PythonPrimer
Python Primer
- 前言
- Python简介
- 创建Python运行环境
-
- 安装Python interpreter
- 安装Python module
- 创建第一个Python程序
- Python基础
-
- 注释
- 操作符
- 布尔值和空值
- Numbers
- String
- 逻辑行和物理行
- 控制流
- 简单容器
- 迭代器和生成器
- 变量作用域
- 函数
-
- 位置参数
- 默认参数
- 关键字参数
- 可变参数
- Lambda 表达式
- 练习题
- 函数式编程
-
- 高阶函数
- 返回函数和闭包
- 装饰器
- 偏函数
- 练习题
- OOP
-
- OOP基础
- 特殊变量和属性
- 枚举类
- 元类
- object和type
- 文件与IO
-
- input和print
- 文件读写
- StringIO和BytesIO
- pikle
- 并发编程
-
- 进程
- 线程
- 分布式进程
- 协程
- 异步IO
- 练习题
- 网络编程
-
- Socket编程
- HTTP编程
- 邮件
- 数据库
- Web框架
前言
Python作为一门热门语言,从来不缺乏Programmers的喜爱,作为即将从事人工智能行业的我们,就更得学好这门语言,学会利用这门语言的优势来在未来的研究中收获满满!
学习编程以来,从未系统认真地学好一门语言,更从未做好一门语言的学习笔记。我希望这本Python Primer作为我学习历史的转折点,能够使我改变在以往的学习过程中学习方式,并且在以后的学习生活中养成良好的学习方法以及学习习惯。
本书适用于对计算机基础知识包括计算机网络、计算机组成原理等有很一定的了解的人,如果是小白建议在看本书之前学习一点相关基础知识。
本书的很多例子引用自python-cookbook和网上一些blog,由于才疏学浅以及自身的不够细致,书中难免会有一些疏漏,敬请各位读者指出,并发送邮件给我。
本书只是基础性入门,在后面我可能会写关于对Python深入应用的实战案例作为我的下一本书!敬请期待!
2019.06.30
Python简介
Python is an easy to learn, powerful programming language. It has efficient high-level data structures and a simple but effective approach to object-oriented programming. Python’s elegant syntax and dynamic typing, together with its interpreted nature, make it an ideal language for scripting and rapid application development in many areas on most platforms.
引用自Python官方文档
创建Python运行环境
安装Python interpreter
Python是跨平台,在任意平台编写的程序,在任何平台都能运行。
- Windows 和 Mac
自行去官网下载Python安装包,如果龟速的话,可以去镜像去下载。
- Linux
For GNU/Linux users, use your distribution’s package manager to install Python 3, e.g. on
Debian & Ubuntu: sudo apt-get update && sudo apt-get install python3 .
For GNU/Linux users, use your distribution’s package manager to install Python 3, e.g. on
Centos: sudo yum install python3 .
- 科研
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大,如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。下载地址
安装Python module
要安装一个模块必须知道模块的名字,然后使用命令:
pip install numpy
创建第一个Python程序
Python是交互式脚本语言,在命令行运行后程序无法运行。我们可以使用文件将所要执行的代码保存到文件中,然后执行这个程序就行。
# hello.py
print('Hello Python!')
# Result: Hello Python!
Python基础
注释
注释的作用:使得代码更具有阅读性;记录相关的问题。Python中注释以#来代表注释
# Note that print is a function
print('hello world') # Note that print is a function
操作符
- 基本四则运算和常用的数学运算符
+ - * /基本运算符//做除法并且向下取整%求模**求乘方+=一般用于i = i + 1的简写i += 1
- 位运算相关
<<和>>二进制左移和右移& | ^ ~与、或、异或、非
- 逻辑运算相关
< > <= >= == !=小于、大于、小于等于、大于等于、等于、不等于and, or, not与或非
布尔值和空值
布尔值:True 和 False
空值:None
while True:
if child is None:
break
else:
child += children
Numbers
Python只有两种数字类型:integers and floats
# numbers.py
a = 2
b = 1.222
c = 1.3E4
print(a, b, c)
# Result: 2 1.222 13000.0
String
- 引号
单引号和双引号用法是一样的,因此'python' 和 "python" 是一样的,没有任何区别。
三引号(''' 或者 """)适用于多行字符串,例如:
'''Hello python
Hello world'''
- 格式化
Python 提供类似C格式化方法:占位符
>>> '%2d - %02d' % (3, 1)
>>> 'hello %s' % 'world'
>>> '%.2f' % 2.023
format函数可以将字符串进行格式化:
# str_format.py
age = 20
name = 'Python'
print('I am {0} and {1} years old'.format(name, age))
print('I am {} and {} years old'.format(name, age))
print('I am {name} and {age} years old'.format(name=name, age=age))
print(f'I am {name} and {age} years old')
# Result: I am Python and 20 years old
fotmat函数还能进行一些特殊的格式化:
# decimal (.) precision of 3 for float '0.333'
print('{0:.3f}'.format(1.0/3))
# fill with underscores (_) with the text centered
# (^) to 11 width '___hello___'
print('{0:_^11}'.format('hello'))
# keyword-based 'Swaroop wrote A Byte of Python'
print('{name} wrote {book}'.format(name='Swaroop', book='A Byte of Python'))
- 拼接
- 使用
+进行拼接,但是效率有点低- 使用
join进行拼接,相对而言比较好的- 对于两个字面量的字符串,只需要简单的将它们放到一起,不需要用任何操作符或者函数
# for '+'
s = ''
for p in parts:
s += p
# for join
data = ['ACME', 50, 91.1]
print(','.join(str(d) for d in data))
# Result: 'ACME,50,91.1'
# for two const string
v = 'Hello' 'world'
最后还得注意不必要的字符串连接操作。有时候程序员在没有必要做连接操作的时候仍然多此一举。比如在打印的时候:
print(a + ':' + b + ':' + c) # Ugly
print(':'.join([a, b, c])) # Still ugly
print(a, b, c, sep=':') # Better
For more combining and concatenating strings, you can go there.
逻辑行和物理行
在Python里 逻辑行是指一句完整的代码行,例如:print('Hello Python'),物理行就是在显示器上所显示的一行。
但是往往有时候我们会遇到一行很长的代码,这时为了使得整个代码看起来舒适,我们会对代码进行划分,例如:
str_display = 'la la la la la la la \
duo duo duo duo duo'
print(str_display)
# Result: la la la la la la la duo duo duo duo duo
控制流
if
使用if语句进行条件判断,else和elif是另外的分支。
number = 23
guess = int(input('Enter an integer : '))
if guess == number:
# New block starts here
print('Congratulations, you guessed it.')
print('(but you do not win any prizes!)')
# New block ends here
elif guess < number:
# Another block
print('No, it is a little higher than that')
# You can do whatever you want in a block ...
else:
print('No, it is a little lower than that')
# you must have guessed > number to reach here
print('Done')
# This last statement is always executed,
# after the if statement is executed.
Note for C/C++/Java/etc. Programmers
There is nocondition ? then : elseoperator for python, you can usevariable if condition else variableinstead.
while
while语句允许你一直执行某个块,只要条件为真。while语句能够有一个else分支。
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
else:
print('loop is over')
print(sum)
for
for...in...是另一种循环语句,它能够对序列进行迭代。跟while语句一样也能够有一个else分支。
sum = 0
for x in range(101):
sum = sum + x
else:
print('The loop is over')
print(sum)
break
break语句被用于跳出一层循环
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')
continue
在循环过程中,也可以通过continue语句,跳过当前的这次循环,直接开始下一次循环。
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print语句不会执行
print(n)
简单容器
list
list在Python中是一种有序的集合,可以随时添加和删除其中的元素。一般来说,list中的元素都是同类型的,但是有时可以包含不同类型。
nums = [0, 1, 4, 9, 16] # It is equivalent to nums = [d ** 2 for d in range(5)]
# 通过index访问
print(nums[0]) # Result: 0
print(nums[-1]) # Result: 16
# 正序遍历, 步长为1
for i in nums:
print(i, end=' ')
# 逆序遍历, 步长为1
for i in nums[::-1]
print(i, end=' ')
# 增、删
nums.append(5 * 5) # nums = [0, 1, 4, 9, 16, 25]
nums.insert(7, 36) # nums = [0, 1, 4, 9, 16, 25, 36]
nums.pop # 36 被删除
nums.pop(6) # 25 被删除
tuple
和list很类似,只不过不能修改。
nums = (1, 3, 5, 7, 9)
# Notice
t = # t is a tuple
t_1 = (1) # t_1 is not a tuple
t_2 = (1,) # t_2 is a tuple
# We can modify the tuple indirectly
p = (1, 2, [3, 4])
p[2][0] = 1 # the pointer to the list is not modified
p[2][1] = 2
print(p) # Result: (1, 2, [1, 2])
dict
dict 是Python 中很有用的数据类型,在其他编程语言中被称之为 associative arrays 或者 map 。
# creat dict
a = dict(one=1, two=2, three=3)
b = {
'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3])) # zip(['one', 'two', 'three'], [1, 2, 3])打包成元组
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({
'three': 3, 'one': 1, 'two': 2})
print(a == b == c == d == e)
# check key
print('five' in c )
# read
print(d['three'])
print(d.get('three'))
print(d.get('five', 5)) # Return the value for key if key is in the dictionary, else default. If default is not given, it defaults to None
# remove, delet
a.pop('one')
del b['one']
set
Python 也有集合类的数据类型,set 是无序且没有重复的元素的。一般用于消除重复和存在测试,同时还支持数学集合运算。
# basic operate
s = {
1, 2, 3, 4}
t = {
-1, -2, -3, -4}
s & t # nums in both a and b
s | t # nums in a or b or both
s - t # nums in a but not in b
s ^ t # nums in a or b but not in both
a = {
x for x in s if x not in t} # s - t
# add remove
s.add(5)
s.remove(5)
迭代器和生成器
- 迭代器
如何对一个可迭代对象进行遍历,但却不使用for循环呢?
为了手动的遍历可迭代对象,使用 next 函数并在代码中捕获 StopIteration 异常。 比如,下面的例子手动读取一个文件中的所有行:
def manual_iter:
with open('/etc/passwd') as f:
try:
while True:
line = next(f)
print(line, end='')
except StopIteration:
pass
通常来讲, StopIteration 用来指示迭代的结尾。 然而,如果你手动使用上面演示的 next 函数的话,你还可以通过返回一个指定值来标记结尾,比如 None 。 下面是示例:
with open('/etc/passwd') as f:
while True:
line = next(f, None)
if line is None:
break
print(line, end='')
- 生成器
如何实现一个自定义迭代模式,跟普通的内置函数比如 range , reversed 不一样。
如果你想实现一种新的迭代模式,使用一个生成器函数来定义它。 下面是一个生产某个范围内浮点数的生成器:
def frange(start, stop, increment):
x = start
while x < stop:
yield x
x += increment
为了使用这个函数, 你可以用for循环迭代它或者使用其他接受一个可迭代对象的函数(比如 sum , list 等)。
yield
简单地讲,yield的作用就是把一个函数变成一个generator,带有 yield 的函数不再是一个普通函数,Python解释器会将其视为一个generator,下次迭代时,代码从yield b的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到yield。
yield from
鉴于在生成器中调用生成器比较麻烦,所以有了yield from语法,用于简化嵌套调用生成器的语法复杂度。
- 练习题
如何实现一个以深度优先方式遍历树形节点的生成器?
class Node:
def __init__(self, value):
self._value = value
self._children = []
def __repr__(self):
return 'Node({!r})'.format(self._value)
def add_child(self, node):
self._children.append(node)
def __iter__(self):
return iter(self._children)
def depth_first(self):
pass
- 思考下面的代码和你实现代码有何不同?
class Node:
def __init__(self, value):
self._value = value
self._children = []
def __repr__(self):
return 'Node({!r})'.format(self._value)
def add_child(self, node):
self._children.append(node)
def __iter__(self):
return iter(self._children)
def depth_first(self):
return DepthFirstIterator(self)
class DepthFirstIterator(object):
'''
Depth-first traversal
'''
def __init__(self, start_node):
self._node = start_node
self._children_iter = None # 当前结点所有迭代子节点
self._child_iter = None # 当前迭代路径的子节点
def __iter__(self):
return self
def __next__(self):
# Return myself if just started; create an iterator for children
if self._children_iter is None:
self._children_iter = iter(self._node) # proxy
return self._node
# If processing a child, return its next item
elif self._child_iter:
try:
nextchild = next(self._child_iter) # It may raise a StopIteration, but when?
return nextchild
except StopIteration:
self._child_iter = None
return next(self)
# Advance to the next child and start its iteration
else:
self._child_iter = next(self._children_iter).depth_first
return next(self)
变量作用域
在Python中,使用一个变量时并不严格要求需要预先声明它,但是在真正使用它之前,它必须被绑定到某个内存对象(被定义、赋值);这种变量名的绑定将在当前作用域中引入新的变量,同时屏蔽外层作用域中的同名变量。
L(local)局部作用域
局部变量:包含在def关键字定义的语句块中,即在函数中定义的变量。每当函数被调用时都会创建一个新的局部作用域。Python中也有递归,即自己调用自己,每次调用都会创建一个新的局部命名空间。在函数内部的变量声明,除非特别的声明为全局变量,否则均默认为局部变量。有些情况需要在函数内部定义全局变量,这时可以使用global关键字来声明变量的作用域为全局。局部变量域就像一个 栈,仅仅是暂时的存在,依赖创建该局部作用域的函数是否处于活动的状态。所以,一般建议尽量少定义全局变量,因为全局变量在模块文件运行的过程中会一直存在,占用内存空间。
注意:如果需要在函数内部对全局变量赋值,需要在函数内部通过global语句声明该变量为全局变量。
E(enclosing)嵌套作用域
E也包含在def关键字中,E和L是相对的,E相对于更上层的函数而言也是L。与L的区别在于,对一个函数而言,L是定义在此函数内部的局部作用域,而E是定义在此函数的上一层父级函数的局部作用域。主要是为了实现Python的闭包,而增加的实现。
G(global)全局作用域
即在模块层次中定义的变量,每一个模块都是一个全局作用域。也就是说,在模块文件顶层声明的变量具有全局作用域,从外部开来,模块的全局变量就是一个模块对象的属性。
注意:全局作用域的作用范围仅限于单个模块文件内
B(built-in)内置作用域
系统内固定模块里定义的变量,如预定义在builtin 模块内的变量。
观察下面两段代码:
# code 1
cnt = 1
def count:
cnt += 4
return cnt
# code 2
def count:
cnt = 0
def f:
cnt += 1
return cnt
return f
以上两段代码都会报错,原因都是cnt没有初始化值。
这是为什么?不是给cnt赋值了?
在code 1里,由于count函数里对cnt 进行了赋值操作,因此count函数把cnt看作局部变量
而code 2里,由于f函数里对cnt 进行了赋值操作,使得cnt从嵌套变量变成局部变量
如何修改使得代码能够正确的运行呢?
对于code 1我们只需在count函数内部将cnt声明为全局就行即global cnt
对于code 1我们只需在count函数内部将cnt声明为嵌套就行即nonlocal cnt
函数
如何打印出斐波那契数列?
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 ...
我们知道斐波那契数列,任意前两项(a, b)的和等于后一项(c),因此 c = a + b
def fib(n): # write Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
print(a, end=' ')
result.append(a) # see below
a, b = b, a+b
print
return result
位置参数
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
def ask_ok(prompt, retries=4, reminder='Please try again!'):
while True:
ok = input(prompt)
if ok in ('y', 'ye', 'yes'):
return True
if ok in ('n', 'no', 'nop', 'nope'):
return False
retries = retries - 1
if retries < 0:
raise ValueError('invalid user response')
print(reminder)
This function can be called in several ways:
giving only the mandatory argument: ask_ok(‘Do you really want to quit?’)
giving one of the optional arguments: ask_ok(‘OK to overwrite the file?’, 2)
or even giving all arguments: ask_ok(‘OK to overwrite the file?’, 2, ‘Come on, only yes or no!’)
关键字参数
函数能够通过使用 key=value这种形式的关键字参数进行调用。
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
parrot(action='VOOOOOM', voltage=1000000) # 2 keyword arguments
parrot('a million', 'bereft of life', 'jump') # 3 positional arguments
parrot('a thousand', state='pushing up the daisies') # 1 positional, 1 keyword
可变参数
函数如果给定的参数是不定,就需要可变参数
def write_multiple_items(file, separator, *args, **keyword):
file.write(separator.join(args))
print(keyword)
Python内置函数max,就是个可变函数,如果我们给定一个list,如何得到list的最大值?
l = [1, 2, 5, -1]
max(*l)
Lambda 表达式
小型匿名函数可以通过lambda关键字创建
def make_incrementor(n):
return lambda x: x + n
f = make_incrementor(30)
f(9)
练习题
Promblem 1
汉诺塔的移动可以用递归函数非常简单地实现。
请编写move(n, a, b, c)函数,它接收参数n,表示3个柱子A、B、C中第1个柱子A的盘子数量,然后打印出把所有盘子从A借助B移动到C的方法,例如:
def move(n, a, b, c):
if n == 1:
print(a, '-->', c)
pass
函数式编程
高阶函数
观察下面的交互过程:
>>> f = abs
>>> f(-10)
10
>>> f
>>> <built-in function abs>
在这个例子中,变量可以指向函数,函数的参数能接收变量。因此一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
map/reduce
简单来说,在函数式语言里,map表示对一个列表(list)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。
比如对某个list里的每一项进行平方,可以通过map进行:
list(map(lambda x : x * x, [1, 2, 3, 4, 5]))
# Result: [1, 4, 9, 16, 25]
值得注意的是:map函数接受两个参数,一个函数,一个是Iterable,并且把结果作为新的Iterator返回。
比如对某个list里的每一项进行求积,可以通过reduce进行:
print(reduce(lambda x, y : x * y, [1, 2, 3, 4, 5]))
# Result: 120
值得注意的是:reduce函数接受两个参数,一个函数,这个函数必须接收两个参数,一个是Iterable,并且返回某个值。
filter
filter把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
计算素数的一个方法是埃氏筛法,它的算法理解起来非常简单。
def primes(n):
def _not_divisible(n):
return lambda x: x % n > 0
yield 2
it = filter(_not_divisible(2), range(3, n))
while True:
try:
t = next(it)
yield t
it = filter(_not_divisible(t), it)
except StopIteration:
break;
sorted
这个函数很有用处,sorted函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,如果要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True。
Python3.x 已经在sorted函数内不支持使用自定义的cmp函数,只能使用key函数,但是却提供了cmp函数到key函数转换工具functools.cmp_to_key(cmp),源代码如下:
def cmp_to_key(cmp):
"""Convert a cmp= function into a key= function"""
class K(object):
__slots__ = ['obj']
def __init__(self, obj):
self.obj = obj
def __lt__(self, other):
return cmp(self.obj, other.obj) < 0
def __gt__(self, other):
return cmp(self.obj, other.obj) > 0
def __eq__(self, other):
return cmp(self.obj, other.obj) == 0
def __le__(self, other):
return cmp(self.obj, other.obj) <= 0
def __ge__(self, other):
return cmp(self.obj, other.obj) >= 0
__hash__ = None
return K
sorted排序一定是稳定排序!This wonderful property lets you build complex sorts in a series of sorting steps.
更多关于排序请查看Sorting HOW To
from operator import itemgetter, attrgetter
# To sort the data by descending total grade, the descending first grade, the descending second grade
# and then the ascending name.
data = [('Bob', 90, 100), ('Jack', 95, 95), ('Tom', 60, 100), ('Jakson', 95, 95)]
# To sort the data by ascending name
data = sorted(data, key=itemgetter(0))
# To sort the data by descending second grade
data = sorted(data, key=itemgetter(2), reverse=True)
# To sort the data by descending first grade
data = sorted(data, key=itemgetter(1), reverse=True)
#To sort the data by descending total grade
data = sorted(data, key=lambda x : x[1] + x[2], reverse=True)
print(data)
# Result: [('Jack', 95, 95), ('Jakson', 95, 95), ('Bob', 90, 100), ('Tom', 60, 100)]
返回函数和闭包
既然函数能够作为变量,变量能够作为返回值,那么函数也能作为返回值。
def return_fun(a, b):
def fun(n):
return lambda x : x + n
return fun(a)(b)
print(return_fun(1, 2))
在使用闭包的时候要注意,返回的函数并没有立刻执行,而是直到调用了f才执行。
def count:
fs = []
for i in range(1, 4):
def f:
return i*i
fs.append(f)
return fs
f1, f2, f3 = count
print(f1, f2, f3) #999
全部都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count:
def f(j):
def g:
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f
return fs
装饰器
什么是装饰器?装饰器本质上讲就是返回高阶函数的函数,能够在被装饰的函数执行前后,进行特定操作的的函数!
def decorator(func):
def wrapper(*args, **kw):
print('call %s:' % func.__name__)
return func(*args, **kw)
return wrapper
@decorator # thing = decorator(thing)
def thing:
pass
thing # call thing
print(thing.__name__) # wrapper
以上两种decorator的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有__name__等属性,但你去看经过decorator装饰之后的函数,它们的__name__已经从原来的'now'变成了'wrapper'。
def log(func):
def wrapper(*args, **kw):
print('call %s:' % func.__name__)
return func(*args, **kw)
return wrapper
def test:
pass
test = log(test)
print(test.__name__)
test
所以,一个完整的decorator的写法如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s:' % func.__name__)
return func(*args, **kw)
return wrapper
装饰器的用途很多,比如设计一个decorator,它可作用于任何函数上,并打印该函数的执行时间。
def metric(fn):
@functools.wraps(fn)
def wrapper(*args,**kw):
start=time.time
re=fn(*args,**kw)
end=time.time
print('%s executed in %s ms' % (fn.__name__, end-start))
return re
return wrapper
装饰器也能带有参数:
def logged(level, name=None, message=None):
"""
Add logging to a function. level is the logging
level, name is the logger name, and message is the
log message. If name and message aren't specified,
they default to the function's module and name.
"""
def decorate(func):
logname = name if name else func.__module__
log = logging.getLogger(logname)
logmsg = message if message else func.__name__
@wraps(func)
def wrapper(*args, **kwargs):
log.log(level, logmsg)
return func(*args, **kwargs)
return wrapper
return decorate
# Example use
@logged(logging.DEBUG)
def add(x, y):
return x + y
@logged(logging.CRITICAL, 'example')
def spam:
print('Spam!')
偏函数
观察下面的代码:
# code 1
pro = ts.pro_api
data = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
# code 2
pro = ts.pro_api
data = pro.query('stock_basic', exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
这两段代码非常相似,但实际上stock_basic函数并不存在,只是通过某种技术间接调用了query函数,而这种技术就是本小节所要说的偏函数。
下面就是偏函数的大致实现思路:
def partial(func, *args, **keywords):
def newfunc(*fargs, **fkeywords):
newkeywords = keywords.copy
newkeywords.update(fkeywords)
return func(*args, *fargs, **newkeywords)
newfunc.func = func
newfunc.args = args
newfunc.keywords = keywords
return newfunc
从原理上讲偏函数和装饰器很像,都是返回高阶函数。
对于
code 1是如何具体实现的我们到OOP一节继续为你揭秘。
练习题
Promblem 1
给定n个学生的信息:name, age, grade_1, grade_2,按照如下要求编写代码:
- 输出n个学生的平均分和平均年龄
- 输出每一门都及格的学生信息,输出顺序按总成绩从高到底,如果总成绩相同则比较第一门成绩,再有相同就比较第二门,还有相同就按名字的字母顺序比较
- 总成绩的计算方法为 g r a d e t = 0.6 × g r a d e 1 + g r a d e 2 × 0.4 grade_t = 0.6 \times grade_1 + grade_2 \times 0.4 gradet=0.6×grade1+grade2×0.4
- 要求使用
map, reduce, filter, sorted
OOP
面向对象编程(Object Oriented Programming),是一种程序设计思想。OOP 的一条基本原则是计算机程序是由单个能够起到子程序作用的单元或对象组合而成。
面向过程编程,就是以过程为中心即面向问题的解决步骤,用函数把这些步骤一步一步实现,使用的时候一个一个依次调用。
下面以例子来阐述两者的区别:
某在线商店只销售一种货物
A,货物A的单价为p,库存为n,请设计该在线商店的交易结算系统。
面向过程的程序可以这样写:
product_a = {
'name':'A', 'price':1.2, 'stock':1000}
def make_a_deal(num):
if product_a['stock'] - num >= 0:
product_a['stock'] -= num
return num * product_a['price']
else:
print('库存数量不足')
return None
面向对象的程序可以这样写:
class product(object):
def __init__(self, name, price, stock):
self.name = name
self.price = price
self.stock = stock
def __str__(self):
return f'product:{self.name} left:{self.stock} price:{self.price}'
class shop(object):
def __init__(self, stocks):
self.stocks = stocks
def make_a_deal(self, products_and_nums):
total = 0
for item in products_and_nums:
if item[0].stock - item[1] >= 0:
item[0].stock -= item[1]
total += item[1] * item[0].price
else:
print('{}库存数量不足'.format(item[0].name))
return total
online_shop = shop([product('A', 1.2, 1000)])
print(online_shop.make_a_deal([(online_shop.stocks[0], 500)]), online_shop.stocks[0])
从两段程序对比可以发现,面向对象的程序更具有一般性,如果要商店添加商品,那么面向过程的程序将要修改,而面向对象的程序几乎不用修改,而且扩展性更加强!
OOP基础
- 类与实例
物以类聚,世间万物都可以视为对象object,那么就有类class,类是抽象的模板,实例是根据类创建出来的一个个具体的“对象”。
在Python中,类是以下方式定义的:
class Test:
pass
想要获得一个实例化的对象可以这样:
test = Test
类对象支持两种操作:属性引用和实例化。
属性引用可以通过obj.name来达到,可以自由地给一个实例变量绑定属性,比如,给实例test绑定一个name属性。
test.name = 'haha'
print(test.name) # haha
而实例化就非常简单,只需通过test = Test就能搞定。实例化过程中一般会伴随着运行一些特殊的初始化块,比如__init__方法。当创建一个新的类实例时,在类内部定义的__init__方法会自动执行。
在Python中,属性分类属性和实例属性,类属性被所有的实例所共享,而实例属性只能属于实例自己。
class Animal:
count = 0
def __init__(self, name):
self.name = name
Animal.count += 1
dog = Animal('dog')
cat = Animal('cat')
print(dog.name, dog.count, sep=' ') # dog 2
print(cat.name, cat.count, sep=' ') # cat 2
print(Animal.count) # 2
- OOP特性
- 封装,就是通过抽象将对象的属性和行为进行封装,而将对象的属性和行为封装起来的载体就是类,类通常对客户隐藏其实现细节。
- 继承,就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
- 多态,是面向对象的程序设计语言最核心的特征。多态,意味着一个对象有着多重特征,可以在特定的情况下,表现不同的状态,从而对应着不同的属性和方法。
- 访问控制
封装过程中为了隐藏其实现细节,一般可以通过成员属性的可见性来限制对属性的访问。在Python中并没有绝对的属性访问控制,一般来说对于以__前缀的属性就变成了一个私有属性,只有内部可以访问,外部不能访问,但有时我们也会看到以_前缀的属性,根据规约我们将其看成私有属性。需要注意的是,在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的。之前说Python中并没有绝对的属性访问控制,是因为以__前缀的属性有时可以通过外部访问的,Python解释器会以一定的规则对__前缀的属性进行命名,当然不同版本的Python解释器各有不同。
在成员属性访问过程中,如果我们对私有属性获取属性值时怎么做?一般来说,都是通过属性访问控制器去访问的,比如getter, setter,但是Python却提供了一种很简单明了的方法去设置属性访问控制器。
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
参考资料
特殊变量和属性
__slots__
在正常情况下,我们可以任意给实例对象绑定属性,但是如果我们想要限制实例的属性怎么办?
为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性:
class Test
__slots__ = ('name', 'time')
使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的,除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
__str____repr__
__str__一般用于返回字符串,__repr__返回程序开发者看到的字符串,通常__str__和__repr__代码都是一样的:
class Test(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Test object (name=%s)' % self.name
__repr__ = __str__
__iter__
如果一个类想被用于for ... in循环,类似list或tuple那样,就必须实现一个__iter__方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。
我们以斐波那契数列为例,写一个Fib类,可以作用于for循环:
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration
return self.a # 返回下一个值
for n in Fib:
print(n)
__getattr____setattr__
__getattr____setattr__参数描述器
正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。比如前面的例子:
# code 1
pro = ts.pro_api
data = pro.stock_basic(exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
# code 2
pro = ts.pro_api
data = pro.query('stock_basic', exchange='', list_status='L', fields='ts_code,symbol,name,area,industry,list_date')
注意,只有在没有找到属性的情况下,才调用__getattr__,已有的属性。
下面展示一个嵌套调用属性的例子:
class Chain(object):
def __init__(self, path=''):
self._path = path
def __getattr__(self, path):
return Chain('%s/%s' % (self._path, path))
def __str__(self):
return self._path
__repr__ = __str__
Chain.status.user.timeline.list
__get____set____delete__
__get____set____delete__对象描述器
class Integer:
def __init__(self, name):
self.name = name
def __get__(self, instance, cls):
if instance is None:
return self
else:
return instance.__dict__[self.name]
def __set__(self, instance, value):
if not isinstance(value, int):
raise TypeError('Expected an int')
instance.__dict__[self.name] = value
def __delete__(self, instance):
del instance.__dict__[self.name]
class Point:
x = Integer('x')
y = Integer('y')
def __init__(self, x, y):
self.x = x
self.y = y
__enter____exit__
为了让一个对象兼容 with 语句,你需要实现__enter__和__exit__方法。
例如,考虑如下的一个类,它能为我们创建一个网络连接:
from socket import socket, AF_INET, SOCK_STREAM
class LazyConnection:
def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
self.address = address
self.family = family
self.type = type
self.sock = None
def __enter__(self):
if self.sock is not None:
raise RuntimeError('Already connected')
self.sock = socket(self.family, self.type)
self.sock.connect(self.address)
return self.sock
def __exit__(self, exc_ty, exc_val, tb):
self.sock.close
self.sock = None
这个类的关键特点在于它表示了一个网络连接,但是初始化的时候并不会做任何事情(比如它并没有建立一个连接)。 连接的建立和关闭是使用 with 语句自动完成的,例如:
from functools import partial
conn = LazyConnection(('www.python.org', 80))
# Connection closed
with conn as s:
# conn.__enter__ executes: connection open
s.send(b'GET /index.html HTTP/1.0\r\n')
s.send(b'Host: www.python.org\r\n')
s.send(b'\r\n')
resp = b''.join(iter(partial(s.recv, 8192), b''))
# conn.__exit__ executes: connection closed
__call__
一个对象实例可以有自己的属性和方法,当我们调用实例方法时,我们用instance.method来调用。能不能直接在实例本身上调用呢?在Python中,答案是肯定的。
任何类,只需要定义一个__call__方法,就可以直接对实例进行调用。
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
s = Student
s
前面讲到装饰器本质是个返回高阶函数的函数,那么通过__call__函数就能让装饰器用类表示:
import types
from functools import wraps
class Profiled:
def __init__(self, func):
wraps(func)(self)
self.ncalls = 0
def __call__(self, *args, **kwargs):
self.ncalls += 1
return self.__wrapped__(*args, **kwargs) # 执行func
def __get__(self, instance, cls): # 注意__get__(self, instance, cls)必不可少
if instance is None:
return self
else:
return types.MethodType(self, instance) # 在调用的时候自动传入被调用对象作为self参数
@Profiled
def add(x, y):
return x + y
class Spam:
@Profiled # bar = Profiled(bar)
def bar(self, x):
print(self, x)
s = Spam
s.bar(1) # 由于bar被Profiled装饰,因此对bar访问会触发__get__自动传入被调用对象作为self参数,然后调用__call__
# 如果没有__get__,那么直接调用__call__,就会导致丢失参数的错误:bar missing 1 required positional argument: 'x'
__new___
所有类都继承于object,因此所有类继承了__new__方法
object.__new__(cls[, …])
- Called to create a new instance of class
cls. __new__is a static method (special-cased so you need not declare it as such) that takes the class of which an instance was requested as its first argument. The remaining arguments are those passed to the object constructor expression (the call to the class). The return value of__new__should be the new object instance (usually an instance of cls).- Typical implementations create a new instance of the class by invoking the superclass’s
__new__method usingsuper.__new__(cls[, ...])with appropriate arguments and then modifying the newly-created instance as necessary before returning it.- If
__new__returns an instance of cls, then the new instance’s__init__method will be invoked like__init__(self[, ...]), where self is the new instance and the remaining arguments are the same as were passed to__new__.- If
__new__does not return an instance of cls, then the new instance’s__init__method will not be invoked.__new__is intended mainly to allow subclasses of immutable types (like int, str, or tuple) to customize instance creation. It is also commonly overridden in custom metaclasses in order to customize class creation.
class test(object):
def __new__(cls,*args):
print(cls.__new__)
return super.__new__(cls, *args)
def __init__(self, *args):
print(self.__init__)
t = test
print(type(t))
枚举类
Python提供了Enum类来实现这个枚举类功能:
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
这样定义出来的枚举量的值是默认的,我们也可以通过自定义枚举量:
from enum import Enum, unique
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
@unique装饰器可以帮助我们检查保证没有重复值。
元类
在Python中类被视作对象,那么既然被视做对象,总还有类来创建它,而这个类就是元类,元类的基类是type。
type创建类:type(class_name, (base_class,), dict(method_name=func))
def func(*args, **kwagrs):
pass
test = type('test', (object,), dict(test_func=func))
既然type能够创建类,那么是不是能够通过继承type实现自定义创建类?
答案是肯定的,Python通过metaclass实现自定义创建类:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return super.__new__(cls, name, bases, attrs)
class MyList(list, metaclass=ListMetaclass):
pass
metaclass=ListMetaclass实际上等同于Mylist = ListMetaclass(MyList.__qualname__, MyList.__bases__, dict(MyList.__dict__))
那么动态创建类有什么用呢?
ORM就是一个典型的例子。ORM全称Object Relational Mapping,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
要编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
首先来定义Field类,它负责保存数据库表的字段名和字段类型:
class Field(object):
def __init__(self, name, column_type):
self.name = name
self.column_type = column_type
def __str__(self):
return '<%s:%s>' % (self.__class__.__name__, self.name)
在Field的基础上,进一步定义各种类型的Field,比如StringField,IntegerField等等:
class StringField(Field):
def __init__(self, name):
super(StringField, self).__init__(name, 'varchar(100)')
class IntegerField(Field):
def __init__(self, name):
super(IntegerField, self).__init__(name, 'bigint')
下一步,就是编写最复杂的ModelMetaclass了:
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict
for k, v in attrs.items:
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys:
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
以及基类Model:
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items:
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
object和type
在Python中一切皆对象,类,函数,变量都是对象,且所有的基类都是object,所有的类对象都是由type创建的。
那么object和type两者的关系呢?
>>>type(object)
<class 'type'>
>>>object.__class__
<class 'type'>
>>>type.__bases__
object
从上面的交互命令的结果可以看出,object是type的实例,object是type的超类。那么问题来了,到底是先有鸡还是先有蛋呢?
在回答这个问题之前,先介绍两条规则:
- Dashed Arrow Up Rule: If X is an instance of A, and A is a subclass of B, then X is an instance of B as well.
- Dashed Arrow Down Rule: If B is an instance of M, and A is a subclass of B, then A is an instance of M as well.
有些人可能会对A,B既是类又是实例感到迷惑,但这却在Python里很常见,Python的类既是类也是对象实例
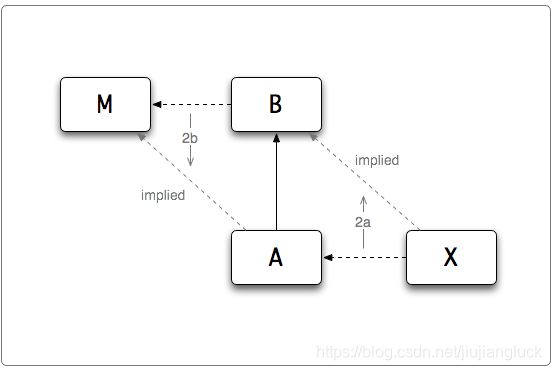
在已知上面的信息的基础上,现在我们运用上面两条规则对一些问题进行测试验证:
>>>isinstance(object, object) # isinstance(instance, class)
True
>>>isinstance(type, object)
True
isinstance(object, object)
根据object是type的实例,object是type的超类,应用Dashed Arrow Up Rule可以得到:
object is an instance of object, type is an instance of type
isinstance(type, object)
由前面的例子可以知道object is an instance of object, type is an instance of type,因此应用Dashed Arrow Down Rule可以得到:
type is an instance of object
从这里就可以看出,object和type密不可分,相互依赖,两者缺一不可,而且Python中的两个源对象。
文件与IO
input和print
最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
你想使用 print 函数输出数据,但是想改变默认的分隔符或者行尾符。
可以使用在 print 函数中使用 sep 和 end 关键字参数,以你想要的方式输出。比如:
>>> print('ACME', 50, 91.5)
ACME 50 91.5
>>> print('ACME', 50, 91.5, sep=',')
ACME,50,91.5
>>> print('ACME', 50, 91.5, sep=',', end='!!\n')
ACME,50,91.5!!
>>> row = ('ACME', 50, 91.5)
>>> print(','.join(row))
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: sequence item 1: expected str instance, int found
>>> print(*row, sep=',')
ACME,50,91.5
将 print 函数的输出重定向到一个文件中去:
with open('d:/work/test.txt', 'wt') as f:
print('Hello World!', file=f)
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
raw_inputinput
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符)
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
文件读写
如何读写各种不同编码的文本数据,比如ASCII,UTF-8或UTF-16编码等?
要以读文件的模式打开一个文件对象,使用Python内置的open函数,传入文件名和标示符。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
>>> f = open('/Users/michael/test.txt', 'r')
# 标示符'r'表示读,这样,我们就成功地打开了一个文件。
open函数 读写模式有很多:
| Character | Meaning |
|---|---|
| ‘r’ | open for reading (default) |
| ‘w’ | open for writing, truncating the file first |
| ‘x’ | open for exclusive creation, failing if the file already exists |
| ‘a’ | open for writing, appending to the end of the file if it exists |
| ‘b’ | binary mode |
| ‘t’ | text mode (default) |
| ‘+’ | open a disk file for updating (reading and writing) |
为了防止读写过程出现的各种问题,我们可以使用上下文管理语句with:
# Read the entire file as a single string
with open('somefile.txt', 'rt') as f:
data = f.read
# Iterate over the lines of the file
with open('somefile.txt', 'rt') as f:
for line in f:
# process line
...
# rt模式下,python在读取文本时会自动把\r\n转换成\n.
如果文件很小,read一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines最方便:
for line in f.readlines:
print(line.strip) # 把末尾的'\n'删掉
文件的读写操作默认使用系统编码(unicode),可以通过调用 sys.getdefaultencoding 来得到。 在大多数机器上面都是utf-8编码。如果你已经知道你要读写的文本是其他编码方式, 那么可以通过传递一个可选的 encoding 参数给open函数。
with open('somefile.txt', 'rt', encoding='latin-1') as f:
...
StringIO和BytesIO
使用 io.StringIO 和 io.BytesIO 类来创建类文件对象操作字符串数据。比如:
>>> s = io.StringIO
>>> s.write('Hello World\n')
12
>>> print('This is a test', file=s)
15
>>> # Get all of the data written so far
>>> s.getvalue
'Hello World\nThis is a test\n'
>>>
>>> # Wrap a file interface around an existing string
>>> s = io.StringIO('Hello\nWorld\n')
>>> s.read(4)
'Hell'
>>> s.read
'o\nWorld\n'
>>>
io.StringIO 只能用于文本。如果你要操作二进制数据,要使用 io.BytesIO 类来代替。比如:
>>> s = io.BytesIO
>>> s.write(b'binary data')
>>> s.getvalue
b'binary data'
>>>
pikle
一个Python对象可以被序列化为一个字节流,以便将它保存到一个文件、存储到数据库或者通过网络传输它,Python提供了pickle模块来实现序列化。
import pickle
data = ... # Some Python object
f = open('somefile', 'wb')
pickle.dump(data, f)
为了将一个对象转储为一个字符串,可以使用 pickle.dumps :
s = pickle.dumps(data)
为了从字节流中恢复一个对象,使用 pickle.load 或 pickle.loads 函数。比如:
# Restore from a file
f = open('somefile', 'rb')
data = pickle.load(f)
# Restore from a string
data = pickle.loads(s)
有些类型的对象是不能被序列化的。这些通常是那些依赖外部系统状态的对象, 比如打开的文件,网络连接,线程,进程,栈帧等等。 用户自定义类可以通过提供
__getstate__和__setstate__方法来绕过这些限制。
具体参考序列化Python对象
并发编程
自从操作系统诞生以来,操作系统经历了人工操作方式、单批道处理系统、多批道处理系统、分时系统、实时系统、分布式操作系统。在操作系统发展过程中,操作系统逐渐由单任务处理系统发展为多任务处理系统,而在多任务处理系统进程和线程的调度时十分频繁的,为了使我们的程序能够更好的在系统中高效率运行,了解进程和线程显得尤为重要。
- 进程
进程的三个组成部分
a. 程序
b. 数据
c. 进程控制块(PCB):为了管理和控制进程,系统在创建每个进程时,都为其开辟一个专用的存储区,用以记录它在系统中的动态特性。系统根据存储区的信息对进程实施控制管理。进程任务完成后,系统收回该存储区,进程随之消亡,这一存储区就是进程控制块
进程的三种基本状态
a. 运行状态:获得CPU的进程处于此状态,对应的程序在CPU上运行着
b. 阻塞状态:为了等待某个外部事件的发生(如等待I/O操作的完成,等待另一个进程发来消息),暂时无法运行。也成为等待状态
c. 就绪状态:具备了一切运行需要的条件,由于其他进程占用CPU而暂时无法运行
- 线程
线程(英语:
thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
- 锁
为了保证数据的一致性,无论是在多线程还是多进程编程中我们会用到锁,使得在某一时间点,只有一个线程或进程进入临界区代码。
进程
如何利用os模块创建一个子进程?
在Unix/Linux系统中提供了fork用于创建子线程,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid)
# Only works on Unix/Linux/Mac:
pid = os.fork
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid, os.getppid))
else:
print('I (%s) just created a child process (%s).' % (os.getpid, pid))
由于Python是跨平台,因此要实现多进程必须能够在所有的系统能够运行,而multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid))
if __name__=='__main__':
print('Parent process %s.' % os.getpid)
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start
p.join # join方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步
print('Child process end.')
如果要启动大量子进程,就要用到进程池Pool:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid))
start = time.time
time.sleep(random.random * 3)
end = time.time
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid)
p = Pool(4) # 最多同时执行4个进程
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close
# 调用join方法会等待所有子进程执行完毕,调用之前必须先调用close,调用close后就不能添加新的Process
p.join
print('All subprocesses done.')
如果终端已经运行了一个Python进程,而此时你还想引入一个外部子进程,并且该子进程能够控制终端的输入/输出,此时 subprocess 模块是一个很不错的选择。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
subprocess.run(args, ...)
Run the command described by args. Wait for command to complete, then return a CompletedProcess instance.
>>>r = subprocess.run(["ls", "-l", "/dev/null"], capture_output=True)
>>>r
CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0,
stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null\n', stderr=b'')
class subprocess.Popen(args, ...)
Execute a child program in a new process. On POSIX, the class uses os.execvp-like behavior to execute the child program. On Windows, the class uses the Windows CreateProcess function.
import subprocess
p = subprocess.Popen(['python test.py'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'This is test')# Interact with process: Send data to stdin.
p.terminate # Stop the child.
# p.wait(timeout=5) Wait for child process to terminate.
p.poll # Check if child process has terminated.
p.kill # Kills the child.
最后讲一下进程的通信:
When using multiple processes, one generally uses message passing for communication between processes and avoids having to use any synchronization primitives like locks.
For passing messages one can usePipe(for a connection between two processes) or aqueue(which allows multiple producers and consumers).
import time, random
from multiprocessing import Process, Pipe, current_process
from multiprocessing.connection import wait
def foo(w):
for i in range(10):
w.send((i, current_process.name))
w.close
if __name__ == '__main__':
readers = []
for i in range(4):
r, w = Pipe(duplex=False)
readers.append(r)
p = Process(target=foo, args=(w,))
p.start
# We close the writable end of the pipe now to be sure that
# p is the only process which owns a handle for it. This
# ensures that when p closes its handle for the writable end,
# wait will promptly report the readable end as being ready.
w.close
while readers:
for r in wait(readers):
try:
msg = r.recv
except EOFError:
readers.remove(r)
else:
print(msg)
线程
如何为需要并发执行的代码创建/销毁线程?
Python的threading 库可以在单独的线程中执行任何的在 Python 中可以调用的对象。你可以创建一个 Thread 对象并将你要执行的对象以 target 参数的形式提供给该对象。 下面是一个简单的例子:
# Code to execute in an independent thread
import time
def countdown(n):
while n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
# Create and launch a thread
from threading import Thread
t = Thread(target=countdown, args=(10,))
t.start # launch a thread
Python中的线程会在一个单独的系统级线程中执行,这些线程将由操作系统来全权管理。
你可以查询一个线程对象的状态,看它是否还在执行:
if t.is_alive:
print('Still running')
else:
print('Completed')
你也可以将一个线程加入到当前线程,并等待它终止:
t.join
Python解释器直到所有线程都终止前仍保持运行。对于需要长时间运行的线程或者需要一直运行的后台任务,你应当考虑使用后台线程。 例如:
t = Thread(target=countdown, args=(10,), daemon=True)
t.start
你无法结束一个线程,无法给它发送信号,无法调整它的调度,也无法执行其他高级操作。如果需要这些特性,你需要自己添加。比如说,如果你需要终止线程,那么这个线程必须通过编程在某个特定点轮询来退出。你可以像下边这样把线程放入一个类中:
class CountdownTask:
def __init__(self):
self._running = True
def terminate(self):
self._running = False
def run(self, n):
while self._running and n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
c = CountdownTask
t = Thread(target=c.run, args=(10,))
t.start
c.terminate # Signal termination
t.join # Wait for actual termination (if needed)
如何创建一个线程池?
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象,不仅可以帮我们自动调度线程,还可以做到:
- 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
- 当一个线程完成的时候,主线程能够立即知道。
- 让多线程和多进程的编码接口一致。
from socket import AF_INET, SOCK_STREAM, socket
from concurrent.futures import ThreadPoolExecutor
def echo_client(sock, client_addr):
'''
Handle a client connection
'''
print('Got connection from', client_addr)
while True:
msg = sock.recv(65536)
if not msg:
break
sock.sendall(msg)
print('Client closed connection')
sock.close
def echo_server(addr):
pool = ThreadPoolExecutor(128)
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(addr)
sock.listen(5)
while True:
client_sock, client_addr = sock.accept
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
pool.submit(echo_client, client_sock, client_addr)
echo_server(('',15000))
当然你也可以手动实现线程池,通过使用Queue来轻松实现,具体实现可以参考这里。
多线程如何对一个共享变量进行互不竞争的访问?
Python提供了threading.Lock来实现对临界区域的访问:
from threading import threading.Lock, threading.Thread
class SharedCounter:
'''
A counter object that can be shared by multiple threads.
'''
def __init__(self, initial_value = 0):
self._value = initial_value
self._value_lock = threading.Lock
# with 语句会在这个代码块执行前自动获取锁,在执行结束后自动释放锁
def incr(self,delta=1):
'''
Increment the counter with locking
'''
with self._value_lock:
self._value += delta
def decr(self,delta=1):
'''
Decrement the counter with locking
'''
with self._value_lock:
self._value -= delta
s = ShareCounter(100)
t1 = Thread(target=s.incr, arg=(10,) )
t1 = Thread(target=s.decr, arg=(9,) )
除了普通的锁threading.Lock之外,Python还提供了RLock 和 Semaphore 对象。
一个
RLock(可重入锁)可以被同一个线程多次获取,主要用来实现基于监测对象模式的锁定和同步。在使用这种锁的情况下,当锁被持有时,只有一个线程可以使用完整的函数或者类中的方法。
import threading
class SharedCounter:
'''
A counter object that can be shared by multiple threads.
'''
_lock = threading.RLock
def __init__(self, initial_value = 0):
self._value = initial_value
def incr(self,delta=1):
'''
Increment the counter with locking
'''
with SharedCounter._lock:
self._value += delta
def decr(self,delta=1):
'''
Decrement the counter with locking
'''
with SharedCounter._lock:
self.incr(-delta)
信号量
Semaphore对象是一个建立在共享计数器基础上的同步原语。尽管你可以在程序中像标准锁一样使用信号量来做线程同步,但是这种方式并不被推荐,因为使用信号量为程序增加的复杂性会影响程序性能。相对于简单地作为锁使用,信号量更适用于那些需要在线程之间引入信号或者限制的程序。
from threading import Semaphore
import urllib.request
# At most, five threads allowed to run at once
_fetch_url_sema = Semaphore(5)
def fetch_url(url):
with _fetch_url_sema:
return urllib.request.urlopen(url)
如何创建线程局部变量,而且该变量对于其他的线程是不可见的?
观察下面的代码:
from socket import socket, AF_INET, SOCK_STREAM
import threading
class LazyConnection:
def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
self.address = address
self.family = AF_INET
self.type = SOCK_STREAM
self.local = threading.local
def __enter__(self):
if hasattr(self.local, 'sock'):
raise RuntimeError('Already connected')
self.local.sock = socket(self.family, self.type)
self.local.sock.connect(self.address)
return self.local.sock
def __exit__(self, exc_ty, exc_val, tb):
self.local.sock.close
del self.local.sock
# Example use
from functools import partial
def test(conn):
with conn as s:
s.send(b'GET /index.html HTTP/1.0\r\n')
s.send(b'Host: www.python.org\r\n')
s.send(b'\r\n')
resp = b''.join(iter(partial(s.recv, 8192), b''))
print('Got {} bytes'.format(len(resp)))
if __name__ == '__main__':
conn = LazyConnection(('www.python.org', 80))
t1 = threading.Thread(target=test, args=(conn,))
t2 = threading.Thread(target=test, args=(conn,))
t1.start
t2.start
t1.join
t2.join
代码中self.local被初始化为一个 threading.local 实例,且代码中每个连接的socket被存储为self.local.sock。这段代码之所以没有出现对self.local.sock的争用,是因为每个线程会创建一个自己专属的套接字连接存储为self.local.sock。 因此,当不同的线程执行套接字操作时,由于操作的是不同的套接字,因此它们不会相互影响。
分布式进程
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
首先我们来看任务分发的服务进程:
import random, time, queue
from multiprocessing.managers import BaseManager
# 发送任务的队列:
task_queue = queue.Queue
# 接收结果的队列:
result_queue = queue.Queue
# 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass
# 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口5000, 设置验证码'abc':
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 启动Queue:
manager.start
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue
result = manager.get_result_queue
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown
print('master exit.')
再来看接受任务的客户进程:
import time, sys, queue
from multiprocessing.managers import BaseManager
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
# 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# 连接到服务器,也就是运行task_master.py的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 从网络连接:
m.connect
# 获取Queue的对象:
task = m.get_task_queue
result = m.get_result_queue
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')
协程
协程和子程序一样也是程序的组件,但是协程是在一个线程内执行的,没有线程的切换,而且切换是由程序本身控制的。
最简单的协程应用就是通过yield实现的:
import time
def consumer:
status = ''
while True:
# get the food from the producer and return status
food = yield status
# check the food and eat the food
if food is None:
return
print(f'Consumer: I am eating the No.{food} food')
status = '200 OK'
def producer(c):
c.send(None) # activate the consumer generator
for i in range(1,10):
# simulate the process of producing
time.sleep(5)
print(f'Producer: I have produced the No.{i} food')
# send the food to the consumer and get status
status = c.send(i)
print(f'Channel: {status}')
c.close
c = consumer
producer(c)
上面的例子,整个过程生产者和消费者协助做运行,没有出现竞争。
异步IO
Python提供了asyncio对异步IO的支持。
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
import asyncio
@asyncio.coroutine # 把一个generator标记为coroutine类型
def wget(host):
print('wget %s...' % host)
connect = asyncio.open_connection(host, 80)
reader, writer = yield from connect
header = 'GET / HTTP/1.0\r\nHost: %s\r\n\r\n' % host
writer.write(header.encode('utf-8'))
yield from writer.drain
while True:
line = yield from reader.readline
if line == b'\r\n':
break
print('%s header > %s' % (host, line.decode('utf-8').rstrip))
# Ignore the body, close the socket
writer.close
loop = asyncio.get_event_loop
tasks = [wget(host) for host in ['www.sina.com.cn', 'www.sohu.com', 'www.163.com']]
loop.run_until_complete(asyncio.wait(tasks))
loop.close
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
请注意,async和await是针对coroutine的新语法,要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为async; - 把
yield from替换为await。
练习题
Problem 1
使用信号量实现哲学家就餐问题
Problem 2
使用信号量实现睡眠的理发师问题
网络编程
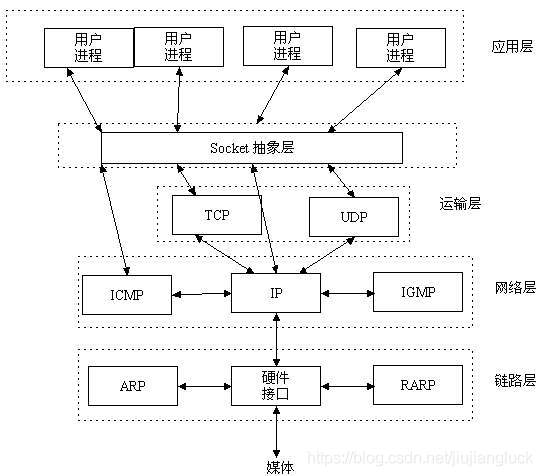
互联网发展到今天,网络应用随处可见,因此学习网络编程是十分有意义的。学习网络编程,就应该去了解计算机网络是怎么回事。
一个简单的计算机网络模型如下:
而我们学习网络编程,重点要学习的是TCP/IP协议。
TCP/IP(Transmission Control Protocol/Internet Protocol)即传输控制协议/网间协议,是一个工业标准的协议集,它是为广域网(wan)设计的。
TCP/IP协议存在于OS中,网络服务通过OS提供,在OS中增加支持TCP/IP的系统调用——Berkeley套接字,如Socket,Connect,Send,Recv等
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是属于TCP/IP协议族中的一种。

TCP/UDP协议是属于运输层协议,是属于端到端。所谓端到端简单来讲就是指进程到进程,一般来说进行网络操作的进程都会开放一个端口进行网络通信。TCP协议是面向连接的,可靠的,能够保证TCP分组正确到达、顺序交付,而保证正确到达、顺序交付的有三种基本协议:停等协议、后退N步协议、选择重传协议,这就是TCP协议的流量控制。TCP协议还能对网络进行拥塞控制,及时调节发送窗口的大小。
IP协议主要是负责在源地址和目的地址之间传递数据,还负责将数据包重新组装。
Socket编程
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个编程API,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
- TCP编程
下面是TCP的socket的通信流程:
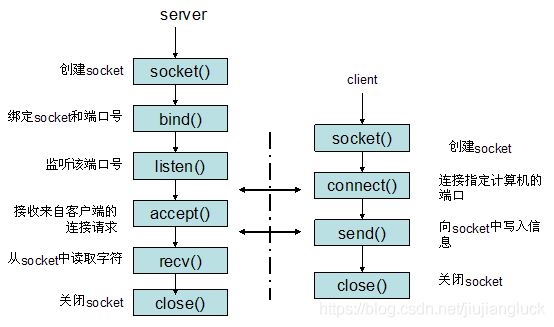
根据以上通信流程,首先我们可以编写服务器端程序:
from socket import AF_INET, SOCK_STREAM, socket
from concurrent.futures import ThreadPoolExecutor
def handle_client(sock, client_addr):
while True:
# 从客户端接收数据
msg = sock.recv(65536)
if msg is None or msg.decode('utf-8') == 'exit':
break
sock.sendall(msg)
print('Client closed connection')
sock.close
# 创建一个socket
s = socket(AF_INET, SOCK_STREAM)
# 绑定端口, 阿里云ECS绑定私有IP
s.bind(('', 9999))
# 监听端口
s.listen(5)
# 创建线程池响应客户端
pool = ThreadPoolExecutor(128)
# 不断轮询是否有新的客户端连接到服务器
while True:
# 接受一个新连接:
sock, addr = s.accept
pool.submit(handle_client, sock, addr)
然后我们再来编写客户端程序:
from socket import AF_INET, SOCK_STREAM, socket
s = socket(AF_INET, SOCK_STREAM)
# 建立连接, 阿里云ECS公网IP
s.connect(('47.100.117.119', 9999))
while True:
msg = input('Input the message:').strip('\n')
s.send(msg.encode('utf-8'))
if msg == 'exit':
break
print('Server: ', s.recv(65536).decode('utf-8'))
s.close
- UDP编程
下面是UDP的socket的通信流程:

首先,我们可以编写服务端代码:
from socket import AF_INET, SOCK_DGRAM, socket
s = socket(AF_INET, SOCK_DGRAM)
s.bind(('127.0.0.1', 9999))
while True:
data, addr = s.recvfrom(1024)
print('Received from %s:%s.' % addr)
s.sendto(b'Hello, %s!' % data, addr)
然后我们再来编写客户端程序:
from socket import AF_INET, SOCK_DGRAM, socket
s = socket(AF_INET, SOCK_DGRAM)
while True:
msg = input('Input the message:').strip('\n')
s.sendto(msg.encode('utf-8'), ('127.0.0.1', 9999))
if msg == 'exit':
break
print('Server: ', s.recv(65536).decode('utf-8'))
s.close
Python为我们内置了TCPServer,UDPServer帮助我们创建效率更高的TCP服务器或者UDP服务器,具体实现可以参考官方代码。
需要注意的是TCPServer,UDPServer都是单线程的,一次只能为一个客户端连接服务。 如果你想处理多个客户端,可以初始化一个ForkingTCPServer或者是ThreadingTCPServer。使用线程服务器有个潜在问题就是它们会为每个客户端连接创建一个新的进程或线程。 由于客户端连接数是没有限制的,因此一个恶意的黑客可以同时发送大量的连接让你的服务器奔溃。
HTTP编程
HTTP: HyperText Transfer Protocol, 超文本传输协议,是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。
以下图表展示了HTTP协议通信流程:

下面实例是一个典型的使用GET来传递数据的实例:
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务端响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
了解了基本的HTTP协议,我们可以开始构造一个简单的动态HTTPSever,我们可以利用Python内置的TCPServer来实现我们自定义的HTTPServer。
查看TCPServer的源码可以发现:
TCPServer的初始化函数__init__(server_address, RequestHandlerClass, bind_and_activate=True),包含了一个请求处理类,也就是说TCPServer只负责对服务器的创建,而把处理request相关操作放到了RequestHandlerClass。
首先我们可以创建一个多线程的HTTPServer,然后关于处理类Python提供了一个CGIHTTPRequestHandler,支持请求动态文件。但是有个小问题,CGIHTTPRequestHandler在对HTTP响应报文的实体主体(entity body)和首部行(headerlines)处理时在它们之间没有加入空行,导致动态文件无法正确显示。要想正确显示,就必须在动态文件最开始的地方输出一个空行。
下面的例子中,我对CGIHTTPRequestHandler进行了小修改,可以省去在动态文件最开始的地方输出一个空行。
from concurrent.futures import ThreadPoolExecutor
from socketserver import BaseRequestHandler, TCPServer
import socket
import os
import sys
import select
import copy
import urllib
from http import HTTPStatus
from http.server import SimpleHTTPRequestHandler, ThreadingHTTPServer
class MultiThreadingMixIn:
"""Mix-in class to handle each request in a new thread."""
# If true, server_close waits until all non-daemonic threads terminate.
block_on_close = True
# Threading objects used by server_close to wait for all threads completion.
_pool = None
max_children = 128
def process_request_thread(self, request, client_address):
"""Same as in BaseServer but as a thread.
In addition, exception handling is done here.
"""
try:
self.finish_request(request, client_address)
except Exception:
self.handle_error(request, client_address)
finally:
self.shutdown_request(request)
def process_request(self, request, client_address):
"""submit a new thread to process the request."""
if self.block_on_close:
if self._pool is None:
self._pool = ThreadPoolExecutor(self.max_children)
self._pool.submit(self.process_request_thread, request, client_address)
def server_close(self):
super.server_close
if self.block_on_close:
# the 'wait' parameter of showdown with the default value will wait
# until all threads terminate.
if self._pool is not None:
self._pool.shutdown
class HTTPServer(TCPServer):
allow_reuse_address = True
def server_bind(self):
"""Override server_bind to store the server name."""
TCPServer.server_bind(self)
host, port = self.server_address[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port
class MultiThreadingHTTPServer(MultiThreadingMixIn, HTTPServer): pass
# Utilities for CGIHTTPRequestHandler
def _url_collapse_path(path):
"""
Given a URL path, remove extra '/'s and '.' path elements and collapse
any '..' references and returns a collapsed path.
Implements something akin to RFC-2396 5.2 step 6 to parse relative paths.
The utility of this function is limited to is_cgi method and helps
preventing some security attacks.
Returns: The reconstituted URL, which will always start with a '/'.
Raises: IndexError if too many '..' occur within the path.
"""
# Query component should not be involved.
path, _, query = path.partition('?')
path = urllib.parse.unquote(path)
# Similar to os.path.split(os.path.normpath(path)) but specific to URL
# path semantics rather than local operating system semantics.
path_parts = path.split('/')
head_parts = []
for part in path_parts[:-1]:
if part == '..':
head_parts.pop # IndexError if more '..' than prior parts
elif part and part != '.':
head_parts.append( part )
if path_parts:
tail_part = path_parts.pop
if tail_part:
if tail_part == '..':
head_parts.pop
tail_part = ''
elif tail_part == '.':
tail_part = ''
else:
tail_part = ''
if query:
tail_part = '?'.join((tail_part, query))
splitpath = ('/' + '/'.join(head_parts), tail_part)
collapsed_path = "/".join(splitpath)
return collapsed_path
nobody = None
def nobody_uid:
"""Internal routine to get nobody's uid"""
global nobody
if nobody:
return nobody
try:
import pwd
except ImportError:
return -1
try:
nobody = pwd.getpwnam('nobody')[2]
except KeyError:
nobody = 1 + max(x[2] for x in pwd.getpwall)
return nobody
def executable(path):
"""Test for executable file."""
return os.access(path, os.X_OK)
class CGIHTTPRequestHandler(SimpleHTTPRequestHandler):
"""Complete HTTP server with GET, HEAD and POST commands.
GET and HEAD also support running CGI scripts.
The POST command is *only* implemented for CGI scripts.
"""
# Determine platform specifics
have_fork = hasattr(os, 'fork')
# Make rfile unbuffered -- we need to read one line and then pass
# the rest to a subprocess, so we can't use buffered input.
rbufsize = 0
def do_POST(self):
"""Serve a POST request.
This is only implemented for CGI scripts.
"""
if self.is_cgi:
self.run_cgi
else:
self.send_error(
HTTPStatus.NOT_IMPLEMENTED,
"Can only POST to CGI scripts")
def send_head(self):
"""Version of send_head that support CGI scripts"""
if self.is_cgi:
return self.run_cgi
else:
return SimpleHTTPRequestHandler.send_head(self)
def is_cgi(self):
"""Test whether self.path corresponds to a CGI script.
Returns True and updates the cgi_info attribute to the tuple
(dir, rest) if self.path requires running a CGI script.
Returns False otherwise.
If any exception is raised, the caller should assume that
self.path was rejected as invalid and act accordingly.
The default implementation tests whether the normalized url
path begins with one of the strings in self.cgi_directories
(and the next character is a '/' or the end of the string).
"""
collapsed_path = _url_collapse_path(self.path)
dir_sep = collapsed_path.find('/', 1)
head, tail = collapsed_path[:dir_sep], collapsed_path[dir_sep+1:]
if head in self.cgi_directories:
self.cgi_info = head, tail
return True
return False
cgi_directories = ['/cgi-bin', '/htbin']
def is_executable(self, path):
"""Test whether argument path is an executable file."""
return executable(path)
def is_python(self, path):
"""Test whether argument path is a Python script."""
head, tail = os.path.splitext(path)
return tail.lower in (".py", ".pyw")
def run_cgi(self):
"""Execute a CGI script."""
dir, rest = self.cgi_info
path = dir + '/' + rest
i = path.find('/', len(dir)+1)
while i >= 0:
nextdir = path[:i]
nextrest = path[i+1:]
scriptdir = self.translate_path(nextdir)
if os.path.isdir(scriptdir):
dir, rest = nextdir, nextrest
i = path.find('/', len(dir)+1)
else:
break
# find an explicit query string, if present.
rest, _, query = rest.partition('?')
# dissect the part after the directory name into a script name &
# a possible additional path, to be stored in PATH_INFO.
i = rest.find('/')
if i >= 0:
script, rest = rest[:i], rest[i:]
else:
script, rest = rest, ''
scriptname = dir + '/' + script
scriptfile = self.translate_path(scriptname)
if not os.path.exists(scriptfile):
self.send_error(
HTTPStatus.NOT_FOUND,
"No such CGI script (%r)" % scriptname)
return
if not os.path.isfile(scriptfile):
self.send_error(
HTTPStatus.FORBIDDEN,
"CGI script is not a plain file (%r)" % scriptname)
return
ispy = self.is_python(scriptname)
if self.have_fork or not ispy:
if not self.is_executable(scriptfile):
self.send_error(
HTTPStatus.FORBIDDEN,
"CGI script is not executable (%r)" % scriptname)
return
# Reference: http://hoohoo.ncsa.uiuc.edu/cgi/env.html
# XXX Much of the following could be prepared ahead of time!
env = copy.deepcopy(os.environ)
env['SERVER_SOFTWARE'] = self.version_string
env['SERVER_NAME'] = self.server.server_name
env['GATEWAY_INTERFACE'] = 'CGI/1.1'
env['SERVER_PROTOCOL'] = self.protocol_version
env['SERVER_PORT'] = str(self.server.server_port)
env['REQUEST_METHOD'] = self.command
uqrest = urllib.parse.unquote(rest)
env['PATH_INFO'] = uqrest
env['PATH_TRANSLATED'] = self.translate_path(uqrest)
env['SCRIPT_NAME'] = scriptname
if query:
env['QUERY_STRING'] = query
env['REMOTE_ADDR'] = self.client_address[0]
authorization = self.headers.get("authorization")
if authorization:
authorization = authorization.split
if len(authorization) == 2:
import base64, binascii
env['AUTH_TYPE'] = authorization[0]
if authorization[0].lower == "basic":
try:
authorization = authorization[1].encode('ascii')
authorization = base64.decodebytes(authorization).\
decode('ascii')
except (binascii.Error, UnicodeError):
pass
else:
authorization = authorization.split(':')
if len(authorization) == 2:
env['REMOTE_USER'] = authorization[0]
# XXX REMOTE_IDENT
if self.headers.get('content-type') is None:
env['CONTENT_TYPE'] = self.headers.get_content_type
else:
env['CONTENT_TYPE'] = self.headers['content-type']
length = self.headers.get('content-length')
if length:
env['CONTENT_LENGTH'] = length
referer = self.headers.get('referer')
if referer:
env['HTTP_REFERER'] = referer
accept = []
for line in self.headers.getallmatchingheaders('accept'):
if line[:1] in "\t\n\r ":
accept.append(line.strip)
else:
accept = accept + line[7:].split(',')
env['HTTP_ACCEPT'] = ','.join(accept)
ua = self.headers.get('user-agent')
if ua:
env['HTTP_USER_AGENT'] = ua
co = filter(None, self.headers.get_all('cookie', []))
cookie_str = ', '.join(co)
if cookie_str:
env['HTTP_COOKIE'] = cookie_str
# XXX Other HTTP_* headers
# Since we're setting the env in the parent, provide empty
# values to override previously set values
for k in ('QUERY_STRING', 'REMOTE_HOST', 'CONTENT_LENGTH',
'HTTP_USER_AGENT', 'HTTP_COOKIE', 'HTTP_REFERER'):
env.setdefault(k, "")
self.send_response(HTTPStatus.OK, "Script output follows")
self.flush_headers
decoded_query = query.replace('+', ' ')
if self.have_fork:
# Unix -- fork as we should
args = [script]
if '=' not in decoded_query:
args.append(decoded_query)
nobody = nobody_uid
self.wfile.flush # Always flush before forking
pid = os.fork
if pid != 0:
# Parent
pid, sts = os.waitpid(pid, 0)
# throw away additional data [see bug #427345]
while select.select([self.rfile], [], [], 0)[0]:
if not self.rfile.read(1):
break
if sts:
self.log_error("CGI script exit status %#x", sts)
return
# Child
try:
try:
os.setuid(nobody)
except OSError:
pass
os.dup2(self.rfile.fileno, 0)
os.dup2(self.wfile.fileno, 1)
os.execve(scriptfile, args, env)
except:
self.server.handle_error(self.request, self.client_address)
os._exit(127)
else:
# Non-Unix -- use subprocess
import subprocess
cmdline = [scriptfile]
if self.is_python(scriptfile):
interp = sys.executable
if interp.lower.endswith("w.exe"):
# On Windows, use python.exe, not pythonw.exe
interp = interp[:-5] + interp[-4:]
cmdline = [interp, '-u'] + cmdline
if '=' not in query:
cmdline.append(query)
self.log_message("command: %s", subprocess.list2cmdline(cmdline))
try:
nbytes = int(length)
except (TypeError, ValueError):
nbytes = 0
p = subprocess.Popen(cmdline,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
env = env
)
if self.command.lower == "post" and nbytes > 0:
data = self.rfile.read(nbytes)
else:
data = None
# throw away additional data [see bug #427345]
while select.select([self.rfile._sock], [], [], 0)[0]:
if not self.rfile._sock.recv(1):
break
stdout, stderr = p.communicate(data)
# ! it must write a linesep to separate the head from the body
self.wfile.write(bytes(os.linesep, 'utf-8'))
# writes the body
self.wfile.write(stdout)
if stderr:
self.log_error('%s', stderr)
p.stderr.close
p.stdout.close
status = p.returncode
if status:
self.log_error("CGI script exit status %#x", status)
else:
self.log_message("CGI script exited OK")
if __name__ == '__main__':
with MultiThreadingHTTPServer(('127.0.0.1', 8080), CGIHTTPRequestHandler) as httpd:
sa = httpd.socket.getsockname
serve_message = "Serving HTTP on {host} port {port} (http://{host}:{port}/) ..."
print(serve_message.format(host=sa[0], port=sa[1]))
try:
httpd.serve_forever
except KeyboardInterrupt:
print("\nKeyboard interrupt received, exiting.")
sys.exit(0)
函数调用分析:
邮件
- 要想发送一封邮件就得先构造好邮件内容,然后通过
SMTP协议发送出去。
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
# 构造邮件内容
from_addr = input('Input your Email address:')
psw = input('Input your password:'')
to_addr = input('Input receiver Email address:')
from_name = input('Input your name:')
to_name input('Input receiver name:')
subject = input('Input your Email subject:')
text = input('Input your Email content:')
file_path = input('Input your Email attach file path:')
mas = MIMEMultipart
msg['From'] = '{} <{}>'.format(from_name, from_addr)
msg['To'] ='{} <{}>'.format(to_name, to_addr)
msg['Subject'] = ''
msg.attach(MIMEText(text, _subtype='html',_charset='utf-8'))
with open(file_path, 'rb') as f:
mime = MIMEBase('image', 'png', filename='test.png')
mime.add_header('Content-Disposition', 'attachment', filename='test.png')
mime.add_header('Content-ID', '<0>')
mime.add_header('X-Attachment-Id', '0')
mime.set_payload(f.read)
encoders.encode_base64(mime)
msg.attach(mime)
s = smtplib.SMTP("smtp.qq.com",587)
server.starttls
s.login(from_addr, psw)
s.sendmail(from_addr, to_addr, msg.as_string)
s.close
数据库
要想使用MySQL就必须安装MySQL的驱动:
$ pip install mysql-connector
import mysql-connector
conn = mysql.connector.connect(host='localhost',user='root', password='password', database='test');
cursor = conn.cursor
cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
conn.commit
conn.close
cursor = conn.cursor
cursor.execute('select * from user where id = %s', ('1',))
values = cursor.fetchall
cursor.close
conn.close
异步MySQL驱动:aiomysql这个库提供了一种通过简洁的工厂级别的函数aiomysql.connect去连接MySQL数据库的一种方式。如果你只想要存在一个连接,可以使用这种方式。对于多个连接可以考虑连接池。
注意使用之前请安装aiomysql: pip install aiomysql
import asyncio
import aiomysql
loop = asyncio.get_event_loop
async def test_example:
conn = await aiomysql.connect(host="localhost", port=3306,user="root", password="****",db="****", loop=loop)
cur = await conn.cursor
await cur.execute("select Host, User from user")
print(cur.description)
result = await cur.fetchall
print(result)
await cur.close
conn.close
loop.run_until_complete(test_example)
创建连接池:
import asyncio
import aiomysql
loop = asyncio.get_event_loop
async def test_example:
async with aiomysql.create_pool(host="localhost", port=3306, user="root", password="*****", db="****", loop=loop) as pool:
async with pool.acquire as conn:
async with conn.cursor as cursor:
await cursor.execute("select * from *")
data = await cursor.fetchall
print(data)
await pool.wait_closed
loop.run_until_complete(test_example)
Web框架
前面我们实现了一个简单HTTP服务器,这个服务器能够让我们处理动态文件以及静态文件,但是离实际应用还差的很远,比如
- 每次增加一个页面都要再写一个页面
- 没有实现HTML和动态文件的分离,给开发带来很大困难
- 不支持异步IO处理,会给服务器带来很大负载
现在我们希望只关注解析用户请求,然后对其做出响应。所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI:Web Server Gateway Interface。
简单来说WSGI接口只要求你实现一个application函数,这个函数带有两个参数一个包含所有请求信息,一个是对请求结果做出响应的函数,最后返回body。
现在我们对Python内置的wsgiref模块进行分析:
WSGIHTTPServer继承自HTTPServer,覆盖了server_bind(),添加了application函数对象WSGIRequestHandler继承自BaseHTTPRequestHandler,覆盖了handle()并通过ServerHandler的实例调用application函数
常见的Python Web框架有:
-
Django:全能型Web框架;
-
Flask:轻量级 Web 应用框架
-
web.py:一个小巧的Web框架;
-
Bottle:和Flask类似的Web框架;
-
Tornado:Facebook的开源异步Web框架。