非root用户配置hadoop的终极踩坑教程
三台linux部署完全分布式集群的终极踩坑教程
- 前言
- 硬件,软件环境
-
- 1.总体架构
- 2.软件下载
- 配置步骤
-
- 1. 配置ssh免密登录
- 2. 配置hosts文件
- 3.hadoop配置文件修改
- 4.启动
- 问题汇总
-
- 1.ssh配置问题
- 2.java的路径问题
- 3.datanode无法开启
- 4.secondarynamenode无法开启
- 5.resourcemanager无法开启
- 6.unhealthy node
- 总结
前言
因实验需要,使用实验室服务器的非root用户搭建一个完全分布式hadoop,自己踩坑无数,所以写篇教程记录一下,希望大家一起学习。少走弯路!
硬件,软件环境
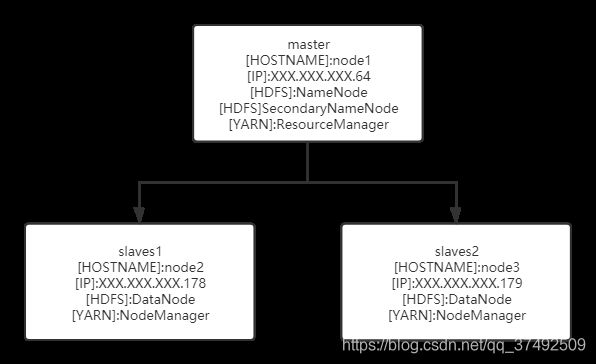
1.总体架构
使用了三台服务器,都是ubuntu18.04,其中一台作为master,两台作为slaves,hadoop版本为2.9.2。
2.软件下载
- java,建议使用Java1.8,因为我装的hadoop版本为2.9,我一开始有台服务器默认使用jdk11的时候会报warning。由于是实验室服务器,没有管理员权限。为此就没有另外下载java,使用了默认的openjdk。想要下载的同学网上教程也很多。当有多个java环境时,之后我会强调如何使用环境变量
- hadoop下载,我自己是在windows上在官网下的【下载链接】,选了2.9版本的。
配置步骤
接下来的步骤,我没有强调就是只针对master,图片中的64服务器做操作!
备注:三个服务器都在home目录下创建了一个叫做hadoop的用户,作为管理hadoop账号!由于已经配置完成,演示阶段我使用了阿里云服务器进行一个演示过程!
1. 配置ssh免密登录
由于是完全式分布式,需要采用ssh让master服务器能够免密登录其他两台服务器。
- 清空.ssh目录下的内容
因为环境的不同,这里统一清空下面的目录,保证生效,使用如下指令清空
cd ~/.ssh
rm -rf *
- 生成公私密钥
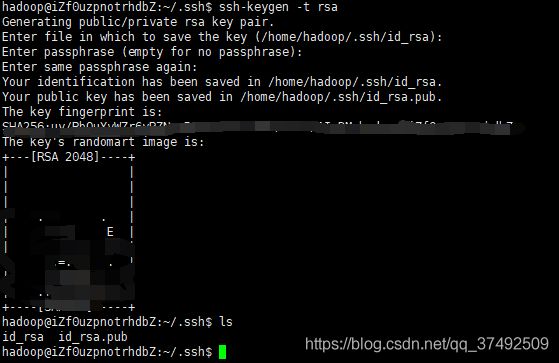
在主服务器上使用指令
ssh-keygen -t rsa
生成公私密钥,一路enter即可,这时会在/home/hadoop下的.ssh目录下会生成一个id_rsa(私钥),id_rsa.pub(公钥)
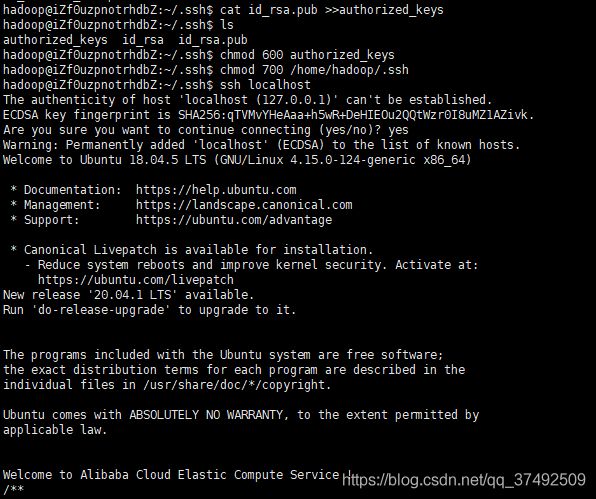
进入.ssh目录,使用指令将公钥写入authorized_keys,并将authorized_keys权限改为600,.shh文件改为700!!!很重要,否则无法配置成功。进行完成后,先进行本机免密登录的尝试,首次登录会询问是否加入know_hosts,输入yes即可,可以看出已经实现了免密登录。
cat id_rsa.pub >>authorized_keys
chmod 600 authorized_keys
chmod 700 /home/hadoop/.ssh
ssh localhost
接下来,将主服务器的公钥拷贝到其他两个服务器,介绍三种方法,任选一个就行!!
- ssh-copy-id来实现,其中[email protected]是slave服务器的用户名和ip
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
- 或者使用scp指令拷贝到其他两个服务器
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/.ssh
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/.ssh
再登录178和179两台服务器,分别进行
cat id_rsa.pub >>authorized_keys
chmod 600 authorized_keys
chmod 700 /home/hadoop/.ssh
- 使用xftp等工具将id_rsa.pub拷贝到其余两个服务器的.ssh目录中!
cat id_rsa.pub >>authorized_keys
chmod 600 authorized_keys
chmod 700 /home/hadoop/.ssh
通过上述三种方法,主服务器就能顺路登录两个子服务器,回到64主服务器,进行测试。
ssh [email protected]
ssh [email protected]
若都能顺利登录则配置成功。当然我在实际的配置时也遇到了一些问题,为此之前写过一篇博客记录,大家可以参考ssh配置免密登录踩坑记录
2. 配置hosts文件
**此步骤三台服务器都需要,且需要管理员权限!
vim /etc/hosts
在hosts文件中编辑相同的如下内容,保存。
XXX.XXX.XXX.64 node1
XXX.XXX.XXX.178 node2
XXX.XXX.XXX.179 node3
3.hadoop配置文件修改
在64主服务器中,通过上传得到的hadoop安装包,解压并改名。有六个文件需要修改配置。都在/home/hadoop/hadoop/etc/hadoop下
tar -zxvf hadoop.2.9.2.tar.gz -C /home/hadoop
mv hadoop.2.9.2 hadoop
1. hadoop-env.sh
在该文件末尾加入此句,让hadoop可以找到java,我使用的服务器上已有的openjdk,如果找到到java的同学,我在问题汇总中将会详细介绍!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- core-site.xml
在该文件中增加如下内容,首先就是defaultsFS这个配置,下面的node1:8020,node1对应的就是hosts文件下的64服务器ip!
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://node1:8020</value>
23 </property>
24 <property>
25 <name>hadoop.tmp.dir</name>
26 <value>file:/home/hadoop/hadoop/tmp</value>
27 <description>Abase for other temporary directories.</description>
28 </property>
29 <property>
30 <name>io.file.buffer.size</name>
31 <value>131072</value>
32 <description>该属性值单位为KB,131072KB即为默认的 64M</description>
33 </property>
34 </configuration>
- ** hdfs-site.xml**
在该文件中注意一下namenode和datanode的文件目录,这是自定义的,由于是非root用户,所以需要有可写权力,所以我设置在hadoop安装目录下的dfs文件中!replication这个配置,由于只有两个子节点,所以就写了2,
19 <configuration>
20 <property>
21 <name>dfs.namenode.secondary.http-address</name>
22 <value>node1:50090</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name>
26 <value>file:/home/hadoop/hadoop/dfs/name</value>
27 </property>
28 <property>
29 <name>dfs.datanode.data.dir</name>
30 <value>file:/home/hadoop/hadoop/dfs/data</value>
31 </property>
32 <property>
33 <name>dfs.replication</name>
34 <value>2</value>
35 </property>
36 <!---块大小-->
37 <property>
38 <name>dfs.blocksize</name>
39 <value>134217728</value>
40 <description>node2文件系统HDFS块大小为128M</description>
41 </property>
42 <property>
43 <name>dfs.webhdfs.enabled</name>
44 <value>true</value>
45 </property>
46 </configuration>
- yarn-site.xml
该文件的下配置的node1就是64服务器的ip
15 <configuration>
16 <property>
17 <name>yarn.resourcemanager.hostname</name>
18 <value>node1</value>
19 </property>
20 <property>
21 <name>yarn.nodemanager.aux-services</name>
22 <value>mapreduce_shuffle</value>
23 </property>
24 <property>
25 <name>yarn.resourcemanager.scheduler.address</name>
26 <value>node1:8030</value>
27 </property>
28 <property>
29 <name>yarn.resourcemanager.address</name>
30 <value>node1:8032</value>
31 </property>
32 <property>
33 <name>yarn.resourcemanager.resource-tracker.address</name>
34 <value>node1:8031</value>
35 </property>
36 <property>
37 <name>yarn.resourcemanager.admin.address</name>
38 <value>node1:8033</value>
39 </property>
40 <property>
41 <name>yarn.resourcemanager.webapp.address</name>
42 <value>node1:8088</value>
43 </property>
44 </configuration>
- mapred-site.xml
19 <configuration>
20 <property>
21 <name>mapreduce.framework.name</name>
22 <value>yarn</value>
23 </property>
24 <property>
25 <name>mapreduce.jobhistory.address</name>
26 <value>node1:10020</value>
27 </property>
28 <property>
29 <name>mapreduce.jobhistory.webapp.address</name>
30 <value>node1:19888</value>
31 </property>
32 </configuration>
- slaves
在slaves文件下写入两个子节点的名字,都是在hosts文件中配好了ip。
1 node2
2 node3
至此,主要的主服务器的配置已经完成,接下来将该hadoop安装文件原封不动的拷贝到其他两个服务器,我在64服务器的位置是/home/hadoop/hadoop,拷贝完毕后,在178,179服务器的/home/hadoop目录下也出现hadoop安装文件!,这里依旧有三个方法拷贝,和公私钥配置相同,我直接使用了scp的方法。
scp -r /home/hadoop/hadoop [email protected]:/home/hadoop
scp -r /home/hadoop/hadoop [email protected]:/home/hadoop
在三个服务器配置hadoop环境变量!!!编辑~/.bashrc文件。
下面顺便配置了java的环境,特别注意三个服务器的java位置可能有不同,在问题汇总中我会再次强调。
119 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
120 export HADOOP_HOME=/home/hadoop/hadoop/
122 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
123 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
124 export JRE_HOME=${JAVA_HOME}/jre
125 export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
126 export PATH=${JAVA_HOME}/bin:$PATH
编辑完毕,使用指令使它生效。
source ~/.bashrc
4.启动
注意,接下来在64主服务器上操作,格式化hdfs操作,初次部署操作,多次操作将遇坑!
1. 格式化HDFS
注意在首次使用时使用,若重复格式化,将无法开启datanode
cd /home/hadoop/hadoop/etc/bin
hdfs namenode -format
2. 开启hadoop
最简单的开启指令是
start-all.sh
不过已经被官方建议不要使用,所以使用如下指令,(其实all操作就是用下面两个脚本,官方应该的意思是一个个开启比较好)
start-dfs.sh
start-yarn.sh
关闭指令将上述start改为stop即可。
3. 展示效果
三个服务器都是用jps指令查看
- 64主服务器将会开启如下服务
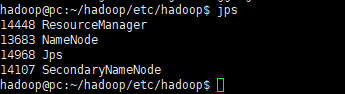
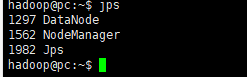
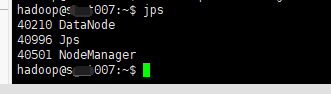
- 178和179服务器开启如下服务
如果按照我的配置,在本地电脑浏览器输入以下网址XXX.XXX.XXX.64:8088,,就是在yarn-site.xml文件配置的主服务器端口就可以看到如下管理界面。

网址XXX.XXX.XXX.64:50070可以看到
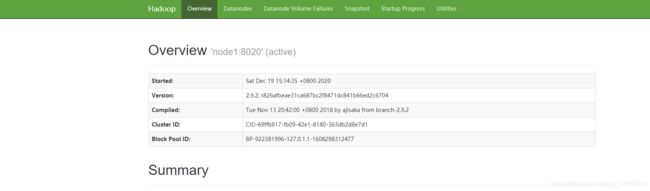
这样就完全配置好了hadoop!!!
问题汇总
1.ssh配置问题
参考我之前写的ssh配置免密登录踩坑记录,
主要是文件权限问题!,还有特别重要的的一点,在让管理员帮忙写hosts的ip时,ip千万别写错,就因为这问题我弄了一天,免密登录一直出错~
2.java的路径问题
这个问题也很重要,踩了不少的坑。由于采用的已有的java环境,所以需要找到他的安装环境。
使用which java可以看到现在指向的软链接。使用如下指令,可以看到默认的安装路径

本文中有两个地方需要配置java环境,一个是三个服务器上的~/.bashrc文件中,一个是在hadoop下的etc/hadoop下的hadoop-env.sh。我在实际的操作中发现,三台服务器可能存在java的版本不同,由于安装的是2.9.2的hadoop。所以采用了1.8的jdk,上文中我是直接将64主服务器的hadoop拷贝到178和179服务器,但是操作中,由于java的不同,需要修改java配置,读者可以看下我的几个不同路径。
- 首先64主服务器.bashrc
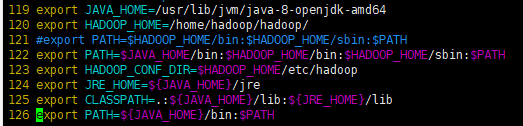
- 看下179服务器上

- 以下是178服务器

这是笔者在操作中遇到的一个比较打的坑。
3.datanode无法开启
遇到过datanode无法开启,在查了半天的资料后发现,首次的namenode初始化不可以多次进行,否则会出现版本问题,无法开启datanode,解决方案是,我们在hdfs-site.xml配置的namenode的保存路径下的name文件下清空即可。
4.secondarynamenode无法开启
通过查看logs,我遇到的问题是在配置 core-site.xml的tmp这个存储路径时,使用了网上的存储路径,但是那个路径需要管理员权限读写,所以需要修改到本目录文件下。
5.resourcemanager无法开启
我遇到的这个无法开启是因为一直报找不到java路径,但是根据网上的各路教程我觉得已经配置无误了。。然后也没有生成log让我查看,在经过大半天的挣扎后,我发现在/hodoop/etc/hadoop目录下有一个yarn-env.sh可以修改配置。修改其java的路径!
![]()
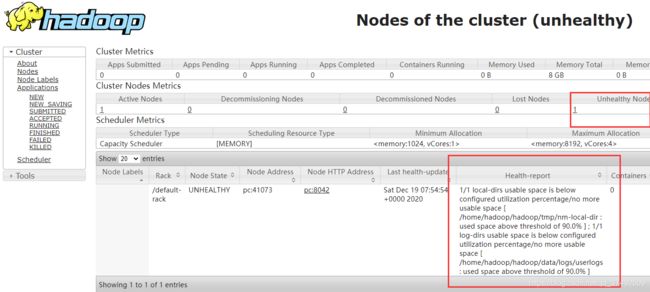
6.unhealthy node
从这个页面上,我们可以看到有个节点是unhealty的,停止使用,这是因为存储路径已经使用量已经大于90%,为此需要修改该服务器的存储位置!!,就是core-site.xml,hafd-site.xml这两个配置文件下里面写的存储位置。(无奈我的账号没办法写入其他地方位置,先这么弄把),贴个参考的修改博客修改存储位置参考
总结
磕磕绊绊装了两天多的hadoop,算是装完了,中间遇到很多坑,其实大多都是因为自己不够理解造成的,为此还需要更多的学习,书写下来也是为了让更多读者少遇到坑,顺利解决~