扩展Prometheus的解决方案thanos的简介和几个月使用心得
1 云原生监控的事实标准Promethues:
监控系统的历史悠久,是一个颇为成熟的领域,而Prometheus作为新生代的开源监控系统,慢慢成为了云原生体系的监控事实标准,也证明了其设计得到业界认可。Prometheus启发于Google公司的borgmon监控系统,由google前员工在2012年作为社区开源项目创建和开发,并于2015年正式发布。2016年,Prometheus正式加入Cloud Native Computing Foundation,成为仅次于Kubernetes的第二把交椅的项目。
1.1 架构

1.1.1 组件概述
Prometheus server
核心组件,负责从外部主动抓取指标到内存时序数据库,并定时将内存中的指标同步到磁盘。
Alertmanager
转发来自Prometheus server发送的告警信息至外部的告警接收者。
Pushgateway
被监控对象可主动推送指标至Pushgateway,Pushgateway的指标是被Prometheus server抓取。
Promethues web UI
Prometheus server的界面,输入表达式可查询相关的指标数据。
1.1.2 工作流程
Prometheus的工作流程核心是,以主动拉取pull的方式搜集被监控对象的metrics数据(监控指标数据),并将这些metrics数据存储到一个内存TSDB(时间序列数据库)中,并定期将内存中的指标同步到本地硬盘。有了这个核心工作流程,其余组件只是为了配合这个工作流程。被监控对象也可向Pushgateway组件推送指标,Prometheus最终也会从Pushgateway组件拉取指标到TSDB。Altermanager组件像是一个路由器,将Prometheus的告警进行转发至外部的接收者。
1.2 优点
Prometheus具有以下引人注意的优点:
1)强大的多维度数据模型
2)灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个metrics进行乘法、加法、连接、取分数位等操作。
3)易于管理:Prometheus server是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
4)高效:平均每个采样点仅占3 bytes,且一个Prometheus server可以处理数百万的 metrics。
5)使用pull模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的metrics。
6)可以采用push gateway的方式把时间序列数据推送至Prometheus server端。
7)可以通过服务发现或者静态配置去获取监控目标。
8)有多种可视化图形界面。
9) 非常多的应用都实现了Prometheus的metrics接口以暴露自身各项数据指标让 Prometheus去采集,很多没有适配的应用也会有第三方 exporter 帮它去适配 Prometheus。
1.3 局限性
1.3.1 无集群部署
Prometheus 本身只支持单机部署,没有自带支持集群部署,对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择Federate、Cortex、Thanos等开源方案或自研方案。
1.3.2 存储容量
它的存储空间也受限于单机磁盘容量,磁盘容量决定了单个Prometheus所能存储的数据量,数据量大小又取决于被采集服务的指标数量、服务数量、采集速率以及数据过期时间。在数据量大的情况下,我们可能就需要做很多取舍,比如丢弃不重要的指标、降低采集速率、设置较短的数据过期时间。
1.3.3 非精确监控系统
在设计上的权衡:放弃了一部分数据准确性,但放弃一点准确性得到的是更高的可靠性,监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。Prometheus不一定保证数据准确,这里的非精确来自两个方面:
1)rate、histogram_quantile等数学函数。
2)来查询范围过长要做降采样,势必会造成数据精度丢失。
1.4 资源消耗
在一个节点数量为6的kuberntes集群(指标主要来自kubelet服务、node-exporter服务、kube-apiserver、kube-controller等核心服务),单个Prometheus实例消耗0.1-0.4个cpu,2.5G-3G内存。

1.5 Prometheus高可用方案
1.5.1 业界Prometheus高可用方案概述:
1)基本HA:即两套 Prometheus 采集完全一样的数据,外边挂负载均衡。
2)HA + 远程存储:除了基础的多副本 Prometheus,还通过 Remote Write 写入到远程存储,解决存储持久化问题。
3)联邦集群:即Federation,按照功能进行分区,不同的 Shard 采集不同的数据,由 Global 节点来统一存放,解决监控数据规模的问题。
使用 Thanos或者Victoriametrics,来解决全局查询、多副本数据 Join 问题。
就算使用官方建议的多副本+联邦,仍然会遇到一些问题:
官方建议数据做Shard,然后通过Federation来实现高可用,
但是边缘节点和Global节点依然是单点,需要自行决定是否每一层都要使用双节点重复采集进行保活。
本质原因是,Prometheus的本地存储没有数据同步能力,要在保证可用性的前提下,再保持数据一致性是比较困难的,基础的HA Proxy满足不了以下要求,比如:集群的后端有A和B两个实例,A和B之间没有数据同步。A 宕机一段时间,丢失了一部分指标数据,如果负载均衡正常轮询,请求打到 A 上时,数据就会异常。
1.5.2增强高可用的Prometheus数据一致性的思路
解决方案是可以从存储、查询两个角度上保证数据的一致。
1.5.2.1 存储角度
如果使用 Remote Write 远程存储, A和B后面可以都加一个Adapter,Adapter做选主逻辑,只有一份数据能推送到 TSDB,这样可以保证一个异常,另一个也能推送成功,数据不丢,同时远程存储只有一份,是共享数据。
1.5.2.2 查询角度
存储角度的解决方案实现很复杂且有一定风险,因此现在的大多数方案在查询层面做文章,比如Thanos或者Victoriametrics,仍然是两份数据,但是查询时做数据去重和Join。只是Thanos是通过Sidecar把数据放在对象存储,Victoriametrics是把数据Remote Write 到自己的Server实例,但查询层Thanos-Query和Victor的Promxy的逻辑基本一致。
2 扩展Prometheus的解决方案
2.1 cortext
2.1.1 概述
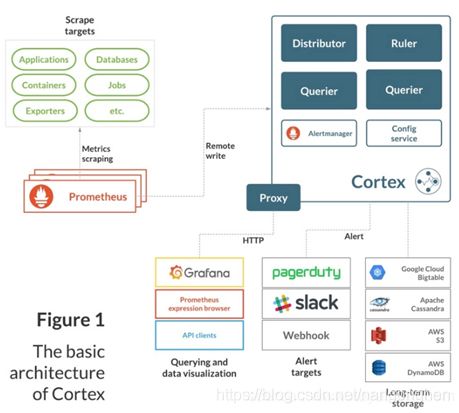
Cortex(https://cortexmetrics.io)为Prometheus提供了水平可扩展,高可用性,多租户的长期存储。目前在cncf 沙箱孵化。
Cortex为Prometheus提供了水平可扩展,高可用性,多租户的长期存储。Cortex是一个CNCF沙箱项目,用于多个生产系统,包括Weave Cloud和Grafana Cloud。Corte主要用作Prometheus的远程写入的存储,它提供与Prometheus兼容的查询API。
2.1.2行业实践

2.1.3 特点
1)水平可扩展:Cortex可以跨集群中的多台机器运行,超过了单台机器的吞吐量和存储量。这使您能够将指标从多个Prometheus服务器发送到单个Cortex群集,并在单个位置跨所有数据运行“全局聚合”查询。
1)高度可用:在集群中运行时,Cortex可以在机器之间复制数据。这样,您就可以在机器故障中幸存下来,而不会在图表中留下空白。
多租户:Cortex可以将数据和查询与单个群集中的多个不同独立Prometheus源隔离,从而使不受信任的各方共享同一群集。
1)长期存储:Cortex支持Amazon DynamoDB,Google Bigtable,Cassandra,S3和GCS来长期存储度量标准数据。这样一来,您可以持久地存储数据,其时间长于任何一台计算机的生命周期,并将此数据用于长期容量规划。
2.1.4 架构

2.1.5 社区活跃度
1)commit的提交分布:
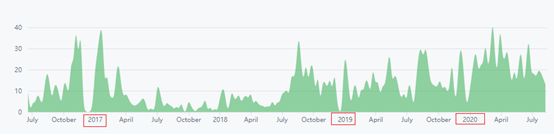
2)代码贡献者有136人。
3)issue数量为211。
4)github星星数量为3K。
2.2 VictoriaMetrics
2.2.1 概述
VictoriaMetrics是一种快速,经济高效且可扩展的时间序列数据库。
它在二进制发行版,Docker映像和源代码中可用。
VictoriaMetrics也提供付费企业支持。
业界实践:Adidas、COLOPL、Wix.com、Wedos.com等公司。
例如:日本游戏公司 COLOPL,三个集群对接到VictoriaMetrics。
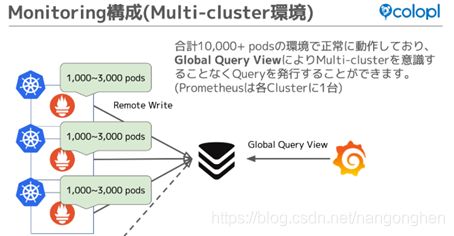
2.2.2 架构
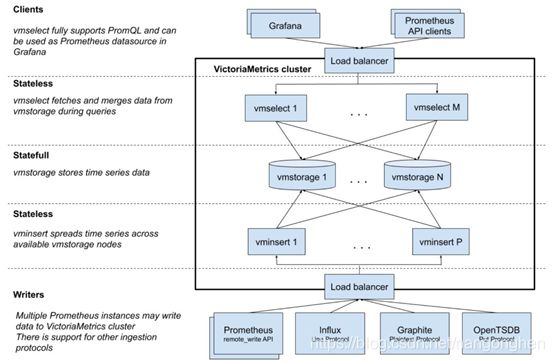
2.2.3社区活跃度
1)commit的提交分布:
2)代码贡献者有39人。
3)issue数量为141。
4)github星星数量为2.8K。
2.3 Thanos
2.3.1 概述
诞生于2018年9月,Thanos是一系列组件,基于Prometheus之上的可以组成具有无限存储容量的高可用性指标系统。Thanos是CNCF沙箱项目。Thanos利用Prometheus 2.0存储格式在任何对象存储中经济高效地存储历史指标数据,同时保留快速查询延迟。另外,它提供了所有Prometheus安装的全局查询视图,并且可以即时合并Prometheus HA对中的数据。
2.3.2 公司实践

2.3.3 架构

2.3.4 特点
1)提供全局查询视图。
2)支持主流对象存储,以提供可靠的历史数据存储。
3)支持降准采样,以提供更大时间范围的指标。
2.3.5 核心组件
2.3.5.1 Thanos sidecar
Sidecar作为一个单独的进程和已有的Prometheus实例运行在一个server上,互不影响。Sidecar可以视为一个Proxy组件,所有对Prometheus的访问都通过Sidecar来代理进行。通过Sidecar还可以将采集到的数据直接备份到云端对象存储服务器。
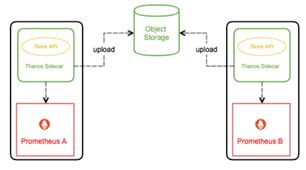
2.3.5.2 Thanos store gateway
Store gateway实现了一套和Sidecar完全一致的API提供给Querier用于查询Sidecar备份到云端对象存储的数据。因为Sidecar在完成数据备份后,Prometheus会清理掉本地数据保证本地空间可用。所以当监控人员需要调取历史数据时只能去对象存储空间获取,而Store就提供了这样一个接口。Store Gateway内部还做了一些加速数据获取的优化逻辑,一是缓存了 TSDB 索引,二是优化了对象存储的远程调用请求 (用尽可能少的请求量拿到所有需要的数据)。
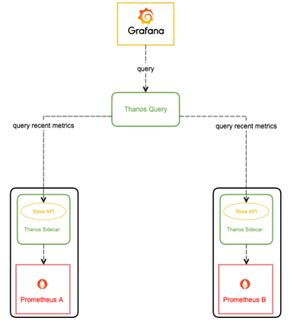
2.3.5.3 Thanos query
Querier从Sidecar和Store gateway获取指标数据,同时Querier实现了一套Prometheus官方的HTTP API从而保证对外提供与Prometheus一致的数据源接口,Grafana可以通过同一个查询接口请求不同集群的数据,Querier负责找到对应的集群并通过Sidecar获取数据,也能从Store gateway获取指标数据。Querier本身也是无状态的、可水平可扩展的,因而可以实现高可部署。Querier可以实现对高可部署的Prometheus的数据进行合并从而保证多次查询结果的一致性,从而解决全局视图和Prometheus高可用的问题。
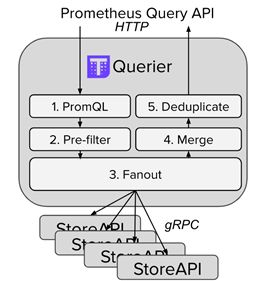
Thanos Query查询位于下游的Thanos Sidecar的指标数据,而Thanos Sidecar的指标数据来自与其绑定的Prometheus实例。
2.3.5.4 Thanos ruler
对监控数据进行评估和告警,还可以计算出新的监控数据,将这些新指标数据提供给 Thanos Query 查询,上传指标数据到对象存储,以供长期存储。
2.3.5.5 Thanos compactor
通常在查看较大时间范围的监控数据时,很多时候并不需要那么详细的数据,更多时候是为了得到数据趋势。compactor读取对象存储的数据,对其进行压缩以及降采样后再上传到对象存储,在查询大时间范围数据时就只读取压缩和降采样后的数据,极大地减少了查询的数据量,从而加速查询。
注意:Compact 组件并不会减少对象存储的使用空间,而是会增加,因为增加更长采样间隔的指标数据。如此一来,当查询大时间范围的数据时,就自动拉取更长时间间隔采样的数据以减少查询数据的总量,从而加快查询速度(大时间范围的数据不需要很精细的指标,需要的是趋势),当放大往细节查看时 (选择其中一小段时间),又自动选择拉取更短采样间隔的数据,从而也能显示出小时间范围的监控细节。
2.3.6.社区活跃度


代码贡献者有253人。
issue数量为120个。
星星数量为6.2K(在所有扩展Prometheus方案中最高)。
3 个人thanos实践和测试
在Kubernetes集群中测试部署了Qhanos Sidecar、Thanos Query、Thanos Store Gateway、Thanos Ruler组件,版本为2020年1月发布的v0.11。
3.1.Thanos Sidecar
Thanos Sidecar以边车形式和Prometheus处于同一个Pod中,由于Prometheus散落在多个集群中,因此Thanos Sidecar位于多个集群中。prometheus和thanos sidecar是通过prometheus-operator来进行部署。thanos sidecar也通过nodePort方式的暴露(由于一个集群有2个thanos sidecar,因此分为设置nodePort为10901和10902)。thanos sidecar暴露的原因是作为位于其他集群的thanos query组件的后端存储。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.mirrors.ustc.edu.cn/prometheus/prometheus:v2.15.2
nodeSelector:
kubernetes.io/os: linux
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.15.2
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
thanos:
baseImage: quay.mirrors.ustc.edu.cn/thanos/thanos
version: v0.11.0
objectStorageConfig:
key: objectstorage.yaml
name: thanos-objectstorage
externalLabels:
cluster: test
apiVersion: v1
kind: Service
metadata:
labels:
app: thanos-sidecar
statefulset.kubernetes.io/pod-name: prometheus-k8s-0
name: thanos-sidecar-0-external
namespace: monitoring
spec:
externalTrafficPolicy: Cluster
ports:
- name: grpc
nodePort: 10901
port: 10901
protocol: TCP
targetPort: grpc
selector:
prometheus: k8s
statefulset.kubernetes.io/pod-name: prometheus-k8s-0
sessionAffinity: None
type: NodePort
----
apiVersion: v1
kind: Service
metadata:
labels:
app: thanos-sidecar
statefulset.kubernetes.io/pod-name: prometheus-k8s-1
name: thanos-sidecar-1-external
namespace: monitoring
spec:
externalTrafficPolicy: Cluster
ports:
- name: grpc
nodePort: 10902
port: 10901
protocol: TCP
targetPort: grpc
selector:
prometheus: k8s
statefulset.kubernetes.io/pod-name: prometheus-k8s-1
sessionAffinity: None
type: NodePort
3.2 Thanos query
Thanos Query是无状态服务,以Deployment形式、双副本部署在一个独立集群中。通过配置文件的方式指定位于其他集群中的thanos sidecar。
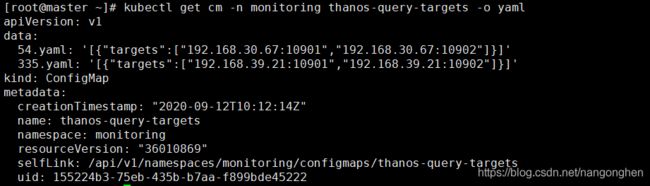
说明:
1)开启部分响应特性,此时在部分后端 Store API 返回错误或超时的情况下也能查询到正确的监控数据(如果后端 Store API 做了高可用,挂掉一个副本,Query访问挂掉的副本超时,但由于还存在其他可用的副本,于是客户端能获取正确的查询结果;如果挂掉的某个后端本身就不存在客户端需要的数据,挂掉也不影响查询结果的正确性)。
2)开启查询时自动降采样的特性,以提供查询效率。
3.3 Thanos store gateway
store gateway以StatefulSet形式、双副本部署在一个独立集群中。为它创建Kubernetes headless service,用于 Thanos Query组件对Store Gateway进行服务发现。
3.4 Thanos ruler
Thanos ruler以StatefulSet形式、双副本部署在一个独立集群(和thanos query同一个集群)中。为它创建Kubernetes headless service,用于 Thanos Query组件对Thanos Ruler进行集群内的服务发现。另外我制作了一个小镜像用于让ruler组件重载配置文件,在规则文件被修改的时候。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: thanos-rule
name: thanos-rule
namespace: monitoring
spec:
clusterIP: None
ports:
- name: grpc
port: 10901
targetPort: grpc
- name: http
port: 10902
targetPort: http
selector:
app.kubernetes.io/name: thanos-rule
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: thanos-rule
name: thanos-rule
namespace: monitoring
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: thanos-rule
serviceName: thanos-rules
podManagementPolicy: Parallel
template:
metadata:
labels:
app.kubernetes.io/name: thanos-rule
spec:
serviceAccount: thanos-rules
containers:
- name: reloader
image: registry.cn-shenzhen.aliyuncs.com/gzlj/thanos-reloader:v0.1
imagePullPolicy: Always
resources:
limits:
cpu: 100m
memory: 100Mi
- args:
- rule
- --grpc-address=0.0.0.0:10901
- --http-address=0.0.0.0:10902
- --rule-file=/etc/thanos/rules/*rules.yaml
- --objstore.config-file=/etc/thanos/objectstorage.yaml
- --data-dir=/var/thanos/rule
- --label=rule_replica="$(NAME)"
- --alert.label-drop="rule_replica"
- --query=dnssrv+_http._tcp.thanos-query.monitoring.svc.cluster.local
- --alertmanagers.url=http://alertmanager-main.monitoring.svc.cluster.local:9093
env:
- name: NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
image: quay.mirrors.ustc.edu.cn/thanos/thanos:v0.11.0
livenessProbe:
failureThreshold: 24
httpGet:
path: /-/healthy
port: 10902
scheme: HTTP
periodSeconds: 5
name: thanos-rule
ports:
- containerPort: 10901
name: grpc
- containerPort: 10902
name: http
readinessProbe:
failureThreshold: 18
httpGet:
path: /-/ready
port: 10902
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 5
terminationMessagePolicy: FallbackToLogsOnError
volumeMounts:
- mountPath: /var/thanos/rule
name: data
readOnly: false
- name: thanos-objectstorage
subPath: objectstorage.yaml
mountPath: /etc/thanos/objectstorage.yaml
- name: thanos-rules
mountPath: /etc/thanos/rules
volumes:
- name: thanos-objectstorage
secret:
secretName: thanos-objectstorage
- name: thanos-rules
configMap:
name: thanos-rules
- name: data
emptyDir: {}
3.5 实验测试结果
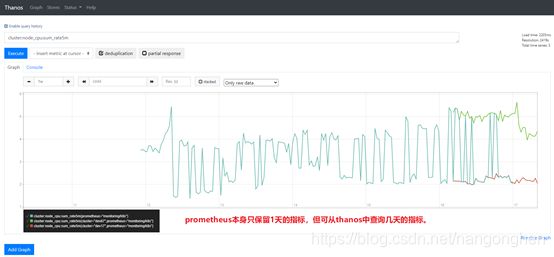
3.5.1 查询超过Prometheus指标保留时间范围的指标
3.5.2统一的查询面板
在Prometheus的配置文件中指定了名称为cluster的external label之后,在Thanos Query UI中可一次查询所有Prometheus实例和对象存储中的指标,并且指标出现external label以便用户区分指标来自哪个Kubernetes集群,结果如下图所示:

3.5.3记录新指标
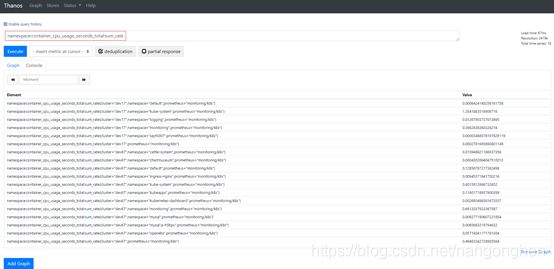
Thanos rule 规则文件兼容Prometheus规则文件,编写Thanos rule 规则文件并以configmap形式保存至Kubernetes集群中。configmap的内容一旦更新,ruler实例中的专门用于重载配置文件的容器会发送http请求到ruler容器以提醒ruler组件进行重载配置。

在Thanos Query UI中可查询新指标:
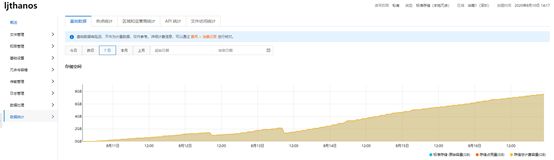
3.5.4 对象存储使用量消耗趋势
对于一个节点数量为6的kuberntes集群(指标主要来自kubelet服务、node-exporter服务、kube-apiserver等核心服务),则一个Prometheus实例采集一天的指标容量的为1.5G-2G。

让一个对象存储桶同时保存来自一个节点数量为3的Kubernetes集群和节点数量为6的Kubernetes集群(两个集群的指标主要来自kubelet服务、node-exporter服务、kube-apiserver等核心服务)的指标,每天约增加2 G的使用量,使用容量增长趋势下图所示。