internetreadfile读取数据长度为0_深度学习基础4:Tensorflow2.0数据集与神经网络的初探...


废话不多说,直接上货....
 -----思想和方法才是灵魂-----
前期提要:
深度学习开篇:Tensorflow2.0基础——从入门到放弃? 深度学习基础:数学分析基础与Tensorflow2.0回归模型(文章末尾可下载PDF书籍) 移动式安装包TensorFlow 2.0和PyTorch: 如何将配置好的深度学习环境移植到其他计算机上去? 解决安装AI算法库TensorFlow 2.0的最新入坑指南以及详细的安装教程【分别在linux和windows系统下安装】
-----思想和方法才是灵魂-----
前期提要:
深度学习开篇:Tensorflow2.0基础——从入门到放弃? 深度学习基础:数学分析基础与Tensorflow2.0回归模型(文章末尾可下载PDF书籍) 移动式安装包TensorFlow 2.0和PyTorch: 如何将配置好的深度学习环境移植到其他计算机上去? 解决安装AI算法库TensorFlow 2.0的最新入坑指南以及详细的安装教程【分别在linux和windows系统下安装】

本文要解决的问题是,将手写数字的灰度图像(28 像素×28 像素)划分到 10 个类别 中(0~9)。我们将使用 MNIST 数据集,它是机器学习领域的一个经典数据集,其历史几乎和这 个领域一样长,而且已被人们深入研究。这个数据集包含 60 000 张训练图像和 10 000 张测试图 像,由美国国家标准与技术研究院(National Institute of Standards and Technology,即 MNIST 中 的 NIST)在 20 世纪 80 年代收集得到。
(Mixed National Institute of Standards and Technology database)
如果你是第一次接触深度学习神经网络,那么对MNIST数据集的分析和认识可看作你在深度学习领域的“Hello World”,同时你将用它来验证你的算法是否按预期运行。
数据集网站为:http://yann.lecun.com/exdb/mnist/


数据集的一般字样
由于TensorFlow已经自带集成下载数据集的AIP接口,以及深度学习Keras框架的配合使用,因此这里不直接下载数据集,只需导入
#TensorFlow 1.x版本的导入方法# from tensorflow.examples.tutorials.mnist import input_data# mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)执行结果:说明数据集已载入到指定文件目录
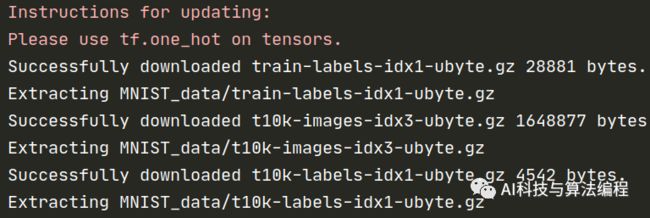
如果上述代码执行没有自动下载数据集,可根据终端提示,进入指定位置找到mnist.py文件查看是怎么调用的。
注意:
运行上面的代码,会自动下载数据集并将文件解压到当前代码所在同级自录下的 MNIST_data 文件夹下。 此外,代码中的one hot=True ,表示将样本标签转化为one hot 编码。这里用一个例子来理解one hot 编码:假设样本共10 类,即:0 的one_hot 为1000000000、1 的one_hot 为0100000000、2 的one hot 为0010000000、3 的one hot 为0001000000 ..…·依 此类推到9,直到只有一个位为1 , 1 所在的位置就代表着第几类。
1、TensorFlow 2.x版本载入数据集方式
由于我使用的是tf-gpu 2.x版本,所以上面的数据加载代码时报错,于是解决的方法是使用tensorflow2.0的数据集集成到keras高级接口之中,使用如下代码一般都能下载
mint=tf.keras.datasets.mnist(x_,y_),(x_1,y_1)=mint.load_data() 这是提一下,如果你在Windows和ubuntu下没有Keras模块库,可使用下面的命令在终端安装:(这是我认为最快的安装命令了:香啊!)
pip install --index-url https://pypi.douban.com/simple keras
下面直接打印数据集中的一张图片:
# from tensorflow.examples.tutorials.mnist import input_data# mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)import osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'import matplotlib.pyplot as pltimport tensorflow as tfprint(tf.__version__)mint=tf.keras.datasets.mnist(x_,y_),(x_1,y_1)=mint.load_data()plt.imshow(x_[2], cmap="binary")plt.show()执行结果:数字4
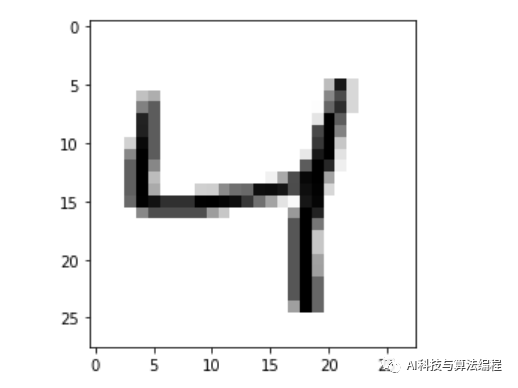
2、TensorFlow 1.x版本载入数据集方式
加载方法上面已经说过,下面开始分析得到一个数据集后的首要任务是将数据可视化,从感官上了解数据的具体情况
#保证输出不出现2020的干扰import osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'#载入数据集from tensorflow.examples.tutorials.mnist import input_data# 存储路径mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)# 训练集train_images = mnist.train.images # 数据集图片train_labels = mnist.train.labels# 验证集validation_images = mnist.validation.imagesvalidation_labels = mnist.validation.labels# 测试集test_images = mnist.test.imagestest_labels = mnist.test.labels执行该代码读取数据集获得新的数据集,此时返回了的内容在mnist.py文件内容中:
可以发现是训练集、验证集、测试集
return base.Datasets(train=train, validation=validation, test=test)2.1、下面先打印数据的个数(长度):
print(len(train_images))print(len(validation_images))print(len(test_images))执行结果:
550005000100002.2、输出数据集中的第一个数据点的形状
im = train_images[0]print(im.shape)执行结果:说明这张图片是由784个数据像素点构成
(784,) # 一维的像素点2.3、输出数据类型格式
print(type(train_images))print(type(validation_images))print(type(test_images))执行结果:说明是numpy格式,因此后面在处理的时候可用np进行分析
2.4、输出最值:由于已经知道了数据类型,因此可求出最值
print(np.min(im),np.max(im))执行结果:数字在0-1区间的,这是被标准化或者是归一化处理得了
0.0 0.99607852.5、打印第11个数据点的图片
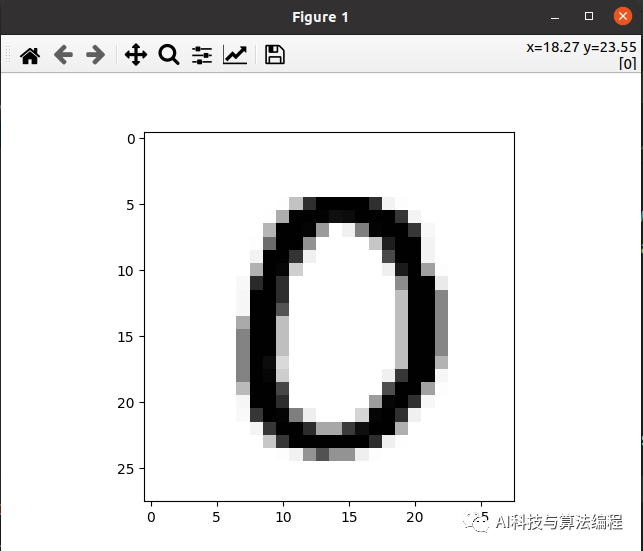
import matplotlib.pyplot as pltim = train_images[10]# print(im.shape)# print(np.min(im),np.max(im))im = im.reshape(28, 28)print(im.shape)plt.imshow(im, cmap='Greys')plt.show()执行结果:好像是数字0
2.6、标签值的数据和图片的数据的索引一样,则图片数字的识别结果相同:
print(mnist.train.labels[10])执行结果(one-hot encoding的编码):
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]或者
im = train_images[10]label = train_labels[10]print(label)执行结果:
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]由于数据集已经经过预处理,因此我们可以将
one_hot=True 修改为 one_hot=False再次运行上面的代码,结果为
0.说明图片与数值对应成功。
关于类和标签的说明:在机器学习中,分类问题中的某个类别叫作类(class)。数据点叫作样本(sample)。某个样本对应的类叫作标签(label)
2.7、指定打印同一个数值0的前25张图片
# 训练图片的索引indexs = np.where(train_labels == 0)# 打印25个,长度是5fig, ax = plt.subplots( nrows=5, ncols=5, sharex='all', sharey='all', )# 索引的个矩阵,所以indexs[0][i]ax = ax.flatten()for i in range(25): img = train_images[indexs[0][i]].reshape(28, 28) ax[i].imshow(img, cmap='Greys', interpolation='nearest')#去掉坐标轴的表示ax[0].set_xticks([])ax[0].set_yticks([])# 让25张图片自动排列plt.tight_layout()plt.show()执行结果:
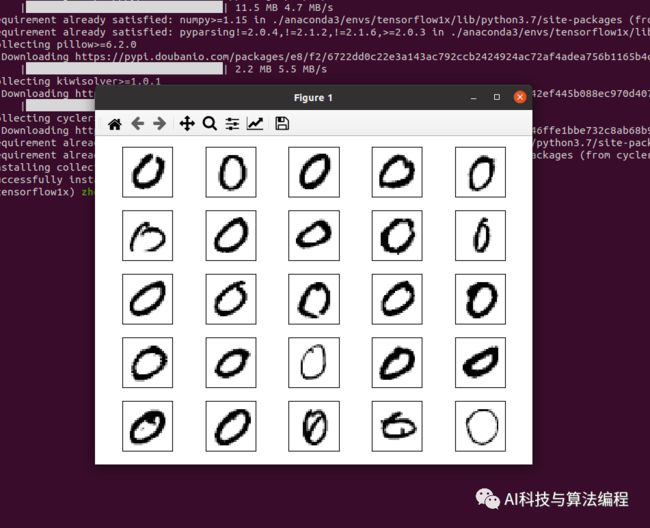
2.8、打印前25张图片
只需修改上述代码的一行:
img = train_images[i].reshape(28, 28)执行结果:可以发现第11个的确是0
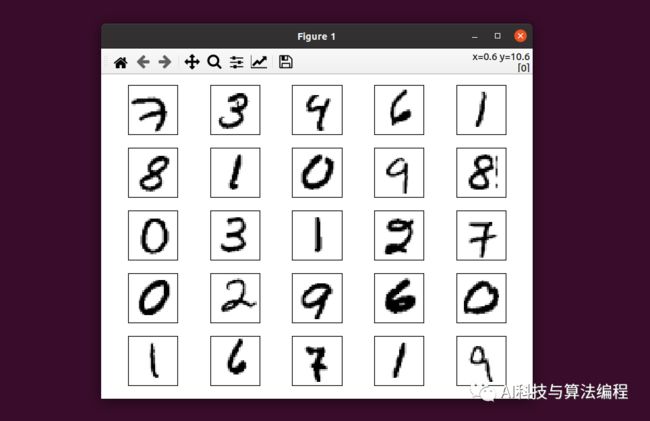
类似地,可打印更多:
indexs = np.where(train_labels == 0)fig, ax = plt.subplots( nrows=10, ncols=10, sharex='all', sharey='all', )ax = ax.flatten()for i in range(100): # 打印100张图片 img = train_images[50+i].reshape(28, 28) # 从第50张图片开始打印 ax[i].imshow(img, cmap='Greys', interpolation='nearest')ax[0].set_xticks([])ax[0].set_yticks([])plt.tight_layout()plt.show()执行结果:
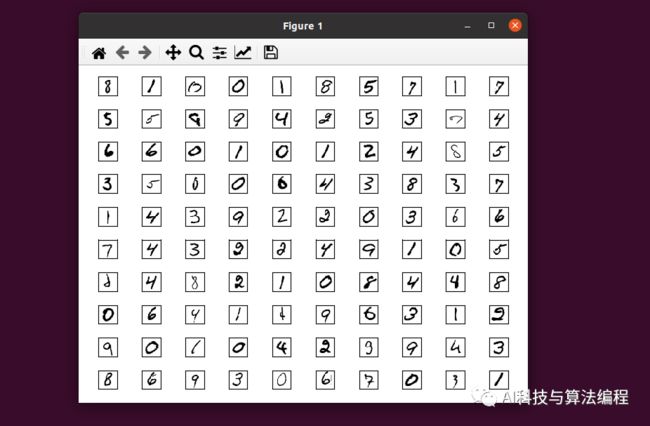
2.9、可视化数据集从0-9的分布
执行结果:
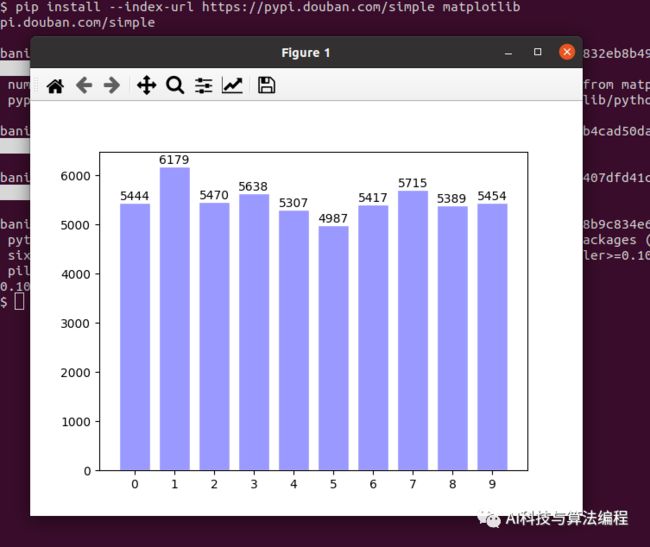
3.0、备注说明:
train_images 和 train_labels 组成了训练集(training set),模型将从这些数据中进行学习。然后在测试集(test set,即 test_images 和 test_labels)上对模型进行测试。图像被编码为 Numpy 数组,而标签是数字数组,取值范围为 0~9。图像和标签一一对应。我们来看一下训练数据:
>>> train_images.shape(60000, 28, 28)>>> len(train_labels)60000>>> train_labelsarray([5, 0, 4, ..., 5, 6, 8], dtype=uint8)下面是测试数据:
>>> test_images.shape(10000, 28, 28)>>> len(test_labels)10000>>> test_labelsarray([7, 2, 1, ..., 4, 5, 6], dtype=uint8)神经网络的核心组件是层(layer),它是一种数据处理模块,你可以将它看成数据过滤器。进去一些数据,出来的数据变得更加有用。具体来说,层从输入数据中提取表示——我们期望这种表示有助于解决手头的问题。大多数深度学习都是将简单的层链接起来,从而实现渐进式的数据蒸馏(data distillation)。深度学习模型就像是数据处理的筛子,包含一系列越来越精细的数据过滤器(即层) 。
值得一提的是,训练神经网络主要围绕以下四个方面:
层,多个层组合成网络(或模型)。
输入数据和相应的目标。
损失函数,即用于学习的反馈信号。
优化器,决定学习过程如何进行。
你可以将这四者的关系可视化,下图所示:多个层链接在一起组成了网络,将输入数据映射为预测值。然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度。优化器使用这个损失值来更新网络的权重。
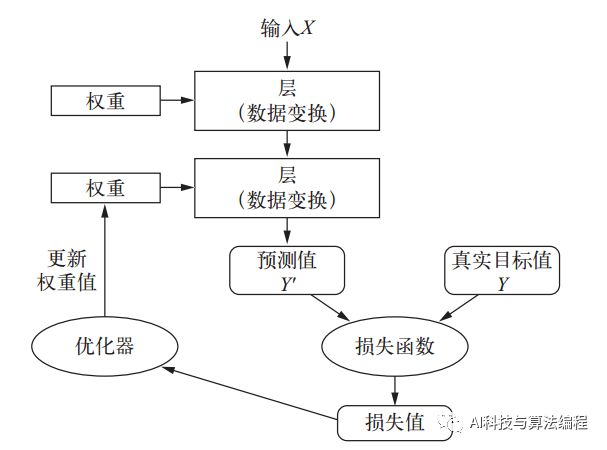
参考文献
https://mp.weixin.qq.com/s?__biz=MzIwNzUwOTY1Nw==&tempkey=MTA3Ml9NV3lJZGNqWWY5UHk0M0lXaWVLeF94Z0VfVUhEeVBWQnJoMmxITTJDdzJYX2h3RV9HZU1DYWZQVVYtZVpNalR4Y3prUmVzV1ZZRHp5U0ItYUhTcGp4MzdvV2E0d2s3MWx6dWNla1ZuWGJxRmxMSDlmSDBsX2hsVkR0MElTbGVHM0hHdkdmT2VlSGkzS3lQZV9lSmRMbEx5VExRYXRVTHVzWkxVTVRBfn4%3D&chksm=171012c420679bd2b85ab5b341e9e944a1eb8a6440a13c47daaa5c625fb729a3214e5f174ea9&__mpa_temp_link_flag=1&token=1243895064#rdhttp://yann.lecun.com/exdb/mnist/https://matplotlib.org/gallery/index.htmlhttps://drivingc.com/p/5ad8688f9718002c1e409808https://blog.csdn.net/qq_43060552/article/details/103189040
