色。zabbix-server的java poller连接
zabbix-java-gateway,由zabbix-java-gateway去获取远程JMX信息,所以,在zabbix-web配置之前,需要先配置zabbix-server相关进程和设置
yum install -y zabbix-java-gateway
cat >> /etc/zabbix/zabbix-server.conf <
JavaGatewayPort=10052
StartJavaPollers=5
EOF
/etc/init.d/zabbix-java-gateway restart
/etc/init.d/zabbix-server restart
然后在zabbix-web上给运行logstash的主机的host界面添加JMX接口,port为定义的9001端口
最后添加item,type下拉框选择JMX agent,key文本框输入xxx
JMX有很多的监控项,可以通过Jconsole来查看
nxlog P99
在windows服务器上作为logstash的替代品运行
nxlog的windows安装文件下载地址
http://nxlog.co/products/nxlog-community-edition/download
nxlog默认配置文件位置在:C:\Program Files (x86)\nxlog
配置文件中有3个关键设置,分别是:input(日志输入端)、output(日志输出端)、route(绑定某输入到具体某输出)
logstash服务器IP:192.168.1.100
logstash配置文件
input {
tcp {
port => 514}
}
output {
elasticsearch {
host =>"127.0.0.1"
port =>"9200"
protocol =>"http"
}
}
nxlog配置文件
Module im_file
File "C:\\test\\\*.log"
SavePos TRUE
Path testfile => out
配置文件修改完后重启nxlog服务即可
logstash被elastic.co收购以后,就是把logstash的核心部分代码,尽量JVM通用化 P108
logstash运行在JVM上,包括了ruby代码和java代码
Linux系统有些重要日志不是以可读文本形式存在文件中,而是以二进制形式存放,比如utmp,wtmp,lastlog等 P119
elasticsearch是一个P2P类型(使用gossip协议)的分布式系统,所有请求都可以发送到集群内任意一台节点上 P140
组播方式 multicast
组播地址:224.2.2.4,端口54328
默认情况下,路由器和交换机都不开启组播信息传输
单播方式unicast
配置里提供几个节点的地址,以完成集群的发现
1、keepalived 默认需要使用D类多播地址224.0.0.18 进行心跳通信
2、keepalived 使用vrrp协议进行通信(协议号码为112)
-A INPUT -i eth1 -d 224.0.0.0/8 -j ACCEPT #224.0.0.0广播地址
搜索请求 P143
全文搜索
elasticsearch的搜索请求有简易语法和完整语法两种方式,简易语法是kIbana上最常用方式,一定要学会。
querystring语法
elasticsearch中的正则性能很差,而且支持的功能也不强大
脚本 P148
elasticsearch每分钟会扫描一次/etc/elasticsearch/scripts/目录,并尝试加载目录下的所有文件并加载
不要在该目录下添加任何脚本文件,以免出错
搜索引擎会使用倒排索引inverted index来映射单词到文档的ID号 P162
时间格式 P185
timestamp时间格式
nginx里叫$time_iso8601
rsyslog中叫date-rfc3339
elasticsearch中叫dateOptionalTime
线程池信息 P197
elasticsearch内部是保持着几个线程池的,不同的工作由不同的线程池负责
后续请求会暂时放到队列里,每个线程池的队列也有大小限制的,默认是100
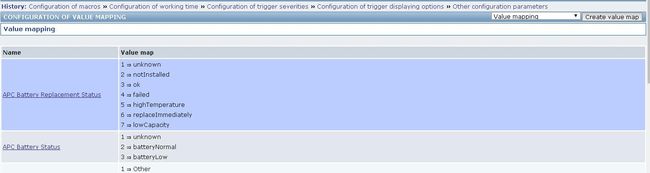
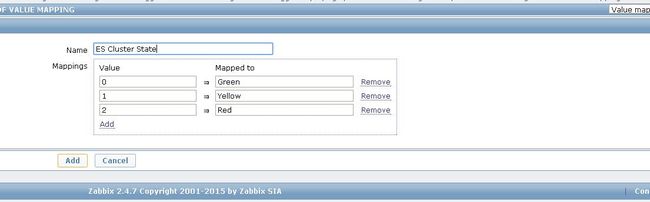
zabbix创建键值映射 P212
name:ES Cluster State
mappings
value mapped to
0 Green
1 Yellow
2 Red
创建数值映射,在模板中国,设置了集群状态的触发报警,没有映射的话,报警短信只有0,1,2数字不是很容易看懂
创建数值映射
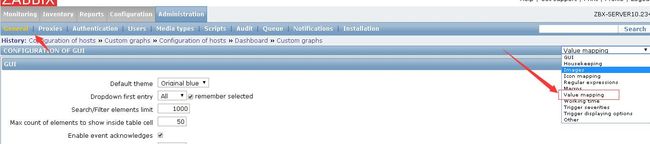
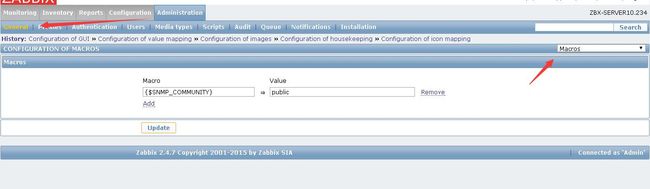
创建宏
packetbeat抓包分析 P220
packetbeat利用libpcap库抓取网络流量并识别其中的特定网络协议,自动按照协议规范,将网络流量划分为事件字段插入到es中
pcap包,安装libpcap包
pfring包,安装pfring包
yum install -y libpcap
宝哥的ELK视频 笔记
elasticsearch的API都是下划线开头
_update
_delete
_get
_mget
_bulk
_mapping
_all
如果文档里面没有定义_id,es会自动创建uuid
elasticsearch的内置关键字
_source, _version,_id
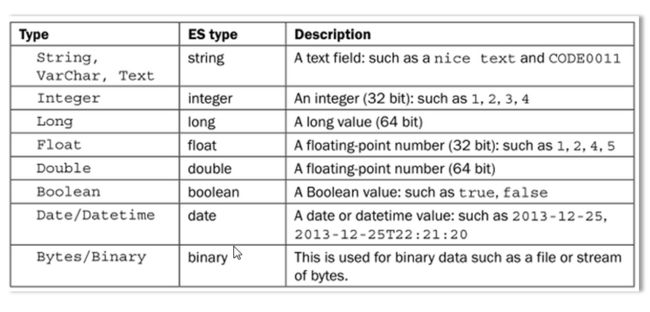
字段类型 《=》 elasticsearch 类型 映射
string ,varchar,text =》 string
integer =》integer
long =》long
float =》float
double =》double
boolean =》boolean
date ,datetime =》date
byte,binary =》binary
查询结果的分值最大是1
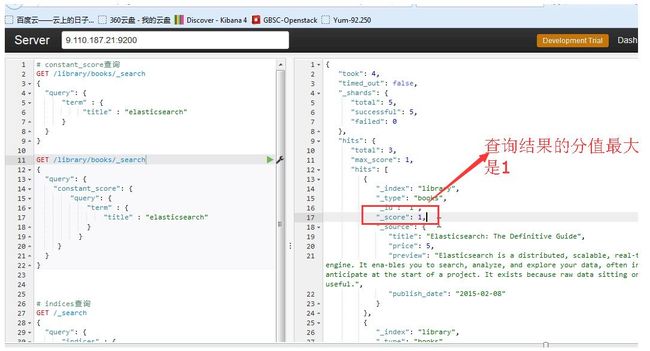
更新文档请求必须发给master节点,检索文档请求可以发给任何节点

单个ES节点最好32G内存,超过32G内存反而性能会下降

bigdesk和head插件的3个主要功能
1.看状态
2.管理方面操作,查询
3.邮件告警
elasticsearch的3种集群状态
green:各个分片正常
yellow:主分片正常,副本分片缺失,但是不影响使用
red:主分片缺失
logstash
File 文件输入
input {
file {
codec =>... #可选项, codec,默认是plain,可通过这个参数设置编码方式
discover_interval =>... #可选项,number,logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
exclude =>... #可选项,array,不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
sincedb_path =>... #可选项,string,如果你不想用默认的 $HOME/.sincedb(Windows 平台上在C:\Windows\System32\config\systemprofile\.sincedb),可以通过这个配置定义 sincedb 文件到其他位置。
sincedb_write_interval =>... #可选项, number,logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
stat_interval =>... #可选项, number, logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
start_position =>... #可选项, string , logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 “beginning”,logstash 进程就从头开始读取,有点类似cat,但是读到最后一行不会终止,而是继续变成 tail –F;默认值end
path =>... # 必选项, array ,定需处理的文件路径, 可以定义多个路径
tags =>... # 可选项, array,在数据处理过程中,由具体的插件来添加或者删除的标记
type =>... # 可选项, string,自定义将要处理事件类型,可以自己随便定义,比如处理的是linux的系统日志,可以定义为"syslog"
}
}
例子, 可定义多个file
input {
file {
path => ["/opt/elasticsearch1.7.1/logs/elasticsearch.log"]
type => “eslog"
start_position => "beginning"
}
file {
path=>"/var/log/apache2/access.log"
type=>"apache-access"
start_position => "end"
}
}
rubydebug 就是键值对的编码格式,输入到redis非常好,一般用来调试写在output区域查看调试结果,看grok匹配规则是否正确解释日志
output {
stdout {codec => rubydebug }
redis {
host => '10.11.30.40'
data_type => 'list'
key => 'logstash:redis'
}
}
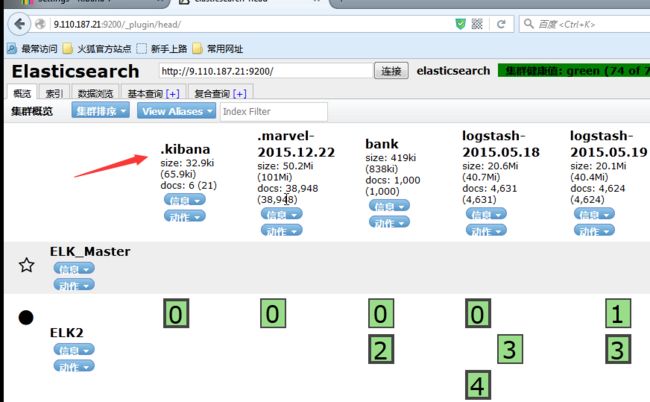
kIbana会自动在ES里面创建一个.kIbana索引保存kIbana界面上的一些设置
_source和_all的作用
_source的作用在store,_all的作用在index
Lucene中,每个field是需要设置store才能获取原文的;
ES中,单独使用_source存原文,各field默认"store":false
_all是为了响应不指明field的全文检索请求。
在script中,可以使用_source.field和doc['field']来获取内容,分别从_source store和inverted index里拿数据。
elasticsearch有两种数据结构
1、倒排索引
2、 field data (用于做字段聚合,group by)
disk-based field data(doc_values
将uninverted index的数组变成类似cassandra的列存储
views=[1,1000,5000,...]
变成
1
1000
5000
...
读取过程利用操作系统的VFS cache
即时监控工具插件
Kopf
Bigdesk(不支持2.x)
Marvel
site plugin
通过es的接口去获取静态web网站文件,利用es的接口打开静态网站,省得你自己去架设网站
这种插件统一叫site plugin,站点插件,依附于es
插件目录下会有一个_site目录,里面放网站文件
pwd
/usr/local/elasticsearch/plugins/kopf/_site
rsyslog跟logstash的原理一样,都是用sincedb来记录上次读取到文件的哪个位置
很多内核组件都需要调用rsyslog来记录日志,所以需要保证rsyslog进程不挂
ll /dev/log
srw-rw-rw- 1 root root 0 Nov 16 15:12 /dev/log
logstatsh2.2工作流程图
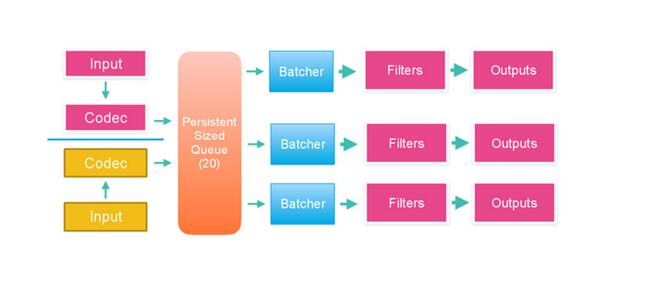
timestamp用的UTC时间

logstatsh里的每一个插件
file插件
input插件
codec插件
event插件
都对应着一个xxx.rb源代码文件,文件里有实现的源代码
------------------------------------------------------------------------------------
.kibana索引结构
1、Index patterns
2、saveObjects
{
saveSearch
saveVisualize
saveDashboard}
index pattern
曾经需要指定time-based,现在直接根据fieldstats接口自动确定是否有date类型字段
fields数组,记录每个field的 type, name, indexed, analyzed, doc_values, count, scripted
scripted field是动态提交的脚本内容。在indexpattern里还会多记录:script、lang、type。默认,type固定是number,lang是expression。
需要使用groovy的,可以手动修改ES索引数据。
search
每个_id是一个已保存搜索,记录title、column、sort、kibanaSavedObjectMeta。
kibanaSavedObjectMeta是一串searchSourceJSON。即搜索语句处理转换成的query JSON。
搜索框可以写querystring,也可以直接写JSON。
visualization
每个_id是一个已保存visualize,记录title、savedSearchId、kibanaSavedObjectMeta、visState。
visState里是一串aggregation的JSON。
savedSearchId是和本visualize关联的savedSearch的_id。
在savedSearchId空缺时,可以直接在visualize上定义搜索语句,依然叫kibanaSavedObjectMeta。内容还是一串searchSourceJSON。
dashboard
每个_id是一个已保存仪表盘,记录title、panelsJSON、kibanaSavedObjectMeta。
panelsJSON是一个数组,每个元素代表一个panel的定义。包括:
type: 具体加载的 app 类型,就默认来说,肯定就是 search 或者 visualization 之一。
id: 具体加载的 app 的保存 id。也就是上面说过的,它们在各自类型下的 _id 内容。
size_x: panel 的 X 轴长度。Kibana 4 采用 gridster 库做挂件的动态划分,默认为 3。
size_y: panel 的 Y 轴长度。默认为 2。
col: panel 的左边侧起始位置。Kibana 4 指定 col 最大为 12。每行第一个 panel 的 col 就是 1,假如它的 size_x 是 4,那么第二个 panel 的 col 就是 5。
row: panel 位于第几行。gridster 默认的 row 最大为 15。
--------------------------------------------------------------------------------------
经典时间序列数据库实现:rrdtool,很多老监控系统都基于rrdtool实现,elasticsearch也可以做时间序列数据库
Round Robin Database tool
1个rrd有多个rra;
rra存储CDP值,以及计算这个个CDP需要几个PDP和具体CF的信息;
每个step,传入的值叫PDP。
CF:average,min,max,last
不同DST下,收到的值跟写入的PDP不一致:
Values = 300, 600, 900, 1200
Step = 300 seconds
COUNTER = 1,1, 1,1
DERIVE = 1,1,1,1
ABSOLUTE = 1,2,3,4
GAUGE = 300,600,900,1200
graphite:python实现,提供HTTP接口,解决rrdtool必须固定间隔写入一次数据的问题;扩展方式太复杂。
influxdb:golang实现,部署简单,提供类SQL语法;集群方式不稳定。
opentsdb: open time serial database ,基于hbase,数据不归并全部保存;大范围读取性能极差。
监控
logstatsh output zabbix,nagios等等 logstatsh有各种各样的output插件 输出到zabbix ,nagios来做监控
在logstatsh里写dsl,if message =xx 各种正则匹配有error的message
监控nginx
logstatsh采集ngx_http_stub_status_module的nginx模块
./configure --prefix=/usr/local/nginx --with-http_gzip_static_module \
--with-http_stub_status_module --with-pcre
ngx_http_stub_status_module
业务监控系统的维度
1、终端用户体验监控——抓取端到端延迟、运行的正确率和呈现给终端用户的质量数据。在应用可用性方面,APM通过建立模拟终端用户行为的transaction来实现,
这是终端用户体验监控的第二个重点
2、应用拓扑发现和可视化——应用在执行过程中所涉及的软、硬件基础组件,数据在这些组件和应用间流动。这些节点和方向线,APM需要用拓扑图展示给用户。
3、用户定义的事务分析——用户在应用中的一系列行为,可以通过用户定义的事务来整合分析。用户向应用发起一个请求,就产生了一个事务。
4、应用组件的深度探究——用户在应用中的行为,会产生针对应用拓扑中涉及的软硬件组件的资源消耗。APM要针对这些包括服务器端组件在内的资源消耗进行细粒度的监控
5、ITOA——对下述技术的组合使用:复杂操作行为的处理;数据模式的发现和识别;非结构化文本的索引、搜索和推断;拓扑分析;多维度数据库的搜索和分析,用elk等技术收集日志
一个index下面就一个type,即使一个index下面有多个type其实也是所有type合并在一起的一张宽表
而实际物理存储的时候,index下面就是直接的分片直接的数据,而不是type,type的概念是ES刚出来的时候为了跟关系型数据库做对比而出来的概念
从ES2.0开始已经淡化了
ES默认是5个分片一个副本,副本的原理是:一个document过来,这个document会发到主分片和副本分片,然后主分片和副本分片可以理解为两个
独立的ES进程,处理发过来的document,当主分片挂掉了translog 会丢失5秒的数据 ,因为translog每隔5秒刷写到磁盘,ES挂掉重启之后需要从磁盘里的
translog文件里读取出日志,如果挂掉的时刻刚好在这5秒的间隔,那么主分片就会丢失5秒的数据,但是因为有副本分片,所以不用怕
副本分片的缺点,因为是独立的es进程,所以最好副本分片单独一台机器,这样就需要每个分片独立增加一台机器,默认5个分片就要增加5台机器
副本分片是一个document同时发到主分片和副本分片,而不是直接的块复制,把segment直接复制到副本分片,这样做的好处是,在segment合并的时候不需要再
把整个segment发送到副本分片,节省带宽和资源
f