基于kubeadm方式部署kubernetes v1.12.1
参考文献如下:
https://blog.csdn.net/jq0123/article/details/80471625
https://www.kubernetes.org.cn/3808.html
http://blog.51cto.com/devingeng/2096495
https://www.linuxidc.com/Linux/2018-10/154548.htm
说明:
- 目前k8s组件并没有全部安装成功,dns目前处于running状态,但,无法提供服务。
- 其他服务可以正常使用
- 仅供参考
============
2018.10.16 更新,
按照当前博文可以安装成功,上面提到的dns服务异常,
其实,dns服务一开始就成功了,是测试工具的问题
============
一、 初始化环境介绍
| 系统类型 | IP | role | cpu | memory | hostname |
|---|---|---|---|---|---|
| CentOS 7.4.1708 | 172.16.91.135 | master | 4 | 2G | master |
| CentOS 7.4.1708 | 172.16.91.136 | worker | 2 | 1G | slave1 |
| CentOS 7.4.1708 | 172.16.91.137 | worker | 2 | 1G | slave2 |
二、 安装环境准备工作
2.1 主机映射(所有节点)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.91.135 master
172.16.91.136 slave1
172.16.91.137 slave2
2.2 ssh免密码登陆(在master节点上 )
- ssh-keygen
- ssh-copy-id root@slave1
- ssh-copy-id root@slave2
2.3 关闭防火墙(所有节点)
- systemctl stop firewalld
- systemctl disable firewalld
2.4 关闭Swap(所有节点)
- swapoff -a
- sed -i 's/.swap./#&/' /etc/fstab
2.5 设置内核(所有节点)
2.5.1 设置netfilter模块
modprobe br_netfilter
cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
ls /proc/sys/net/bridge
2.5.2 打开ipv4的转发功能 (所有节点)
如果不打开的话,在将从节点加入到集群时,会报以下的问题?

解决措施?
# 执行下面的命令
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
# 保存执行
sysctl -p
2.5.3 更新内核参数
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
echo "* soft nproc 65536" >> /etc/security/limits.conf
echo "* hard nproc 65536" >> /etc/security/limits.conf
echo "* soft memlock unlimited" >> /etc/security/limits.conf
echo "* hard memlock unlimited" >> /etc/security/limits.conf
或者
echo "* soft nofile 65536" >> /etc/security/limits.conf &&
echo "* hard nofile 65536" >> /etc/security/limits.conf &&
echo "* soft nproc 65536" >> /etc/security/limits.conf &&
echo "* hard nproc 65536" >> /etc/security/limits.conf &&
echo "* soft memlock unlimited" >> /etc/security/limits.conf &&
echo "* hard memlock unlimited" >> /etc/security/limits.conf
2.5.4 关闭Selinux(所有节点)
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
2.6 更新yum源 并 安装相关依赖包(所有节点)
2.6.1 更新yum源(添加k8s源)
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2.6.2 添加相关依赖包
yum install -y epel-release
yum install -y yum-utils device-mapper-persistent-data lvm2 net-tools conntrack-tools wget vim ntpdate libseccomp libtool-ltdl
2.7 配置ntp(所有节点)
systemctl enable ntpdate.service
echo '*/30 * * * * /usr/sbin/ntpdate time7.aliyun.com >/dev/null 2>&1' > /tmp/crontab2.tmp
crontab /tmp/crontab2.tmp
systemctl start ntpdate.service
2.7.1 发现系统时间跟实际时间不对,如何解决
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate us.pool.ntp.org
date
三、 部署
3.1 部署docker
具体可以参考其他文章,
目前使用的版本是:
[root@slave2 ~]# docker version
Client:
Version: 17.03.2-ce
API version: 1.27
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 02:21:36 2017
OS/Arch: linux/amd64
Server:
Version: 17.03.2-ce
API version: 1.27 (minimum version 1.12)
Go version: go1.7.5
Git commit: f5ec1e2
Built: Tue Jun 27 02:21:36 2017
OS/Arch: linux/amd64
Experimental: false
3.1.1 添加镜像加速器(所有节点)
如果没有的话,可以在阿里云上注册,获取自己的镜像加速器;
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxxxx.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
3.2 部署以rpm包方式部署kubelet,kubedam, kubectl, kubernetes-cni(所有节点)
yum install -y kubelet kubeadm kubectl kubernetes-cni
systemctl enable kubelet
安装成功后,显示安装的版本:
kubeadm.x86_64 0:1.12.0-0 kubectl.x86_64 0:1.12.0-0 kubelet.x86_64 0:1.12.0-0 kubernetes-cni.x86_64 0:0.6.0-0
通过下面的方式,可以安装制定版本的二进制文件:
yum install -y kubelet-1.12.0 kubeadm-1.12.0 kubectl-1.12.0 kubernetes-cni-0.6.0
3.3 更新kubelet配置文件(所有节点)
- 更新配置文件(选做)
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf#修改这一行 Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs" #添加这一行 Environment="KUBELET_EXTRA_ARGS=--v=2 --fail-swap-on=false --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/k8sth/pause-amd64:3.0"
说明:
为什么要添加pause-amd64:3.0?
kubelet就不会在启动pod的时候去墙外的k8s仓库拉取pause-amd64:3.0镜像了
可以先在master节上更新,然后通过scp命令,传递给slave1,slave2
scp /etc/systemd/system/kubelet.service.d/10-kubeadm.conf root@slave1:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
scp /etc/systemd/system/kubelet.service.d/10-kubeadm.conf root@slave2:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
说明:
pause镜像已经下载到本地的话,可以不用这么配置的,
- 重新启动kubelet服务
systemctl daemon-reload systemctl enable kubelet - 命令部署效果:(master节点上部署即可)(选做)
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
3.4 初始化集群(master节点)
3.4.1 关于镜像
国内某种原因,对于镜像要特别处理
-
查看kubeadm用到的镜像
kubeadm config images list
 image
image -
在阿里云或者docker hub,或者其他。。。。。 下载所需要的镜像
我用的阿里云镜像(图片显示的版本是v1.12.0)
 image
image -
相关镜像下载地址
已经上传到阿里云上了,可以直接下载名称 地址 kube-proxy registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-proxy:v1.12.1 kube-scheduler registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-scheduler:v1.12.1 kube-controller-manage registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-controller-manager:v1.12.1 kube-apiserver registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-apiserver:1.12.1 coredns registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/coredns:1.2.2 pause registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/pause:3.1 etcd registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/etcd:3.2.24 calico-cni registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/calico-cni:v3.1.3 calico-node registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/calico-node:v3.1.3 如:
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/pause:1.12.1
即可下载 -
将下载好的镜像,修改成正确的镜像名称
 image
image最后删除掉没用的镜像标签(选做)
 image
image
在master节点上,操作
其中:
etcd-master、apiserver、controller-manager、scheduler 这些都是部署在master节点上的,镜像不用copy到其他节点
#!/bin/bash
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-proxy:v1.12.1
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-scheduler:v1.12.1
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-controller-manager:v1.12.1
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-apiserver:1.12.1
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/coredns:1.2.2
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/pause:3.1
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/etcd:3.2.24
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/calico-cni:v3.1.3
docker pull registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/calico-node:v3.1.3
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-proxy:v1.12.1 k8s.gcr.io/kube-proxy:v1.12.1
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-scheduler:v1.12.1 k8s.gcr.io/kube-scheduler:v1.12.1
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-controller-manager:v1.12.1 k8s.gcr.io/kube-controller-manager:v1.12.1
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-apiserver:1.12.1 k8s.gcr.io/kube-apiserver:v1.12.1
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/coredns:1.2.2 k8s.gcr.io/coredns:1.2.2
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/etcd:3.2.24 k8s.gcr.io/etcd:3.2.24
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-controller-manager:v1.12.1
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-proxy:v1.12.1
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-scheduler:v1.12.1
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/kube-apiserver:1.12.1
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/etcd:3.2.24
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/coredns:1.2.2
docker rmi -f registry.cn-qingdao.aliyuncs.com/kubernetes_xingej/pause:3.1
- 需要将pause镜像、kube-proxy拷贝到其他从节点上去,
拷贝镜像,重新打tag为k8s.gcr.io/pause:1.12.0、k8s.gcr.io/kube-proxy:v1.12.1
因为创建pod时需要这些镜像, 尤其是pause镜像
3.4.2 更新kubeadm配置文件config.yaml (master节点)
配置文件名字随便起的;
vim kubeadm-config-v1.12.1.yaml
apiVersion: kubeadm.k8s.io/v1alpha3
kind: ClusterConfiguration
etcd:
external:
endpoints:
- https://172.16.91.222:2379
caFile: /root/ca-k8s/ca.pem
certFile: /root/ca-k8s/etcd.pem
keyFile: /root/ca-k8s/etcd-key.pem
dataDir: /var/lib/etcd
networking:
podSubnet: 192.168.0.0/16
kubernetesVersion: v1.12.1
api:
advertiseAddress: "172.16.91.135"
token: "ivxcdu.wub0bx69mk91qo6w"
tokenTTL: "0s"
apiServerCertSANs:
- master
- slave1
- slave2
- 172.16.91.135
- 172.16.91.136
- 172.16.91.137
- 172.16.91.222
featureGates:
CoreDNS: true
注意:
- 不同kubeadm的版本 对应的配置文件的属性是不一样的,要注意
- 上面配置文件里,etcd需要根据自己的实际情况进行配置, 由于我本地环境有etcd,因此就不需要kubeadm自带的etcd了,因此这里需要配置一下,设置成external属性,
3.4.3 初始化master节点(master节点)
方案一: 不使用配置文件(最后采纳了这种方案)
kubeadm init --kubernetes-version=v1.9.0 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
指定镜像仓库方式
如镜像如下:
registry.aliyuncs.com/google_containers/kube-proxy:v1.15.1时,可以指定镜像仓库
kubeadm init --kubernetes-version="v1.15.1" --pod-network-cidr=192.168.0.0/16 --image-repository=registry.aliyuncs.com/google_containers | tee kubeadm-init.log
https://www.cnblogs.com/AutoSmart/p/11230268.html
方案二: 使用配置文件(这种方案可能有问题)
kubeadm init --config kubeadm-config-v1.12.1.yaml
报错如下:
error ensuring dns addon: unable to create/update the DNS service: Service "kube-dns" is invalid: spec.clusterIP: Invalid value: "10.96.0.10": field is immutable
原因?
很明显值的类型不符合要求
解决措施?
需要将kind的类型,改成InitConfiguration
最终配置文件的内容如下所示:
vim kubeadm-config-v1.12.1.yaml
apiVersion: kubeadm.k8s.io/v1alpha3
kind: InitConfiguration
etcd:
external:
endpoints:
- https://172.16.91.222:2379
caFile: /root/ca-k8s/ca.pem
certFile: /root/ca-k8s/etcd.pem
keyFile: /root/ca-k8s/etcd-key.pem
dataDir: /var/lib/etcd
networking:
podSubnet: 192.168.0.0/16
token: "ivxcdu.wub0bx69mk91qo6w"
tokenTTL: "0"
apiServerCertSANs:
- master
- slave1
- slave2
- 172.16.91.135
- 172.16.91.136
- 172.16.91.137
- 172.16.91.222
- 127.0.0.1
初始化正确结果,打印信息如下:
[init] using Kubernetes version: v1.12.1
[preflight] running pre-flight checks
[preflight/images] Pulling images required for setting up a Kubernetes cluster
[preflight/images] This might take a minute or two, depending on the speed of your internet connection
[preflight/images] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[preflight] Activating the kubelet service
[certificates] Generated etcd/ca certificate and key.
[certificates] Generated etcd/peer certificate and key.
[certificates] etcd/peer serving cert is signed for DNS names [master localhost] and IPs [172.16.91.135 127.0.0.1 ::1]
[certificates] Generated etcd/healthcheck-client certificate and key.
[certificates] Generated apiserver-etcd-client certificate and key.
[certificates] Generated etcd/server certificate and key.
[certificates] etcd/server serving cert is signed for DNS names [master localhost] and IPs [127.0.0.1 ::1]
[certificates] Generated ca certificate and key.
[certificates] Generated apiserver certificate and key.
[certificates] apiserver serving cert is signed for DNS names [master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.16.91.135]
[certificates] Generated apiserver-kubelet-client certificate and key.
[certificates] Generated front-proxy-ca certificate and key.
[certificates] Generated front-proxy-client certificate and key.
[certificates] valid certificates and keys now exist in "/etc/kubernetes/pki"
[certificates] Generated sa key and public key.
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[controlplane] wrote Static Pod manifest for component kube-apiserver to "/etc/kubernetes/manifests/kube-apiserver.yaml"
[controlplane] wrote Static Pod manifest for component kube-controller-manager to "/etc/kubernetes/manifests/kube-controller-manager.yaml"
[controlplane] wrote Static Pod manifest for component kube-scheduler to "/etc/kubernetes/manifests/kube-scheduler.yaml"
[etcd] Wrote Static Pod manifest for a local etcd instance to "/etc/kubernetes/manifests/etcd.yaml"
[init] waiting for the kubelet to boot up the control plane as Static Pods from directory "/etc/kubernetes/manifests"
[init] this might take a minute or longer if the control plane images have to be pulled
[apiclient] All control plane components are healthy after 25.504521 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.12" in namespace kube-system with the configuration for the kubelets in the cluster
[markmaster] Marking the node master as master by adding the label "node-role.kubernetes.io/master=''"
[markmaster] Marking the node master as master by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "master" as an annotation
[bootstraptoken] using token: yj2qxf.s4fjen6wgcmo506w
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 172.16.91.135:6443 --token yj2qxf.s4fjen6wgcmo506w --discovery-token-ca-cert-hash sha256:6d7d90a6ce931a63c96dfe9327691e0e6caa3f69082a9dc374c3643d0d685eb9
3.4.4 初始化失败时的解决措施(2种方式) (master节点)
-
方式一(推荐这种方式简单明了):
kubeadm reset
-
方式二:
rm -rf /etc/kubernetes/.conf
rm -rf /etc/kubernetes/manifests/.yaml
docker ps -a |awk '{print $1}' |xargs docker rm -f
systemctl stop kubelet
3.4.5 配置kubectl的认证信息(master节点)
配置kubectl的配置文件
- 若是非root用户
mkdir -p HOME/.kube/config
sudo chown (id -g) $HOME/.kube/config - 若是root用户
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
做了这一步操作后,就不会报类似这样的错误了:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
3.4.6 简单测试下
-
查看master节点状态
kubectl get node
 image
image -
查看pod资源情况
kubectl get pod -n kube-system -o wide
 image
image -
查看组件运行状态
kubectl get componentstatus
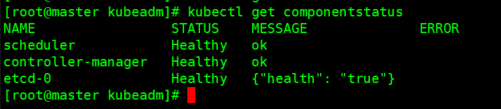 image
image -
查看kubelet运行状况
systemctl status kubelet
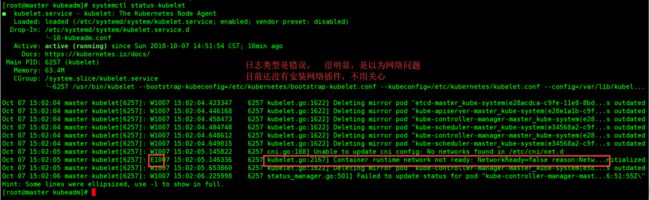 image
image
3.4.7 让master也运行pod(默认master不运行pod)(选做)
kubectl taint nodes --all node-role.kubernetes.io/master-
3.4.8 将其他从节点slave1,slave2添加到集群里
分别登陆到slave1, slave2上,运行下面的命令即可了(注意,要改成自己的)
kubeadm join 172.16.91.135:6443 --token yj2qxf.s4fjen6wgcmo506w --discovery-token-ca-cert-hash sha256:6d7d90a6ce931a63c96dfe9327691e0e6caa3f69082a9dc374c3643d0d685eb9
假如:忘记上面的token,可以使用下面的命令,找回(master节点上执行)
kubeadm token create --print-join-command
3.4.9 再次查看pod的状态
kubectl get pods --all-namespaces -owide
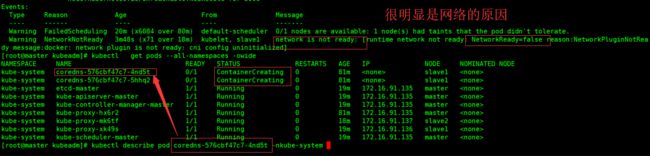
通过下面的命令,查看原因?
kubectl describe pod coredns-576cbf47c7-4nd5t -nkube-system
3.4.10 安装calico插件, 从而实现pod间的网络通信
进入k8s官网,获取calico yaml
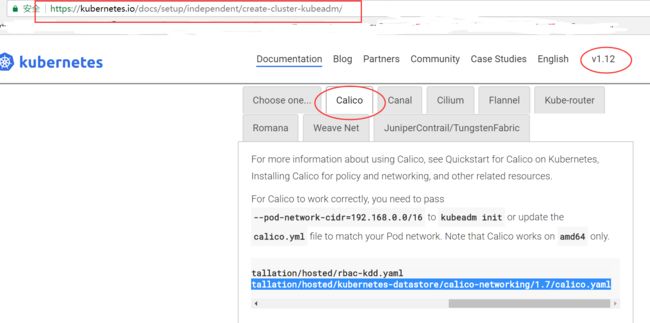
注意:
kubernetes v1.12.1对应的calico版本是Calico Version v3.1.3
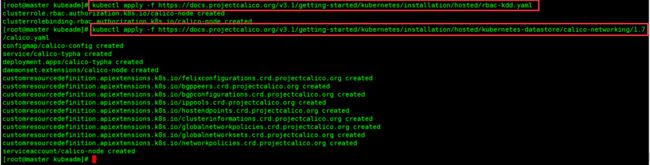
直接运行下面的命令
kubectl apply -f https://docs.projectcalico.org/v3.1/getting-started/kubernetes/installation/hosted/rbac-kdd.yaml
kubectl apply -f https://docs.projectcalico.org/v3.1/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
四、 问题说明:
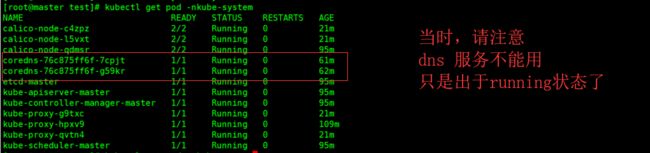
- 查看pod状态? 发现只有coredns pod 一直处于containercreating状态,没有分配到ip?
查看kubelet日志,发现network cni插件状态为false
可能是因为,在初始化master节点时, 配置文件里定义的属性podpodSubnet 没有生效
因此,直接使用命令行的方式, - 如果发现coredns pod 一直处于running,error等状态的话,
查看日志
[root@master /]#kubectl logs coredns-55f86bf584-7sbtj -n kube-system
.:53
2018/10/09 10:20:15 [INFO] CoreDNS-1.2.2
2018/10/09 10:20:15 [INFO] linux/amd64, go1.11, eb51e8b
CoreDNS-1.2.2
linux/amd64, go1.11, eb51e8b
2018/10/09 10:20:15 [INFO] plugin/reload: Running configuration MD5 = 86e5222d14b17c8b907970f002198e96
2018/10/09 10:20:15 [FATAL] plugin/loop: Seen "HINFO IN 2050421060481615995.5620656063561519376." more than twice, loop detected
如何解决?
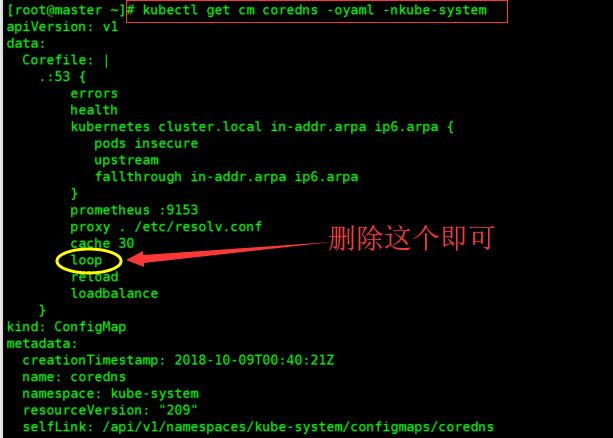
通过下面的命令,进行编辑删除
kubectl edit cm coredns -oyaml -nkube-system
具体原因,暂时不再跟踪,目前主要想研究calico的network policy,此问题先放一边
跟此问题相关的文章如下:
https://github.com/coredns/coredns/issues/2087
https://github.com/kubernetes/kubeadm/issues/998
这里面有解决方案,不知道为什么我的集群不起作用
补充:测试dns插件的方法
- 准备测试用的yaml, pod-for-dns.yaml
注意:busybox的版本号,有些版本号测试失败apiVersion: v1 kind: Pod metadata: name: dns-test namespace: default spec: containers: - image: busybox:1.28.4 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: dns-test restartPolicy: Always - 创建pod
kubectl create -f pod-for-dns.yaml - 测试dns服务
[root@master ~]# kubectl exec dns-test -- nslookup kubernetes Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes Address 1: 10.96.0.1 webapp.default.svc.cluster.local