AI上推荐 之 xDeepFM模型(显隐性高阶特征交互的组合策略)
1. 写在前面
这篇文章整理模型,不再使用华丽的前言外表, 也跳出了王喆老师书上的推荐模型, 从前面的各个模型的基础上开始尝试推荐系统领域各个方面的一些新探索和成果了, 后面的这个系列打算采用“小步快跑”的方式,每次研究一个模型,主要是基于原论文和一些不错的博客,然后通过一篇文章把细节进行梳理,这样既兼顾论文总结,也能保持短期更新,逼迫自己快速学习和输出。 但是为了整理清楚每篇论文里面的细节和完成知识的串联,篇幅上可能依然不会减太少,当然,也是视情况而定, 重要的模型多整理(理论和代码), 不太重要的简单总结啦。下面开始
今天介绍的这个模型,叫做xDeepFM(eXtreme DeepFM),这是2018年中科大联合微软在KDD上提出的一个模型,在DeepFM的前面加了一个eXtreme,看这个名字,貌似是DeepFM的加强版,但当我仔细的读完原文之后才发现,如果论血缘关系,这个模型应该离着DCN更近一些,这个模型的改进出发点依然是如何更好的学习特征之间的高阶交互作用,从而挖掘更多的交互信息。而基于这样的动机,作者提出了又一个更powerful的网络来完成特征间的高阶显性交互(DCN的话是一个交叉网络), 这个网络叫做CIN(Compressed Interaction Network),这个网络也是xDeepFM的亮点或者核心创新点了(牛x的地方), 有了这个网络才使得这里的"Deep"变得名副其实。而xDeepFM的模型架构依然是w&D结构,更好的理解方式就是用这个CIN网络代替了DCN里面的Cross Network, 这样使得该网络同时能够显性和隐性的学习特征的高阶交互(显性由CIN完成,隐性由DNN完成)。 那么为啥需要同时学习特征的显性和隐性高阶交互呢? 为啥会用CIN代替Cross Network呢? CIN到底有什么更加强大之处呢? xDeepFM与之前的DeepFM以及FM的关系是怎样的呢? 这些问题都会在后面一一揭晓。
这篇文章的逻辑和前面一样,首先依然是介绍xDeepFM的理论部分和论文里面的细节,我觉得这篇文章的创新思路还是非常厉害的,也就是CIN的结构,在里面是会看到RNN和CNN的身影的,又会看到Cross Network的身影。所以这个结构我这次也是花了一些时间去理解,花了一些时间找解读文章看, 但讲真,解读文章真没有论文里面讲的清晰,所以我这次整理也是完全基于原论文加上我自己的理解进行解读。 当然,我水平有限,难免有理解不到位的地方,如果发现有错,也麻烦各位大佬帮我指出来呀。这样优秀的一个模型,不管是工业上还是面试里面,也是非常喜欢用或者考的内容,所以后面依然参考deepctr的代码,进行简化版的复现,重点看看CIN结构的实现过程。最后就是简单介绍和小总。
这篇文章依然比较长,首先是CIN结构本身可能比较难理解,前面需要一定的铺垫任务,比如一些概念(显隐性交叉,bit-wise和vector-wise等), 一些基础模型(FM,FNN,PNN,DNN等),DCN的Cross Network,有了这些铺垫后再理解CIN以及操作会简单些,而CIN本身运算也可能比较复杂,再加上里面时间复杂度和空间复杂度那块的分析,还有后面实验的各个小细节以最后论文还帮助我们串联了各种模型,我想在这篇文章中都整理一下。 再加上模型的复现内容,所以篇幅上还是会很长,各取所需吧还是哈哈。当然这篇文章的重点还是在CIN,这个也是面试里面非常喜欢问的点。
PS: 读这篇文章之前,建议先阅读我之前整理的AI上推荐 之 Wide&Deep与Deep&Cross模型, 因为上面也说了,xDeepFM的核心是CIN网络,而这个网络的改进动机是有Deep&Cross模型里面的Cross网络的不足, 所以有必要了解下DCN网络的交叉网络的原理,当然我这里会简介,但应该不会太详细。
大纲如下:
- xDeepFM? 我们需要先了解这些
- xDeepFM模型的理论以及论文细节
- xDeepFM模型的代码复现及重要结构解释
- 小总
Ok, let’s go!
2. xDeepFM? 我们需要先了解这些
2.1 简介与进化动机
再具体介绍xDeepFM之前,想先整理点铺垫的知识,也是以前的一些内容,是基于原论文的Introduction部分摘抄了一些,算是对前面内容的一些回顾吧,因为这段时间一直忙着找实习,也已经好久没有写这个系列的相关文章了。所以多少还是有点风格和知识上的遗忘哈哈。
首先是在推荐系统里面, 一般原始的特征很难让模型学习到隐藏在数据背后的规律,因为推荐系统中的原始特征往往非常稀疏,且维度非常高。所以如果想得到一个好的推荐系统,我们必须尽可能的制作更多的特征出来,而特征组合往往是比较好的方式,毕竟特征一般都不是独立存在的,那么特征究竟怎么组合呢? 这是一个比较值得研究的难题,并且好多学者在这上面也下足了工夫。 如果你说,特征组合是啥来? 不太清楚了呀,那么文章中这个例子正好能解决你的疑问

起初的时候,是人工特征组合,这个往往在作比赛的时候会遇到,就是特征工程里面自己进行某些特征的交叉与组合来生成新的特征。 这样的方式会有几个问题,作者在论文里面总结了:
- 一般需要一些经验和时间才会得到比较好的特征组合,也就是找这样的组合对于人来说有着非常高的要求,无脑组合不可取 — 需要一定的经验,耗费大量的时间
- 由于推荐系统中数据的维度规模太大了,如果人工进行组合,根本就不太可能实现 — 特征过多,无法全面顾及特征的组合
- 手工制作的特征也没有一定的泛化能力,而恰巧推荐系统中的数据往往又非常稀疏 — 手工组合无泛化能力
所以,让模型自动的进行特征交叉组合探索成了推荐模型里面的比较重要的一个任务,还记得吗? 这个也是模型进化的方向之一,之所以从前面进行引出,是因为本质上这篇的主角xDeepFM也是从这个方向上进行的探索, 那么既然又探索,那也说明了前面模型在这方面还有一定的问题,那么我们就来再综合理一理。
- FM模型: 这个模型能够自动学习特征之间的两两交叉,并且比较厉害的地方就是用特征的隐向量内积去表示两两交叉后特征的重要程度,这使得模型在学习交互信息的同时,也让模型有了一定的泛化能力。 But,这个模型也有缺点,首先一般是只能应付特征的两两交叉,再高阶一点的交叉虽然行,但计算复杂,并且作者在论文中提到了高阶交叉的FM模型是不管有用还是无用的交叉都建模,这往往会带来一定的噪声。
- DNN模型: 这个非常熟悉了,深度学习到来之后,推荐模型的演化都朝着DNN的时代去了,原因之一就是因为DNN的多层神经网络可以比较出色的完成特征之间的高阶交互,只需要增加网络的层数,就可以轻松的学习交互,这是DNN的优势所在。 比较有代表的模型PNN,DeepCrossing模型等。 But, DNN并不是非常可靠,有下面几个问题。
- 首先,DNN的这种特征交互是隐性的,后面会具体说显隐性交互区别,但直观上理解,这种隐性交互我们是无法看到到底特征之间是怎么交互的,具体交互到了几阶,这些都是带有一定的不可解释性。
- 其次,DNN是bit-wise层级的交叉,关于bit-wise,后面会说,这种方式论文里面说一个embedding向量里面的各个元素也会相互影响, 这样我觉得在这里带来的一个问题就是可能会发生过拟合。 因为我们知道embedding向量的表示方法就是想从不同的角度去看待某个商品(比如颜色,价格,质地等),当然embedding各个维度是无可解释性的,但我们还是希望这各个维度更加独立一点好,也就是相关性不那么大为妙,这样的话往往能更加表示出各个商品的区别来。 但如果这各个维度上的元素也互相影响了(神经网络会把这个也学习进去), 那过拟合的风险会变大。当然,上面这个是我自己的感觉, 原作者只是给了这样一段:

也就是DNN是否能够真正的有效学习特征之间的高阶交互是个谜! - DNN还存在的问题就是学习高阶交互或许是可能,但没法再兼顾低阶交互,也就是记忆能力,所以后面w&D架构在成为了主流架构。
- Wide&Deep, DeepFM模型: 这两个模型是既有DNN的深度,也有FM或者传统模型的广度,兼顾记忆能力和泛化能力,也是后面的主流模型。但依然有不足之处,wide&Deep的话不用多讲,首先逻辑回归(宽度部分)仍然需要人工特征交叉,而深度部分的高阶交叉又是一个谜。 DeepFM的话是FM和DNN的组合,用FM替代了逻辑回归,这样至少是模型的自动交叉特征,结合了FM的二阶以及DNN的高阶交叉能力。 但如果DNN这块高度交叉是个谜的话,就有点玄乎了。
- DCN网络: 这个模型也是w&D架构,不过宽度那部分使用了一个Cross Network,这个网络的奇妙之处,就是扩展了FM这种只能显性交叉的二阶的模型, 通过交叉网络能真正的显性的进行特征间的高阶交叉。 具体结构后面还会在复习,毕竟这次的xdeepFM主要是在Cross Network的基础上进行的再升级,这也是为啥说论血缘关系,xdeepFM离DCN更近一些的原因。那么Cross network有啥问题呢? 这个想放在后面的2.4去说了,这样能更好的引出本篇主角来。
通过上面的一个梳理,首先是回忆起了前面这几个模型的发展脉络, 其次差不多也能明白xDeepFM到底再干个什么事情了,或者要解决啥问题了,xDeepFM其实简单的说,依然是研究如何自动的进行特征之间的交叉组合,以让模型学习的更好。 从上面这段梳理中,我们至少要得到3个重要信息:
- 推荐模型如何有效的学习特征的交叉组合信息是非常重要的, 而原始的人工特征交叉组合不可取,如何让模型自动的学习交叉组合信息就变得非常关键
- 有的模型(FM)可以显性的交叉特征, 但往往没法高阶,只能到二阶
- 有的模型(DNN)可以进行高阶的特征交互,但往往是以一种无法解释的方式(隐性高阶交互),并且是bit-wise的形式,能不能真正的学习到高阶交互其实是个谜。
- 有的模型(DCN)探索了显性的高阶交叉特征,但仍然存在一些问题。
所以xDeepFM的改进动机来了: 更有效的高阶显性交叉特征(CIN),更高的泛化能力(vector-wise), 显性和隐性高阶特征的组合(CIN+DNN), 这就是xDeepFM了, 而这里面的关键,就是CIN网络了。在这之前,还是先把准备工作做足。
2.2 Embedding Layer
这个是为了回顾一下,简单一说,我们拿到的数据往往会有连续型数据和离散型或者叫类别型数据之分。 如果是连续型数据,那个不用多说,一般会归一化或者标准化处理,当然还可能进行一定的非线性化操作,就算处理完了。 而类别型数据,一般需要先LabelEncoder,转成类别型编码,然后再one-hot转成0或者1的编码格式。 比如论文里面的这个例子:

这样的数据往往是高维稀疏的,不利于模型的学习,所以往往在这样数据之后,加一个embedding层,把数据转成低维稠密的向量表示。 关于embedding的原理这里不说了,但这里要注意一个细节,就是如果某个特征每个样本只有一种取值,也就是one-hot里面只有一个地方是1,比如前面3个field。这时候,可以直接拿1所在位置的embedding当做此时类别特征的embedding向量。 但是如果某个特征域每个样本好多种取值,比如interests这个,有好几个1的这种,那么就拿到1所在位置的embedding向量之后求和来代表该类别特征的embedding。这样,经过embedding层之后,我们得到的数据成下面这样了:
e = [ e 1 , e 2 , … , e m ] \mathbf{e}=\left[\mathbf{e}_{1}, \mathbf{e}_{2}, \ldots, \mathbf{e}_{m}\right] e=[e1,e2,…,em]
这个应该比较好理解, e i e_i ei表示的一个向量,一般是 D D D维的(隐向量的维度), 那么假设 m m m表示特征域的个数,那么此时的 e \mathbf{e} e是 m × D m\times D m×D的矩阵。

2.3 bit-wise VS vector-wise
这是特征交互的两种方式,需要了解下,因为论文里面的CIN结构是在vector-wise上完成特征交互的, 这里拿从网上找到的一个例子来解释概念。
假设隐向量的维度是3维, 如果两个特征对应的向量分别是 ( a 1 , b 1 , c 1 ) (a_1, b_1, c_1) (a1,b1,c1)和 ( a 2 , b 2 , c 2 ) (a_2,b_2, c_2) (a2,b2,c2)
- bit-wise = element-wise
在进行交互时,交互的形式类似于 f ( w 1 a 1 a 2 , w 2 b 1 b 2 , w 3 c 1 c 2 ) f(w_1a_1a_2, w_2b_1b_2,w_3c_1c_2) f(w1a1a2,w2b1b2,w3c1c2),此时我们认为特征交互发生在元素级别上,bit-wise的交互是以bit为最小单元的,也就是向量的每一位上交互,且学习一个 w i w_i wi - vector-wise
如果特征交互形式类似于 f ( w ( a 1 a 2 , b 1 b 2 , c 1 c 2 ) ) f(w(a_1a_2,b_1b_2,c_1c_2)) f(w(a1a2,b1b2,c1c2)), 我们认为特征交互发生在向量级别上,vector-wise交互是以整个向量为最小单元的,向量层级的交互,为交互完的向量学习一个统一的 w w w
这个一直没弄明白后者为什么会比前者好,我也在讨论群里问过这个问题,下面是得到的一个伙伴的想法:

对于这个问题有想法的伙伴,也欢迎在下面评论,我自己的想法是bit-wise看上面的定义,仿佛是在元素的级别交叉,然后学习权重, 而vector-wise是在向量的级别交叉,然后学习统一权重,bit-wise具体到了元素级别上,虽然可能学习的更加细致,但这样应该会增加过拟合的风险,失去一定的泛化能力,再联想作者在论文里面解释的bit-wise:

更觉得这个想法会有一定的合理性,就想我在DNN那里解释这个一样,把细节学的太细,就看不到整体了,佛曰:着相了哈哈。如果再联想下FM的设计初衷,FM是一个vector-wise的模型,它进行了显性的二阶特征交叉,却是embedding级别的交互,这样的好处是有一定的泛化能力到看不见的特征交互。 emmm, 我在后面整理Cross Network问题的时候,突然悟了一下, bit-wise最大的问题其实在于违背了特征交互的初衷, 我们本意上其实是让模型学习特征之间的交互,放到embedding的角度,也理应是embedding与embedding的相关作用交互, 但bit-wise已经没有了embedding的概念,以bit为最细粒度进行学习, 这里面既有不同embedding的bit交互,也有同一embedding的bit交互,已经意识不到Field vector的概念。 具体可以看Cross Network那里的解释,分析了Cross Network之后,可能会更好理解些。
这个问题最好是先这样理解或者自己思考下,因为xDeepFM的一个挺大的亮点就是保留了FM的这种vector-wise的特征交互模式,也是作者一直强调的,vector-wise应该是要比bit-wise要好的,否则作者就不会强调Cross Network的弊端之一就是bit-wise,而改进的方法就是设计了CIN,用的是vector-wise。
2.4 高阶隐性特征交互(DNN) VS 高阶显性特征交互(Cross Network)
2.4.1 DNN的隐性高阶交互
DNN非常擅长学习特征之间的高阶交互信息,但是隐性的,这个比较好理解了,前面也提到过:
x 1 = σ ( W ( 1 ) e + b 1 ) x k = σ ( W ( k ) x ( k − 1 ) + b k ) \begin{array}{c} \mathbf{x}^{1}=\sigma\left(\mathbf{W}^{(1)} \mathbf{e}+\mathbf{b}^{1}\right) \\ \mathbf{x}^{k}=\sigma\left(\mathbf{W}^{(k)} \mathbf{x}^{(k-1)}+\mathbf{b}^{k}\right) \end{array} x1=σ(W(1)e+b1)xk=σ(W(k)x(k−1)+bk)
但是问题的话,前面也剖析过了, 简单总结:
- DNN 是一种隐性的方式学习特征交互, 但这种交互是不可解释性的, 没法看出究竟是学习了几阶的特征交互
- DNN是在bit-wise层级上学习的特征交互, 这个不同于传统的FM的vector-wise
- DNN是否能有效的学习高阶特征交互是个迷,其实不知道学习了多少重要的高阶交互,哪些高阶交互会有作用,高阶到了几阶等, 如果用的话,只能靠玄学二字来解释
2.4.2 Cross Network的显性高阶交互
谈到显性高阶交互,这里就必须先分析一下我们大名鼎鼎的DCN网络的Cross Network了, 关于这个模型,我在AI上推荐 之 Wide&Deep与Deep&Cross模型文章中进行了一些剖析,这里再复习的话我又参考了一个大佬的文章,因为再把我之前的拿过来感觉没有啥意思,重新再阅读别人的文章很可能会再get新的点,于是乎还真的学习到了新东西,具体链接放到了下面。 这里我们重温下Cross Network,看看到底啥子叫显性高阶交互。再根据论文看看这样子的交互有啥问题。
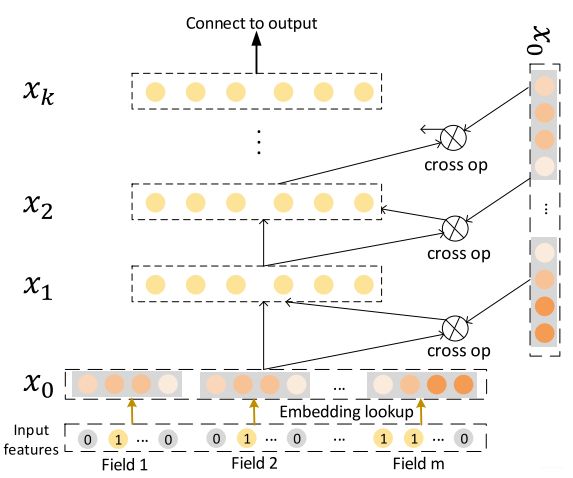
这里的输入 x 0 x_0 x0需要提醒下,首先对于离散的特征,需要进行embedding, 对于multi-hot的离散变量, 需要embedding之后再做一个简单的average pooling, 而dense特征,归一化, 然后和embedding的特征拼接到一块作为Cross层和Deep层的输入,也就是Dense特征会在这里进行拼接。 下面回顾Cross Layer。
Cross的目的是一一种显性、可控且高效的方式,自动构造有限高阶交叉特征。 具体的公式如下:
x l + 1 = x 0 x l T w l + b l + x l = f ( x l , w l , b l ) + x l \boldsymbol{x}_{l+1}=\boldsymbol{x}_{0} \boldsymbol{x}_{l}^{T} \boldsymbol{w}_{l}+\boldsymbol{b}_{l}+\boldsymbol{x}_{l}=f\left(\boldsymbol{x}_{l}, \boldsymbol{w}_{l}, \boldsymbol{b}_{l}\right)+\boldsymbol{x}_{l} xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
其中 x l + 1 , x l , x 0 ∈ R d \boldsymbol{x}_{l+1}, \boldsymbol{x}_{l}, \boldsymbol{x}_{0} \in \mathbb{R}^{d} xl+1,xl,x0∈Rd。有图有真相:

Cross Layer的巧妙之处全部体现在上面的公式,下面放张图是为了更好的理解,这里我们回顾一些细节。
- 每层的神经元个数相同,都等于输入 x 0 \boldsymbol{x}_0 x0的维度 d d d, 即每层的输入和输出维度是相等的(这个之前没有整理,没注意到)
- 残差网络的结构启发,每层的函数 f \boldsymbol{f} f拟合的是 x l + 1 − x l \boldsymbol{x}_{l+1}-\boldsymbol{x}_l xl+1−xl的残差,残差网络有很多优点,其中一个是处理梯度消失的问题,可以使得网络更“深”
那么显性交叉到底体会到哪里呢? 还是拿我之前举的那个例子:假设 x 0 = [ x 0 , 1 x 0 , 2 ] \boldsymbol{x}_{0}=\left[\begin{array}{l}x_{0,1} \\ x_{0,2}\end{array}\right] x0=[x0,1x0,2], 为了讨论各层,先令 b i = 0 \boldsymbol{b}_i=0 bi=0, 则
x 1 = x 0 x 0 T w 0 + x 0 = [ x 0 , 1 x 0 , 2 ] [ x 0 , 1 , x 0 , 2 ] [ w 0 , 1 w 0 , 2 ] + [ x 0 , 1 x 0 , 2 ] = [ w 0 , 1 x 0 , 1 2 + w 0 , 2 x 0 , 1 x 0 , 2 + x 0 , 1 w 0 , 1 x 0 , 2 x 0 , 1 + w 0 , 2 x 0 , 2 2 + x 0 , 2 ] x 2 = x 0 x 1 T w 1 + x 1 = [ w 1 , 1 x 0 , 1 x 1 , 1 + w 1 , 2 x 0 , 1 x 1 , 2 + x 1 , 1 w 1 , 1 x 0 , 2 x 1 , 1 + w 1 , 2 x 0 , 2 x 1 , 2 + x 1 , 2 ] = [ w 0 , 1 w 1 , 1 x 0 , 1 3 + ( w 0 , 2 w 1 , 1 + w 0 , 1 w 1 , 2 ) x 0 , 1 2 x 0 , 2 + w 0 , 2 w 1 , 2 x 0 , 1 x 0 , 2 2 + ( w 0 , 1 + w 1 , 1 ) x 0 , 1 2 + ( w 0 , 2 + w 1 , 2 ) x 0 , 1 x 0 , 2 + x 0 , 1 ] … … … . \boldsymbol{x}_{1}=\boldsymbol{x}_{0} \boldsymbol{x}_{0}^{T} \boldsymbol{w}_{0}+\boldsymbol{x}_{0}=\left[\begin{array}{l} x_{0,1} \\ x_{0,2} \end{array}\right]\left[x_{0,1}, x_{0,2}\right]\left[\begin{array}{c} w_{0,1} \\ w_{0,2} \end{array}\right]+\left[\begin{array}{l} x_{0,1} \\ x_{0,2} \end{array}\right]=\left[\begin{array}{l} w_{0,1} x_{0,1}^{2}+w_{0,2} x_{0,1} x_{0,2}+x_{0,1} \\ w_{0,1} x_{0,2} x_{0,1}+w_{0,2} x_{0,2}^{2}+x_{0,2} \end{array}\right] \\ \begin{aligned} \boldsymbol{x}_{2}=& \boldsymbol{x}_{0} \boldsymbol{x}_{1}^{T} \boldsymbol{w}_{1}+\boldsymbol{x}_{1} \\ =&\left[\begin{array}{l} w_{1,1} x_{0,1} x_{1,1}+w_{1,2} x_{0,1} x_{1,2}+x_{1,1} \\ \left.w_{1,1} x_{0,2} x_{1,1}+w_{1,2} x_{0,2} x_{1,2}+x_{1,2}\right] \end{array}\right. \\ &=\left[\begin{array}{l} \left.w_{0,1} w_{1,1} x_{0,1}^{3}+\left(w_{0,2} w_{1,1}+w_{0,1} w_{1,2}\right) x_{0,1}^{2} x_{0,2}+w_{0,2} w_{1,2} x_{0,1} x_{0,2}^{2}+\left(w_{0,1}+w_{1,1}\right) x_{0,1}^{2}+\left(w_{0,2}+w_{1,2}\right) x_{0,1} x_{0,2}+x_{0,1}\right] \\ \ldots \ldots \ldots . \end{array}\right. \end{aligned} x1=x0x0Tw0+x0=[x0,1x0,2][x0,1,x0,2][w0,1w0,2]+[x0,1x0,2]=[w0,1x0,12+w0,2x0,1x0,2+x0,1w0,1x0,2x0,1+w0,2x0,22+x0,2]x2==x0x1Tw1+x1[w1,1x0,1x1,1+w1,2x0,1x1,2+x1,1w1,1x0,2x1,1+w1,2x0,2x1,2+x1,2]=[w0,1w1,1x0,13+(w0,2w1,1+w0,1w1,2)x0,12x0,2+w0,2w1,2x0,1x0,22+(w0,1+w1,1)x0,12+(w0,2+w1,2)x0,1x0,2+x0,1]……….
最后得到 y cross = x 2 T ∗ w cross ∈ R y_{\text {cross }}=\boldsymbol{x}_{2}^{T} * \boldsymbol{w}_{\text {cross }} \in \mathbb{R} ycross =x2T∗wcross ∈R参与到最后的loss计算。 可以看到 x 1 \boldsymbol{x}_1 x1包含了原始特征 x 0 , 1 , x 0 , 2 x_{0,1},x_{0,2} x0,1,x0,2从一阶导二阶所有可能叉乘组合, 而 x 2 \boldsymbol{x}_2 x2包含了从一阶导三阶素有可能的叉乘组合, 而显性特征组合的意思,就是最终的结果可以经过一系列转换,得到类似 W i , j x i x j W_{i,j}x_ix_j Wi,jxixj的形式, 上面这个可以说是非常明显了吧。
- 有限高阶: 叉乘阶数由网络深度决定, 深度 L c L_c Lc对应最高 L c + 1 L_c+1 Lc+1阶的叉乘
- 自动叉乘:Cross输出包含了原始从一阶(本身)到 L c + 1 L_c+1 Lc+1阶的所有叉乘组合, 而模型参数量仅仅随着输入维度线性增长: 2 × d × L c 2\times d\times L_c 2×d×Lc
- 参数共享: 不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重,通过参数共享,Cross有效降低了参数数量。 并且,使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 x i ≠ 0 ∧ x j ≠ 0 x_{i} \neq 0 \wedge x_{j} \neq 0 xi=0∧xj=0这个叉乘特征没有出现,对应权重肯定是0,而参数共享不会,类似的,数据集中的一些噪声可以由大部分样本来纠正权重参数的学习
这里有一点很值得留意,前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?联系这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种trade-off的可行选择。
看下DNN与Cross Network的参数量对比:
初始输入 x 0 x_0 x0维度是 d d d, Deep和Cross层数分别为 L c r o s s L_{cross} Lcross和 L d e e p L_{deep} Ldeep, 为便于分析,设Deep每层神经元个数为 m m m则两部分参数量:
Cross: d ∗ L cross ∗ 2 V S Deep: ( d ∗ m + m ) + ( m 2 + m ) ∗ ( L deep − 1 ) \text { Cross: } d * L_{\text {cross }} * 2 \quad V S \quad \text { Deep: }(d * m+m)+\left(m^{2}+m\right) *\left(L_{\text {deep }}-1\right) Cross: d∗Lcross ∗2VS Deep: (d∗m+m)+(m2+m)∗(Ldeep −1)
可以看到Cross的参数量随 d d d增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。Deep那部分参数计算其实是第一层单算 m ( d + 1 ) m(d+1) m(d+1), 接下来的 L − 1 L-1 L−1层,每层都是 m m m, 再加上 b b b个个数,所以 m ( m + 1 ) m(m+1) m(m+1)。
好了, Cross的好处啥的都分析完了, 下面得分析点不好的地方了,否则就没法引出这次的主角了。作者直接说:

每一层学习到的是 x 0 \boldsymbol{x}_0 x0的标量倍,这是啥意思。 这里有一个理论:
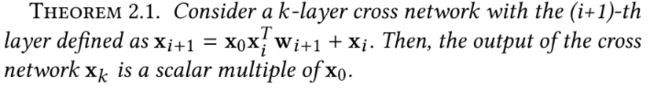
这里作者用数学归纳法进行了证明。
当 k = 1 k=1 k=1的时候
x 1 = x 0 ( x 0 T w 1 ) + x 0 = x 0 ( x 0 T w 1 + 1 ) = α 1 x 0 \begin{aligned} \mathbf{x}_{1} &=\mathbf{x}_{0}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{1}\right)+\mathbf{x}_{0} \\ &=\mathbf{x}_{0}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{1}+1\right) \\ &=\alpha^{1} \mathbf{x}_{0} \end{aligned} x1=x0(x0Tw1)+x0=x0(x0Tw1+1)=α1x0
这里的 α 1 = x 0 T w 1 + 1 \alpha^{1}=\mathbf{x}_{0}^{T} \mathbf{w}_{1}+1 α1=x0Tw1+1是 x 0 x_0 x0的一个线性回归, x 1 x_1 x1是 x 0 x_0 x0的标量倍成立。 假设当 k = i k=i k=i的时候也成立,那么 k = i + 1 k=i+1 k=i+1的时候:
x i + 1 = x 0 x i T w i + 1 + x i = x 0 ( ( α i x 0 ) T w i + 1 ) + α i x 0 = α i + 1 x 0 \begin{aligned} \mathbf{x}_{i+1} &=\mathbf{x}_{0} \mathbf{x}_{i}^{T} \mathbf{w}_{i+1}+\mathbf{x}_{i} \\ &=\mathbf{x}_{0}\left(\left(\alpha^{i} \mathbf{x}_{0}\right)^{T} \mathbf{w}_{i+1}\right)+\alpha^{i} \mathbf{x}_{0} \\ &=\alpha^{i+1} \mathbf{x}_{0} \end{aligned} xi+1=x0xiTwi+1+xi=x0((αix0)Twi+1)+αix0=αi+1x0
其中 α i + 1 = α i ( x 0 T w i + 1 + 1 ) \alpha^{i+1}=\alpha^{i}\left(\mathbf{x}_{0}^{T} \mathbf{w}_{i+1}+1\right) αi+1=αi(x0Twi+1+1), 即 x i + 1 x_{i+1} xi+1依然是 x 0 x_0 x0的标量倍。
所以作者认为Cross Network有两个缺点:
- 由于每个隐藏层是 x 0 x_0 x0的标量倍,所以CrossNet的输出受到了特定形式的限制
- CrossNet的特征交互是bit-wise的方式(这个经过上面举例子应该是显然了),这种方式embedding向量的各个元素也会互相影响,这样在泛化能力上可能受到限制,并且也意识不到Field Vector的概念, 这其实违背了我们特征之间相互交叉的初衷。因为我们想让模型学习的是特征与特征之间的交互或者是相关性,从embedding的角度,,那么自然的特征与特征之间的交互信息应该是embedding与embedding的交互信息。 但是bit-wise的交互上,已经意识不到embedding的概念了。由于最细粒度是bit(embedding的具体元素),所以这样的交互既包括了不同embedding不同元素之间的交互,也包括了同一embedding不同元素的交互。本质上其实发生了改变。 这也是作者为啥强调CIN网络是vector-wise的原因。而FM,恰好是以向量为最细粒度学习相关性。
好了, 如果真正理解了Cross Network,以及上面存在的两个问题,理解xDeepFM的动机就不难了,xDeepFM的动机,正是将FM的vector-wise的思想引入到了Cross部分。
下面主角登场了:

3. xDeepFM模型的理论以及论文细节
了解了xDeepFM的动机,再强调下xDeepFM的核心,就是提出的一个新的Cross Network(CIN),这个是基于DCN的Cross Network,但是有上面那几点好处。下面的逻辑打算是这样,首先先整体看下xDeepFM的模型架构,由于我们已经知道了这里其实就是用一个CIN网络代替了DCN的Cross Network,那么这里面除了这个网络,其他的我们都熟悉。 然后我们再重点看看CIN网络到底在干个什么样的事情,然后再看看CIN与FM等有啥关系,最后分析下这个新网络的时间复杂度等问题。
3.1 xDeepFM的架构剖析
首先,我们先看下xDeepFM的架构
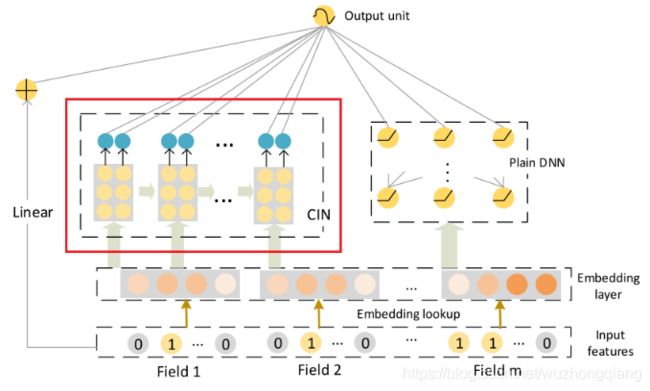
这个网络结构名副其实,依然是采用了W&D架构,DNN负责Deep端,学习特征之间的隐性高阶交互, 而CIN网络负责wide端,学习特征之间的显性高阶交互,这样显隐性高阶交互就在这个模型里面体现的淋漓尽致了。不过这里的线性层单拿出来了。

最终的计算公式如下:
y ^ = σ ( w linear T a + w d n n T x d n n k + w cin T p + + b ) \hat{y}=\sigma\left(\mathbf{w}_{\text {linear }}^{T} \mathbf{a}+\mathbf{w}_{d n n}^{T} \mathbf{x}_{d n n}^{k}+\mathbf{w}_{\text {cin }}^{T} \mathbf{p}^{+}+b\right) y^=σ(wlinear Ta+wdnnTxdnnk+wcin Tp++b)
这里的 a \mathbf{a} a表示原始的特征, a d n n k \mathbf{a}_{dnn}^k adnnk表示的是DNN的输出, p + \mathbf{p}^+ p+表示的是CIN的输出。最终的损失依然是交叉熵损失,这里也是做一个点击率预测的问题:
L = − 1 N ∑ i = 1 N y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) \mathcal{L}=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \hat{y}_{i}+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right) L=−N1i=1∑Nyilogy^i+(1−yi)log(1−y^i)
最终的目标函数加了正则化:
J = L + λ ∗ ∥ Θ ∥ \mathcal{J}=\mathcal{L}+\lambda_{*}\|\Theta\| J=L+λ∗∥Θ∥
3.2 CIN网络的细节(重头戏)
这里尝试剖析下本篇论文的主角CIN网络,全称Compressed Interaction Network。这个东西说白了其实也是一个网络,并不是什么高大上的东西,和Cross Network一样,也是一层一层,每一层都是基于一个固定的公式进行的计算,那个公式长这样:
X h , ∗ k = ∑ i = 1 H k − 1 ∑ j = 1 m W i j k , h ( X i , ∗ k − 1 ∘ X j , ∗ 0 ) \mathbf{X}_{h, *}^{k}=\sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{k, h}\left(\mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0}\right) Xh,∗k=i=1∑Hk−1j=1∑mWijk,h(Xi,∗k−1∘Xj,∗0)
这个公式第一眼看过来,肯定更是懵逼,这是写的个啥玩意?如果我再把CIN的三个核心图放上来:

上面其实就是CIN网络的精髓了,也是它具体的运算过程,只不过直接上图的话,会有些抽象,难以理解,也不符合我整理论文的习惯。下面,我们就一一进行剖析, 先从上面这个公式开始。但在这之前,需要先约定一些符号。要不然不知道代表啥意思。
- X 0 ∈ R m × D \mathbf{X}^{0} \in \mathbb{R}^{m \times D} X0∈Rm×D: 这个就是我们的输入,也就是embedding层的输出,可以理解为各个embedding的堆叠而成的矩阵,假设有 m m m个特征,embedding的维度是 D D D维,那么这样就得到了这样的矩阵, m m m行 D D D列。 X i , ∗ 0 = e i \mathbf{X}_{i, *}^{0}=\mathbf{e}_{i} Xi,∗0=ei, 这个表示的是第 i i i个特征的embedding向量 e i e_i ei。所以上标在这里表示的是网络的层数,输入可以看做第0层,而下标表示的第几行的embedding向量,这个清楚了。
- X k ∈ R H k × D \mathbf{X}^{k} \in \mathbb{R}^{H_{k} \times D} Xk∈RHk×D: 这个表示的是CIN网络第 k k k层的输出,和上面这个一样,也是一个矩阵,每一行是一个embedding向量,每一列代表一个embedding维度。这里的 H k H_k Hk表示的是第 k k k层特征的数量,也可以理解为神经元个数。那么显然,这个 X k \mathbf{X}^{k} Xk就是 H k H_k Hk个 D D D为向量堆叠而成的矩阵,维度也显然了。 X h , ∗ k \mathbf{X}_{h, *}^{k} Xh,∗k代表的就是第 k k k层第 h h h个特征向量了。
所以上面的那个公式:
X h , ∗ k = ∑ i = 1 H k − 1 ∑ j = 1 m W i j k , h ( X i , ∗ k − 1 ∘ X j , ∗ 0 ) \mathbf{X}_{h, *}^{k}=\sum_{i=1}^{H_{k-1}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{k, h}\left(\mathbf{X}_{i, *}^{k-1} \circ \mathbf{X}_{j, *}^{0}\right) Xh,∗k=i=1∑Hk−1j=1∑mWijk,h(Xi,∗k−1∘Xj,∗0)
其实就是计算第 k k k层第 h h h个特征向量, 这里的 1 ≤ h ≤ H k , W k , h ∈ R H k − 1 × m 1 \leq h \leq H_{k}, \mathbf{W}^{k, h} \in \mathbb{R}^{H_{k-1} \times m} 1≤h≤Hk,Wk,h∈RHk−1×m是第 h h h个特征向量的参数矩阵。 ∘ \circ ∘表示的哈达玛积,也就是向量之间对应维度元素相乘(不相加了)。 ⟨ a 1 , a 2 , a 3 ⟩ ∘ ⟨ b 1 , b 2 , b 3 ⟩ = ⟨ a 1 b 1 , a 2 b 2 , a 3 b 3 ⟩ \left\langle a_{1}, a_{2}, a_{3}\right\rangle \circ\left\langle b_{1}, b_{2}, b_{3}\right\rangle=\left\langle a_{1} b_{1}, a_{2} b_{2}, a_{3} b_{3}\right\rangle ⟨a1,a2,a3⟩∘⟨b1,b2,b3⟩=⟨a1b1,a2b2,a3b3⟩。通过这个公式也能看到 X k \mathbf{X}^k Xk是通过 X k − 1 \mathbf{X}^{k-1} Xk−1和 X 0 \mathbf{X}^0 X0计算得来的,也就是说特征的显性交互阶数会虽然网络层数的加深而增加。
那么这个公式到底表示的啥意思呢? 是具体怎么计算的呢?我们往前计算一层就知道了,这里令 k = 1 k=1 k=1,也就是尝试计算第一层里面的第 h h h个向量, 那么上面公式就变成了:
X h , ∗ 1 = ∑ i = 1 H 0 ∑ j = 1 m W i j 1 , h ( X i , ∗ 0 ∘ X j , ∗ 0 ) \mathbf{X}_{h, *}^{1}=\sum_{i=1}^{H_{0}} \sum_{j=1}^{m} \mathbf{W}_{i j}^{1, h}\left(\mathbf{X}_{i, *}^{0} \circ \mathbf{X}_{j, *}^{0}\right) Xh,∗1=i=1∑H0j=1∑mWij1,h(Xi,∗0∘Xj,∗0)
这里的 W 1 , h ∈ R H 0 × m \mathbf{W}^{1, h} \in \mathbb{R}^{H_{0} \times m} W1,h∈RH0×m。这个能看懂吗? 首先这个 W \mathbf{W} W矩阵是 H 0 H_0 H0行 m m m列, 而前面那两个累加正好也是 H 0 H_0 H0行 m m m列的参数。 m m m代表的是输入特征的个数, H 0 H_0 H0代表的是第0层( k − 1 k-1 k−1层)的神经元的个数, 这个也是 m m m。这个应该好理解,输入层就是第0层。所以这其实就是一个 m × m m\times m m×m的矩阵。那么后面这个运算到底是怎么算的呢? 首先对于第 i i i个特征向量, 要依次和其他的 m m m个特征向量做哈达玛积操作,当然也乘以对应位置的权重,求和。对于每个 i i i特征向量,都重复这样的操作,最终求和得到一个 D D D维的向量,这个就是 X h , ∗ 1 \mathbf{X}_{h, *}^{1} Xh,∗1。好吧,这么说。我觉得应该也没有啥感觉,画一下就了然了,现在可以先不用管论文里面是怎么说的,先跟着这个思路走,只要理解了这个公式是怎么计算的,论文里面的那三个图就会非常清晰了。灵魂画手:
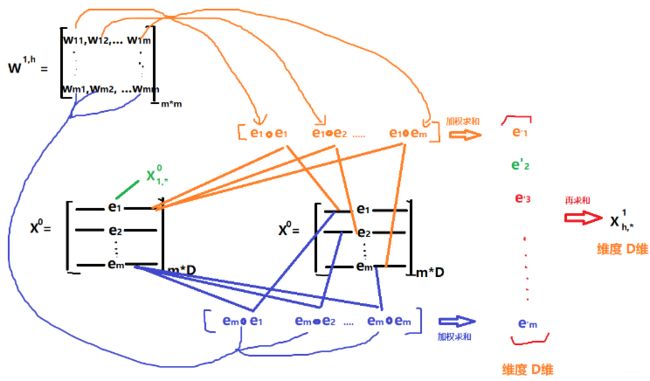
这就是上面那个公式的具体过程了,图实在是太难看了, 但应该能说明这个详细的过程了。这样只要给定一个 W 1 , h \mathbf{W}^{1,h} W1,h之后,就能算出一个相应的 X h , ∗ 1 \mathbf{X}^1_{h,*} Xh,∗1来,这样第一层的 H 1 H_1 H1个神经元按照这样的步骤就能够都计算出来了。 后面的计算过程其实是同理,无非就是输入是前一层的输出以及 X 0 \mathbf{X}_0 X0罢了,而这时候,第一个矩阵特征数就不一定是 m m m了,而是一个 H k − 1 H_{k-1} Hk−1行 D D D列的矩阵了。这里的 W k , h \mathbf{W}^{k,h} Wk,h就是上面写的 H k − 1 H_{k-1} Hk−1行 m m m列了。
这个过程明白了之后,再看论文后面的内容就相对容易了,首先

CIN里面能看到RNN的身影,也就是当前层的隐藏单元的计算要依赖于上一层以及当前的输入层,只不过这里的当前输入每个时间步都是 X 0 \mathbf{X}_0 X0。 同时这里也能看到,CIN的计算是vector-wise级别的,也就是向量之间的哈达玛积的操作,并没有涉及到具体向量里面的位交叉。
下面我们再从CNN的角度去看这个计算过程。其实还是和上面一样的计算过程,只不过是换了个角度看而已,所以上面那个只要能理解,下面CNN也容易理解了。首先,这里引入了一个tensor张量 Z k + 1 \mathbf{Z}^{k+1} Zk+1表示的是 X k \mathbf{X}^k Xk和 X 0 \mathbf{X}^0 X0的外积,那么这个东西是啥呢? 上面加权求和前的那个矩阵,是一个三维的张量。
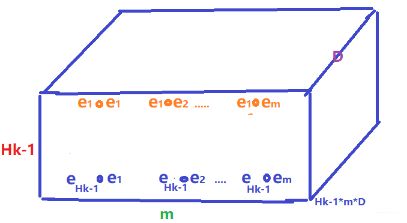
这个可以看成是一个三维的图片, H k − 1 H_{k-1} Hk−1高, m m m宽, D D D个通道。而 W k , h \mathbf{W}^{k,h} Wk,h的大小是 H k − 1 × m H_{k-1}\times m Hk−1×m的, 这个就相当于一个过滤器,用这个过滤器对输入的图片如果逐通道进行卷积,就会最终得到一个 D D D维的向量,而这个其实就是 X h , ∗ k \mathbf{X}^{k}_{h,*} Xh,∗k,也就是一张特征图(每个通道过滤器是共享的)。 第 k k k层其实有 H k H_k Hk个这样的过滤器,所以最后得到的是一个 H k × D H_k\times D Hk×D的矩阵。这样,在第 k k k个隐藏层,就把了 H k − 1 × m × D H_{k-1}\times m\times D Hk−1×m×D的三维张量通过逐通道卷积的方式,压缩成了一个 H k × D H_k\times D Hk×D的矩阵( H k H_k Hk张特征图), 这就是第 k k k层的输出 X k \mathbf{X}^k Xk。 而这也就是“compressed"的由来。这时候再看这两个图就非常舒服了:
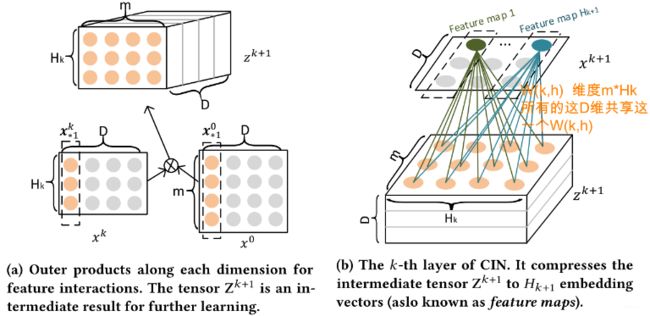
通过这样的一个CIN网络,就很容易的实现了特征的显性高阶交互,并且是vector-wise级别的,那么最终的输出层是啥呢? 通过上面的分析,首先我们了解了对于第 k k k层输出的某个特征向量,其实是综合了输入里面各个embedding向量显性高阶交互的信息(第 k k k层其实学习的输入embedding k + 1 k+1 k+1阶交互信息),这个看第一层那个输出就能看出来。第 k k k层的每个特征向量其实都能学习到这样的信息,那么如果把这些向量在从 D D D维度上进行加和,也就是 X k \mathbf{X}^k Xk,这是个 H k × D H_k\times D Hk×D的,我们沿着D这个维度加和,又会得到一个 H k H_k Hk的向量,公式如下:
p i k = ∑ j = 1 D X i , j k p_{i}^{k}=\sum_{j=1}^{D} \mathbf{X}_{i, j}^{k} pik=j=1∑DXi,jk
每一层,都会得到一个这样的向量,那么把所有的向量拼接到一块,其实就是CIN网络的输出了。之所以,这里要把中间结果都与输出层相连,就是因为CIN与Cross不同的一点是,在第 k k k层,CIN只包含 k + 1 k+1 k+1阶的组合特征,而Cross是能包含从1阶- k + 1 k+1 k+1阶的组合特征的,所以为了让模型学习到从1阶到所有阶的组合特征,CIN这里需要把中间层的结果与输出层建立连接。
这也就是第三个图表示的含义:
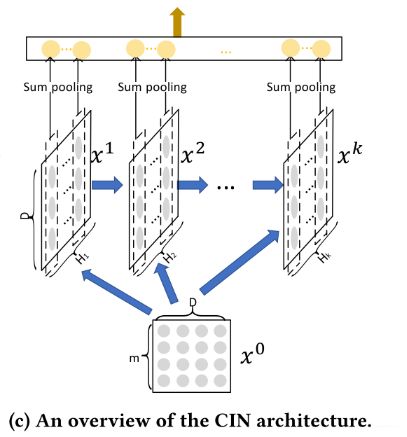
这样, 就得到了最终CIN的输出 p + \mathbf{p}^+ p+了:
p + = [ p 1 , p 2 , … , p T ] ∈ R ∑ i = 1 T H i \mathbf{p}^{+}=\left[\mathbf{p}^{1}, \mathbf{p}^{2}, \ldots, \mathbf{p}^{T}\right] \in \mathbb{R} \sum_{i=1}^{T} H_{i} p+=[p1,p2,…,pT]∈Ri=1∑THi
后面那个维度的意思,就是说每一层是的向量维度是 H i H_i Hi维, 最后是所有时间步的维度之和。 CIN网络的计算过程的细节就是这些了。
3.2 CIN网络的其他角度分析
3.2.1 设计意图分析
CIN和DCN层的设计动机是相似的,Cross层的input也是前一层与输入层,这么做的原因就是可以实现: 有限高阶交互,自动叉乘和参数共享。
但是CIN与Cross的有些地方是不一样的:
- Cross是bit-wise级别的, 而CIN是vector-wise级别的
- 在第 l l l层,Cross包含从1阶- l + 1 l+1 l+1阶的所有组合特征, 而CIN只包含 l + 1 l+1 l+1阶的组合特征。 相应的,Cross在输出层输出全部结果, 而CIN在每层都输出中间结果。 而之所以会造成这两者的不同, 就是因为Cross层计算公式中除了与CIN一样包含"上一层与输入层的×乘"外,会再额外加了个"+输入层"。这是两种涵盖所有阶特征交互的不同策略,CIN和Cross也可以使用对方的策略。
3.2.2 时间和空间复杂度分析
- 空间复杂度
假设CIN和DNN每层神经元个数是 H H H,网络深度为 T T T。 那么CIN的参数空间复杂度 O ( m T H 2 ) O(mTH^2) O(mTH2)。 这个我们先捋捋是怎么算的哈, 首先对于CIN,第 k k k层的每个神经元都会对应着一个 H k − 1 × m H_{k-1}\times m Hk−1×m的参数矩阵 W k , h \mathbf{W}^{k,h} Wk,h, 那么第 k k k层 H H H个神经元的话,那就是 H × H k − 1 × m H \times H_{k-1} \times m H×Hk−1×m个参数,这里假设的是每层都有 H H H个神经元,那么就是 O ( H 2 × m ) O(H^2\times m) O(H2×m),这是一层。 而网络深度一共 T T T层的话,那就是 H × H k − 1 × m × T H \times H_{k-1} \times m\times T H×Hk−1×m×T的规模。 但别忘了,输出层还有参数, 由于输出层的参数会和输出向量的维度相对应,而输出向量的维度又和每一层神经单元个数相对应, 所以CIN的网络参数一共是 ∑ k = 1 T H k × ( 1 + H k − 1 × m ) \sum_{k=1}^{T} H_{k} \times\left(1+H_{k-1} \times m\right) ∑k=1THk×(1+Hk−1×m), 而换成大O表示的话,其实就是上面那个了。当然,CIN还可以对 W \mathbf{W} W进行 L L L阶矩阵分解,使得空间复杂度再降低。
再看DNN,第一层是 m × D × H 1 m\times D\times H_1 m×D×H1, 中间层 H k × H k − 1 H_k\times H_{k-1} Hk×Hk−1,T-1层,这是一个 O ( m D H + T H 2 ) O(mDH+TH^2) O(mDH+TH2)的空间复杂度,并且参数量会随着 D D D的增加而增加。
所以空间上来说,CIN会有优势。 - 时间复杂度
对于CIN, 我们计算某一层的某个特征向量的时候,需要前面的 H k − 1 H_{k-1} Hk−1个向量与输入的 m m m个向量两两哈达玛积的操作,这个过程花费的时间 O ( H m ) O(Hm) O(Hm), 而哈达玛积完事之后,有需要拿个过滤器在D维度上逐通道卷积,这时候得到了 Z k + 1 \mathbf{Z}^{k+1} Zk+1,花费时间 O ( H m D ) O(HmD) O(HmD)。 这只是某个特征向量, k k k层一共 H H H个向量, 那么花费时间 O ( H 2 m D ) O(H^2mD) O(H2mD), 而一共 T T T层,所以最终时间为 O ( m H 2 T D ) O(mH^2TD) O(mH2TD)
对于普通的DNN,花费时间 O ( m H D + H 2 T ) O(mHD+H^2T) O(mHD+H2T)
所以时间复杂度会是CIN的一大痛点。
3.2.3 多项式逼近
这地方没怎么看懂,大体写写吧, 通过对问题进行简化,即假设CIN中不同层的feature map的数量全部一致,均为fields的数量 m m m,并且用[m]表示小于等于m的正整数。CIN中的第一层的第 h h h个feature map表示为 x h 1 ∈ R D x_h^1 \in \mathbb{R}^D xh1∈RD,即
x h 1 = ∑ i ∈ [ m ] , j ∈ [ m ] W i , j 1 , h ( x i 0 ∘ x j 0 ) \boldsymbol{x}_{\boldsymbol{h}}^{1}=\sum_{i \in[m], j \in[m]} \boldsymbol{W}_{i, j}^{1, h}\left(x_{i}^{0} \circ x_{j}^{0}\right) xh1=i∈[m],j∈[m]∑Wi,j1,h(xi0∘xj0)
因此, 在第一层中通过 O ( m 2 ) O(m^2) O(m2)个参数来建模成对的特征交互关系,相似的,第二层的第 h h h个特征图表示为:
x h 2 = ∑ i ∈ [ m ] , j ∈ [ m ] W i , j 2 , h ( x i 1 ∘ x j 0 ) = ∑ i ∈ [ m ] , j ∈ [ m ] ] ∈ [ m ] , k ∈ [ m ] W i , j 2 , h W l , k 1 , h ( x j 0 ∘ x k 0 ∘ x l 0 ) \begin{array}{c} \boldsymbol{x}_{h}^{2}=\sum_{i \in[m], j \in[m]} \boldsymbol{W}_{i, j}^{2, h}\left(x_{i}^{1} \circ x_{j}^{0}\right) \\ =\sum_{i \in[m], j \in[m]] \in[m], k \in[m]} \boldsymbol{W}_{i, j}^{2, h} \boldsymbol{W}_{l, k}^{1, h}\left(x_{j}^{0} \circ x_{k}^{0} \circ x_{l}^{0}\right) \end{array} xh2=∑i∈[m],j∈[m]Wi,j2,h(xi1∘xj0)=∑i∈[m],j∈[m]]∈[m],k∈[m]Wi,j2,hWl,k1,h(xj0∘xk0∘xl0)
由于第二个 W \mathbf{W} W矩阵在前面一层计算好了,所以第二层的feature map也是只用了 O ( m 2 ) O(m^2) O(m2)个参数就建模出了3阶特征交互关系。
我们知道一个经典的 k k k阶多项式一般是需要 O ( m k ) O(m^k) O(mk)个参数的,而我们展示了CIN在一系列feature map中只需要 O ( k m 2 ) O(k m^2) O(km2)个参数就可以近似此类多项式。而且paper使用了归纳假设的方法证明了一下,也就是后面那两个公式。具体的没咋看懂证明,不整理了。但得知道两个结论:
- 对于CIN来讲, 第 k k k层只包含 k + 1 k+1 k+1阶特征间的显性特征交互
- CIN的一系列特征图只需要 O ( k m 2 ) O(km^2) O(km2)个参数就可以近似此类多项式
3.2.4 xDeepFM与其他模型的关系
- 对于xDeepFM,将CIN模块的层数设置为1,feature map数量也为1时,其实就是DeepFM的结构,因此DeepFM是xDeepFM的特殊形式,而xDeepFM是DeepFM的一般形式;
- 在1中的基础上,当我们再将xDeepFM中的DNN去除,并对feature map使用一个常数1形式的
sum filter,那么xDeepFM就退化成了FM形式了。
一般这种模型的改进,是基于之前模型进行的,也就是简化之后,会得到原来的模型,这样最差的结果,模型效果还是原来的,而不应该会比原来模型的表现差,这样的改进才更有说服力。
所以,既然提到了FM,再考虑下面两个问题理解下CIN设计的合理性。
- 每层通过sum pooling对vector的元素加和输出,这么做的意义或者合理性? 这个就是为了退化成FM做准备,如果CIN只有1层, 只有 m m m个vector,即 H 1 = m H_1=m H1=m ,且加和的权重矩阵恒等于1,即 W 1 = 1 W^1=1 W1=1 ,那么sum pooling的输出结果,就是一系列的两两向量内积之和,即标准的FM(不考虑一阶与偏置)。
- 除了第一层,中间层的基于Vector高阶组合有什么物理意义? 回顾FM,虽然是二阶的,但可以扩展到多阶,例如考虑三阶FM,是对三个嵌入向量做哈达玛积乘再对得到的vector做sum, CIN基于vector-wise的高阶组合再sum pooling与之类似,这也是模型名字"eXtreme Deep Factorization Machine(xDeepFM)"的由来。
3.3 论文的其他重要细节
3.3.1 实验部分
这一块就是后面实验了,这里作者依然是抛出了三个问题,并通过实验进行了解答。
-
CIN如何学习高阶特征交互
通过提出的交叉网络,这里单独证明了这个结构要比CrossNet,DNN模块和FM模块要好 -
推荐系统中,是否需要显性和隐性的高阶特征交互都存在?

并且网络不用设置的太深。 -
超参对于xDeepFM的影响
- 网络的深度: 不用太深, CIN网络层数大于3,就不太好了,容易过拟合
- 每一层神经网络的单元数: 100是比较合适的一个数值
- 激活函数: CIN这里不用加任何的非线性激活函数,用恒等函数 f ( x ) = x f(x)=x f(x)=x效果最好
这里用了三个数据集
- 公开数据集 Criteo 与 微软数据集 BingNews
- DianPing 从大众点评网整理的相关数据,收集6个月的user check-in 餐厅poi的记录,从check-in餐厅周围3km内,按照poi受欢迎度抽取餐厅poi作为负例。根据user属性、poi属性,以及user之前3家check-in的poi,预测用户check-in一家给定poi的概率。
评估指标用了两个AUC和Logloss, 这两个是从不同的角度去评估模型。
- AUC: AUC度量一个正的实例比一个随机选择的负的实例排名更高的概率。它只考虑预测实例的顺序,对类的不平衡问题不敏感.
- LogLoss(交叉熵损失): 真实分数与预测分数的距离
作者说:

3.3.2 相关工作部分
这里作者又梳理了之前的模型,这里就再梳理一遍了
-
经典推荐系统
- 非因子分解模型: 主要介绍了两类,一类是常见的线性模型,例如LR with FTRL,这一块很多工作是在交互特征的特征工程方面;另一类是提升决策树模型的研究(GBDT+LR)
- 因子分解模型: MF模型, FM模型,以及在FM模型基础上的贝叶斯模型
-
深度学习模型
- 学习高阶交互特征: 论文中提到的DeepCross, FNN,PNN,DCN, NFM, W&D, DeepFM,
- 学习精心的表征学习:这块常见的深度学习模型不是focus在学习高阶特征交互关系。比如NCF,ACF,DIN等。
推荐系统数据特点: 稀疏,类别连续特征混合,高维。
关于未来两个方向:
- CIN的sum pooling这里, 后面可以考虑DIN的那种思路,根据当前候选商品与embedding的关联进行注意力权重的添加
- CIN的时间复杂度还是比较高的,后面在GPU集群上使用分布式的方式来训练模型。
4. xDeepFM模型的代码复现及重要结构解释
4.1 xDeepFM的整体代码逻辑
下面看下xDeepFM模型的具体实现, 这样可以从更细节的角度去了解这个模型, 这里我依然是参考的deepctr的代码风格,这种函数式模型编程更清晰一些,当然由于时间原因,我这里目前只完成了一个tf2版本的(pytorch版本的后面有时间会补上)。 这里先看下xDeepFM的全貌:
def xDeepFM(linear_feature_columns, dnn_feature_columns, cin_size=[128, 128]):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入预Input层对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# 线性部分的计算逻辑 -- linear
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# 线性层和dnn层统一的embedding层
embedding_layer_dict = build_embedding_layers(linear_feature_columns+dnn_feature_columns, sparse_input_dict, is_linear=False)
# DNN侧的计算逻辑 -- Deep
# 将dnn_feature_columns里面的连续特征筛选出来,并把相应的Input层拼接到一块
dnn_dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns)) if dnn_feature_columns else []
dnn_dense_feature_columns = [fc.name for fc in dnn_dense_feature_columns]
dnn_concat_dense_inputs = Concatenate(axis=1)([dense_input_dict[col] for col in dnn_dense_feature_columns])
# 将dnn_feature_columns里面的离散特征筛选出来,相应的embedding层拼接到一块
dnn_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
dnn_concat_sparse_kd_embed = Concatenate(axis=1)(dnn_sparse_kd_embed)
# DNN层的输入和输出
dnn_input = Concatenate(axis=1)([dnn_concat_dense_inputs, dnn_concat_sparse_kd_embed])
dnn_out = get_dnn_output(dnn_input)
dnn_logits = Dense(1)(dnn_out)
# CIN侧的计算逻辑, 这里使用的DNN feature里面的sparse部分,这里不要flatten
exFM_sparse_kd_embed = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
exFM_input = Concatenate(axis=1)(exFM_sparse_kd_embed)
exFM_out = CIN(cin_size=cin_size)(exFM_input)
exFM_logits = Dense(1)(exFM_out)
# 三边的结果stack
stack_output = Add()([linear_logits, dnn_logits, exFM_logits])
# 输出层
output_layer = Dense(1, activation='sigmoid')(stack_output)
model = Model(input_layers, output_layer)
return model
这种风格最好的一点,就是很容易从宏观上把握模型的整体逻辑。 首先,接收的输入是linear_feature_columns和dnn_feature_columns, 这两个是深度和宽度两侧的特征,具体选取要结合着场景来。 接下来,就是为这些特征建立相应的Input层,这里要分成连续特征和离散的特征,因为后面的处理方式不同, 连续特征的话可以直接拼了, 而离散特征的话,需要过一个embedding层转成低维稠密,这就是第一行代码干的事情了。
接下来, 计算线性部分,从上面xDeepFM的结构里面可以看出, 是分三路走的,线性,CIN和DNN路, 所以get_linear_logits就是线性这部分的计算结果,完成的是 w 1 x 1 + w 2 x 2 . . w k x k + b w_1x_1+w_2x_2..w_kx_k+b w1x1+w2x2..wkxk+b, 这里面依然是连续和离散的不太一样,对于连续特征,直接过一个全连接就实现了这个操作,而离散特征,这里依然过一个embedding,不过这个维度是1,目的是转成了一个连续数值(这个相当于离散特征对应的w值),这样后面进行总的加和操作即可。
接下来是另外两路,DNN这路也比较简单, dnn_feature_columns里面的离散特征过embedding,和连续特征拼接起来,然后过DNN即可。 CIN这路使用的是dnn_feature_columns里面的离散embedding特征,进行显性高阶交叉,这里的输入是[None, field_num, embedding_dim]的维度。这个也好理解,每个特征embedding之后,拼起来即可,注意flatten=False了。 这个输入,过CIN网络得到输出。
这样三路输出都得到,然后进行了一个加和,再连接一个Dense映射到最终输出。这就是整体的逻辑了,关于每个部分的具体细节,可以看代码。 下面主要是看看CIN这个网络是怎么实现的,因为其他的在之前的模型里面也基本是类似的操作,比如前面DIEN,DSIN版本,并且我后面项目里面补充了DCN的deepctr风格版,这个和那个超级像,唯一不同的就是把CrossNet换成了CIN,所以这个如果感觉看不大懂,可以先看那个网络代码。下面说CIN。
4.2 CIN网络的代码实现细节
再具体代码实现, 我们先简单捋一下CIN网络的实现过程,这里的输入是[None, field_num embed_dim]的维度,在CIN里面,我们知道接下来的话,就是每一层会有 H k H_k Hk个神经元, 而每个神经元的计算要根据上面的那个计算公式,也就是 X 0 X_0 X0要和前面一层的输出两两embedding,加权求和再求和的方式。 而从CNN的角度来看,这个过程可以是这样,对于每一层的计算,先 X 0 X_0 X0和 X k X_k Xk进行外积运算(相当于两两embedding),然后采用 H k H_k Hk个过滤器对前面的结果逐通道卷积就能得到每一层的 X k X_k Xk了。 最后的输出是每一层的 X k X_k Xk拼接起来,然后在embedding维度上的求和。 所以依据这个思路,就能得到下面的实现代码:
class CIN(Layer):
def __init__(self, cin_size, l2_reg=1e-4):
"""
:param: cin_size: A list. [H_1, H_2, ....H_T], a list of number of layers
"""
super(CIN, self).__init__()
self.cin_size = cin_size
self.l2_reg = l2_reg
def build(self, input_shape):
# input_shape [None, field_nums, embedding_dim]
self.field_nums = input_shape[1]
# CIN 的每一层大小,这里加入第0层,也就是输入层H_0
self.field_nums = [self.field_nums] + self.cin_size
# 过滤器
self.cin_W = {
'CIN_W_' + str(i): self.add_weight(
name='CIN_W_' + str(i),
shape = (1, self.field_nums[0] * self.field_nums[i], self.field_nums[i+1]), # 这个大小要理解
initializer='random_uniform',
regularizer=l2(self.l2_reg),
trainable=True
)
for i in range(len(self.field_nums)-1)
}
super(CIN, self).build(input_shape)
def call(self, inputs):
# inputs [None, field_num, embed_dim]
embed_dim = inputs.shape[-1]
hidden_layers_results = [inputs]
# 从embedding的维度把张量一个个的切开,这个为了后面逐通道进行卷积,算起来好算
# 这个结果是个list, list长度是embed_dim, 每个元素维度是[None, field_nums[0], 1] field_nums[0]即输入的特征个数
# 即把输入的[None, field_num, embed_dim],切成了embed_dim个[None, field_nums[0], 1]的张量
split_X_0 = tf.split(hidden_layers_results[0], embed_dim, 2)
for idx, size in enumerate(self.cin_size):
# 这个操作和上面是同理的,也是为了逐通道卷积的时候更加方便,分割的是当一层的输入Xk-1
split_X_K = tf.split(hidden_layers_results[-1], embed_dim, 2) # embed_dim个[None, field_nums[i], 1] feild_nums[i] 当前隐藏层单元数量
# 外积的运算
out_product_res_m = tf.matmul(split_X_0, split_X_K, transpose_b=True) # [embed_dim, None, field_nums[0], field_nums[i]]
out_product_res_o = tf.reshape(out_product_res_m, shape=[embed_dim, -1, self.field_nums[0]*self.field_nums[idx]]) # 后两维合并起来
out_product_res = tf.transpose(out_product_res_o, perm=[1, 0, 2]) # [None, dim, field_nums[0]*field_nums[i]]
# 卷积运算
# 这个理解的时候每个样本相当于1张通道为1的照片 dim为宽度, field_nums[0]*field_nums[i]为长度
# 这时候的卷积核大小是field_nums[0]*field_nums[i]的, 这样一个卷积核的卷积操作相当于在dim上进行滑动,每一次滑动会得到一个数
# 这样一个卷积核之后,会得到dim个数,即得到了[None, dim, 1]的张量, 这个即当前层某个神经元的输出
# 当前层一共有field_nums[i+1]个神经元, 也就是field_nums[i+1]个卷积核,最终的这个输出维度[None, dim, field_nums[i+1]]
cur_layer_out = tf.nn.conv1d(input=out_product_res, filters=self.cin_W['CIN_W_'+str(idx)], stride=1, padding='VALID')
cur_layer_out = tf.transpose(cur_layer_out, perm=[0, 2, 1]) # [None, field_num[i+1], dim]
hidden_layers_results.append(cur_layer_out)
# 最后CIN的结果,要取每个中间层的输出,这里不要第0层的了
final_result = hidden_layers_results[1:] # 这个的维度T个[None, field_num[i], dim] T 是CIN的网络层数
# 接下来在第一维度上拼起来
result = tf.concat(final_result, axis=1) # [None, H1+H2+...HT, dim]
# 接下来, dim维度上加和,并把第三个维度1干掉
result = tf.reduce_sum(result, axis=-1, keepdims=False) # [None, H1+H2+..HT]
return result
这里主要是解释四点:
- 每一层的W的维度,是一个
[1, self.field_nums[0]*self.field_nums[i], self.field_nums[i+1]的,首先,得明白这个self.field_nums存储的是每一层的神经单元个数,这里包括了输入层,也就是第0层。那么每一层的每个神经元计算都会有一个 W k , h W^{k,h} Wk,h, 这个的大小是 [ H k − 1 , m ] [H_{k-1},m] [Hk−1,m]维的,而第 K K K层一共 H k H_k Hk个神经元,所以总的维度就是 [ H k − 1 , m , H k ] [H_{k-1},m,H_k] [Hk−1,m,Hk], 这和上面这个是一个意思,只不过前面扩展了维度1而已。 - 具体实现的时候,这里为了更方便计算,采用了切片的思路,也就是从embedding的维度把张量切开,这样外积的计算就会变得更加的简单。
- 具体卷积运算的时候,这里采用的是Conv1d,1维卷积对应的是一张张高度为1的图片(理解的时候可这么理解),输入维度是
[None, in_width, in_channels]的形式,而对应这里的数据是[None, dim, field_nums[0]*field_nums[i]], 而这里的过滤器大小是[1, field_nums[0]*field_nums[i], field_nums[i+1], 这样进行卷积的话,最后一个维度是卷积核的数量。是沿着dim这个维度卷积,得到的是[None, dim, field_nums[i+1]]的张量,这个就是第 i + 1 i+1 i+1层的输出了。和我画的
这个不同的是它把前面这个矩形Flatten了,得到了一个 [ D , H k − 1 × m ] [D,H_{k-1}\times m] [D,Hk−1×m]的二维矩阵,然后用 [ 1 , H k − 1 × m ] [1,H_{k-1}\times m] [1,Hk−1×m]的卷积核沿着D这个维度进行Conv1D, 这样就直接得到了一个D维向量, 而 H k H_k Hk个卷积核,就得到了 H k × D H_k\times D Hk×D的矩阵了。 - 每一层的输出 X k X_k Xk先加入到列表里面,然后在 H i H_i Hi的维度上拼接,再从 D D D这个维度上求和,这样就得到了CIN的最终输出。
关于CIN的代码细节解释到这里啦,剩下的可以看后面链接里面的代码了。
5. 小总
这篇文章主要是介绍了又一个新的模型xDeepFM, 这个模型的改进焦点依然是特征之间的交互信息,xDeepFM的核心就是提出了一个新的CIN结构(这个是重点,面试的时候也喜欢问),将基于Field的vecotr-wise思想引入到了Cross Network中,并保留了Cross高阶交互,自动叉乘,参数共享等优势,模型结构上保留了DeepFM的广深结构。主要有三大优势:
- CIN可以学习高效的学习有界的高阶特征;
- xDeepFM模型可以同时显示和隐式的学习高阶交互特征;
- 以vector-wise方式而不是bit-wise方式学习特征交互关系。
如果说DeepFM只是“Deep & FM”,那么xDeepFm就真正做到了”Deep” Factorization Machine。当然,xDeepFM的时间复杂度比较高,会是工业落地的主要瓶颈,后面需要进行一些优化操作。
这篇论文整体上还是非常清晰的,实验做的也非常丰富,语言描述上也非常地道,建议读读原文呀。
参考:
- xDeepFM原论文-建议读一下,这个真的超级不错
- xDeepFM:名副其实的 ”Deep” Factorization Machine
- 深度CTR之xDeepFM:融合了显式和隐式特征交互关系的深度模型推荐系统
- 揭秘 Deep & Cross : 如何自动构造高阶交叉特征
- 一文读懂xDeepFM
- 推荐系统 - xDeepFM架构详解
整理这篇文章的同时, 也建立了一个GitHub项目, 准备后面把各种主流的推荐模型用复现一遍,并用通俗易懂的语言进行注释和逻辑整理, 今天的xDeepFM已经上传, 从DIEN开始,后面的模型复现代码不仅局限于pytorch了,而是主要参考deepctr的代码风格,写简化版的并进行解释了。前面的模型也会陆续补充上deepctr风格的代码, 感兴趣的可以看一下 ,star下我会更开心哈哈
筋斗云:https://github.com/zhongqiangwu960812/AI-RecommenderSystem
另外一个就是我们的fun-rec项目也渐渐成型啦,这是在学习推荐的路上和一群志同道合的伙伴一块沉淀下来的知识,专注于推荐系统知识的整理,分推荐系统基础,推荐系统进阶和推荐系统实战三个部分,目前也在慢慢的更新中,希望能帮助更多的小伙伴,同样也期待更多伙伴的加入,一块搞搞事情呀 。 具体地址: https://github.com/datawhalechina/fun-rec