Python利用Requests获取2TB大容量不限速小麦魔方网盘/小麦云盘(Own-Cloud.Cn)的文件直链并下载文件
我们在浏览网页的时候一般都会看到很多好用的网盘,最近很多网盘都是一些开发者比较喜欢使用的,原因大多都是他们不像某盘一样限速,要求充会员而且还要广告。这些大容量的网盘大多也是开源的,所以我们也不能存储一些太过于贵重的一些物品。我之前写过一篇关于蓝奏云盘的文章,是可以获取直链和不限速下载链接的。所以今天我们就来讲一讲另一个比较好的网盘——小麦云盘
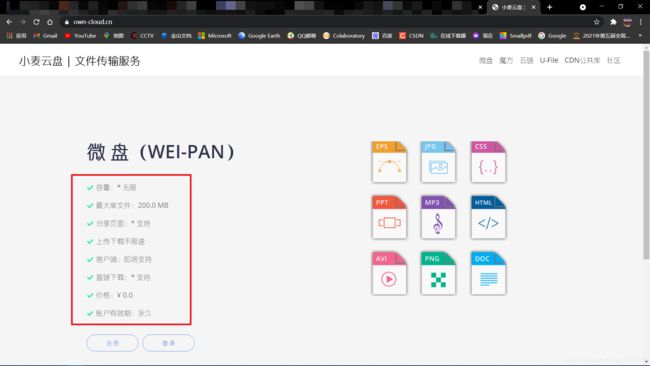
蓝奏云文章传送地址:无限存储空间的蓝奏网盘你还不用?使用Python,直接获取直链!Python使用Requests和BS4实现蓝奏云直链解析与下载
那么接下来我们马上就来尝试一下(大家可以注册一个账号自己体验一下)
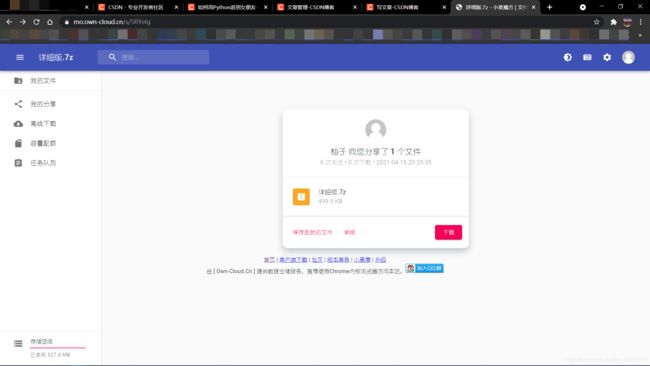
在这里我们会使用某一位仁兄的分享链接作为我们这次实验的对象
文章目录
- 程序设计
-
- 创建一个类
- 分析网站
-
- 示例代码
- 下载链接获取
-
- 示例代码
- 访问并保存文件
- 完整代码
- 提示
- 转载声明
程序设计
创建一个类
我们在使用的时候,为了让我们每一步都非常适合我们后续的操作。我们在编写代码时使用类与对象的方法进行管理。那么首先我们先创建一个名为OwnCloud的类
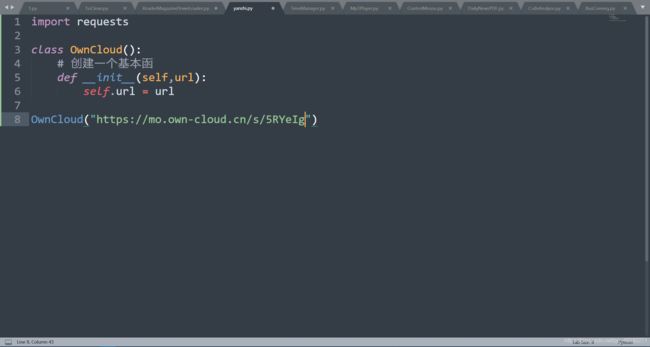
这个程序当你运行时不会有任何的变化,所以我们要在这个类里面加上一些方法
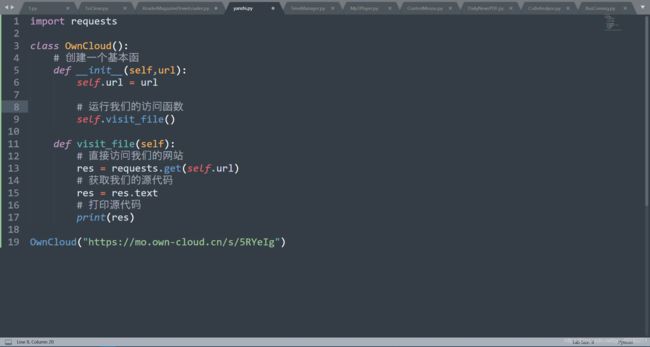
分析网站
我们通过分析可以看出,我们网站的源代码非常少,我们可以通过直接访问网页获取其源代码,修改代码成为这样,我们可以看见运行结果成为了这样
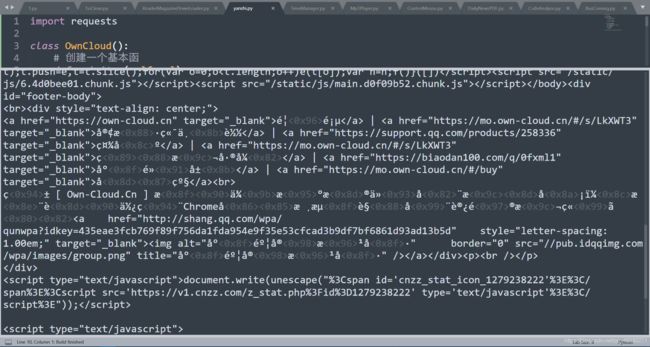
我们不能看到网站上到底有什么内容,所以我们要在代码中加上编码的内容,如果不知道的小伙伴们可以看我的这一篇文章:Requests使用时踩过的坑(一):当使用Text获取网页源代码时乱码了怎么办(requests常见的几种解码方式和常见的编码方式)所以我们将代码加上这一行res.encoding = "utf-8"就会发现我们的返回值可以正常访问了
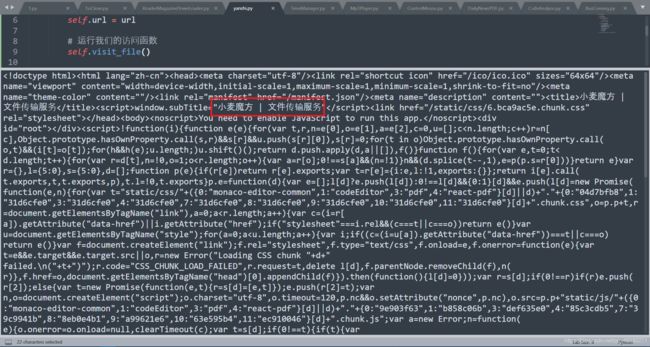
但是显然,我们的源代码太少了,很多关键的地方像分享人都没有出现在我们的页面上,说明它和访问链接不是同一个
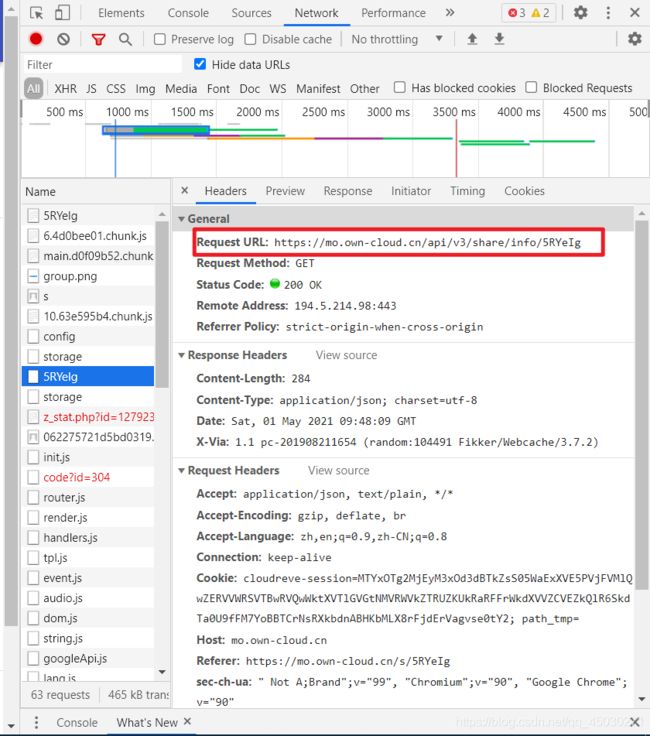
继续观察我们可以发现这一个链接,这是一个GET链接,我们可以点开返回值查看一样它的内容。当然我们也可以从链接的字面意思上了解到我们这个链接的意思,就是获取信息的一个链接。这对我们的爬取非常重要

可是我们将如何获取我们的ID值呢,我们的ID值从第一时刻就传进了程序,但是我们并不能使用我们的返回值,这个时候我们就要使用到我们的一个字符串的操作技术,字符串的分割,我们将使用split()分割出我们的ID
我们将这一行链接写入我们的基本程序

于是我们的程序变成了这样,我们可以看到我们已经可以输出我们的相关信息了
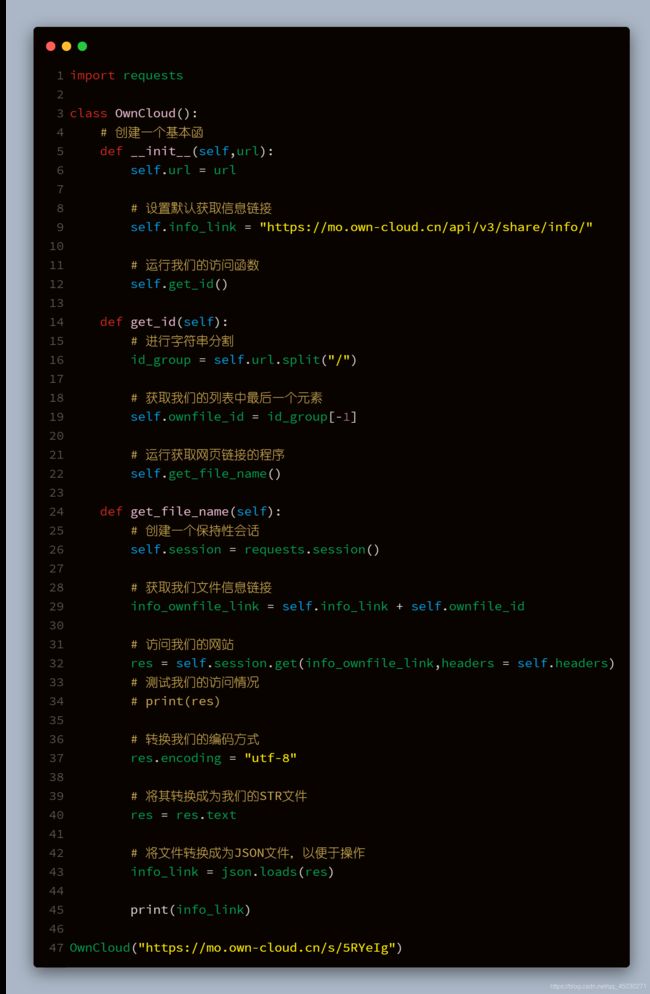
运行结果如下图所示,所以我们便可以获取到我们分享者和我们文件的相关信息了,在这些信息当中,最重要的就是文件的名字和文件的大小。因为我们PYTHON的下载速度是不能显示的,所以我们只能通过文件大小估计我们的下载时间。
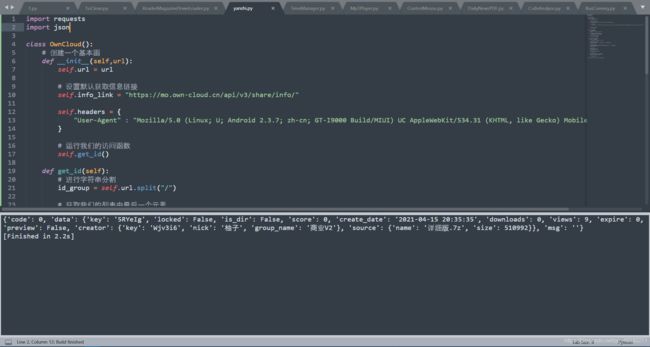
我们加上解析代码,我们的程序已经快完成一半了
示例代码
import requests
import json
class OwnCloud():
# 创建一个基本函
def __init__(self,url):
self.url = url
# 设置默认获取信息链接
self.info_link = "https://mo.own-cloud.cn/api/v3/share/info/"
self.headers = {
"User-Agent" : "Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; GT-I9000 Build/MIUI) UC AppleWebKit/534.31 (KHTML, like Gecko) Mobile Safari/534.31",
}
# 运行我们的访问函数
self.get_id()
def get_id(self):
# 进行字符串分割
id_group = self.url.split("/")
# 获取我们的列表中最后一个元素
self.ownfile_id = id_group[-1]
# 运行获取网页链接的程序
self.get_file_name()
def get_file_name(self):
# 创建一个保持性会话
self.session = requests.session()
# 获取我们文件信息链接
info_ownfile_link = self.info_link + self.ownfile_id
# 访问我们的网站
res = self.session.get(info_ownfile_link,headers = self.headers)
# 测试我们的访问情况
# print(res)
# 转换我们的编码方式
res.encoding = "utf-8"
# 将其转换成为我们的STR文件
res = res.text
# 将文件转换成为JSON文件,以便于操作
info_link = json.loads(res)
# print(info_link)
info_link_data = info_link.get("data")
locked = info_link_data.get("locked")
is_dir = info_link_data.get("is_dir")
create_data = info_link_data.get("create_data")
downloads = info_link_data.get("downloads")
views = info_link_data.get("views")
creator = info_link_data.get("creator")
creator_key = creator.get("key")
creator_nick = creator.get("nick")
source = info_link_data.get("source")
self.name = source.get("name")
self.size = source.get("size")
msg = info_link_data.get("msg")
# 继续运行
self.visit_file()
OwnCloud("https://mo.own-cloud.cn/s/5RYeIg")
下载链接获取
继续下载我们可以发现,我们点击下载的时候,我们的网站会发出一个获取下载链接的代码,通过这个下载链接,我们就一定可以获取到我们的文件了。
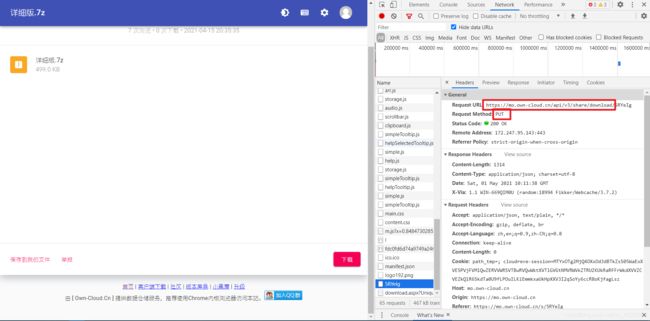
我们使用和获取文件信息一样的方法下载资料,但是要注意的是这里的请求,我们一定要看清请求再写代码,这样才能保证我们的准确性
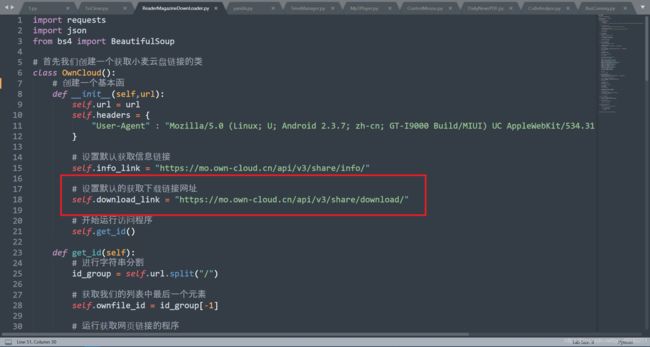
首先先设置我们的默认链接,然后我们再进行相关的活动
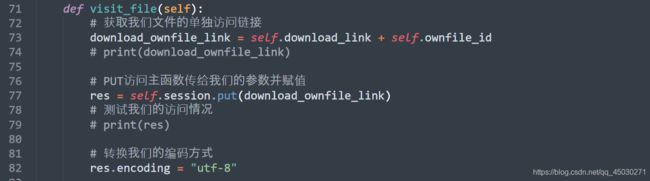
编写我们的代码,我们还是一样的编码方式,并且加上我们自己文件的ID值
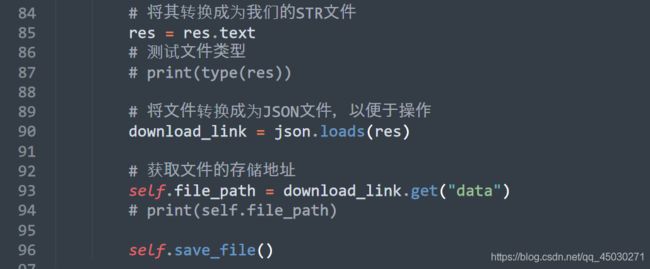
转换之后获取我们的地址,我们可以看到这是一个Json文件,我们可以获取JSON文件的地址,我们可以进一步进行访问操作
示例代码
import requests
import json
from bs4 import BeautifulSoup
# 首先我们创建一个获取小麦云盘链接的类
class OwnCloud():
# 创建一个基本函
def __init__(self,url):
self.url = url
self.headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
}
# 设置默认获取信息链接
self.info_link = "https://mo.own-cloud.cn/api/v3/share/info/"
# 设置默认的获取下载链接网址
self.download_link = "https://mo.own-cloud.cn/api/v3/share/download/"
# 开始运行访问程序
self.get_id()
def get_id(self):
# 进行字符串分割
id_group = self.url.split("/")
# 获取我们的列表中最后一个元素
self.ownfile_id = id_group[-1]
# 运行获取网页链接的程序
self.get_file_name()
def get_file_name(self):
# 创建一个保持性会话
self.session = requests.session()
# 获取我们文件信息链接
info_ownfile_link = self.info_link + self.ownfile_id
# 访问我们的网站
res = self.session.get(info_ownfile_link,headers = self.headers)
# 测试我们的访问情况
# print(res)
# 转换我们的编码方式
res.encoding = "utf-8"
# 将其转换成为我们的STR文件
res = res.text
# 将文件转换成为JSON文件,以便于操作
info_link = json.loads(res)
info_link_data = info_link.get("data")
locked = info_link_data.get("locked")
is_dir = info_link_data.get("is_dir")
create_data = info_link_data.get("create_data")
downloads = info_link_data.get("downloads")
views = info_link_data.get("views")
creator = info_link_data.get("creator")
creator_key = creator.get("key")
creator_nick = creator.get("nick")
source = info_link_data.get("source")
self.name = source.get("name")
self.size = source.get("size")
msg = info_link_data.get("msg")
# 继续运行
self.visit_file()
def visit_file(self):
# 获取我们文件的单独访问链接
download_ownfile_link = self.download_link + self.ownfile_id
# print(download_ownfile_link)
# PUT访问主函数传给我们的参数并赋值
res = self.session.put(download_ownfile_link)
# 测试我们的访问情况
# print(res)
# 转换我们的编码方式
res.encoding = "utf-8"
# 将其转换成为我们的STR文件
res = res.text
# 测试文件类型
# print(type(res))
# 将文件转换成为JSON文件,以便于操作
download_link = json.loads(res)
# 获取文件的存储地址
self.file_path = download_link.get("data")
print(self.file_path)
访问并保存文件
我们使用同一个会话将我们的软件保存,这个时候我们的请求链接是使用GET,我们获取完访问内容后将继续保存文件,也就是调用我们接下来的函数
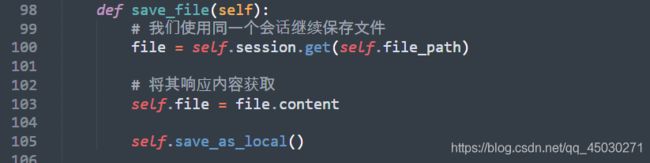
最后,我们保存我们写好的文件,这样大功告成
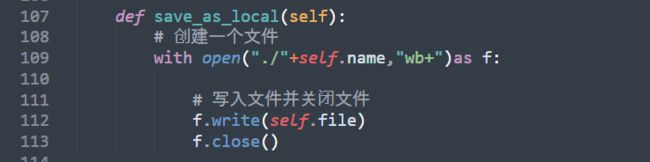
完整代码
其实整一个代码也不是特别难,只要根据网站开发者的思路走就好了
import requests
import json
from bs4 import BeautifulSoup
# 首先我们创建一个获取小麦云盘链接的类
class OwnCloud():
# 创建一个基本函
def __init__(self,url):
self.url = url
self.headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
}
# 设置默认获取信息链接
self.info_link = "https://mo.own-cloud.cn/api/v3/share/info/"
# 设置默认的获取下载链接网址
self.download_link = "https://mo.own-cloud.cn/api/v3/share/download/"
# 开始运行访问程序
self.get_id()
def get_id(self):
# 进行字符串分割
id_group = self.url.split("/")
# 获取我们的列表中最后一个元素
self.ownfile_id = id_group[-1]
# 运行获取网页链接的程序
self.get_file_name()
def get_file_name(self):
# 创建一个保持性会话
self.session = requests.session()
# 获取我们文件信息链接
info_ownfile_link = self.info_link + self.ownfile_id
# 访问我们的网站
res = self.session.get(info_ownfile_link,headers = self.headers)
# 测试我们的访问情况
# print(res)
# 转换我们的编码方式
res.encoding = "utf-8"
# 将其转换成为我们的STR文件
res = res.text
# 将文件转换成为JSON文件,以便于操作
info_link = json.loads(res)
info_link_data = info_link.get("data")
locked = info_link_data.get("locked")
is_dir = info_link_data.get("is_dir")
create_data = info_link_data.get("create_data")
downloads = info_link_data.get("downloads")
views = info_link_data.get("views")
creator = info_link_data.get("creator")
creator_key = creator.get("key")
creator_nick = creator.get("nick")
source = info_link_data.get("source")
self.name = source.get("name")
self.size = source.get("size")
msg = info_link_data.get("msg")
# 继续运行
self.visit_file()
def visit_file(self):
# 获取我们文件的单独访问链接
download_ownfile_link = self.download_link + self.ownfile_id
# print(download_ownfile_link)
# PUT访问主函数传给我们的参数并赋值
res = self.session.put(download_ownfile_link)
# 测试我们的访问情况
# print(res)
# 转换我们的编码方式
res.encoding = "utf-8"
# 将其转换成为我们的STR文件
res = res.text
# 测试文件类型
# print(type(res))
# 将文件转换成为JSON文件,以便于操作
download_link = json.loads(res)
# 获取文件的存储地址
self.file_path = download_link.get("data")
print(self.file_path)
self.save_file()
def save_file(self):
# 我们使用同一个会话继续保存文件
file = self.session.get(self.file_path)
# 将其响应内容获取
self.file = file.content
self.save_as_local()
def save_as_local(self):
# 创建一个文件
with open("./"+self.name,"wb+")as f:
# 写入文件并关闭文件
f.write(self.file)
f.close()
OwnCloud("https://mo.own-cloud.cn/s/5RYeIg")
提示
那么大家要注意的是,我们要使用Headers对网站进行访问的原因,是因为我们想让网站认为我们并不是一个机器人爬虫,而是一个正常访问的正常人,所以我们将在我们的程序中设置Headers。但是当我们的程序访问很多次时,比如说是一个高并发的程序,我们可能要加入我们自己的Cookies或者不停地更改我们Headers来让我们的程序变得不同。当然,使用代理也是一种很好的方法,大家也可以试着去维护一个代理池。
转载声明
博客在2021年5月1日首发自CSDN,如需转载,请附上原文链接:Python利用Requests获取2TB大容量不限速小麦魔方网盘/小麦云盘(Own-Cloud.Cn)的文件直链并下载文件