需要准备 redis mongodb scrapy-redis 这些自己百度安装
1.对要爬取的页面进行分析。。。因爬取时候没使用代理现在ip已经被屏蔽 所以明天进行分析 今天上代码
代码分析 这是没有使用redis的爬虫

# -*- coding: utf-8 -*-
importscrapy
fromscrapy.httpimportRequest
frombooszp.itemsimportBooszpItem
#from scrapy_redis.spiders import RedisSpider
classBoosSpider(RedisSpider):
name ="boos"
# redis_key='boos:start_urls'
start_urls = ['http://www.zhipin.com/job_detail/?query=php&scity=100010000&source=1']
allowed_domains = ["www.zhipin.com"]
# def start_requests(self):
#for url in self.start_urls:
# yield Request(url=url,callback=self.parse)
defparse(self,response):
lianjie =response.xpath('//div[@class="job-primary"]')
fordizhiinlianjie:
item = BooszpItem()
item['name'] = dizhi.xpath('./div[@class="info-primary"]/h3[@class="name"]/text()').extract()
item['xinzi']= dizhi.xpath('./div[@class="info-primary"]/h3[@class="name"]/span[@class="red"]/text()').extract()
item['dizhi']= dizhi.xpath('./div[@class="info-primary"]/p/text()').extract()
item['gongsi']=dizhi.xpath('./div[@class="info-company"]/div[@class="company-text"]/h3[@class="name"]/text()').extract()
yielditem
jj = response.xpath('//div[@class="page"]/a/@href').extract()[-1]
ifjj !='javascript:;':
ff ='http://www.zhipin.com/'+jj
yieldRequest(url=ff,callback=self.parse,dont_filter = True)

# -*- coding: utf-8 -*-
importscrapy
fromscrapy.httpimportRequest
frombooszp.itemsimportBooszpItem
fromscrapy_redis.spidersimportRedisSpider
classBoosSpider(RedisSpider):
name ="boos"
redis_key='boos:start_urls'
# start_urls = ['http://www.zhipin.com/job_detail/?query=php&scity=100010000&source=1']
allowed_domains = ["www.zhipin.com"]
defstart_requests(self):
forurlinself.start_urls:
yieldRequest(url=url,callback=self.parse)
defparse(self,response):
lianjie =response.xpath('//div[@class="job-primary"]')
fordizhiinlianjie:
item = BooszpItem()
item['name'] = dizhi.xpath('./div[@class="info-primary"]/h3[@class="name"]/text()').extract()
item['xinzi']= dizhi.xpath('./div[@class="info-primary"]/h3[@class="name"]/span[@class="red"]/text()').extract()
item['dizhi']= dizhi.xpath('./div[@class="info-primary"]/p/text()').extract()
item['gongsi']=dizhi.xpath('./div[@class="info-company"]/div[@class="company-text"]/h3[@class="name"]/text()').extract()
yielditem
jj = response.xpath('//div[@class="page"]/a/@href').extract()[-1]
ifjj !='javascript:;':
ff ='http://www.zhipin.com/'+jj
yieldRequest(url=ff,callback=self.parse,dont_filter = True)
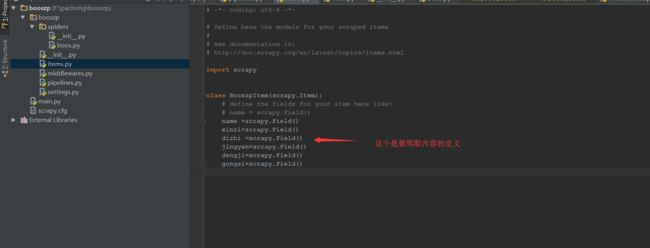
importscrapy
classBooszpItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name =scrapy.Field()
xinzi=scrapy.Field()
dizhi =scrapy.Field()
jingyan=scrapy.Field()
dengji=scrapy.Field()
gongsi=scrapy.Field()
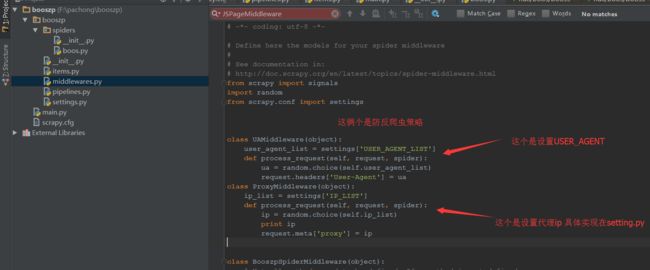
from scrapy importsignals
import random
from scrapy.confimportsettings
classUAMiddleware(object):
user_agent_list = settings['USER_AGENT_LIST']
defprocess_request(self,request,spider):
ua = random.choice(self.user_agent_list)
request.headers['User-Agent'] = ua
classProxyMiddleware(object):
ip_list = settings['IP_LIST']
defprocess_request(self,request,spider):
ip = random.choice(self.ip_list)
printip
request.meta['proxy'] = ip
settings.py

DOWNLOADER_MIDDLEWARES = {
'booszp.middlewares.UAMiddleware':543,#获取middlewares 的user
'booszp.middlewares.ProxyMiddleware':544,#获取 ip代理
}
ITEM_PIPELINES = {
'booszp.pipelines.BooszpPipeline':300,
#'scrapy_redis.pipelines.RedisPipeline':301
}
SCHEDULER ="scrapy_redis.scheduler.Scheduler"#首先是Scheduler的替换,
# 这个东西是Scrapy中的调度员
DUPEFILTER_CLASS ="scrapy_redis.dupefilter.RFPDupeFilter"#去重
SCHEDULER_PERSIST = False
#如果这一项为True,那么在Redis中的URL不会被Scrapy_redis清理掉,
# 这样的好处是:爬虫停止了再重新启动,它会从上次暂停的地方开始继续爬取
# 。但是它的弊端也很明显,如果有多个爬虫都要从这里读取URL,需要另外写一段代码来防止重复爬取。
#如果设置成了False,那么Scrapy_redis每一次读取了URL以后,就会把这个URL给删除。
# 这样的好处是:多个服务器的爬虫不会拿到同一个URL,也就不会重复爬取。但弊端是:爬虫暂停以后再重新启动,它会重新开始爬。
SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.SpiderQueue'
#爬虫请求的调度算法
USER_AGENT_LIST = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11']
IP_LIST = ['http://122.226.62.90:3128',#代理ip
'http://101.200.40.47:3128',
'http://84.52.115.139:8080']
REDIS_HOST ='127.0.0.1'#修改为Redis的实际IP地址
REDIS_PORT =6379#修改为Redis的实际端口
MONGODB_HOST='127.0.0.1'# mongodb
MONGODB_POST =27017
MONGODB_DBNAME='boos'
MONGODB_DOCNAME='boos3'
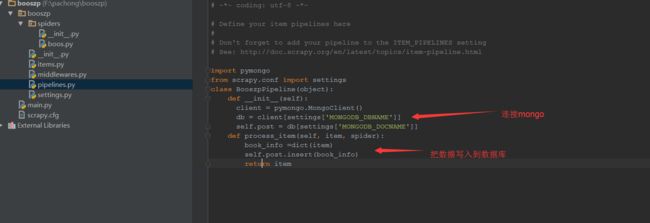
importpymongo
fromscrapy.confimportsettings
classBooszpPipeline(object):
def__init__(self):
client = pymongo.MongoClient()
db = client[settings['MONGODB_DBNAME']]
self.post = db[settings['MONGODB_DOCNAME']]
defprocess_item(self,item,spider):
book_info =dict(item)
self.post.insert(book_info)
returnitem
然后启动redis 喂链接就可以了
启动爬虫就行了

然后使用scrapyd 进行项目部署
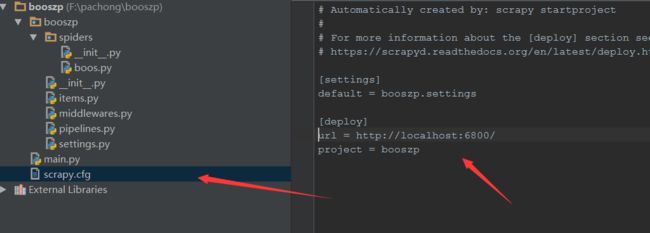
启动 scrapyd

在重新打开cmd

curl http://localhost:6800/listprojects.json 查看爬虫信息

curl http://localhost:6800/schedule.json -d project=booszp -d spider=boos
启动爬虫

在浏览器输入localhost:6500


然后去redis 喂条url


如有问题请留言